Appearance
CAP、PACELC与BASE
本文介绍了CAP、PACELC、BASE三大理论。
1. CAP
由Eric Brewer教授在2000年提出的CAP理论,认为在分布式系统中,三个重要属性,同时最多只能满足两个:
C(Consistency,强一致性):强一致性,更精确地说是线性一致性(Linearizability)。整个系统对外表现得就像只有一个副本,所有节点在任意时刻看到的数据都完全一样。一旦某个写操作成功完成,那么之后任何一个节点上发起的读操作,都必须能读到刚刚写入的值(或更新的值)。
A(Availability,可用性):系统中每一个没有发生故障的节点,对于接收到的每一个请求,都必须返回一个非错误的响应。
这个定义只要求“有响应”,不要求“响应的是最新数据”。这意味着,一个系统即便在发生网络分区时返回了过时的旧数据,只要它迅速给出了合理的应答,就依然算作满足“可用性”。
P(Partition Tolerance,分区容错性):当分布式系统内部节点之间的网络通信发生任意消息丢失或延迟(即网络分区)时,系统仍然能够作为一个整体持续运行,向外提供服务。
CAP理论提出,在分布式系统中,C、A、P三个属性,同时只能满足两个。
由于网络分区是不可避免的,所以系统只能是 CP 或 AP。
- CP (牺牲可用性):分区后,为了保持数据一致,宁可不服务。例如银行转账系统,宁可报错也不能出现余额不一致。
- AP (牺牲强一致性):分区后,为了保证服务不中断,允许各部分独立响应,接受数据暂时不一致。例如社交媒体发帖,优先保证能发出去。
CAP理论的局限是只描绘了“出现故障”时的极端画面,没有指导系统在绝大多数正常运行时间里如何权衡,即网络分区只有很小的几率发送,并且持续时间短,在大部分时间,系统都是正常运行的,此时CA是可以同时满足的。
2. PACELC
CAP理论的局限性是只描绘了出现故障时的场景,而系统大多数时候,是不会出现网络分区的。
因此,PACELC理论扩展了CAP理论,补充了在正常情况下,系统应该如何在性能与一致性之间做出选择。
PACELC理论可以解释为两种情况:
- 如果发生网络分区(P),系统是在可用性(A)和一致性(C)之间做选择。
- 否则(E,即网络正常,没有分区),系统是在延迟(L,Latency)和一致性(C)之间做选择。
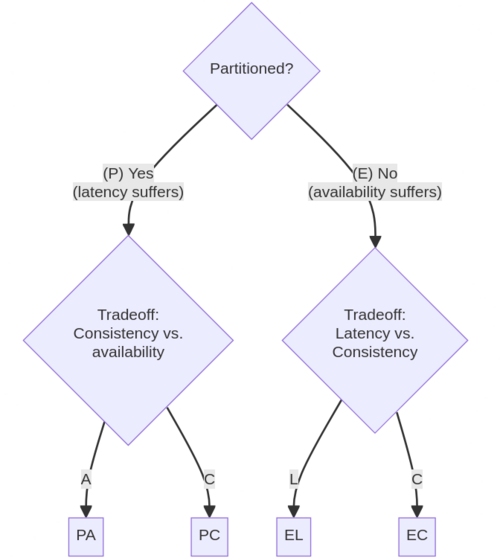
根据PACELC理论,在发生网络分区和正常情况下,选择不同的策略,有以下四种组合方式:
| 类型 | 含义 | 典型代表系统 |
|---|---|---|
| PC/EC | 发生分区时保证一致性(PC);网络正常时也宁可要高延迟也要保证一致性(EC)。 以一致性为第一考虑因素。 | Spanner, CockroachDB, HBase |
| PA/EL | 发生分区时保证可用性(PA);网络正常时为了追求极低延迟而放弃强一致性(EL)。 以可用性为第一考虑因素。 | Cassandra, DynamoDB, Couchbase |
| PA/EC | 发生分区时保证可用性(PA);但网络正常时,愿意牺牲速度来保证一致性(EC)。 | MongoDB(默认配置或特定配置下) |
| PC/EL | 发生分区时保证一致性(PC);网络正常时追求低延迟(EL)。 | 这种设计在实际中极少见,因为逻辑上比较矛盾。 |
3. BASE
BASE理论是选择了PA或EL时的实践指导。
BASE 是三个英文短语的缩写:Basically Available(基本可用)、Soft state(软状态)和 Eventual consistency(最终一致性)。
Basically Available(基本可用):基本可用是指系统遭遇不可预知的故障(如双十一流量暴增、部分网络分区)时,系统允许损失一部分性能或功能,但绝不直接崩盘。
基本可用并不只是应对网络分区这一种异常情况,还包括其他异常情况,例如:
- 流量暴增与瞬时过载:数据库 CPU 飙升到 100%,连接池爆满。如果强行让所有功能都保持完美可用,整个系统会在几秒钟内因为内存溢出(OOM)或雪崩而彻底瘫痪(全盘不可用)。
- 单点硬件故障或核心依赖服务宕机:分布式系统包含成百上千个微服务和底层组件,某个关键组件可能会突然崩溃,导致整个系统不可用。
- 级联故障:在微服务架构中,服务
链条式调用。如果最底层的 C 服务因为写了个死循环导致响应变慢,A 和 B 就会因为等待 C 而堆积大量的线程,最终导致整个系统卡死。
可以通过服务降级、服务熔断、流量限流、异步处理等方式实现系统基本可用:
- 服务降级:当系统压力过大或某些服务异常时,关闭非核心功能,只保留核心业务。常见降级方式:返回默认数据、返回缓存数据、返回静态页面、隐藏部分功能、延迟处理部分业务;
- 服务熔断:当下游服务持续失败时,立即停止调用,避免故障扩散。
- 服务限流:当请求量超过系统处理能力时,限制进入系统的流量。常见算法:固定窗口、滑动窗口、漏桶算法、令牌桶算法(最常用)。
- 异步处理:将非核心业务改为异步执行。例如下单过程中需要扣库存,发短信、发邮件、写日志等操作,可以将发短信、发邮件、写日志等非核心业务,发送到MQ,异步处理,降低主流程压力。
- 负载均衡:部署多个实例,将请求分发到不同实例上,既降低节点压力,并且即使一台节点挂掉,其余节点也可以提供服务。
- 缓存:减少对数据库的压力,热点数据直接从缓存中读取。
Soft state(软状态):在分布式系统中,软状态是指由于网络传输延迟或异步复制机制的存在,导致同一个数据在分布式集群的不同节点之间,在同一物理时间点上的状态或数值不一致。软状态指的是数据的不一致。
例如,用户充值,在某一时刻:
txt数据库A:1000元 (已经更新) 数据库B:800元 (还没有同步) 数据库C:800元 (还没有同步)此时,三个数据库节点的状态不一致,这就是软状态。
在保持系统基本可用的方法中,异步处理、缓存、使用AP型数据库都可能引起软状态。
- 异步处理:假设在下单过程中,库存系统已经更新该订单为已下单,但是在物流系统、用户系统等其他系统中,可能该订单还是待处理状态,此时不同系统之间的订单状态不一致。
- 缓存:假设更新数据库中某商品的库存数量为100,但是此时缓存还没来得及更新,数量还是120,此时数据库和缓存之间的状态不一致。
- 使用AP型数据库:如果使用了AP型数据库,那么可能A数据库中商品单价为1000元,此时B、C数据库的数据还没有同步,还是800元,不同数据库之间的状态不一致。
Eventual consistency(最终一致性):系统不要求数据在写入后立即保持一致,但保证经过一段时间的数据同步后,所有节点的数据最终会达到一致。
例如,用户充值,在某一时刻:
txt数据库A:1000元 (已经更新) 数据库B:800元 (还没有同步) 数据库C:800元 (还没有同步)此时数据状态不一致,但是经过一段时间的同步后:
txt数据库A:1000元 (已经更新) 数据库B:1000元 (已同步) 数据库C:1000元 (已同步)这就是最终一致性。
通常通过消息队列、定时任务补偿、重试机制、本地消息表等方式实现最终一致性。
但是,最终一致性可能会受到并发更新导致数据冲突的影响。
假设在T1时刻,数据库A更新数据值为V1,还没来得及更新,在T2时刻,数据库B更新数据值为V2。也就是说,多个节点同时修改同一份数据时,如何解决数据冲突?
有以下方案解决数据冲突:
- Last Write Wins(最后写入覆盖)
- CRDT(Conflict-free Replicated Data Type)
参考资料
[1] CAP : https://sites.cs.ucsb.edu/~rich/class/cs293b-cloud/papers/Brewer_podc_keynote_2000.pdf
[2] CAP Twelve Years Later: How the "Rules" have changed: https://sites.cs.ucsb.edu/~rich/class/cs293b-cloud/papers/brewer-cap.pdf