Appearance
复制与副本
本文介绍复制的概念与其实现方案。
1. 复制概念
复制(replication),是指在多个节点上保存同一份数据,这些节点称为副本(replica)。
复制(Replication) 指的是“数据复制的整个机制、过程或架构策略”。它关注的是系统如何把一份数据变多份、如何在网络中传输这些数据、以及如何保证它们之间的一致性。
副本(Replica) 指的是“被复制出来的那个具体的、物理存在的数据备份或节点服务器”。
在分布式系统中,实现复制有助于提高系统的可用性,当一个节点崩溃下线后,由于其他节点有相同的数据,其他节点可以继续提供服务,整个系统正常运行。
如果数据是不变的,那么复制很简单,只需要在每个节点上保存一份数据就可以了。**主要的问题是数据是可变的,如何保持副本的数据一致性。**接下来的章节也围绕着副本一致性展开。
2. 重试与幂等性
如下图,假设某个用户在某个推文下点赞,随后发起一个请求。假设该请求被服务端成功接收并处理,此时点赞数加一。但是,如果该请求的响应由于网络原因,没有到达用户侧,此时用户会认为点赞没有成功。
为了保证操作的可靠性,超过一定时间后,客户端重新发起请求,这就是重试。
假设服务端又接收到请求并处理,此时点赞数又加一,最终会造成点赞数多了。
这是重试的问题,如果多次发起请求,那么服务端多次处理请求,可能会造成额外的影响。
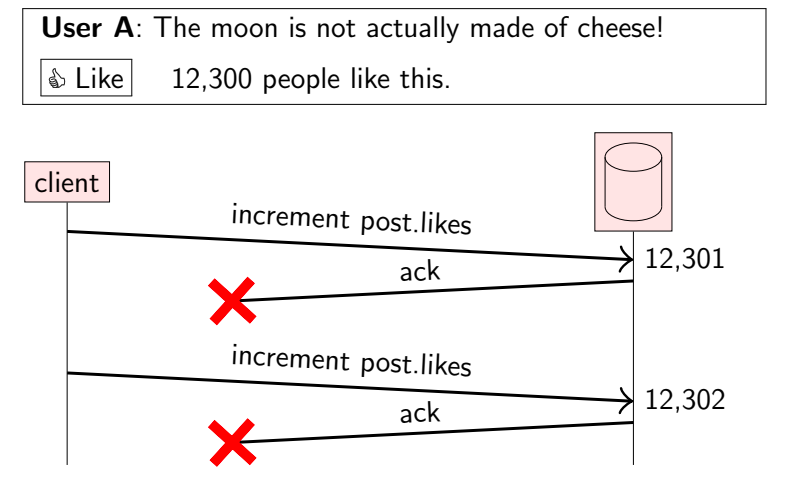
为了消除重试的影响,那么服务端需要对请求去重,这就要求在stop-recovery模型中,需要将请求持久化保存起来,使得可以识别重复请求(但实际上,重复请求的识别也不是很好做)。
一种替换的方法是使得接口幂等,也就是说,请求多次接口和请求一次接口的效果是一样的。
在以上的场景中,我们可以把某篇推文点赞的用户保存起来,如果某个用户点赞了某篇推文,就把该用户ID加入到点赞用户集合中。使用该种方法,该用户点赞多次和点赞一次的效果是相同的。
3. 副本一致性问题
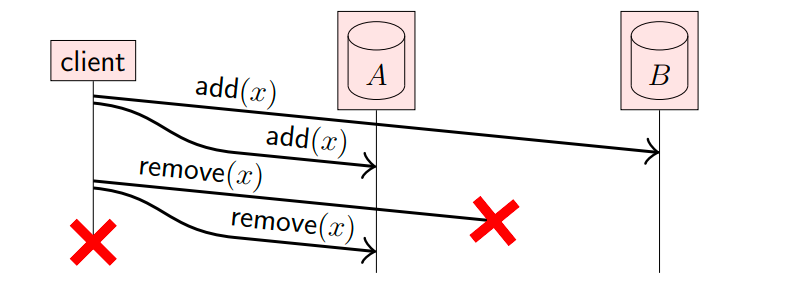
我们先看下图,客户端首先在两个副本(A和B)上添加了数据x,然后又试图移除数据x,但是移除操作在A上成功了,在B上失败了,并且还没来得及重试,客户端也下线了。
最终导致A中没有数据x,而B中有数据x:
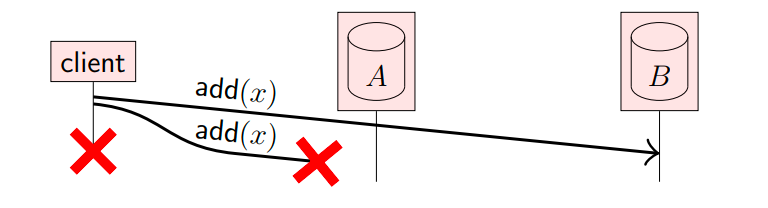
再来看下图,客户端在副本A和B上同时添加数据x,但是添加数据的操作在A上失败了,在B上成功了,并且还没来得及重试,客户端下线了。
最终,仍然是A中没有数据x,而B中有数据x:
以上两个场景,最终的效果是一样的(A中没有数据,B中有数据),但是两个场景,用户的意图完全不同:
- 在场景一,用户想在两个副本移除数据,最终效果是两个副本都没有数据;
- 在场景二,用户想在两个副本添加数据,最终效果是两个副本都有数据;
为了解决以上副本之间不一致的问题,并且希望最终结果和用户意图相同,有以下两种方案:
- 基于冲突解决的“最终一致性”架构(AP 倾向);
- 基于全序广播的“SMR(状态机复制)”架构(CP 倾向);
4. 最终一致性架构方案
基于冲突解决的“最终一致性”架构(AP 倾向)架构的分布式系统,通常是无主(Leaderless)或多主(Multi-Leader)的。
核心思想是允许副本暂时不一致,写入时不强求所有副本立即达成一致。系统优先保证可用性(Availability)和分区容忍(Partition Tolerance),通过后台机制逐步修复差异,最终达到一致。
主要采用以下技术:
逻辑时钟(Logical/Vector Clocks): 因为没有一个中心节点来定顺序,各个副本的时间戳也因为物理时钟漂移不可信。所以必须用向量时钟等逻辑时钟,来标记数据的因果关系(Causality),判断到底谁先改的,谁后改的,哪些改动是并发冲突的。
Tombstone(墓碑标记): 在这种系统里,删除操作不能真的把数据抹去。因为如果副本 A 删除了数据,而副本 B 还没同步,副本 B 就会以为副本 A 只是“漏掉了这笔数据”,在同步时又会把数据给“复活”弹回来。所以必须写入一个“墓碑”标记,告诉别人:这笔数据已经死了。
反熵(anti-entrophy):各个副本(replicas)会运行一种协议,来检测并修复它们之间的差异(这种机制叫做反熵 / anti-entropy),从而使所有副本最终都持有一致的数据副本。
解决冲突的两种手段:
LWW (Last-Write-Wins,最后写入者胜): 简单粗暴。虽然逻辑时钟能分辨并发,但 LWW 强行依赖一个时间戳,后到的覆盖先到的。优点是简单,缺点是会盲目丢数据。
Multi-value register (多值寄存器 / 兄弟版本 Siblings): 当逻辑时钟发现两个写入是并发冲突的,系统选择全都要,同时保存这两个版本。等到客户端下次来读的时候,把两个版本都抛给客户端,让业务层(人类代码)自己去解决冲突,或者采用CRDT。
首先,在每一个更新操作上附带一个逻辑时钟t,并且在副本中存储该时钟;然后,增加一个标记,表示某个数据已被删除,即墓碑标记(逻辑删除):
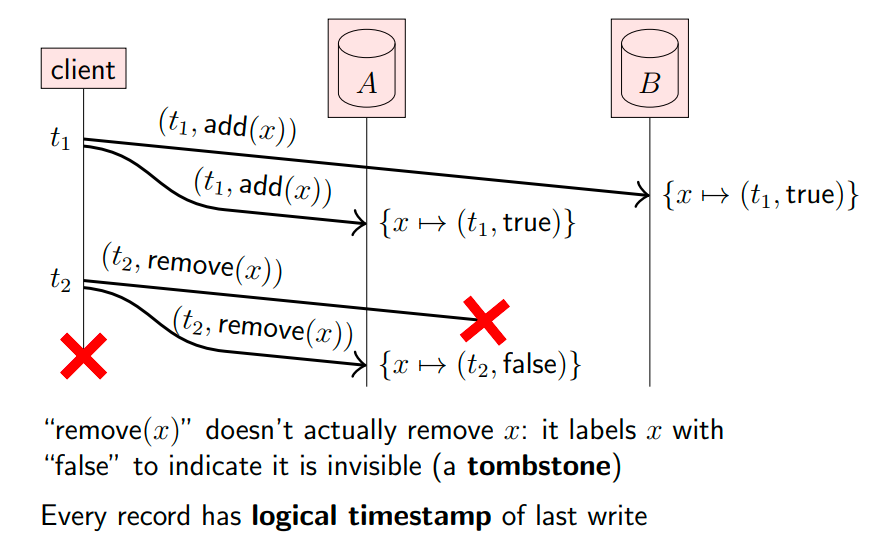
有了逻辑时钟和墓碑标记,当副本间运行反熵协议时,就能检测到不一致的地方,从而协调,达到一致状态,并且有了墓碑标记,就能识别到某个数据是删除状态还是没有成功创建状态。
如下,A副本中有数据{x -> (t2, false)},B副本中有数据{x -> (t1, true)},当A和B副本之间通过反熵协议,交换同一个数据的时间戳和墓碑标记,通过时间戳,就能解决冲突,以达到一致的状态:

对于并发写入操作,可能无法简单比较时间戳,因此需要额外的方式解决冲突。如下,两个客户端并发写入两个副本(A和B),其中副本A先接受到(t2, set(x, v2)),然后接收到(t1, set(x, v1)),副本B的顺序刚好相反。副本并不是根据接收请求的先后时间来写入,而是根据请求携带的时间戳来写入。
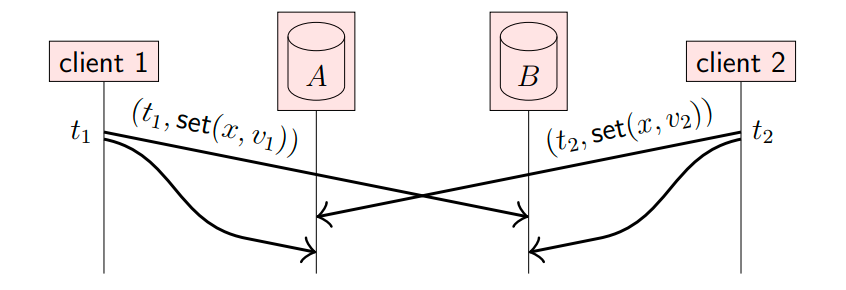
有两种冲突解决方式:
- LWW(Last Write Win):最后写入者胜;当采用LWW时,通常使用Lamport逻辑时钟,因为该逻辑时钟是一种全序(即使不同客户端的某个操作逻辑时钟相同,也可以比较节点ID来决定先后顺序),然后应用最后的操作;使用该方式的缺点是会有数据遗失。例如,假设
t1 < t2,那么会保存v2,舍弃v1; - MVR(Multi-Value Register):多值寄存器;当采用MVR时,通常采用Vector逻辑时钟,该逻辑时钟能完美识别两个操作是否并发,如果两个操作是并发的,那么就要在副本中同时保存两个操作的结果,例如
(x, {v1, v2});使用该方式的缺点是需要存储Vector逻辑时钟,如果系统中节点较多,那么存储逻辑时钟所占的空间可能比数据本身更大;
在LWW方案中,可以使用Vector逻辑时钟吗?不推荐,因为Vector是偏序的,即可能无法确认两个操作的先后关系,而LWW需要全序关系,因此使用Vector,在两个操作是并发的时候,还需要额外定义比较逻辑,以确定两个操作的先后关系。
在MVR方案中,可以使用Lamport逻辑时钟吗?不可以,假如在client 2上发生了很多时间,此时client 2的Lamport逻辑时钟已经很大了,然后开始写入(t2, set(x,v2)),而client 1可能才刚刚启动,此时client 1的Lamport逻辑时钟很小,此时写入(t1, set(x,v1)),此时必然后t2 > t1,但实际上两个操作是并发的,如果使用Lamport逻辑时钟,会误判断两个操作中,t2操作是较后的操作,从而丢弃了t1操作,造成数据丢失。
5. 状态机复制架构方案
状态机复制(State Machine Replication,简称SMR),是指把整个系统看作一个确定性状态机(Deterministic State Machine),然后把这个状态机复制多份到不同的节点上。通过让所有副本按照完全相同的顺序接收和执行相同的操作序列,最终所有副本的状态会保持完全一致。
基于全序广播的“SMR(状态机复制)”架构(CP 倾向),核心思想是通过全序广播(Total Order Broadcast),让所有副本以完全相同的顺序接收并应用相同的操作序列,从而保证强一致性。
核心技术就两个:
全序广播(total order broadcast):保证所有副本(replicas)以完全相同且一致的顺序接收到相同的操作序列。这是 SMR 的传输层,相当于给所有副本提供了一条“相同的日志流”(log)。
常见实现协议:Paxos、Multi-Paxos、Raft、ZAB、Viewstamped Replication 等。
确定性操作(Deterministic Operations):保证所有副本从相同初始状态开始,按照相同顺序执行相同操作后,能到达完全相同的最终状态。
操作必须是确定性的(deterministic):同样的输入 + 同样的执行上下文 → 必须产生同样的输出和状态变化。不能依赖本地时间、随机数、节点 ID、外部传感器等非确定性因素。
例如,使用
UUID()就不是确定性操作,因为在不同节点执行UUID(),得到的结果不同。
例如,如果要应用某个操作,先把该操作请求发送到分布式系统中,该分布式系统通过全序广播,将操作以一致顺序发送给其他副本,其他副本应用该操作,只要该操作是确定性的,就能达到一致性状态。
6. 主动复制和被动复制
主动复制(active replication)是指所有节点独立执行同一段确定性逻辑代码。
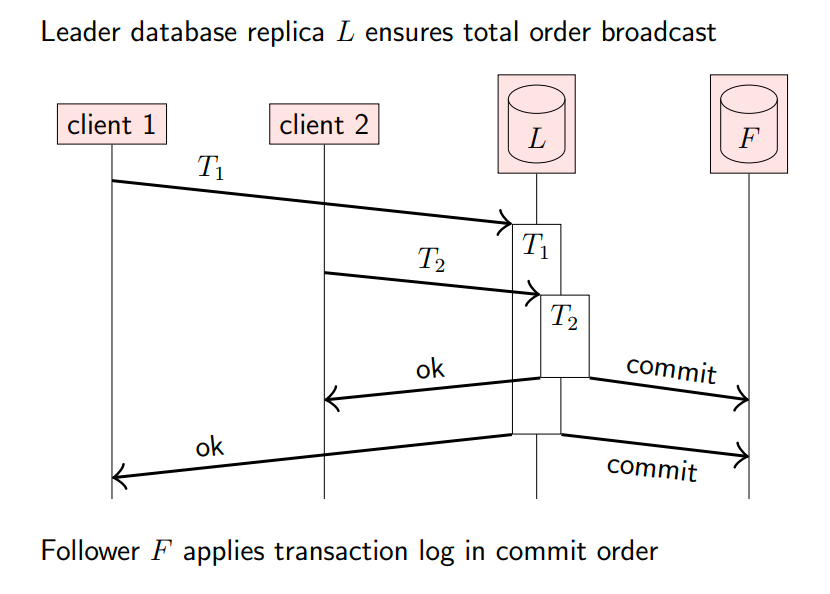
被动复制(passive replication)是指由一个节点计算结果,然后将结果广播到其他副本,其余副本不用再重复计算,只需要应用结果即可。在使用被动复制时,通常会指定某个节点为主节点(leader, primary, 或 master),命令都发送到主节点,主节点计算完成后,再将结果发送给副本节点。
下图展示了数据库系统应用被动复制理念,L为主节点,F为副本节点,客户端将事务命令发送给主节点,主节点完成计算后,按事务提交顺序广播给副本节点,副本节点只需要应用结果即可:
在最终一致性架构方案中,如果要应用主动复制,那就是客户端将命令操作广播给所有节点,各节点独自计算结果,并返回给客户端。
典型代表: 基于操作的 CRDT 系统、Gossip 协议的操作传播(如某些分布式协同编本文档、朋友圈点赞)。
优点如下:
极致的可用性(Availability): 没有单点故障。任何节点挂了,客户端找另一个节点发命令就行;网络分区时,两边都能继续写入。
极低的延迟: 客户端可以就近写入任何节点,不需要等跨国网络同步。
网络带宽极省: 只在网络中传输几十字节的“原始操作命令”(如
+1),不传大数据。
缺点如下:
业务逻辑受限(终极缺点): 只能执行满足数学交换律的操作(如加减、集合并集)。一旦出现
x = x * 2或复杂条件判断,数据立刻分叉死锁。用户体验有“脏数据”: 因为是最终一致,用户在不同节点上读到的数据可能在短时间内不一致。
在最终一致性架构方案中,如果要应用被动复制,客户端首先将命令操作发送给主节点,主节点计算完成并应用结果后,返回结果给客户端,之后主节点再将结果广播给其余副本节点。
典型代表: 传统 MySQL 异步主从复制、Redis 主从架构。
优点如下:
编程极其简单自由: 业务代码里随便写随机数、系统时间(非确定性函数),因为只有主节点算一次,结果定死后才发给从节点,绝不分叉。
从节点 CPU 极闲: 从节点只需要机械地抄写答案(覆盖内存/磁盘),不耗费 CPU 跑业务逻辑,可以用低配机器。
写响应极快: 只要主节点自己写完就返回,不被网络同步拖慢。
缺点如下:
存在丢数据风险: 如果主节点刚算完返回成功,还没来得及把结果异步发给从节点就宕机了,这部分数据就彻底丢了。
主节点是绝对瓶颈: 所有的读写、事务计算、锁全部压在主节点,无法横向扩展写性能。
在状态机复制架构方案中,如果要应用主动复制,客户端将命令发送给分布式系统(不论哪个节点),该命令最终会路由到领导者节点(Raft算法中的领导者),在领导者节点排序后,将命令广播给副本节点,大多数节点都接收到消息后,领导者节点返回结果给客户端,当该消息可交付后,各副本节点独自计算命令结果并应用。
典型代表: 经典的 Raft / Paxos 状态机(如 etcd、ZooKeeper 的写流程)。
优点如下:
- 强一致性(Linearizable): 保证客户端读到的一定是最新的,绝无脏数据。
- Leader 计算压力小: 正如你最开始意识到的,Leader 只负责给命令排队发传单,不负责跑复杂的计算,全网副本平摊 CPU 算力。
- 故障切换(Failover)极快: Followers 本地都在实时计算、维持最新的状态机,Leader 挂了,新 Leader 顺位上马,不需要做耗时的数据恢复。
缺点如下:
同样面临“确定性噩梦”: 状态机要求业务代码里绝对不能有随机、时间戳等不确定逻辑。
高并发下容易流水线阻塞: 所有人必须严格按顺序一个接一个地计算。如果第 100 个命令是个耗时 5 秒的超大计算,后面的 101、102 号命令全部都要在队列里卡死(Head-of-Line Blocking)。
为什么会发生流水线阻塞?流程如下:
客户端 发送命令(如
Command 100)给 Leader。Leader 把命令写进本地日志,并广播给所有 Follower。
Followers 接收并写入日志:注意,此时 Follower 们仅仅是把命令写进日志磁盘里,绝对不运行计算!因为写日志极快,Follower 迅速向 Leader 返回“我收到了”。
达成多数派(Committed):Leader 收到大多数节点的确认,认为该命令安全了。
Leader 亲自计算(Apply):Leader 把
Command 100送进自己的状态机引擎,亲自运行计算,算出结果(例如:成功,当前余额为 100)。响应客户端:Leader 带着这个热乎的计算结果,立刻返回给客户端。
Follower 异步计算:Leader 在随后的心跳或下一个主从通信中,通知 Follower:“100 号命令已经安全提交了,你们可以搬砖计算了。” 于是,Follower 们在后台异步地、默默地把命令拿出来,各自运行计算。
问题出在第5步,状态机开始跑
Command 100。由于这是个超大计算(比如复杂的矩阵运算或全表大扫描),Leader 的执行线程需要死磕 5 秒钟。此时,Command 101只能在状态机队列里排队等着。客户端 1 在等 100 号的结果,它需要等 5 秒,这理所当然。 然而,客户端 2 发送的是一个耗时只需 1 毫秒的极其简单的命令(101 号),但因为 Leader 还没算完 100 号,根本没办法开始算 101 号,更没办法拿 101 号的结果返回给客户端 2。
在状态机复制架构方案中,如果要应用被动复制,客户端发送的命令仍然是路由到领导者节点,领导者节点计算完成后,将结果广播给副本节点。
典型代表: 现代分布式关系型数据库的底层(如 TiDB/TiKV、CockroachDB、MySQL Group Replication)。
优点如下:
完美的强一致性 + 自由的业务逻辑: 既保证了类似 Raft 的不丢数据、强一致读写,又解放了程序员——业务代码里允许任何复杂的事务、时间戳、多线程乱序。
没有执行阻塞: 从节点不需要按顺序去运算复杂的业务代码,它们只需要按顺序覆盖数据即可,速度极快,不会因为某条 SQL 太复杂而卡死整个集群。
主动复制的铁律是:先排队进日志,再按顺序计算(Log
Execute)。 被动复制的铁律是:先并发计算,再排队进日志(Execute
Log)。 在主动复制中,同样的场景在被动复制里流程如下:
- 并发计算(超车阶段):
- 客户端 1 发来100号命令(大计算),被分配给计算线程 A。线程 A 开始哼哧哼哧地算,预计要算 5 秒。
- 与此同时,客户端 2 发来101号命令(小计算),被分配给计算线程 B。线程 B 只需要 1 毫秒就自个儿算完了!
- 排队进日志(结果提交):
- 101号命令因为算得极快,率先把算好的状态结果(比如
Y=20)打包塞进 Raft 日志进行广播。 - Raft 瞬间通过多数派确认,101号命令成功返回给客户端 2。
- 5秒钟后,100号命令终于在线程 A 里算完了,才把结果(
X=50)塞进 Raft 日志去广播。
- 101号命令因为算得极快,率先把算好的状态结果(比如
被动复制当然也会阻塞,但它的阻塞和主动复制的“流水线卡死”截然不同:
- 它堵在【业务数据锁】上: 如果100号和101号命令同时要去改账户
X的余额。100号抢到了锁要算5秒,那101号确实得等5秒。但注意:此时去改账户Y的102号命令依然一路畅通! 它的阻塞被局限在冲突的数据行上,而不是全集群卡死。 - 它堵在【大状态的网络传输】上: 如果100号命令导致了全表100万行数据的修改,主节点算完后,需要把这 100万行的最终状态(巨大的 WAL 日志)跨网络广播给副本。如果网络带宽被这个超大日志挤爆了,后面的 101 号小日志确实会被堵在网络传输队列里。
- 并发计算(超车阶段):
缺点如下:
Leader 顶天压力: 所有的 SQL 解析、事务冲突检测、锁管理、业务计算、WAL 日志生成全堆在 Leader 一个人身上。
网络带宽开销大(State Shipping): 如果执行一个批量更新(比如更新 100 万行),Leader 必须把 100 万行修改后的具体数据日志全部跨网络广播出去,而不能只广播一句简短的 SQL。
在状态机复制架构+被动复制方案中,我们可以发现,领导者节点既要承担消息排序功能,又要承担计算功能,负担非常重。
在现代分布式系统中,提出了存算分离架构,也就是存储和计算分为不同节点。流程如下:
接单(命令到达计算层):
用户发来一个写请求。此时,某个无状态的计算节点(Compute Node)接单,作为这笔事务的“大总管”(计算主节点)。
锁盘(向存储层加锁):
计算层向存储层(Raft 集群)发送一个加锁指令。底层 Raft 的 Leader 收到后,在对应的这行数据上钉上一个“悲观锁”标记。这时候,其他任何计算节点想来动这行数据,都会被底层存储层无情拒绝,乖乖排队。
捞数(获取最新数据):
锁挂好后,计算层通过 Raft 存储层的 Leader 进行“强一致性读”,把这行数据的最新状态(比如
)安全地读进自己的内存。 搬砖(计算):
计算层疯狂燃烧自己的 CPU,运行复杂的业务逻辑(比如扣减、乘除法、判断各种业务条件),最终算出一个死板的、毫无悬念的结果(比如
)。 交卷(发送结果给存储层):
计算层把算好的最终状态结果(
)作为写请求,打包发送给底层存储层的 Raft Leader。 盖章(Raft 集群确保一致性):
存储层的 Raft Leader 收到结果,立刻将其变成一条 Raft 日志,疯狂广播给所有的存储副本(Followers)。当过半数的存储副本都在硬盘里“抄好答案”并返回确认后,Leader 宣布这笔数据正式提交(Commit)。
散场(释放锁):
数据安全落盘后,计算层长舒一口气,通知存储层解除刚才挂的锁,顺便给用户返回成功。
7. 同步复制和异步复制
**同步复制(Synchronous Replication)**是指主节点接收到客户端请求后,将该命令发送给副本节点,需要等所有副本节点返回接收消息,才能视为成功,返回结果。
**异步复制(Asynchronous Replication)**是指主节点接收到客户端请求后,主节点在自己本地处理成功后,就向客户端返回结果,之后才将数据异步复制给副本节点。
同步复制的优点是不会丢失数据,但是缺点为延迟高(需要等所有副本节点返回结果)、可用性低(如果其中一个副本节点下线,都会导致系统不可用)。
异步复制的优点是响应快、可用性高,但是缺点为存在丢失数据的风险(如果主节点刚给客户端返回了成功,还没来得及把数据异步发给副本,主节点就突然断电甚至硬盘坏了,会导致还没同步的数据丢失)。
为了妥协同步复制和异步复制的优缺点,提出了半同步复制(Semi-Synchronous Replication),即主节点收到数据后,不需要等“所有”副本都确认。只要**有任意一个副本(或者超过半数的副本)**收到了并返回确认,主节点就立刻给客户端返回成功。
在半同步复制中,如果需要等待超过半数的副本返回结果,那么也称为多数派复制(Quorum-based Replication)或共识算法复制(Consensus Replication)。相比于只等待一个副本返回的半同步复制(弱半同步复制),多数派复制在数据一致性、数据安全性上更好。
在最终一致性架构方案中,主要使用异步复制或弱半同步复制,因为最终一致性架构方案,追求的是高可用性。
在状态机复制架构方案中,主要使用多数派复制。在一些对可用性要求不高、但绝对不允许一丝一毫数据滞后的极严格 SMR 系统中(或者节点极少的情况,比如双机热备),会使用同步复制。