Appearance
AI 是什么
本文介绍什么是AI、什么是LLM及其相关概念。
1. AI是什么
AI,全称为Artificial Intelligence,译为人工智能,指的是让计算机系统具备类似人类智能的能力,换句话说,AI就是让计算机去做那些原本只有人类大脑才能完成的任务,例如理解周围的世界、学习新事物、产生新的想法。
AI 涵盖许多不同的学科,包括计算机科学、数据分析和统计、硬件和软件工程、语言学、神经学,甚至哲学和心理学。
实现AI涉及的技术方向如下:
- 机器学习 (ML):这类 AI 系统通过数据学习来识别模式,并在没有直接编程的情况下做出预测或决策。例如,通过向计算机展示数千张鸟类图片教会它识别鸟类;计算机会自行学习鸟类的样子。
- 深度学习 (DL):深度学习是机器学习的一个子领域,使用多层(因此称为“深度”)人工神经网络从数据中学习。这些网络的灵感来源于人脑的结构,尤其擅长处理图像识别和语音识别等复杂任务。
- 自然语言处理 (NLP):NLP 使计算机能够理解、解读和生成人类语言。语音助理、翻译服务和聊天机器人都离不开这项技术。
- 计算机视觉:这一技术让计算机能够“看见”并解读这个世界的视觉信息,例如图片和视频。从人脸识别到自动驾驶型汽车,处处都有它的身影。
按能力水平划分, AI 类型可以分为以下几类:
- 弱人工智能 (ANI,Artificial Narrow Intelligence):这是目前唯一存在的人工智能形式。ANI 模型旨在执行单一的特定任务,例如识别图片、进行聊天或过滤邮件。例子包括语音助理、人脸识别技术、Gemini 等生成式 AI 模型,以及其他大语言模型 (LLM)。尽管如此命名,ANI 并不具备推理能力或自我意识,而是将数据与算法相结合,在预定义的参数范围内做出预测。虽然 ANI 有很多好处,但也存在风险,因为质量不佳的训练数据可能会导致输出结果有偏见或不准确,这在贷款审批、招聘决策和预测性警务等应用中可能会造成严重后果。网络犯罪分子还可能利用 ANI 来设计复杂的 AI 诈骗。
- 通用人工智能 (AGI,Artificial General Intelligence):指具有与人类相当的智力水平,能够像人类一样学习、理解、推理并解决任何智力任务的 AI,具备自我意识、常识推理、跨领域迁移能力和情感理解。AGI 尚不存在,这是 AI 技术假想的未来发展阶段。虚构的例子包括电影《星球大战》中的机器人。但是,AGI 可能会引发严重的安全和道德问题,因为恶意方可能会带着有害意图对 AGI 进行编程,如果不加以监管,可能会导致无限的破坏力。
- 超人工智能 (ASI,Artificial Super Intelligence):指在科学创造力、智力、社交技能等所有领域都远超最聪明的人类大脑的智能,它不仅能处理人类能做的事,还能解决人类甚至无法理解的复杂问题。这是理论上最先进的 AI 形式。ASI 将是一种具有自我意识的实体,其运行不受人类控制,在推理、创造力甚至情商方面都将大大超过人类智能。与其他形式的 AI 一样,人们担心 ASI 可能会对人类的生存构成威胁,一些 AI 研究人员认为,ASI 极有可能带来非常糟糕的结果,包括人类灭绝。
2. Generative AI
Generative AI,译为生成式AI。在了解生成式AI之前,先了解一下判别式AI(Discriminative AI)。
判别式 AI 的核心任务是**“做选择题”。它通过学习数据中的特征,来判断输入的东西属于哪一类,或者预测一个具体的数值,判别式AI追求的是精度和唯一确定性**。判别式AI可以完成以下典型任务:
- 分类:这张照片是猫还是狗?这封邮件是不是垃圾邮件?
- 回归:根据房价走势,预测下个月的房价是多少?
- 识别:人脸识别、语音转文字。
生成式AI 的核心任务是创建新内容 。它不仅能理解数据,还能创造出与训练数据相似的全新内容。它不仅仅知道“猫”和“狗”的区别,它还掌握了“猫长什么样”的内在逻辑,从而能自己画出一张世界上不存在的猫(即创造新内容)。生成式AI追求的是多样性和新颖性。生成式AI可以完成以下典型任务:
文本生成:写诗、写代码、写小说;
图像生成:根据文字画图;
音视频生成:生成逼真的语音或视频;
LLM,全称Large Language Model,译为大语言模型,是生成式AI的一种,擅长处理文本内容,即接受文本输入,输出文本内容。由于处理了大量信息,它们可以回答复杂问题、总结文档、翻译语言、撰写创意内容,甚至生成计算机代码。
为什么叫大语言模型?
- 参数规模大:通常拥有数十亿甚至上万亿个参数(如 GPT-4)。
- 数据量大:阅读了几乎整个互联网的文本数据。
由于大语言模型的能力越来越强,出现了涌现能力:当模型的规模(参数量、训练数据、计算量)达到某个临界点时,模型突然表现出了它在规模较小时完全不具备的复杂能力,也就是说量变引起质变。
以下这些能力,通常被认为是大模型在达到一定规模后才“觉醒”的:
一步步思考的能力(Chain of Thought, CoT)
小模型在面对复杂逻辑推理(如:小明有3个苹果,给了小红1个,又买了2个...)时,通常会直接给出一个错误的答案。
但大模型在达到一定规模后,通过 Prompt 引导(如“请一步步思考”),能够展现出严谨的逻辑推导链条。
上下文学习(In-Context Learning)
不需要重新训练模型,只需要在对话中给它几个例子(Few-shot),模型就能立刻理解你的意图并模仿这种模式。
这种“举一反三”的能力在小模型上非常微弱,但在百亿级参数的模型上变得极强。例如:
用户输入:
范例1:输入“A区-01-层2” -> 输出“A-01-02”
范例2:输入“B仓库_05_三层” -> 输出“B-05-03”
范例3:输入“C区 12 4层” -> 输出:
AI 输出: “C-12-04”
这就是上下文学习: 模型通过阅读前两个范例,实时捕捉到了想要的“转换逻辑”,并在第三个输入中应用了这种逻辑。
上下文学习有三种模式:
Zero-shot(零样本):不给例子,直接下指令(“请把这个地址转成JSON”),依赖模型强大的预训练常识;
One-shot(单样本):只给一个例子。这能极大地修正模型对输出格式的理解;
Few-shot(多样本):给 3-5 个例子。这是最稳健的模式,特别适合处理复杂的业务逻辑或特殊的文本格式;
零样本迁移(Zero-shot Transfer)
模型能够完成它在训练阶段从未专门学习过的任务。例如,在训练阶段从未教过它如何将 Java 代码转成 Python,但它凭借对两种语言概率分布的深度掌握,直接理解并完成了翻译。
涌现就像是教孩子识字,当他识字量达到几千个(大模型)时,他突然有一天能读懂寓言故事并告诉你其中的道理了。这种“懂道理”的能力就是涌现能力。
LLM 也正在向多模态的方向发展,这意味着它们不仅可以理解和处理文本,还可以理解和处理图像、音频和视频。
下图展示了不同的生成式AI:
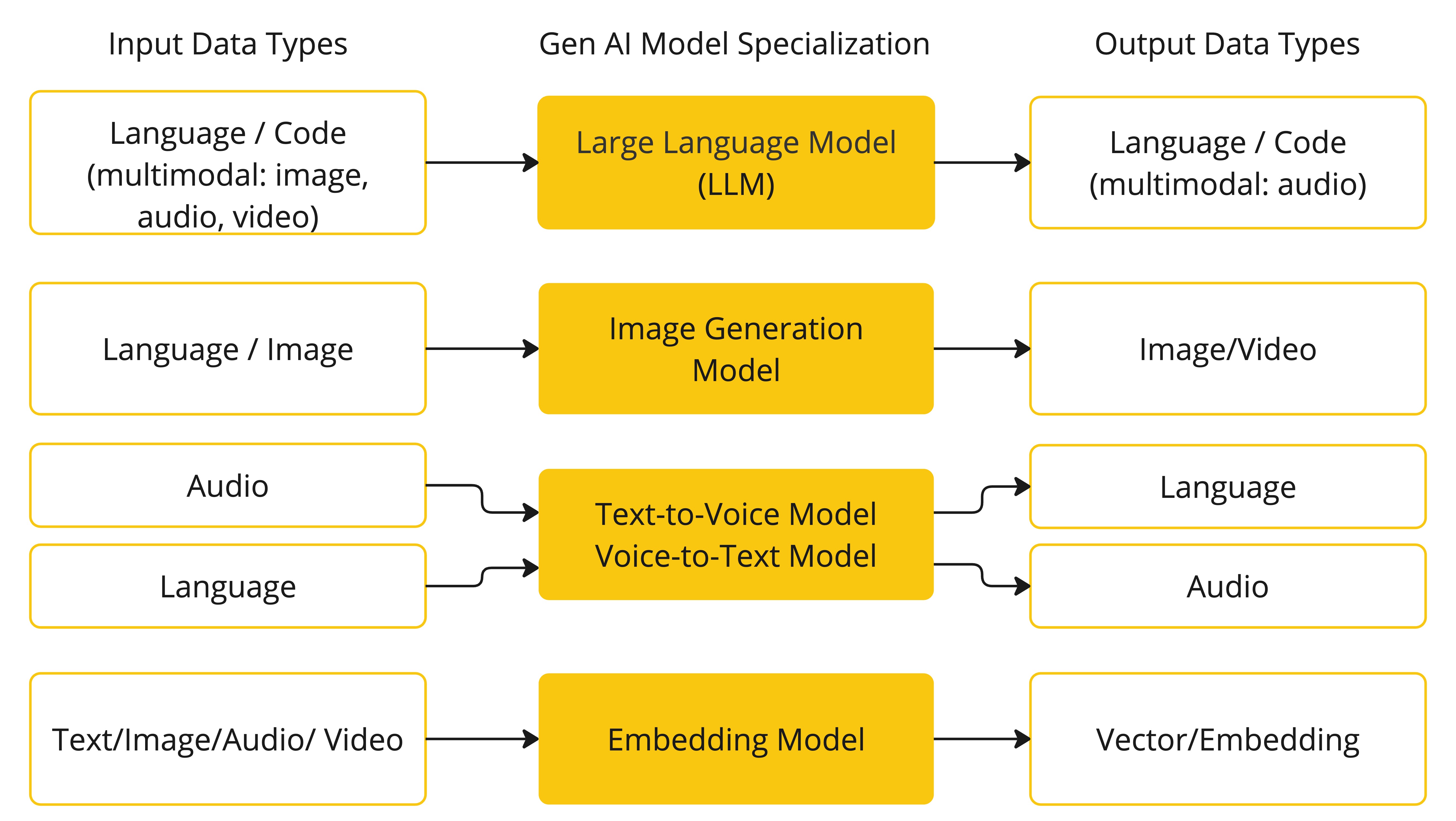
图源:https://docs.spring.io/spring-ai/reference/1.0/_images/spring-ai-concepts-model-types.jpg
3. LLM的工作原理
3.1 工作流程
LLM,大语言模型本质上是一个概率预测器,其核心任务是根据已经出现的文字,预测下一个最可能出现的字符(Token)。
在常用的大语言模型问答系统中,通常我们输入一段话,然后大模型不断预测下一个词,当大模型认为需要结束时,就完成输出。
假如我们给大模型输入:天上的月亮像,大模型获取到输入,开始预测下一个词,此时有以下候选词及概率:
“圆盘”:60%,“小船”:20%,“镰刀”:10%,“月饼”:2%......
此时大模型随机选择一个词,假设大模型选中了“圆盘”。之后,大模型把选中的词拼接到原始输入后,形成新的输入:天上的月亮像圆盘,又开始下一轮的输入及输出,整个过程不断循环,输出内容越来越长。
最终,在某一次大模型的预测中,出现概率最高的那一项变成了**“[结束符号]”**,大模型就终止以上流程,完成输出。
以上流程解释了为什么我们在大模型问答系统中,会看到单词是一个一个出现的,这就是大语言模型的工作原理。
3.2 工作流程技术解释
接下来从技术的角度来解释大模型的工作流程。
3.2.1 词元化-Tokenization
首先理解Token(词元)的概念:模型处理的最小单位。它不一定是单词,可能是词根或字符组合(如 BPE 算法),例如,在GPT 5.x模型中,“你好”是一个词元,"hello"是一个词元:
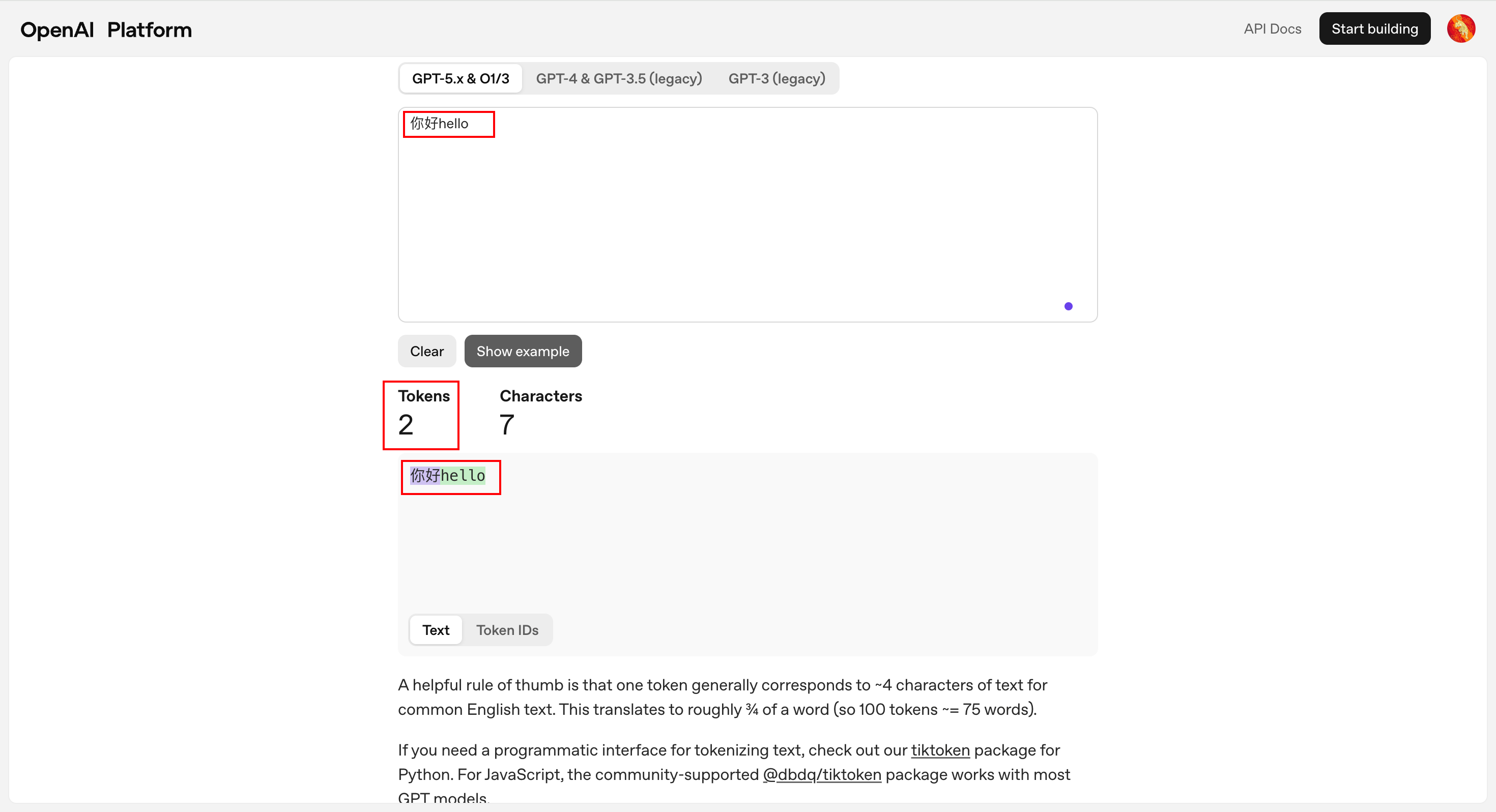
参考资料[3]的网站可以计算词元
在大模型中,每个词元都有一个唯一的ID,例如“你好”对应的ID是177519,“hello”对应的ID是24912。大模型有一个词表,对应着所有的词元及其ID。
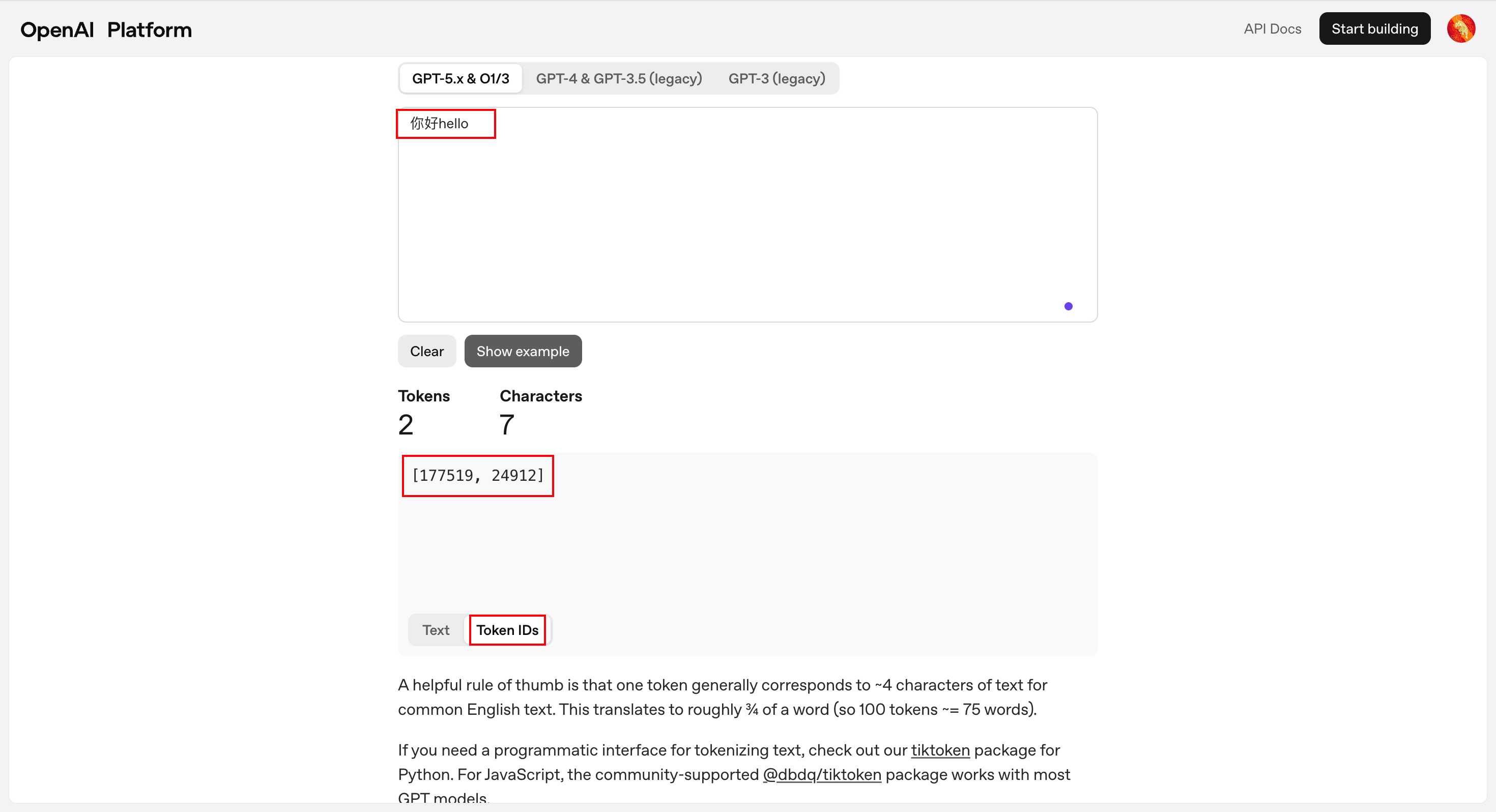
大模型工作的第一步,就是把输入次元化,也就是把输入转换成词元ID列表,例如:
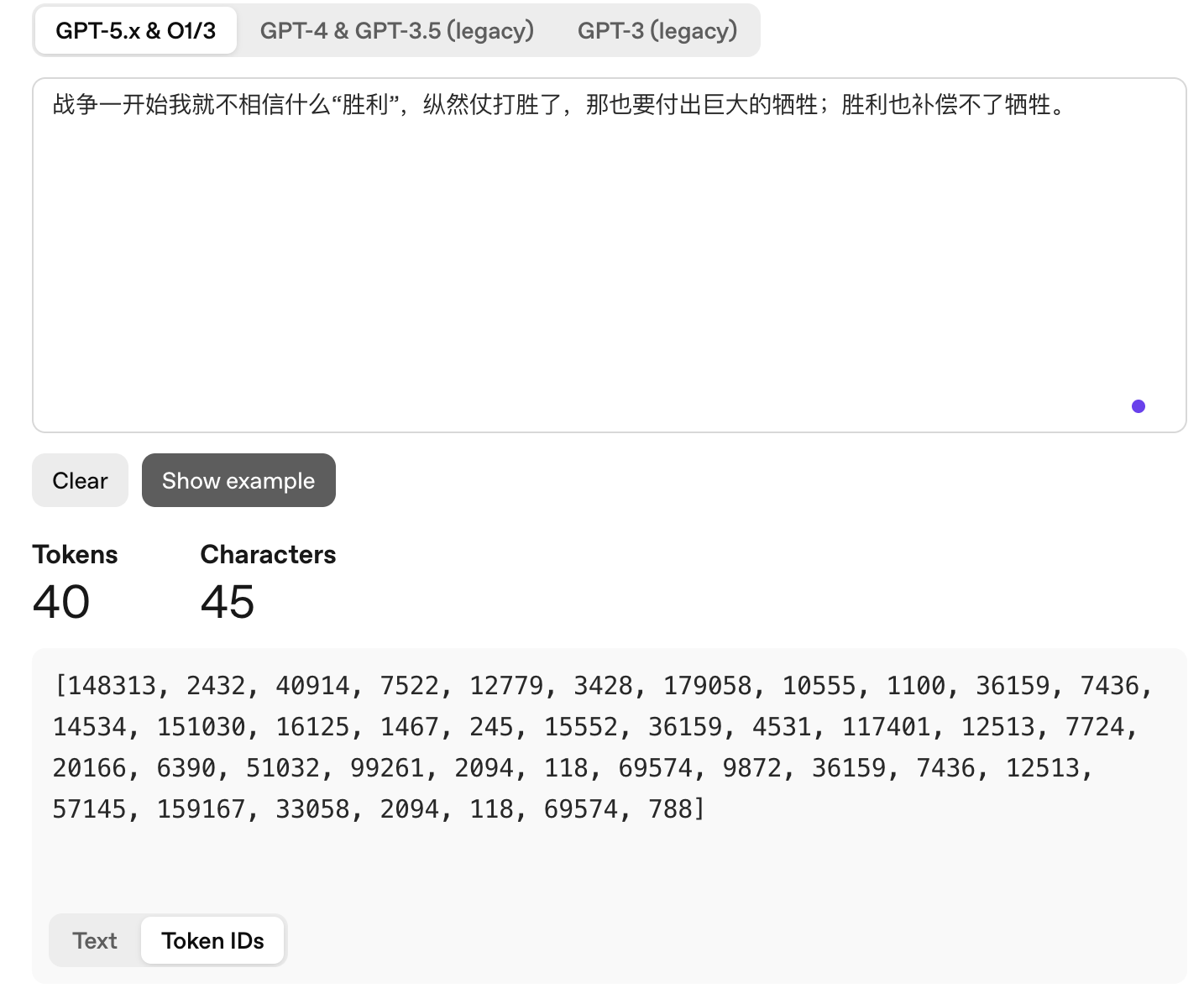
文字选自《昨日的世界》· 茨威格
3.2.2 向量化-Embedding
经过词元化后,我们得到的词元ID列表是没有语义的,只是简单的数字,也就是说,大模型不知道48091(猫)这一个词元ID表示什么意思,需要给这个词元赋上意义。
在大模型内部,有一个Embedding Matrix,其大小通常是 [词表大小, 隐藏层维度],例如,大模型的词表有15万个词元,隐藏层维度是4096,那这个Embedding Matrix的大小就是150000 x 4096(可以想象有15万行,每一行有4096列)。
当输入词元ID后,例如48091,大模型其实是去这个矩阵里提取第 48091 行的数据。提取出来的不再是一个数字,而是一个包含 4096 个浮点数的列表(向量):
这 4096 个维度分别代表了什么?人类无法直接解读,但在模型的视角里,它们可能代表了:
- 维度 1:是否是生物?(得分高)
- 维度 2:是否有毛发?(得分高)
- 维度 3:是否属于液体?(得分极低)
- 维度 4:......
最终,我们的输入经过向量化后变为了特征矩阵,就有了意义,并且从一维矩阵变为了二维矩阵,假设我们的输入是一个长度为10的词元ID列表,经过向量化后,变为了10 x 4096 大小的二维矩阵。
3.2.3 计算分值-Transformer 层与 Logits 输出
经过向量化后,我们得到了特征矩阵,即
这个
- 发生了什么:通过 Self-Attention(自注意力机制),这 10 个向量会互相“打招呼”。
- 原本第 10 个词(比如“月亮”)的向量只包含它自己的意思。
- 经过 Transformer 后,第 10 个词的向量里会“融合”前 9 个词的信息(比如前面提到了“洁白”、“圆盘”)。
- 输出:Transformer 层的输出依然是一个
的矩阵。这叫作“上下文相关的嵌入”(Contextualized Embeddings)。
经过Transformer层后,大模型就开始计算词元得分。
模型会从 Transformer 输出的
大模型还有另一个巨大的矩阵,通常叫作 Language Model Head。它的维度和之前的 Embedding Matrix一样,是 [隐藏层维度, 词表大小],例如 [4096, 150000]。
模型把这个
现在,模型得到了一个包含 15 万个数字的列表。
- 这 15 万个数字就是每个词元的得分 (Logits)。
- 每个位置的索引对应词表里的一个词,例如:
- 索引 500 的分值是 15.2(假设500表示的词元是“像”);
- 索引 800 的分值是 1.1(假设800表示的词元是“苹果”);
3.2.4 缩放分布形态-Temperature
在进入概率转化之前,temperature (
计算公式:
技术影响:
当
:拉大分值差距,使得高分更高,低分更低。 例如 T =。0.1,词元“像”的原始得分是15.2,计算后的得分为152;词元“苹果”的原始得分是1.1,计算后得分为11。
与原始分数相比,经过缩放后,词元之间的差距拉大了(差距从15.2-1.1=14.1变为了152-11=141,差距变大了)。
当
:缩小分值差距,分布变得平坦。 例如T = 2,词元“像”的原始得分是15.2,计算后的得分为7.6;词元“苹果”的原始得分是1.1,计算后得分为0.55。
与原始分数相比,经过缩放后,词元之间的差距变小了(差距从15.2-1.1=14.1变为了7.6-0.55=7.05,差距变小了)。
3.2.5 归一化为概率-softmax
为了让采样器能工作,必须将 Logits 转化为总和为 1 的概率分布。
通过指数化运算,原本微小的分值差距被转化为显著的概率差异。此时,词表中的每个词都有了一个 0 到 1 之间的概率值。
3.2.6 动态截断-Top_p
每个词元都有了一个 0-1之间的概率值后,大模型并不是选择概率值最大的那个词元(这样就没有创造性和多样性了,对于每次一样的输入,必然会产生一样的输出),而是随机选择。但是,如果大模型选到了概率及其低的词元,最终可能会造成整个结果走向越来越偏。
因此,为了防止模型在长尾分布中抽到极其离谱的词(虽然概率低,但在长文本中总会遇到),使用 top_p 进行过滤。
逻辑:将词表按概率从高到低排序,逐个累加概率,直到总和达到
最终,选中的词元才能进入候选词列表,然后大模型从候选词列表中再选出下一个词元。
3.2.7 采样与自回归 -Sampling & Autoregression
最后,采样器根据 top_p 过滤后的概率分布进行加权随机抽样,选出一个 Token ID:
- 解码 (Decode):将抽中的 ID 转回文本进行输出,也就是在网页中看到出现的下一个单词;
- 拼接 (Append):将该 Token 拼接到原始输入序列的末尾;
- 循环 (Loop):将更新后的序列重新喂给模型,开始下一次推理,这就是自回归生成;
- 结束(End):当大模型经过多轮循环后,最终某个特殊词元结束符的概率最高,因此大模型选中该词元后,整个流程结束;
由于有自回归生成,所以每次大模型加上新词后,都需要重复计算,如果没有缓存,那么在前一轮计算过的词元,还需要再次计算,因此,为了提高计算速度,需要将之前计算过的词元结果缓存起来,保存在内存中,这就是KV cache的作用,但是带来的副作用就是显存占用明显增加,并且也限制了模型上下文的大小。
3.3 训练过程
目前业界主流的训练流程通常分为三个阶段:预训练 (Pre-training)、指令微调 (SFT) 和 人类反馈对齐 (Alignment)。
3.3.1 预训练 (Pre-training)
这是最耗时、最烧钱的阶段(占据 90% 以上的算力)。
- 目标: 让模型学习语言的规律、常识和基础逻辑。
- 数据: 海量的无标注文本,包括整个互联网的网页(Common Crawl)、代码仓库(GitHub)、书籍、论文等。
- 训练方式(自监督学习): 模型通过遮盖住一段话的后半部分,不断尝试预测下一个词,然后对比标准答案(原句)来调整参数。
- 产出: 基座模型 (Base Model)。它博学多才,但不太听话。如果你问它“怎么写 Java 单例模式?”,它可能不会直接回答,而是给你列出一堆关于设计模式的文章目录。
3.3.2 指令微调(SFT, Supervised Fine-Tuning)
有了博学的基座模型后,我们需要教它如何“对话”和“听指令”。
- 目标: 将“接龙高手”转化为“对话助手”。
- 数据: 高质量的指令对(Instruction-Response)。比如:
- 指令: “请把这段 Java 代码优化一下。”
- 回答: “好的,这段代码可以通过使用 Optional 来避免空指针……”
- 训练方式: 就像老师带着学生做题,明确告诉模型:看到这种问题,你应该这样回答。
- 产出: 指令微调模型 (Instruct/Chat Model)。它已经可以很好地回答问题,并具备了初步的对话能力。
3.3.3 人类反馈对齐 (Alignment)
模型虽然会说话了,但可能产生幻觉、带有偏见,甚至教人做坏事。这一阶段是为了让模型“更像人”。
核心技术:RLHF (Reinforcement Learning from Human Feedback),这是让大模型产生质变的关键,主要分为三步:
- 人类排序: 让模型针对同一个问题输出几个不同答案,由人类标注员按好坏排序。
- 训练奖励模型 (Reward Model): 训练一个专门打分的“小模型”,用来模拟人类的喜好。
- 强化学习 (PPO/DPO): 让大模型在奖励模型的监督下不断进化,尽可能拿高分。
4. LLM参数
在通常使用的大语言模型问答系统中,我们是没有办法调整模型参数的,需要通过API使用或者通过模型提高公司的实验平台进行调整。
可以使用Google AI Studio进行调整,如参考资料[4]。
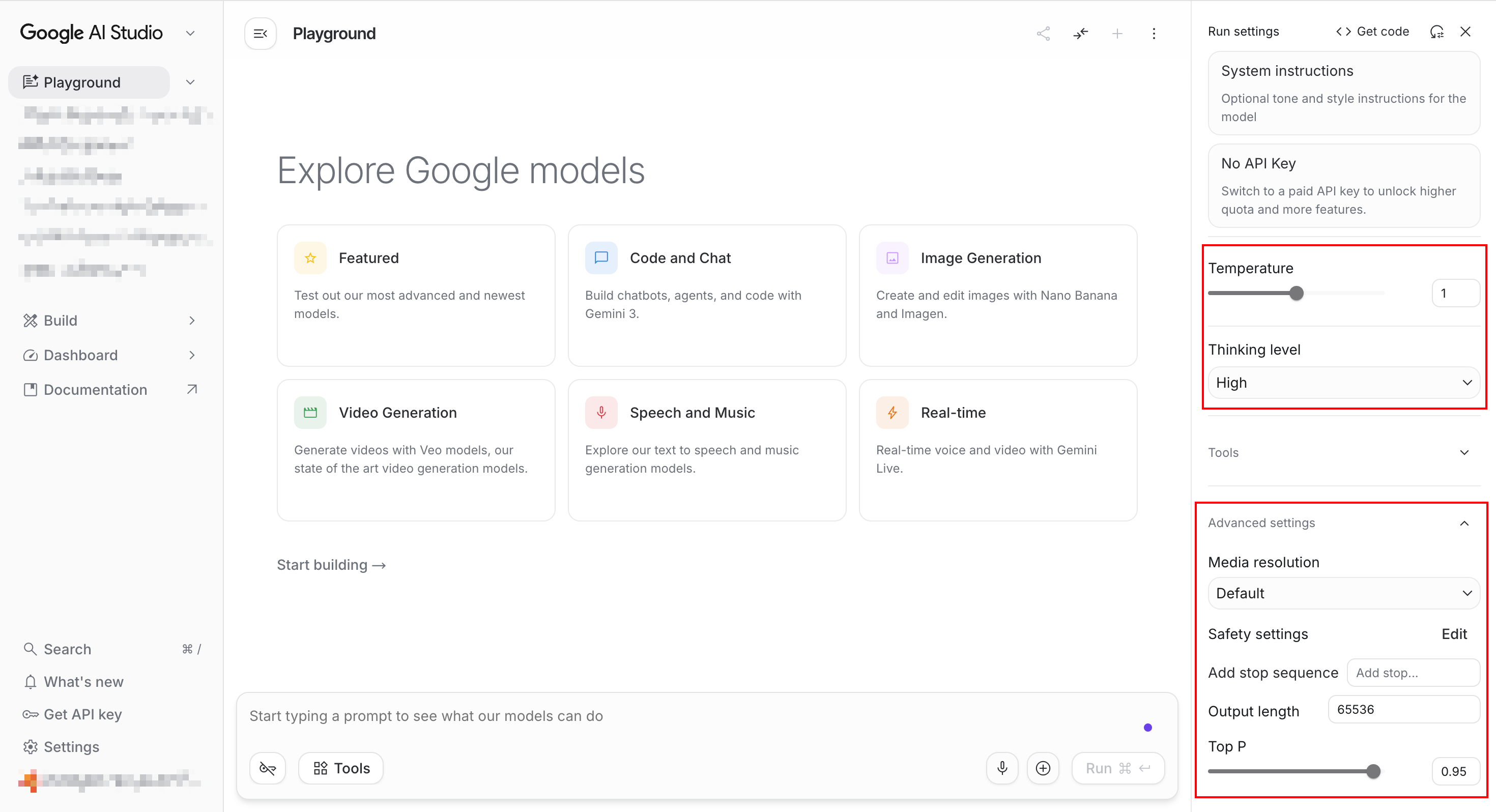
4.1 temperature
在之前了解的大模型工作流程中,temperature(温度)主要用于缩放词元得分。
简而言之,温度越低,结果就越具有确定性,即总是选择概率最高的下一个 token。提高温度可能会导致更多的随机性,从而鼓励生成更多样化或更具创造性的输出。
就应用而言,对于基于事实的问答等任务,使用较低的温度值,以鼓励更具事实性和简洁的回答。对于诗歌生成或其他创意任务,增加温度值可能会更有利。
在Google AI开发文档中指出,如果温度为0(这在数学上是没有意义的,因为除数不能为0),在工程上,意味着选择下一个词元时,总是选择概率最高的。
TIP
Note: When using Gemini 3 models, we strongly recommend keeping the temperature at its default value of 1.0. Changing the temperature (setting it below 1.0) may lead to unexpected behavior, such as looping or degraded performance, particularly in complex mathematical or reasoning tasks.
在Google AI 文档中提示,强烈建议将temperature设置为默认值1,否则在复杂的数学或推理任务中,可能会导致死循环或性能下降。
4.2 top_k
当词元得分经过归一化后得到每个词元的概率,然后词元按照概率从高到低进行排序。
top_k参数表示有多少个词元进入到候选集中。如果top_k为1,表示每次只有概率最高的词元进入候选集,也就是说结果更具有确定性;如果top_k为3,表示每次是三个概率最高的词元进入候选集。
词元经过top_k筛选之后,才会进入top_p筛选。
4.3 top_p
当经过top_k筛选后,候选集中的词元还需要经过top_p筛选,也就是说候选词元的累积概率超过或等于top_p之后,剩下的词元被丢弃。
例如,现在有A、B、C三个词元,概率分别为0.3,0.2,0.1,top_p的值为0.5,那么意味着只有A和B进入最终的候选集,词元C被丢弃,大模型从最终的词元候选集中再选择下一个词元。
4.4 max length
max length/output length/Max output tokens,都是指在一次回答中,大模型最多能输出多少个词元。限制单词输出词元上线,可以阻止模型输出太长的内容或无关的内容,帮助节省费用。
1个词元大约为4个字符(A、B等单字符),100个词元大约为60-80个单词。
4.5 stop sequences
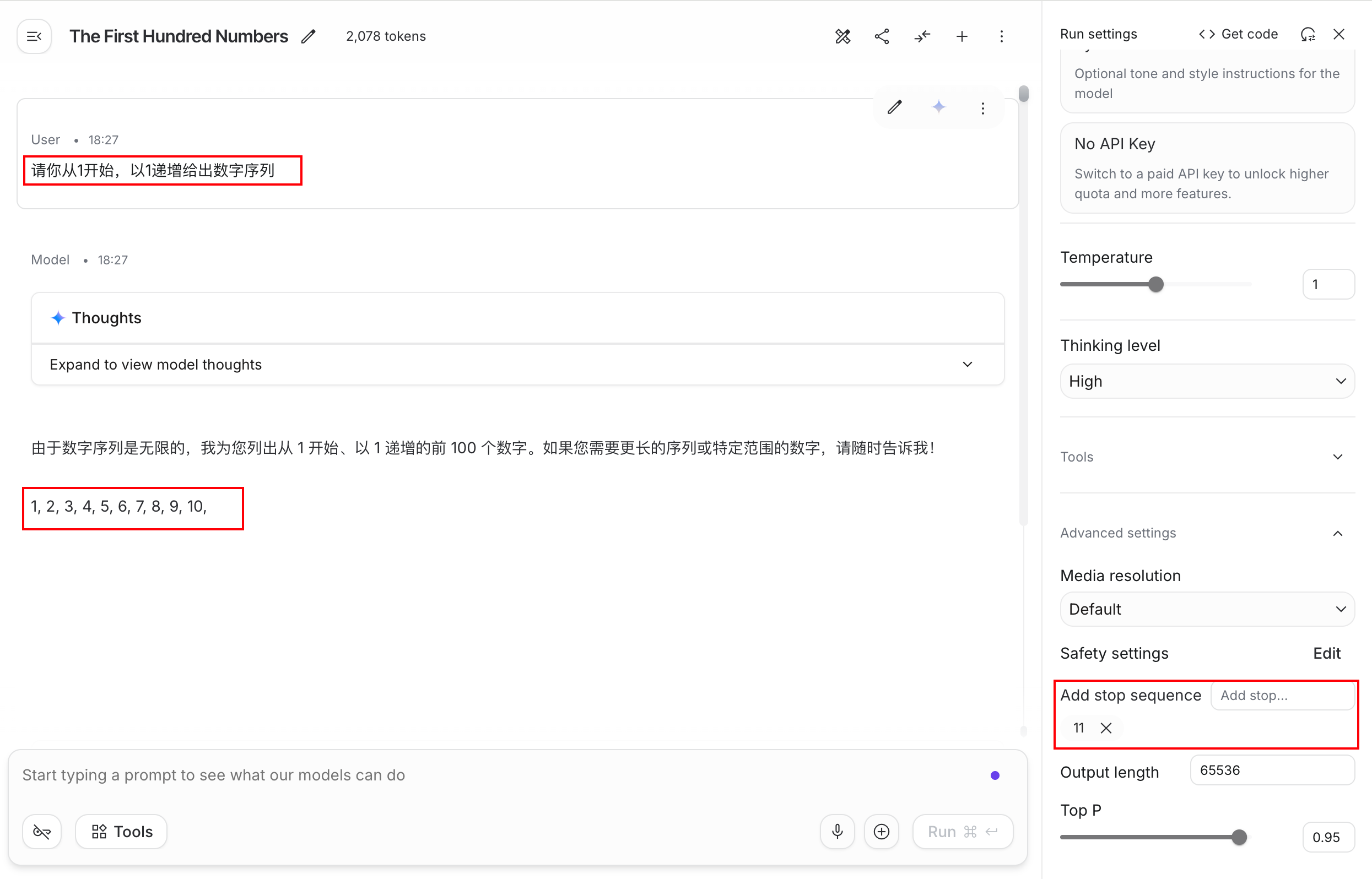
停止词序列,是预先设定的一组特定的字符串,当模型输出的下一个词元包含设定的停止词时,就会停止生成,和max length一样,停止词序列也是用来限制模型输出过长内容的。
例如,在Google AI Studio 中,设置停止词为11,然后发送以下内容:
txt
请你从1开始,以1递增给出数字序列会发现模型只会输出1-10:
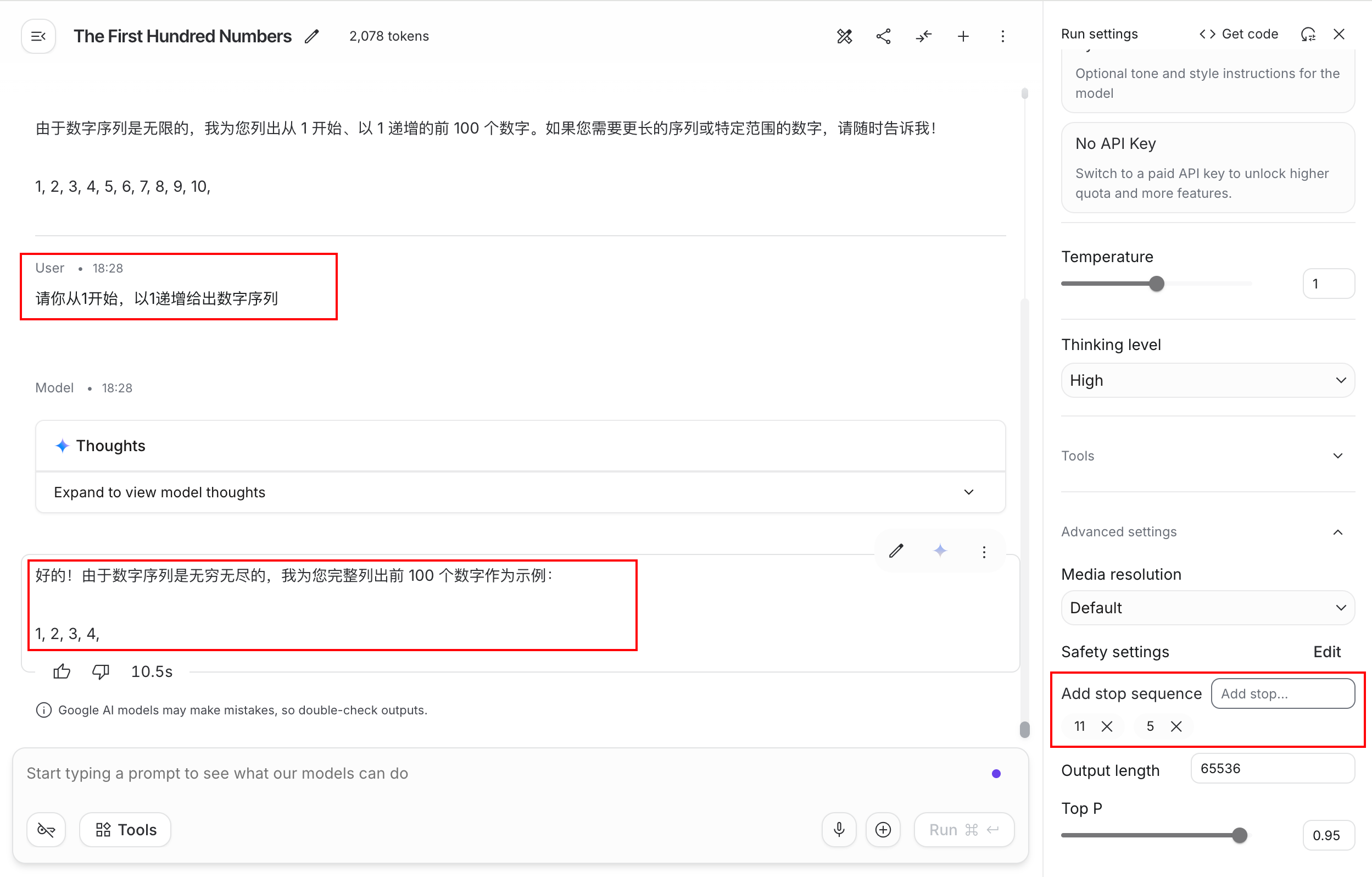
然后,再向停止词序列中添加5,再次提问相同的问题,结果发现只会输出1-4了:
4.6 Frequency Penalty
Frequency Penalty,频率惩罚,也就是说如果一个词出现的次数越多(在用户输入和回答中),它被惩罚得就越重,得分越低,可以理解为:
它非常针对那些高频出现的单个词。比如模型一直重复说“而且...而且...而且...”,频率惩罚会随着“而且”出现的次数增加,不断调低它的得分。
用途:彻底消除词语级别的重复。
4.7 Presence Penalty
Presence Penalty,存在惩罚,也就是说只要这个词在文中出现过,不管出现 1 次还是 100 次,扣分力度都一样,可以理解为:
它更多是针对主题或短语。它会鼓励模型去聊一些之前没提到过的新词。
用途:提升文本的多样性和创意性。它更倾向于让模型“换个话题”或“换个表达方式”,而不是纠结于某个词写了几次。
关于频率惩罚和存在惩罚的应用场景及其设置:
| 场景 | Frequency Penalty | Presence Penalty | 理由 |
|---|---|---|---|
| 严谨的代码生成 | 0.0 | 0.0 | 代码中 List, public, return 等词必须高频重复,惩罚会导致语法错误。 |
| 文档总结 | 0.1 - 0.2 | 0.0 | 略微减少啰嗦,但要保证专业术语(如药品名)的准确性。 |
| 创意写作/写诗 | 0.5 | 0.5 | 强制模型换词、换意境,避免陷入死循环。 |
| 解决“复读机”问题 | 1.0+ | 0.0 | 当模型开始疯狂重复同一句话时,这是最猛的药。 |
参考资料
[1] https://cloud.google.com/learn/what-is-artificial-intelligence?hl=zh-CN
[2] https://docs.spring.io/spring-ai/reference/1.0/concepts.html
[3] https://platform.openai.com/tokenizer
[4] https://aistudio.google.com/
[5] https://www.promptingguide.ai/introduction/settings
[6] https://ai.google.dev/gemini-api/docs/prompting-strategies#model-parameters