Appearance
Agent Skills
本文介绍Agent Skills规范、使用、创建以及Agent对Skills的实现支持。
1. Agent Skills是什么
要明白Agent Skills(智能体技能)是什么,就要先明白AI Agent(AI智能体)是什么。
早期的AI系统,更多是AI问答系统,用户提出问题,AI作出回答。AI Agent即为AI大脑装上了”手“,有了执行能力,使用场景如下:
个人助理: “帮我调研一下这 5 家公司的财务状况,并写一份对比报告发到我邮箱。”(Agent 会自主搜索、阅读、撰写、发送邮件);
软件开发: 像 Devin 这样的 AI 程序员,可以根据一个需求描述,自主编写代码、调试 Bug 并部署上线;
企业自动化: 自动处理报销流程,根据收据信息提取数据、校验合规性并提交审批;
虽然目前的大语言模型已足够强大,但是仍然存在限制:
- 时空限制:LLM训练数据是有截止日期的,但通过“搜索技能”,LLM可以获取最新的信息;模型训练数据都是互联网公开数据,对于企业、组织、个人私有数据,LLM是无法感知到的,所以为LLM提供相关私有数据获取技能,LLM也能获取完整数据;
- 幻觉:面对复杂的数学题,模型容易产生幻觉(Hallucination),但如果它具备“运行代码”的技能,就可以通过计算得到 100% 正确的结果;
- 流程化:对于特定领域的问题,人们总结出了一份标准流程,但LLM并不知道这个标准流程,此时可以提供相关问题解决流程的技能,那LLM就能遵循标准流程进行处理;
所以,Agent Skills是指 AI Agent 为了完成特定任务而具备的一系列功能模块或工具调用能力。
2. Skills规范
一个Agent Skills就是一个文件夹,其中必须包含SKILL.md文件,还可以包含其他可选文件,组织形式例子如下:
txt
skill-name/
├── SKILL.md # Required: metadata + instructions
├── scripts/ # Optional: executable code
├── references/ # Optional: documentation
├── assets/ # Optional: templates, resources
└── ... # Any additional files or directories2.1 SKILL.md格式
SKILL.md必须包含YAML frontmatter,字段如下:
| 字段名 | 是否必须 | 限制 |
|---|---|---|
name | Yes | 最多64个字符,只允许小写字母、数字、连字符-,开头和结尾不能是连字符。连字符不能连续出现,例如 --不允许。技能名称需要与文件夹名称一致。 |
description | Yes | 最多1024个字段,不能为空。描述该技能的功能和作用时期。 |
license | No | 许可证名称或对许可证文件的引用。 |
compatibility | No | 最多 500 个字符。说明环境要求(预期产品、系统包、网络访问等)。 |
metadata | No | 用于额外元数据的任意键值映射 |
allowed-tools | No | 该技能可能使用的预先批准工具的空格分隔字符串。(实验性) |
例如,YAML frontmatter的最小例子(即只包含name和description):
txt
---
name: skill-name
description: A description of what this skill does and when to use it.
---带有可选字段的例子:
txt
---
name: pdf-processing
description: Extract PDF text, fill forms, merge files. Use when handling PDFs.
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---下面是对一些字段的详细说明和例子:
description:用于描述技能的功能以及作用时期,需要包含特定关键词,以帮助agent识别关联任务。
较好的例子:
yamldescription: Extracts text and tables from PDF files, fills PDF forms, and merges multiple PDFs. Use when working with PDF documents or when the user mentions PDFs, forms, or document extraction.不好的例子:
yamldescription: Helps with PDFs.license:明确了该技能的代码、逻辑或数据可以被谁使用,以及如何使用。
- 开源许可: 如果标记为
MIT或Apache 2.0,意味着其他开发者可以自由地集成、修改和分发这个技能。 - 私有许可: 如果标记为
Proprietary或Private,则表示该技能仅供内部使用,严禁未经授权的第三方调用或二次开发。
建议该字段保持简短,也就是说指明许可证名称或者引用具体的许可证文件,例如:
yamllicense: Proprietary. LICENSE.txt has complete terms- 开源许可: 如果标记为
compatibility:如果该技能有特定的环境要求,则可以在该可选字段中指定,可以表示该技能所针对的特定软件、硬件平台或系统环境、网络环境等,例如:
yamlcompatibility: Designed for Claude Code (or similar products)yamlcompatibility: Requires git, docker, jq, and access to the internetyamlcompatibility: Requires Python 3.14+ and uvmetadata:用于指定额外的元数据信息,以键值对形式指定,AI Agent实现(例如Claude Code、Codex等)可以使用该额外字段,例如:
yamlmetadata: author: example-org version: "1.0"allowed-tools:用于指定该技能允许使用的工具,注意,该项配置是实验性的,不同的AI Agent实现对该字段的支持不同,例如:
yamlallowed-tools: Bash(git:*) Bash(jq:*) Read
在YAML frontmatter之后,就是Markdown格式的内容体。对于内容体,没有严格要求的格式规范,只需要写下能帮助Agent有效执行任务的内容即可,推荐以下内容:
执行步骤;
输入输出示例;
常见边缘情况:边缘情况指的是那些在合法输入范围内,但处于极值或特殊组合的情况。系统逻辑依然在运行,但如果不特殊处理,结果往往不符合预期。
异常情况通常指由于外部不可抗力或系统故障导致流程中断的情况。
维度 边缘情况 (Edge Cases) 异常情况 (Exceptions) 性质 逻辑上的“极端” 流程上的“中断” 系统状态 运行中,但可能输出错误结果 已崩溃或报错,无法继续 解决思路 优化 Prompt 或逻辑判断。通过更完善的指令引导模型处理极端值。 容错处理 (Error Handling)。设置重试机制、超时切断或返回友好的错误提示。 例子 用户名字叫“None”(导致代码解析为 null) 服务器宕机了
注意,当LLM决定激活该技能时,Agent会完全加载SKILL.md的内容。如果SKILL.md文档过长,会造成上下文负载过重,因此考虑将内容拆分到引用文档中,保持SKILL.md的内容在500行以内。
2.2 scripts文件夹
scripts文件夹中包含着Agent可以执行的代码/脚本。
根据Agent实现,支持的脚本语言也不相同,通常使用Python、bash以及Javascript语言。
好的脚本语言应该满足以下要求:
自包含性以及清晰的依赖:
自包含性是指尽量使用该编程语言(如 Python 或 JavaScript)的标准库,而不是非要安装一大堆第三方包。例如,如果只需要解析一个简单的 JSON,用 Python 自带的
import json(自包含),而不是去装一个复杂的第三方解析库。这样当这个 Skill 被分发给其他用户或者部署到云端服务器时,不会因为缺环境而直接报错。如果脚本功能很复杂,必须用到第三方库(比如处理图像需要
Pillow,访问网页需要requests),那必须明确交代清楚。在skill.md或脚本头部写明需要的依赖,例如:python# Required Libraries: # pip install requests # pip install beautifulsoup4清晰的报错信息:要求在代码逻辑中捕获异常并输出具体的报错内容,例如:
pythontry: # 业务逻辑 except FileNotFoundError: print("错误:未找到指定的配置文件 'config.json',请确保文件存在于根目录。")不要这样写:
pythontry: # 业务逻辑 except FileNotFoundError: print("error")优雅处理边缘情况:在代码中考虑周全,提前处理各种边缘情况,例如,处理用户输入的数字,先判断是不是空值、是不是负数等;
2.3 references文件夹
references文件夹中包含Agent需要时可以获取的额外文档。例如:
REFERENCE.md(技术手册): 存放纯技术细节。比如 API 的具体参数定义、复杂的逻辑算法说明、或者某些特定代码的执行限制。当 Agent 需要写代码或调用接口时,它会看这个。FORMS.md(格式模版): 存放标准的输出或输入结构。比如“周报模版”、“财务申请表 JSON 结构”等。当 Agent 需要生成规范化数据时,它会参考这个。- Domain-specific files (领域知识): 存放具体的业务规则。
finance.md: 存放公司的报销政策、税率计算规则。legal.md: 存放合规性条款、合同避雷指南。
不要把所有东西都塞进一个巨大的 README.md 里。
- 为什么要小? LLM的上下文窗口是有限且昂贵的。如果把财务、法律、技术全部写在一个文件里,Agent 每处理一个简单问题都要读完这个文件,既费钱又容易让它分心(注意力漂移);
- 做法: 每一个参考文件只讲一件事。比如
shipping_rates.md只讲运费,不讲产品规格;
注意在SKILL.md中正确引用需要的参考文件。
2.4 assets文件夹
assets文件夹存放静态资源:
模板文件:文档模板、配置模板等;例如:
weekly_report_template.docx:一个带有公司 Logo 和固定标题(本周进展、下周计划、风险点)的 Word 模版;meeting_minutes.md:会议纪要的 Markdown 格式,包含时间、地点、参会人、议题、待办事项 (Action Items) 等占位符;nginx_site_config.conf:一个预置好的 Nginx 配置模板,Agent 可以根据用户输入的域名自动替换其中的变量;deployment_manifest.yaml:Kubernetes 的部署清单模版;图片:图片、示例等;例如:
workflow_flowchart.png:描述某个业务审批流程的流程图。当用户询问“现在审批到哪一步了”时,Agent 可以参考此图进行解释;system_architecture.svg:系统架构图;ui_mockup_standard.jpg:一个标准的前端页面设计稿。Agent 在生成代码时,可以参考这个图片的风格(色调、间距);defect_samples.jpg:在工业质检场景下,存放各种“次品”的图片样本,帮助 Agent 学习如何识别瑕疵;数据文件:对照表、模式定义等,例如:
iso_country_codes.json:存储全球国家代码与名称的对应关系(如{"CN": "China", "US": "United States"});shipping_rates_2026.csv:2026 年最新的物流运费对照表,包含重量、地区和对应的价格;user_profile_schema.json:定义了用户信息必须包含哪些字段(如 age 必须是整数,email 必须符合格式)。Agent 在存入数据前会用它来做校验;api_payload_spec.yaml:描述了调用某个外部接口时,JSON 报文的具体结构要求;
2.5 渐进式披露
Agent会渐进式地加载技能,只有当某个任务需要更多信息时,Agent才会去拉取具体的信息。因此,技能需要组织良好。
Agent会按照以下顺序拉取信息:
- 元数据:在开始时,Agent会获取每个技能的
name和description元数据字段,大约消耗100 Tokens; - 技能指令:当LLM决定激活某个技能时,Agent会加载完整的SKILL.md内容,因此建议将SKILL.md的内容保持在500行以内,消耗小于5000 Tokens;
- 资源:在需要时,Agent才会拉取
scripts/,references/, 或assets/中的资源;
2.6 引用资源文件
当在SKILL.md中引用资源文件时,使用相对路径:
markdown
See [the reference guide](references/REFERENCE.md) for details.
Run the extraction script:
scripts/extract.py尽量让参考文件只比 SKILL.md 深一个层级,避免深层嵌套。
3. 技能使用
本小节以Cursor为例介绍如何使用Skills。
支持Skills的完整客户端:https://agentskills.io/clients
Cursor参考文档:https://cursor.com/docs/skills
3.1 管理技能
skills库是vercel出品的,用于管理和分发AI技能的NPM命令行工具包。可以使用以下命令安装skills工具包:
bash
npm install -g @vercel/skills但是,更推荐使用npx的方式来使用skills。
npx是随 Node.js 安装时附带的一个包运行器(Package Runner)。它的核心作用是能直接运行 npm 仓库中的工具,而不需要经历“先安装、后使用、再删除”的繁琐过程。
skills工具包提供了以下命令用于管理AI技能:
安装技能
可以查询 https://skills.sh/ 网站获取需要的技能。
如果要安装某个技能,可以使用如下命令:
bash
# 通过owner/repo的简写形式,从Github中获取技能
npx skills add vercel-labs/agent-skills
# 通过Github仓库完整路径获取技能
npx skills add https://github.com/vercel-labs/agent-skills
# 通过指定Github仓库中的某个路径获取具体技能
npx skills add https://github.com/vercel-labs/agent-skills/tree/main/skills/web-design-guidelines
# 通过GitLab路径获取技能
npx skills add https://gitlab.com/org/repo
# 也可以使用git协议获取技能
npx skills add git@github.com:vercel-labs/agent-skills.git
# 从本地获取技能
npx skills add ./my-local-skills例如,我们以 https://github.com/vercel-labs/agent-skills 仓库为例,演示安装技能过程:
首先执行安装命令,会从仓库中拉取技能并显示,提示需要安装哪一个技能:
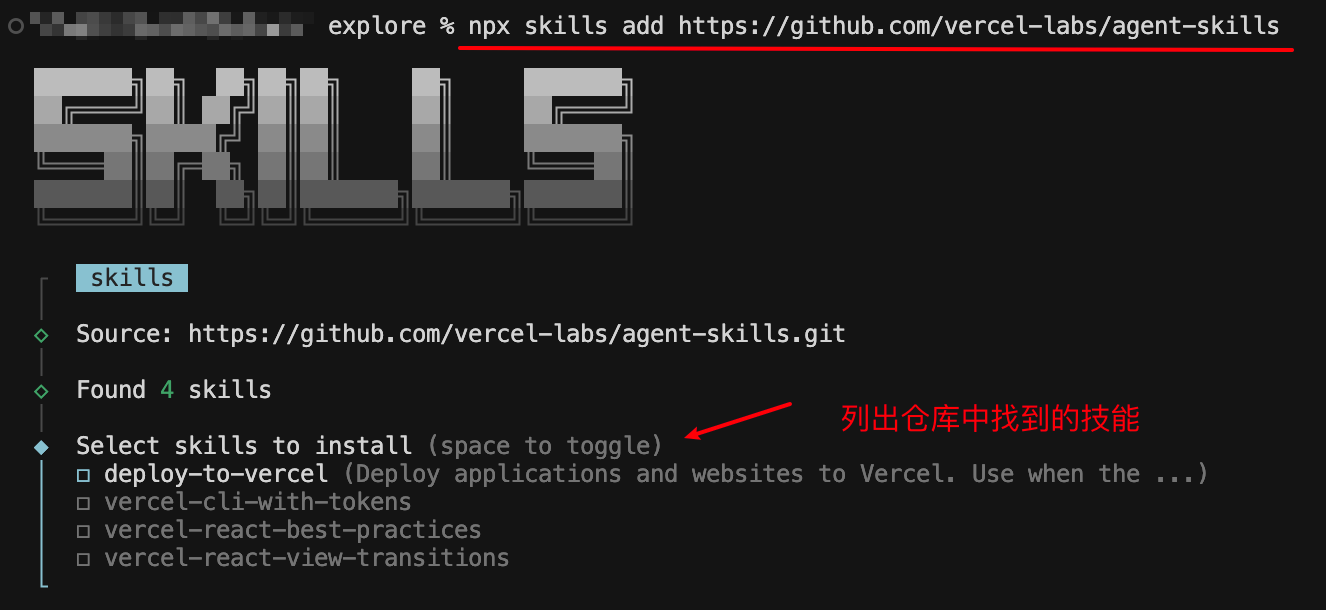
通过空格选中需要安装的技能后,按回车进行下一步,提示需要安装到哪一个Agent实现:
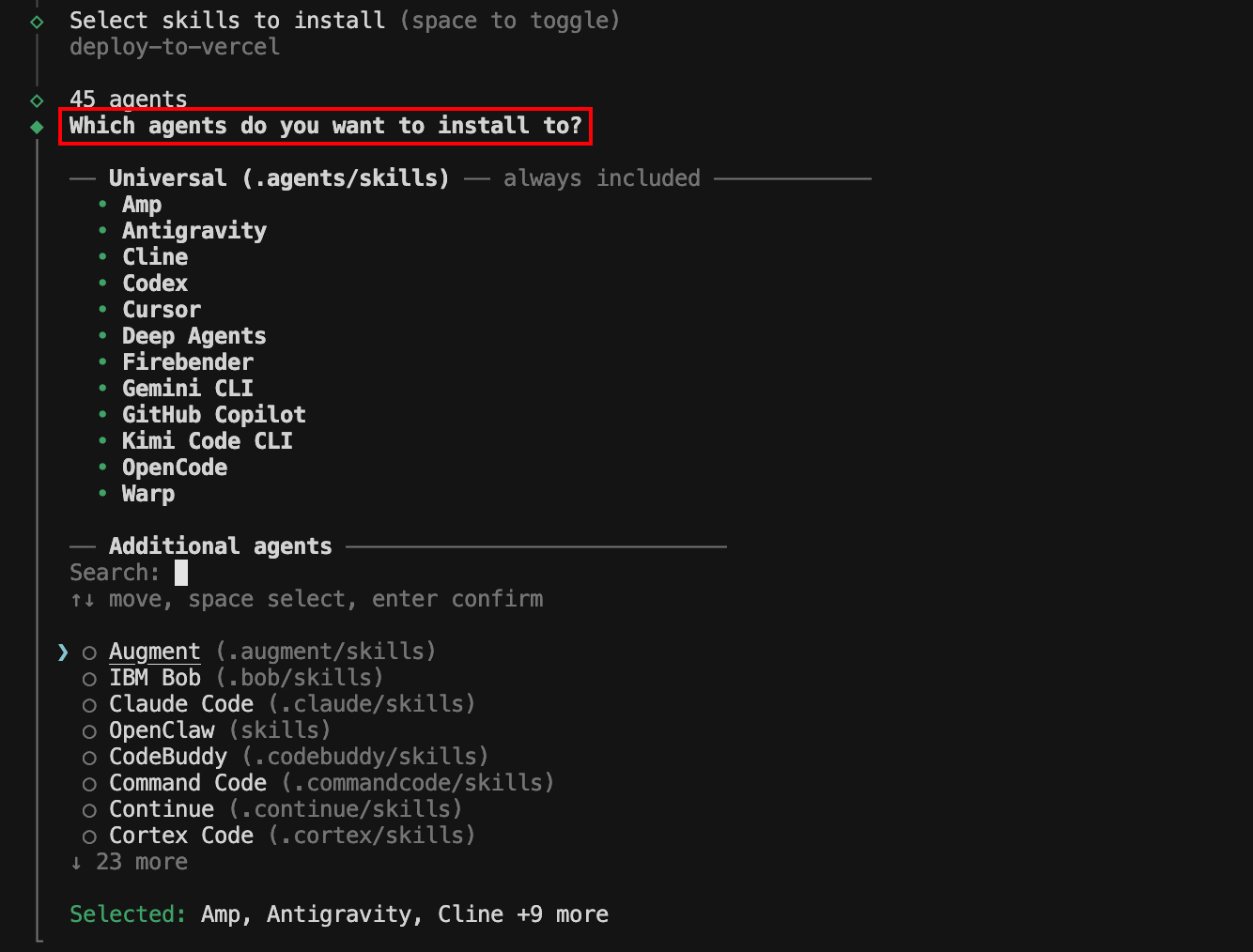
12个Agent实现(包括Codex、Cursor等,竟然默认不包含Claude Code,有点吃惊)默认会安装,可以选择其他Agent实现。
选择了Agent之后,会提示选择安装位置:

有两个安装位置:
- Project:在当前文件夹的
.agents/skills目录下安装,只有当前项目可用; - Global:在用户目录
~/.agents/skills下安装,全局可用;
选择安装位置后,会显示安装位置、技能评估等信息,然后提示是否继续安装:
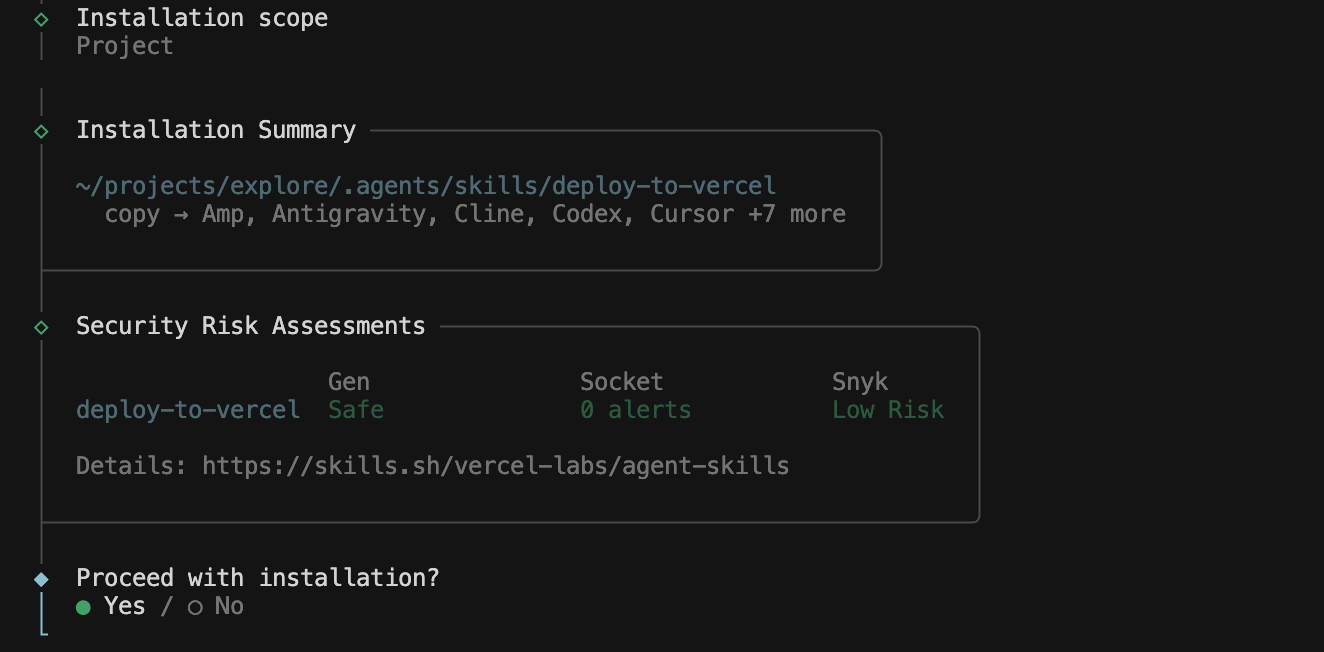
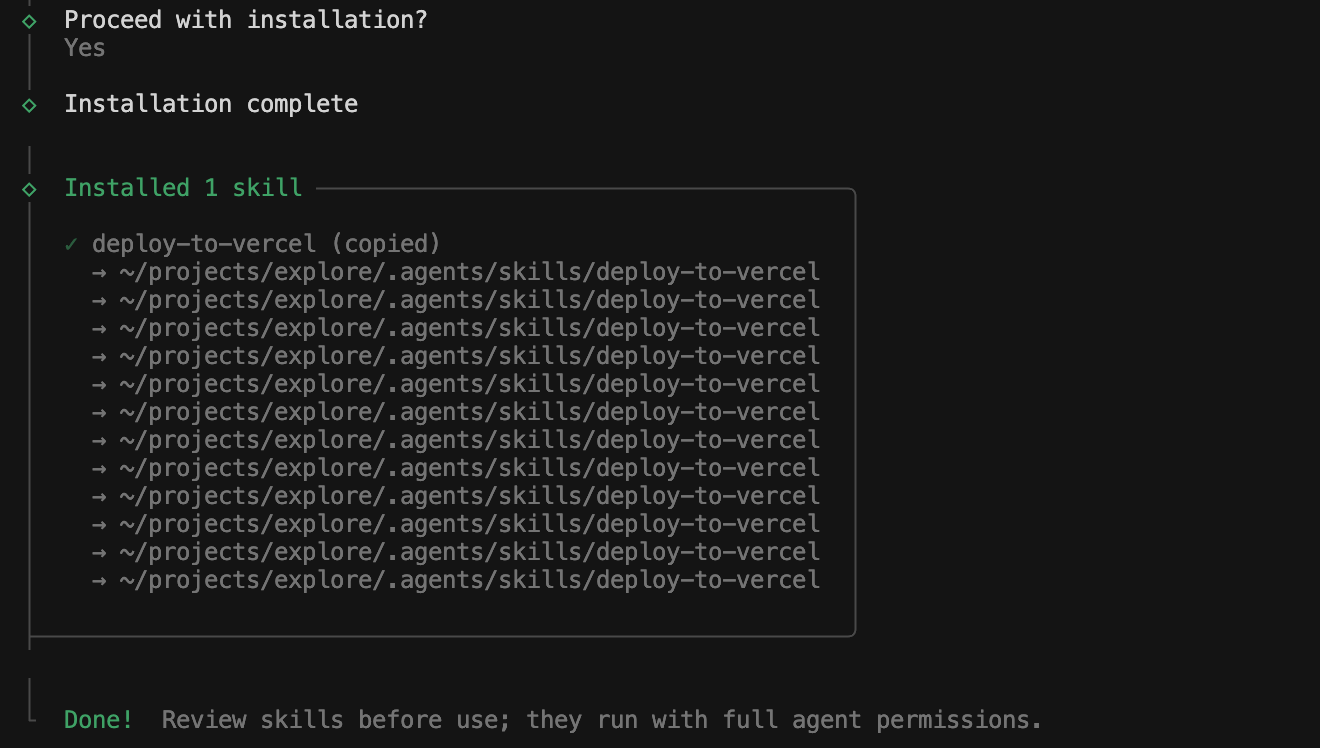
选择Yes后,安装成功:
npx skills add还有以下参数配置:
| 参数 | 说明 |
|---|---|
-g, --global | 全局安装 |
-a, --agent <agents...> | 选择要安装的Agent |
-s, --skill <skills...> | 如果仓库中有多个技能,指定要安装哪个技能 |
-l, --list | 显示可用技能,但是不安装 |
--copy | 指定以copy的方式安装技能,还有以symlink的方式安装 |
-y, --yes | 跳过所有的确认步骤 |
--all | 安装仓库的所有技能到所有Agents |
除了安装技能,skills工具包还提供以下命令,用于管理技能:
| 命令 | 说明 |
|---|---|
npx skills list | 列出当前目录安装的技能,如果要列出全局技能,使用-g参数 |
npx skills find [query] | 搜索技能 |
npx skills remove [skills] | 移除当前目录安装的技能,如果要移除全局技能,使用-g参数 |
npx skills update [skills] | 更新安装的技能 |
npx skills init [name] | 如果要创建自己的技能,使用该命令初始化技能模板 |
更多关于技能管理的命令,参考资料[2]。
3.2 cursor技能使用文档
默认情况下,Cursor会从以下路径加载技能:
| 位置 | 范围 |
|---|---|
.agents/skills/ | Project-level |
.cursor/skills/ | Project-level |
~/.agents/skills/ | User-level (global) |
~/.cursor/skills/ | User-level (global) |
为了兼容性,Cursor也会从以下路径加载技能:.claude/skills/, .codex/skills/, ~/.claude/skills/, ~/.codex/skills/。
当安装好技能后,Cursor会自动从以上路径加载,可以到Cursor Settings -> Rules, Skills, Subagents 设置界面查看安装的技能:
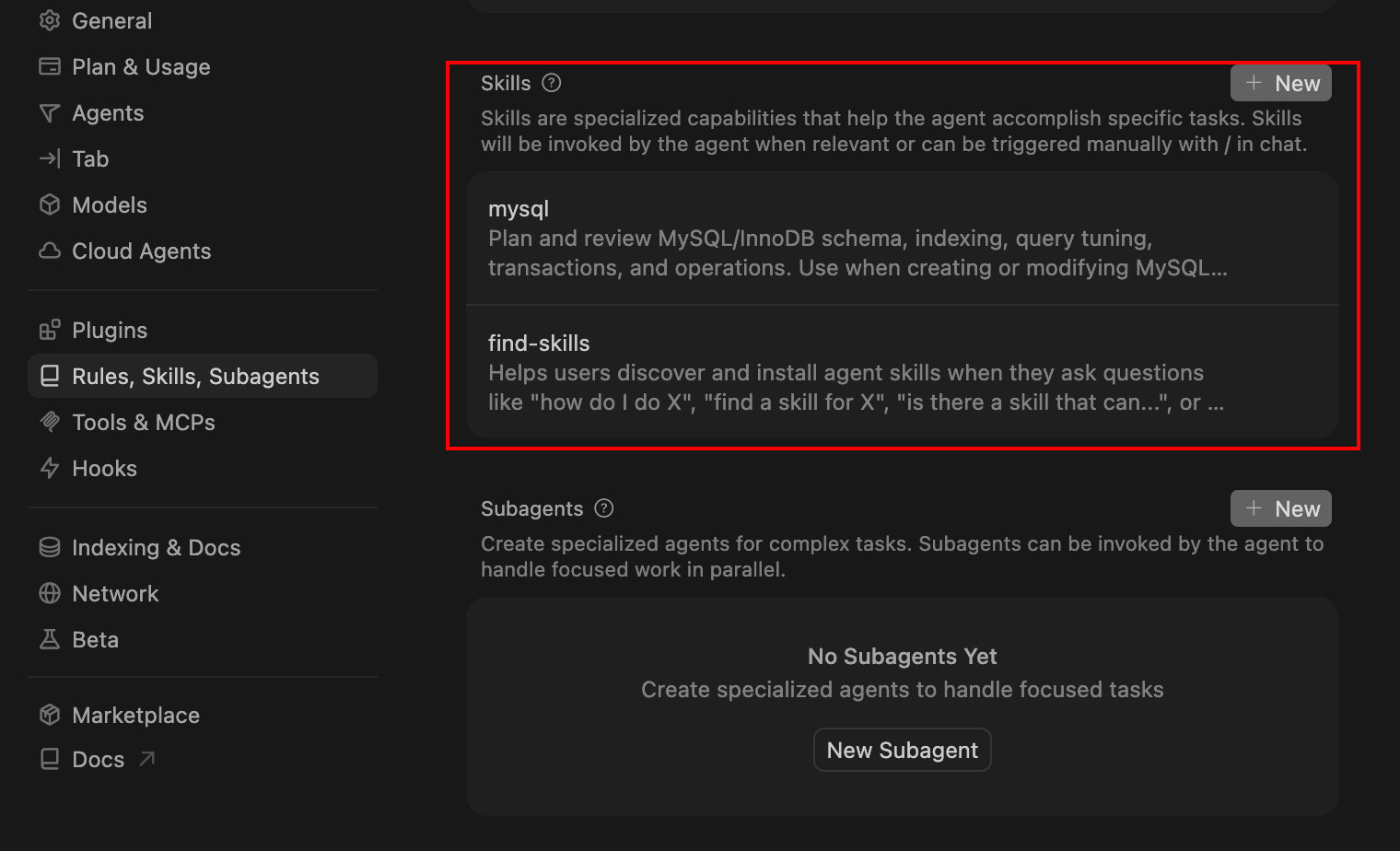
- mysql技能是安装到全局的;
- find-skills技能是安装到当前目录的;
之后,就可以在Cursor中正常使用技能了。
有两种使用技能的方式:
隐式调用:是指Agent自动将安装的技能发送给LLM,之后LLM根据任务相关性调用合适的技能;
显式调用:用户自己通过
/skill-name的方式使用技能;
Cursor会解析SKILL.md中的YAML frontmatter字段,是否有disable-model-invocation配置,如果该配置为true,表示Cursor不会自动把该技能发送给LLM。
3.3 使用技能
我们以find-skills为例,演示如何使用技能。
首先安装该技能:
bash
npx skills add https://github.com/vercel-labs/skills --skill find-skills这里是默认安装到本地目录了。
然后就可以直接使用了,例如:
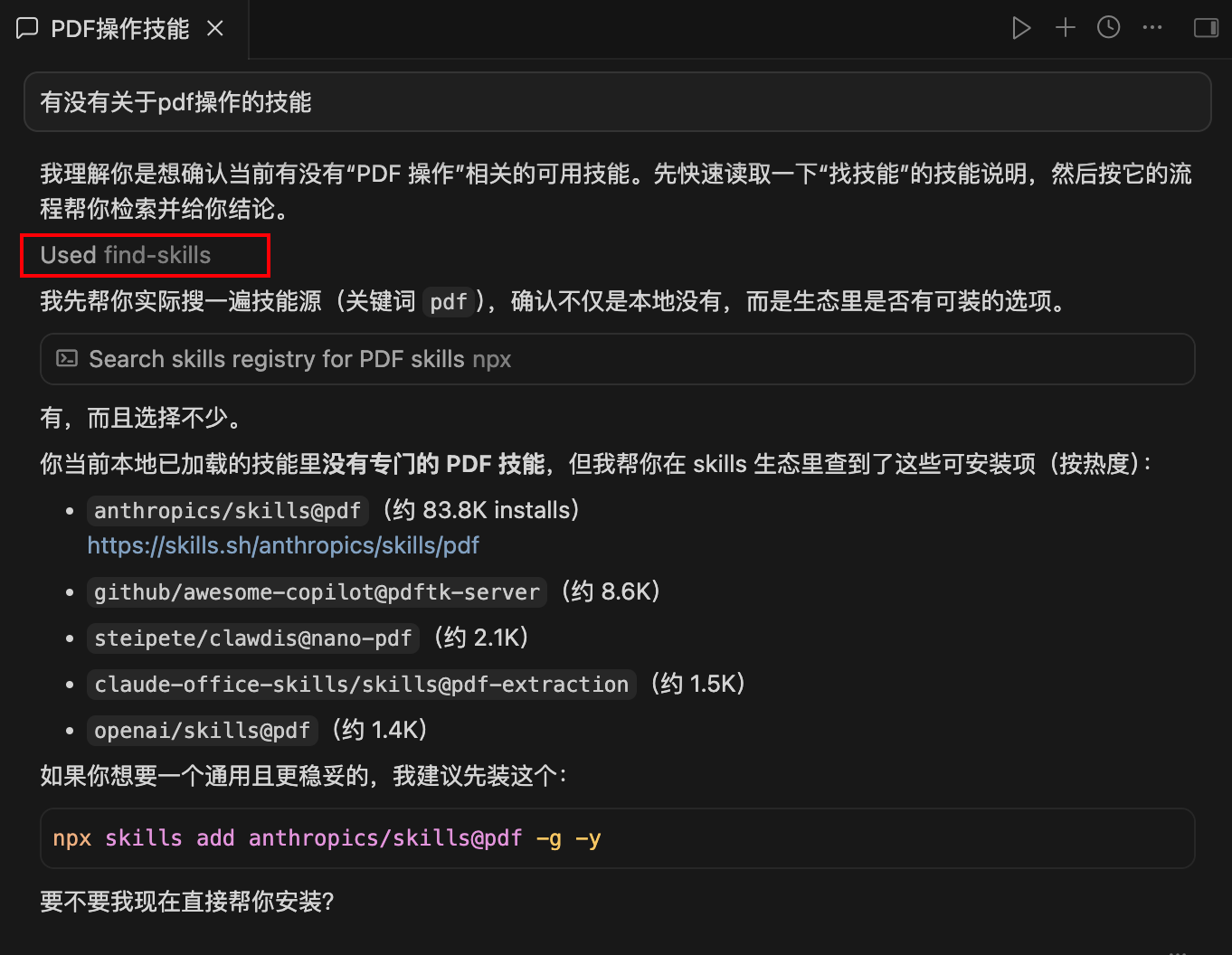
然后,修改find-skills的SKILL.md,在frontmater中加上如下字段:
yaml
disable-model-invocation: true然后新开对话框,查找技能。可以发现LLM没有直接使用安装的find-skills技能,而是先本地搜索了一下,再通过skills工具箱查找技能:
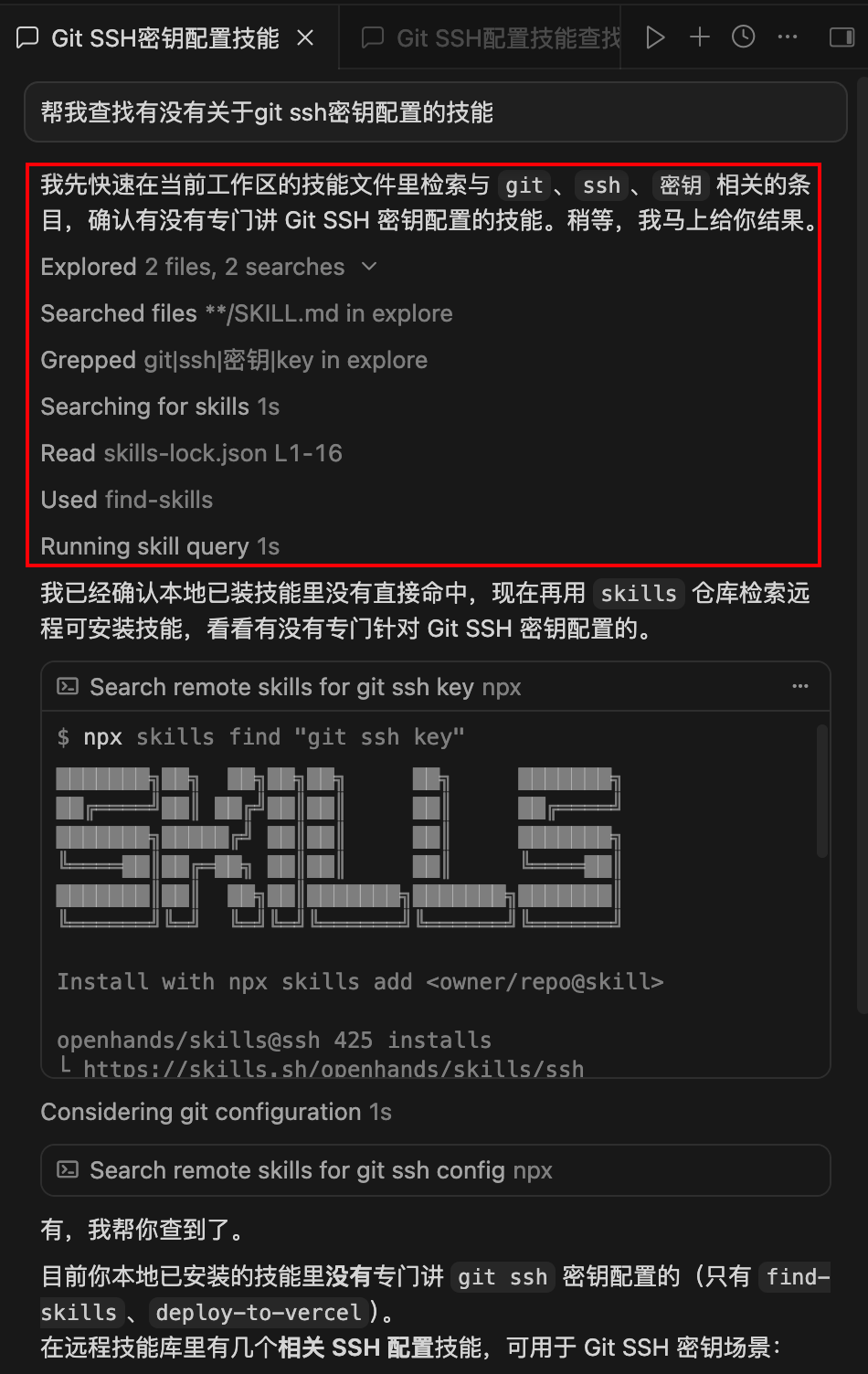
说明disable-model-invocation起效了,cursor并没有直接将安装的find-skills技能发送给LLM。
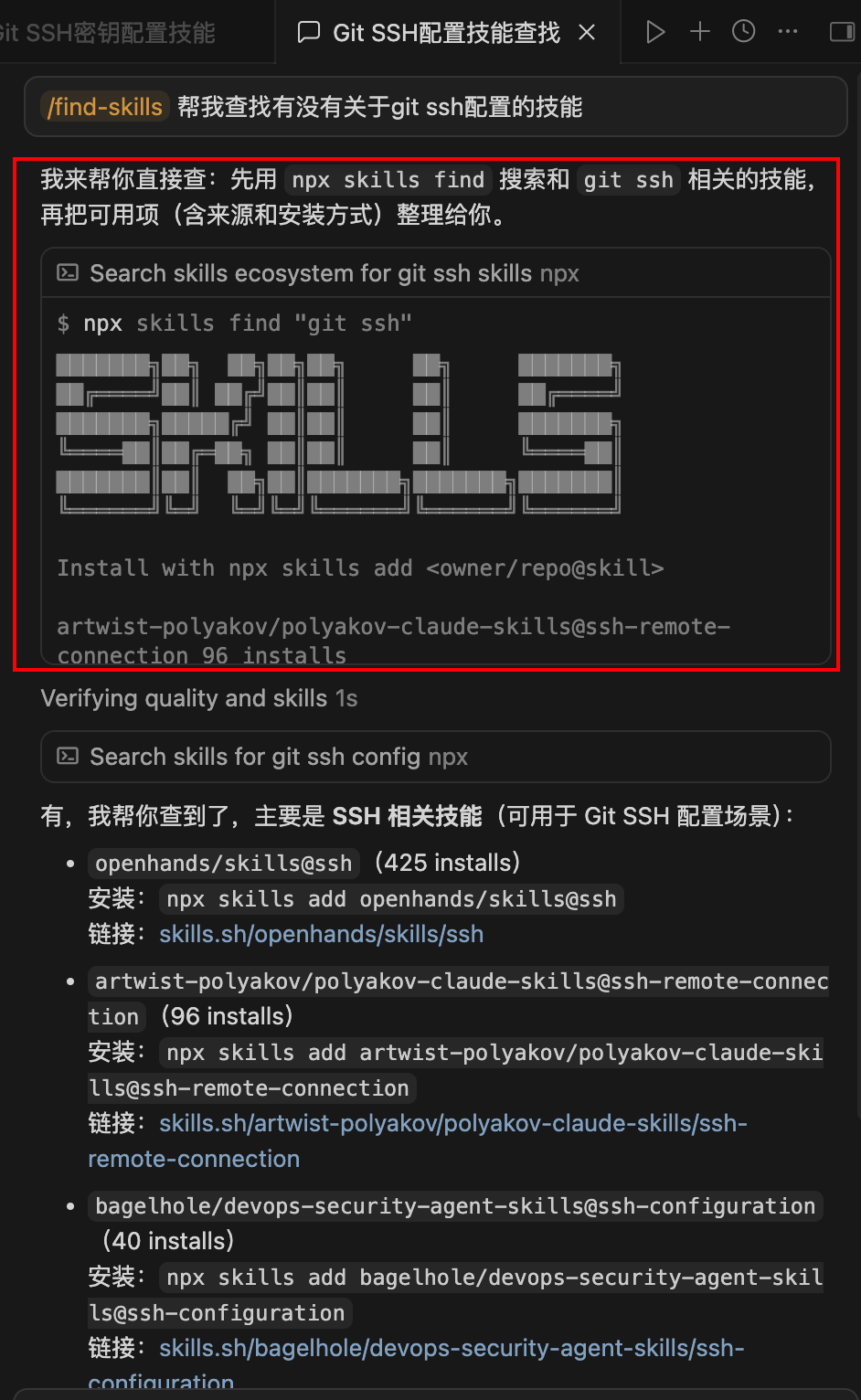
再新开一个对话框,通过显式调用的方式使用技能,LLM直接使用find-skills技能:
4. 如何编写技能
本小节介绍编写技能的一些技巧、优化方法、技能评估方法等。
4.1 最佳实践
4.11 从真实经验出发
在创建AI Skills时,常常犯的错误就是创建一个通用的、宽泛的技能,例如在技能中说“正确处理错误”、“遵循认证标准流程”。
一个真正有价值的 Skill 必须是具体的、深度的,在Skill中需要包含 “Real Expertise(真实专家经验)” ,即要求把那些“只有踩过坑才知道的秘密”放进Skill中。
可以从以下三个维度,把这种“抽象的专业知识”转化为“具体的 Skill 约束”:
从通用建议转向特定模式:不要让 AI 去猜怎么用工具,要直接规定它必须遵循的特定模式。
平庸的指令: “处理图片时请注意性能。”
专家级的指令(Real Expertise):
“在处理超过 20MB 的 4K 图片时,必须使用
Image.open()的延迟加载特性,禁止直接将整个图片读入内存。如果需要缩略图,必须使用draft()模式以减少内存占用。”
挖掘边缘情况:AI 的通用知识库知道图片可能会损坏,但它可能不知道在特定业务中的痛点。
平庸的指令: “优雅处理图片加载错误。”
专家级的指令(Real Expertise):
“注意:部分 iOS 设备拍摄的 HEIC 格式图片在转换为 JPEG 时,EXIF 中的旋转信息(Orientation)经常丢失。脚本必须包含
ImageOps.exif_transpose逻辑,否则输出的图片会发生 90 度翻转。”
注入项目特有的约定:每个项目都有自己的规定,这些是 LLM 绝对无法预测的。
平庸的指令: “按照标准命名保存文件。”
专家级的指令(Real Expertise):
“所有生成的处理后图片必须遵循
{OriginalName}_v{Version}_{UserHash}.webp的命名格式,并自动上传到项目的temp/proc/缓存目录,同时在日志中记录其 MD5 校验码。”
有效的Skill来源于真实的经验,可以通过以下方式创建有效的Skill:
从实战中提取:像往常一样和 AI(比如 Cursor)对话,完成一个真实的任务。在这个过程中,你会不断纠正它、引导它。任务完成后,再把这段**“调教好的过程”**浓缩成一个 Skill。关注以下内容:
- 成功的步骤:完成任务的步骤序列;
- 关键修正:在完成任务过程中,纠正AI的内容,例如,告诉AI不要使用
os.path了,改用pathlib;告诉AI如果是截图,EXIF 会报错,记得加个try-except;告诉AI不要直接print,把结果存进一个列表最后统一输出; - 输入输出规范
- 项目特有上下文:即AI不知道的信息,例如重命名后的格式必须符合
IMG_日期_编号的规范;
从现有资料中提取:从项目中真实存在的文件、报错记录和代码历史来合成 Skill。
这种方法被称为 “知识蒸馏” (Knowledge Synthesis)。通过这种方式产生的 Skill,就像是一个资深员工。
可以将以下“优质素材”转化为具体的 Skill :
- 内部文档、运维手册、风格指南
- Swagger 文档、Protobuf 定义或 SQL 建表语句
- 代码评审(CR)记录,例如GitHub/GitLab 上的评论
- Git 提交历史与补丁
- 事故复盘文档、运维复盘手册
4.1.2 不断优化
当完成一个Skill 草稿后,可以使用该Skill 来完成真实任务,并根据执行过程,来优化Skill。有以下方式可以优化Skill:
核心动作:不要只看结果,要看过程。很多开发者只看 AI 最后给出的代码对不对,但这段话提醒我们要看对话全过程。
- 如果 AI 在对话中表现出: “尝试了方法 A 失败,报错后又试了方法 B,最后才成功。”
- 优化动作: 将方法 B 提升为
skill.md中的首选默认方案。 - 目的: 消除模糊性,减少 AI “走弯路”的时间成本。
核心追问:问自己三个问题
诊断问题 现象举例 优化方案 (Refinement) 什么是误报? (False Positives) 并不是图片任务,但 AI 却加载了图片 Skill。 收窄图片技能 skill.md的触发关键词或条件。遗漏了什么? (What was missed) 成功处理了图片,但忘记按要求记录日志。 在指令中明确:输出结果后必须附加日志记录。 该删减什么? (What could be cut) AI 每次都输出大段的免责声明或背景介绍。 增加约束:“回答必须简洁,仅输出核心代码和关键步骤。” 建立“反馈环” (Execute-then-Revise):不要指望一次性写出完美的 Skill,良好的 Skill 会经历多次迭代:
- Draft(初稿): 基于经验写出第一个版本。
- Execute(执行): 丢给 AI 一个真实的、带点陷阱的任务。
- Trace(分析): 查看 AI 的思考、执行链路。
- Synthesize(再合成): 把刚才纠正它的过程重新写进
skill.md。
4.1.3 明智地使用上下文
LLM的上下文窗口是有限且昂贵的,只把有用的信息放进上下文窗口中。
当一个技能被激活,Agent会把该技能的SKILL.md主题内容,连同对话历史、系统提示词以及其他被激活的技能,一起放进上下文。
忽略Agent已知的,添加Agent缺少的。将重点放在 Agent 如果不借助该技能就无法获知的信息上:项目特有的规范、特定领域的流程、不明显的边缘情况,以及需要使用的特定工具或 API。不需要解释什么是 PDF、HTTP 如何工作,或者数据库迁移是做什么的。
有一个方法判断某段指令是否必需,就是去掉该指令,看Agent会不会报错,如果不会,那么表示该指令是多余的,可以去掉。
设计连贯的单元(即设计一个高内聚的Skill):决定一个技能(Skill)应该涵盖哪些内容,就像决定一个函数应该实现什么功能一样:应该将其封装为一个连贯的工作单元,并且能够与其他技能良好地组合。
范围划分得过窄会迫使单个任务加载多个技能,从而带来额外开销并导致指令冲突。
范围划分得过宽则会变得难以精准激活。一个用于“查询数据库并格式化结果”的技能可能是一个连贯的单元,而一个同时涵盖“数据库管理”的技能则可能承担了过多的职责。
良好组织技能结构(利用渐进式披露方法):规范建议将
SKILL.md控制在 500 行和 5,000 token 以内——仅保留 Agent 每次运行时都需要的核心指令。当一个技能确实需要更多内容时,将详细的参考资料移至references/或类似的独立目录中。关键在于告诉 Agent 何时加载每个文件。相比于泛泛而谈的“详情请参见 references/”,像“如果 API 返回非 200 状态码,请阅读
references/api-errors.md”这样的指令更有用。这能让 Agent 根据需求加载上下文,而不是预先全部加载,这正是**渐进式披露(Progressive Disclosure)**的设计初衷。
4.1.4 控制微调
并非技能的每个部分都需要相同程度的规范性。应根据任务的脆弱程度来调整指令的具体程度。
规范性(Prescriptiveness) 指的是对 Agent 指令的**“约束强度”或“具体程度”**。高规范性意味着给出极度具体、不容置疑的步骤。例如:“必须使用 pathlib 库,必须在第 5 行记录日志,输出必须是特定的 JSON 格式。”。
规范性与脆弱程序相匹配:当有多种有效方法且任务允许变化时,给予智能体自由。对于灵活的指令,解释“为什么”可能比死板的指令更有效——理解指令背后目的的智能体能做出更好的基于上下文的决策。例如,代码审查技能可以描述要寻找的内容,而无需规定确切的步骤:
txt## Code review process 1. Check all database queries for SQL injection (use parameterized queries) 2. Verify authentication checks on every endpoint 3. Look for race conditions in concurrent code paths 4. Confirm error messages don't leak internal details但是,对于脆弱的操作、强一致性场景、或者特定顺序指令,则要求高规范性,例如:
txt## Database migration Run exactly this sequence: ```bash python scripts/migrate.py --verify --backup ``` Do not modify the command or add additional flags.大多数情况下,技能都是灵活性和高规范性操作并存的,独立设计每个部分的操作。
提供默认值,而不是选项:当有多种方式、工具可以实现某项任务时,指定默认值以及可用的替代方式,而不是提供多个选项值。
例如,好的例子:
txtUse pdfplumber for text extraction: ```python import pdfplumber ``` For scanned PDFs requiring OCR, use pdf2image with pytesseract instead.差的例子:
txtYou can use pypdf, pdfplumber, PyMuPDF, or pdf2image...强调方法论:应该教 AI 解决一类问题的“方法论(过程)”,而不是告诉它某个具体任务的“标准答案(声明)”。
声明式 (Declarative) —— 像“一次性脚本”
做法: 直接告诉 AI 具体的执行动作(比如:把 A 表和 B 表合并,过滤出某个地区)。
缺点: 这种指令非常短视。换一个表名,或者换一个地区,这个 Skill 就废了。它只对当前的这一个任务有效。
过程式 (Procedural) —— 像“通用算法”
做法: 告诉 AI 解决这类问题的通用步骤。
- 先去哪里查表结构;
- 按照什么命名规律找关联键;
- 根据用户的实际需求动态生成过滤条件;
- 最后按特定格式输出。
优点: 这种指令具有泛化能力(Generalization)。无论用户问的是“销售数据”还是“用户增长”,AI 都能按照这套逻辑自己推导出答案。
4.1.5 有效指令模板
当组织SKILL内容时,以下是一些可复用的技巧。
容易踩坑的点:在 Skill 开发中,这一部分的内容含金量最高。它的核心意义在于:纠正那些即便是一个聪明的 AI 也会基于“常识”做出的错误假设,也就是说,如果我不说,AI 一定会搞错的地方。例如:
txt## Gotchas - The `users` table uses soft deletes. Queries must include `WHERE deleted_at IS NULL` or results will include deactivated accounts. - The user ID is `user_id` in the database, `uid` in the auth service, and `accountId` in the billing API. All three refer to the same value. - The `/health` endpoint returns 200 as long as the web server is running, even if the database connection is down. Use `/ready` to check full service health.放在
SKILL.md中: 因为容易踩坑的点太重要了,必须让 Agent 在开始干活之前就读到。如果放在独立的参考文件里,Agent 可能根本意识不到什么时候该去读它。动态更新: 每当发现 Agent 犯了一个必须手动纠正的错误时,就把这个纠正写进 Gotchas。这是 Skill 迭代优化(Refine with real execution)最直接的方式。
输出模板:如果需要AI输出指定格式内容,那么提供一个模板。相比长篇大论地去描述输出长什么样,不如提供一个模板,AI可以很好地模仿模板。如果模板很短,可以放在
SKILL.md中;如果很长,可以放在/assets文件夹中,并且在SKILL.md中引用。对于多步骤工作流,提供检查表:显式的检查表可以帮助AI跟踪任务执行进度、避免跳步,尤其是在各步骤有依赖顺序或者校验步骤时。检查表形式通常是带有
[ ]符号的列表,每个步骤通常关联一个具体的动作(如运行脚本)。例如:txt## Form processing workflow Progress: - [ ] Step 1: Analyze the form (run `scripts/analyze_form.py`) - [ ] Step 2: Create field mapping (edit `fields.json`) - [ ] Step 3: Validate mapping (run `scripts/validate_fields.py`) - [ ] Step 4: Fill the form (run `scripts/fill_form.py`) - [ ] Step 5: Verify output (run `scripts/verify_output.py`)检查表与任务执行步骤并不冲突,两者配合使用。
任务执行步骤告诉 AI 如何完成任务,但并不强制 AI 停下来反思。如果没有检查表,AI容易跳步,例如第二步失败了,AI 可能会忽略错误直接尝试第三步。
检查表是一种状态跟踪机制,它强制 Agent 在执行过程中进行“自我审计”。
校验循环:告诉AI在进行下一步之前,先执行校验,只有校验通过才能继续,如果校验失败,需要修复错误,直至校验通过。例如:
txt## Editing workflow 1. Make your edits 2. Run validation: `python scripts/validate.py output/` 3. If validation fails: - Review the error message - Fix the issues - Run validation again 4. Only proceed when validation passes计划-校验-执行模式:对于批处理或破坏性的操作,让AI遵循计划-校验-执行模式。如果缺少了校验步骤,如果AI在执行时出现幻觉,那么执行破坏性操作,可能造成损失。因此,在执行前加入校验,可以确保最终的输出是准确的。例如:
txt## PDF form filling 1. Extract form fields: `python scripts/analyze_form.py input.pdf` → `form_fields.json` (lists every field name, type, and whether it's required) 2. Create `field_values.json` mapping each field name to its intended value 3. Validate: `python scripts/validate_fields.py form_fields.json field_values.json` (checks that every field name exists in the form, types are compatible, and required fields aren't missing) 4. If validation fails, revise `field_values.json` and re-validate 5. Fill the form: `python scripts/fill_form.py input.pdf field_values.json output.pdf`在第三步加入了校验。
脚本构建:如果发现Agent重复执行相似的逻辑,那么就可以把这段逻辑提取为脚本。
4.2 优化description
根据渐进式披露原则,最开始,Agent只会提供name和description给LLM,LLM根据description中的内容,认为该Skill可以用来解决问题时,才会激活Skill,因此,description的质量决定着Skill是否得到激活。
如果一个Skill的description描述不足,即描述写得过于具体或窄小,那LLM可能会忽略这个应该被激活的Skill;如果一个Skill的description描述过于宽泛,即描述写得含糊不清或包罗万象,那LLM 可能会在不该激活Skill的时候激活它。
好的description应该具有以下特征:
使用祈使句:将描述框定为对 Agent 的指令:“当……时使用此技能”,而不是客观描述“此技能可以……”。
为什么要使用祈使句?因为Agent 此时处于“决策”状态,它需要明确的触发指令。
❌ “这个技能可以处理图片重命名。”(客观陈述)
✅ “当用户要求调整图像资产、修改文件名或处理 EXIF 元数据时,请使用此技能。”(行动指令)
关注用户意图,而非内部实现:描述用户想要达成的目标,而不是技能内部的运行机制。
❌ “运行
scripts/compress.py并应用 80% 的质量参数。”(实现细节)✅ “当用户需要关于减小图像文件大小或优化网页图片加载速度时,请使用此技能。”(意图匹配)
宁可强势一点:明确列出适用的上下文,甚至包括那些用户没有直接点名领域的情况,以防止漏掉潜在任务。
✅ “当用户询问数据趋势或表格总结时请使用此技能,即便他们没有明确提到‘CSV’或‘数据分析’等词汇。”
保持简洁:篇幅控制在几句话或一个短段落内。既要覆盖范围,又要避免臃肿。如果描述太长,会占用 Agent 宝贵的上下文窗口。
4.3 使用scripts
本小节介绍如何在Skill中使用脚本。
4.3.1 一次性命令
如果已存在的包已经满足需要,我们可以直接在SKILL.md中使用,不需要写在scripts文件夹中。
很多生态工具(如uv、npx 或 Deno )提供了运行时自动解析(Runtime Auto-resolution)功能,意味着运行环境不再需要手动配置,工具会自动按需处理。也就是说,如果自己写的python脚本my-script.py需要依赖requests库,那么在执行环境中没有安装requests库,执行python my-script.py时,会报错。而如果使用uv工具来执行脚本:uv run my-script.py,并不会报错,会按照以下步骤执行:
扫描 (Scanning): 当运行
uv run my-script.py时,工具会瞬间读取脚本开头的依赖声明(如 PEP 723);隔离 (Isolation): 它会自动在后台创建一个临时的、干净的虚拟环境;
解析与缓存 (Resolving & Caching): 它会去云端仓库寻找匹配的依赖包。如果电脑里曾经下载过(即便是在别的项目里),它会通过“硬链接”瞬间复用,不需要重新下载;
执行 (Execution): 环境准备就绪后立即运行脚本。运行结束后,这个临时环境可以被自动清理,也可以留在缓存中备用。
因此,对于一次性命令,推荐使用生态工具执行。
关于一次性命令的建议:
固定版本:例如
uvx black@24.10.0 .,以保证命令执行效果相同;声明前提:需要在
SKILL.md中声明生态工具,如果没有安装,需要指引用户安装:txt## Prerequisites - **Python 3.10+** - **uv**: 本 Skill 使用 `uv` 进行极速依赖管理和脚本运行。 - 如果未安装,请引导用户运行:`curl -LsSf https://astral.sh/uv/install.sh | sh`也可以在
compatibilityfrontmatter中声明。将复杂命令移到scripts中:如果一次性命令过于复杂,建议将其移入scripts中。
4.3.2 引用脚本
在SKILL.md中,使用从Skill根目录的相对路径引用脚本,不要使用绝对路径。
txt
## Available scripts
- **`scripts/validate.sh`** — Validates configuration files
- **`scripts/process.py`** — Processes input datatxt
## Workflow
1. Run the validation script:
```bash
bash scripts/validate.sh "$INPUT_FILE"- Process the results:bash
python3 scripts/process.py --input results.json
#### 4.3.3 自包含脚本
所谓自包含脚本,就是可以使用单条命令执行,不用再手动安装依赖。
很多语言都支持内联依赖声明,以Python为例,[PEP 723](https://peps.python.org/pep-0723/)就定义了内联依赖声明格式,例如:
```python {1-5}
# /// script
# dependencies = [
# "beautifulsoup4",
# ]
# ///
from bs4 import BeautifulSoup
html = '<html><body><h1>Welcome</h1><p class="info">This is a test.</p></body></html>'
print(BeautifulSoup(html, "html.parser").select_one("p.info").get_text())然后使用uv执行脚本:
bash
uv run scripts/extract.pyuv run会创建一个独立的执行环境,然后安装依赖,执行脚本。
4.3.4 脚本建议
当Agent执行脚本时,它获取标准输出stdout和标准错误输出stderr,然后决定下一步做什么。因此,下面有一些建议,帮助Agent更好地执行脚本。
避免交互式提示:如果脚本中需要输入密码或者确认框,Agent无法响应。因此,避免在脚本中引用交互式提示,改用参数、环境变量、标准输入等方式替代。
txt
# Bad: hangs waiting for input
$ python scripts/deploy.py
Target environment: _
# Good: clear error with guidance
$ python scripts/deploy.py
Error: --env is required. Options: development, staging, production.
Usage: python scripts/deploy.py --env staging --tag v1.2.3显示帮助文档:给脚本增加--help文档说明,这能帮助Agent了解脚本的使用方法。
txt
Usage: scripts/process.py [OPTIONS] INPUT_FILE
Process input data and produce a summary report.
Options:
--format FORMAT Output format: json, csv, table (default: json)
--output FILE Write output to FILE instead of stdout
--verbose Print progress to stderr
Examples:
scripts/process.py data.csv
scripts/process.py --format csv --output report.csv data.csv错误消息应有意义:当脚本执行过程中发生了错误,应该详细说明错误是什么。例如,以下是好的错误消息示例:
txt
Error: --format must be one of: json, csv, table.
Received: "xml"使用结构化输出:结构化输出可以让Agent更好理解,也能更好地送入下一流程:
txt
# Whitespace-aligned — hard to parse programmatically
NAME STATUS CREATED
my-service running 2025-01-15
# Delimited — unambiguous field boundaries
{"name": "my-service", "status": "running", "created": "2025-01-15"}注意,将结构化数据输出到标准输出stuout,将进度信息、警告、错误、其他诊断信息输出到标准错误输出stderr,能帮助Agent更好地理解。
参考资料
[1] https://agentskills.io/home