Appearance
时间、消息顺序与多播
本文介绍在分布式系统中时间的影响、消息顺序以及多播模型。 参考资料Distributed Systems Notes By Dr. Martin Kleppmann
1. 时间
在系统设计中,时间是非常重要的属性,例如操作系统会根据CPU时间来调度任务、日志追踪等。
时钟分为两种:
- 物理时钟:度量实际流逝的时间;
- 逻辑时钟:度量事件数量;
1.1 物理时钟
物理时钟包括基于钟摆或类似机制的模拟/机械时钟,以及基于振动石英晶体的电子时钟。
石英钟存在于大多数的手表、电脑、手机中,以及大量其他的生活用品。
赫兹(Hertz,符号:Hz)是频率的国际单位制单位,用来衡量周期性事件每秒钟发生的次数。
简单来说,如果一个动作在 1 秒钟内重复了 1 次,它的频率就是 1 Hz。
由于很多物理现象的速度极快,我们常用前缀来表示更大的赫兹数值:
- kHz (千赫兹):
Hz = 1,000 Hz - MHz (兆赫兹):
Hz = 1,000,000 Hz(常用于广播电台频率) - GHz (吉赫兹):
Hz(常用于电脑 CPU 主频和无线通信) 石英钟的原理是压电效应,如果给石英晶体施加电压,它会发生机械形变(微小的振动),石英晶体会以极高且极其稳定的频率振动——通常是 32,768 Hz(即每秒振动 32,768 次)。因此,通过监测石英晶体的振动频率,我们就可以计算物理时间的流逝。
石英钟便宜,但是并不完全精确,制作工艺、温度都会影响振动频率。
假设电脑A上的石英钟每秒振动32768次,电脑B上的石英钟每秒振动32800次,那么久而久之,两台电脑的时间差距将会越来越大,这称为时钟漂移(clock drift)。
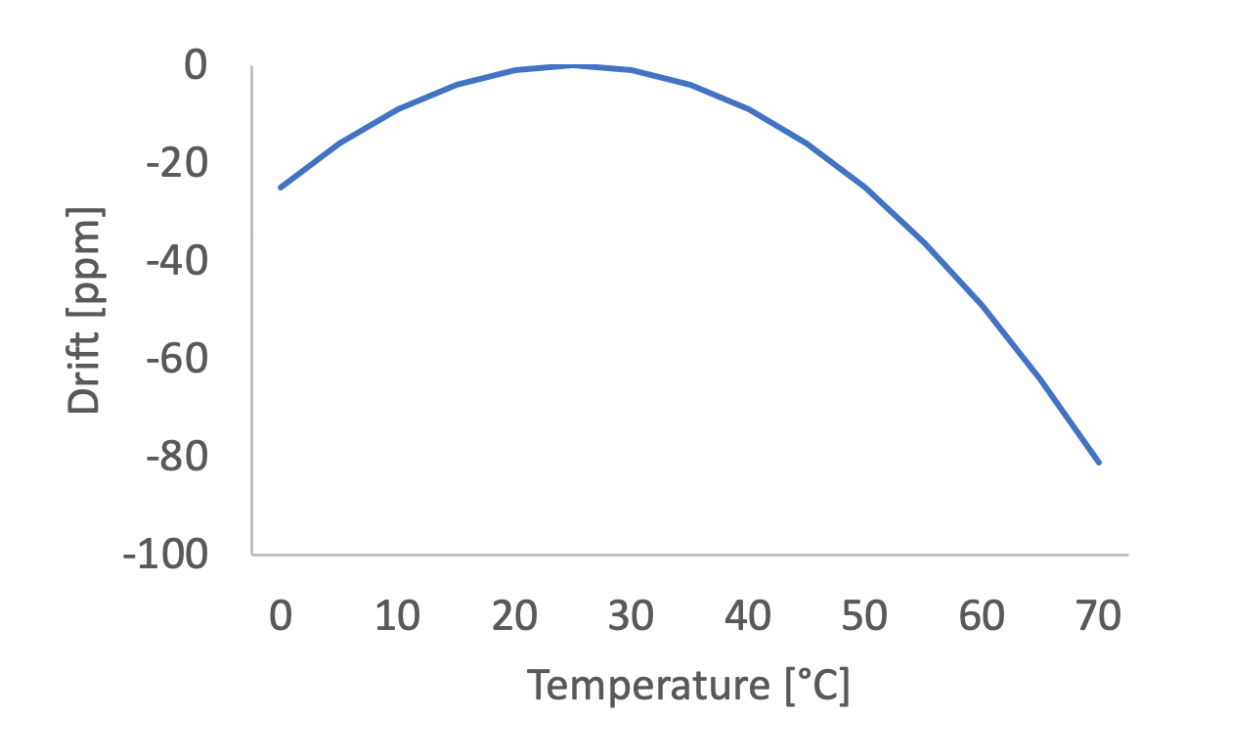
1 ppm = 1 microsecond/second = 86 ms/day = 32 s/year
为了获取更高的时间精度,会使用原子钟,例如铯-133 原子。原子钟是用“原子的能级跃迁信号”来数秒,原子的这种跃迁频率是自然界中最稳定的常数之一,不受温度、压力或湿度的影响,3百万年只有1秒的误差。
目前 1 秒的长度被定义为:铯-133 原子在基态的两个超精细能级间跃迁时,所辐射出的电磁波振荡 9,192,631,770 次(约 9.2 GHz)的时间。
但是,原子钟价格非常昂贵,不适合用于日常设备。
所以,为了获取高精度时间,我们可以从装备了原子钟的设备获取时间,例如GPS卫星。
1.2 物理时间
关于物理时间,现在有两种定义:
- 国际原子时 (TAI) :基于量子力学,也就是说基于原子钟的时间;
- 世界时 (UT1):基于天文学(地球自转),基于地球自转观测的时间,可以认为中午 12 点时,本初子午线一定正对着太阳方向(平太阳,一个假设的均匀运动的太阳);
在世界时的度量中,一天24小时是地球自转一周的时间;在原子时的度量中,一天24小时是铯原子震荡24 × 60 × 60 × 9,192,631,770次的时间。因为地球自转受潮汐力、地核活动等影响在不断变慢且不均匀,所以世界时的“秒”长实际上是不稳定的,因此世界时和原子时是有差距的。
天文学时间 (UT1) 的起点: 它是一个连续的历史演进过程。从古代开始,人类就以“太阳经过观测点中天”为正午。它的起点可以追溯到人类开始记录天象的时刻,本质上是地球在宇宙空间中的旋转角度。
原子时 (TAI) 的起点: 原子时的起点是人为规定的。1967年,科学家正式定义了“秒”。为了让新生的原子时与当时的天文学时间衔接,科学家们规定:将 TAI 的起点(历元)定在 1958 年 1 月 1 日 0 时 0 分 0 秒。
在那一瞬间,TAI 和 UT1 是完全对齐的。
但是,地球自转速度在长期变慢,这意味着,“天文秒”比“原子秒”稍微长那么一点点,截止到2026年,天文时已经比原子时落后了37秒。
为了协调两者之间的差距,协调世界时UTC(Coordinated Universal Time)被提了出来:
- 频率跟随 TAI:UTC 的“秒”长和原子时 TAI 完全一致。
- 相位跟随 UT1:为了不让 UTC 偏离昼夜交替太远,规定 UTC 与 UT1 的差距必须保持在 0.9 秒以内。
- 闰秒 (Leap Second):当两者快要超过 0.9 秒时,UTC 会通过增加 1 秒(闰秒)来等待变慢的地球。
可以用以下关系来表达它们在某一时刻的状态:
TAI 与 UTC 的关系:
这里的
是累计插入的闰秒总数。截至目前, 秒(即原子时比天文时快了 37 秒)。 UTC 与 UT1 的关系:
这是通过插入闰秒强制维持的差值。
在日常中,我们使用的时间就是UTC。
由于UTC需要与天文学时间UT1保持差距在1秒内,因此当UTC在每年的 06-30 23:59:59或12-31 23:59:59时,会出现以下情况:
- 马上跳到00:00:00,也就是说时钟跳过了1秒,称为负闰秒(negative leap second);
- 1秒后跳到00:00:00,正常情况;
- 1秒后跳到23:59:60,再过1秒后,跳转到00:00:00,也就是说时钟多了1秒,称为正闰秒(positive leap second);
由于天文学的秒比原子秒慢,因此现在还没有出现负闰秒的情况,都是正闰秒。
由于闰秒的存在,一小时并不总是3600秒,可能是3601秒或3599秒,同理,一天也不总是86400秒,也可能是86401或86399秒。
1.3 计算机中的时间
计算机(尤其是 Linux/Unix 系统)通常使用 POSIX 时间(Unix Timestamp),它假设每天只有 86,400 秒(
当 UTC 插入闰秒时,这一天实际上有了 86,401 秒。此时,计算机的时间与现实中实际使用的时间就有了1秒的差距。
计算机需要处理闰秒,有三种处理方式:
- 回拨:如果需要插入闰秒时,即到达 60 秒时,系统时钟回跳回 59 秒,此时在系统中,就可能看到有两个59秒;
- 弥散(Smearing):如果发生了闰秒,弥散做法是将 1 秒分散到一整天,即让这一天的一秒变得快一点或慢一点;
- 忽略:即忽略闰秒的存在,在闰秒发生的瞬间,标准 UTC 时间多出了一秒(
23:59:60),而忽略闰秒的系统会直接跳到下一天的00:00:00;这种情况下,NTP(Network Time Protocol,网络时间协议)会介入修正时间;
TIP
NTP是什么?全称是 Network Time Protocol(网络时间协议),专门用于将计算机的网络时钟同步到某种标准时间源(通常是 UTC)。
由于原子钟价格高昂,计算机内部使用石英钟,但石英晶振并不完美,受温度和硬件质量影响,每天可能会产生几毫秒甚至几秒的误差,即时钟漂移。
- 如果不对表:分布式系统中的多台服务器时间会差距过大;
- 后果:日志顺序错乱、金融交易重叠、甚至导致分布式数据库写入冲突;
NTP 采用一种类似树状的分层架构,每一层被称为一个 Stratum:
- Stratum 0:根源设备。如原子钟、GPS 卫星。它们本身不联网,而是直接连接到计算机。
- Stratum 1:一级服务器。直接连接 Stratum 0 设备的计算机,它们是网络上最准确的时间源。
- Stratum 2:二级服务器。通过网络向 Stratum 1 请求时间,再分发给更多的下级设备。
- Stratum 3 及以下:普通的终端设备(如电脑、手机、服务器)。
NTP的工作流程如下:
- 发出请求:客户端记录发送瞬间的时间戳
。 - 到达服务端:服务端记录接收瞬间的时间戳
。 - 服务端响应:服务端处理完请求发送时记录时间戳
。 - 回到客户端:客户端接收到响应时记录时间戳
。
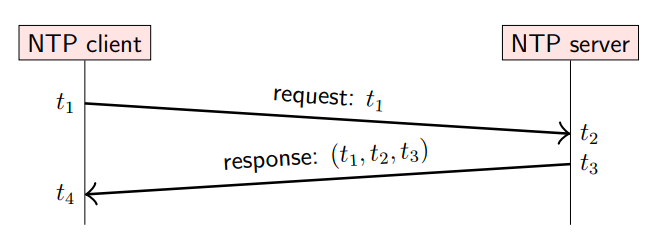
客户端收到响应后,进行如下计算:
- 首先计算往返网络延迟:
- 然后估算从服务器到客户端的单程网络延迟:
- 估算客户端应该收到响应的时间戳:
- 计算时间偏差:
当计算出时间偏差后,客户端有两种处理方式:
- 渐进(Slew):如果差距较小,它会微调 CPU 的时钟频率,让时间跑得稍微快点或慢点,直到对齐。这种方式对分布式系统更安全;
- 步进(Step):如果差距较大,直接强行把表拨快或拨慢,即直接把时间设置为正确的时间。这可能导致时间“跳变”;
特殊情况下,如果时间差距很大(默认情况下,超过15分钟),NTP客户端认为发生了错误,不会重置时间。
由于NTP机制的存在,计算机时间可能会发生跳变,也就是说时间会突然往前或往后跳。对于任何基于计算机时间来计算流逝时间的程序,这将是一个问题,例如:
java
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
doSomething(); // 在这期间,由于NTP的影响,计算机可能会发生跳变,会导致耗时不准确
long endTime = System.currentTimeMillis();
long elapsedTime = endTime - startTime;
}
public static void doSomething(){
// ...
}System.currentTimeMillis()是用于获取计算机真实时间的,即获取从1970-01-01 00:00:00到现在的毫秒,当NTP发生跳变时,System.currentTimeMillis()也会有影响,最终,elapsedTime不准确,甚至可能为负数。因此,System.currentTimeMillis()不适合用于测量流逝的时间。
为了避免NTP跳变的影响,保证时间一直是往前走的,在Java中还有System.nanoTime()这一方法,这是单调时钟。所谓单调时钟,就是不受NTP跳变影响,时间一直往前走,但是,往前走的快慢仍然会受NTP渐进(slew)调整的影响。单调时钟可以用来测量消逝的时间,但是,单调时钟的时间戳是没有意义的,因为单调时钟的起点是随机的,例如JVM启动时间,因此,比较两台计算机的单调时钟也是没有意义的。下面代码使用单调时钟计算某段代码的耗时:
java
public static void main(String[] args) {
long startNanos = System.nanoTime();
doSomething();
long endNanos = System.nanoTime();
long elapsedNanos = endNanos - startNanos;
}
public static void doSomething(){
// ...
}2. happens-before关系
2.1 happens-before与causality
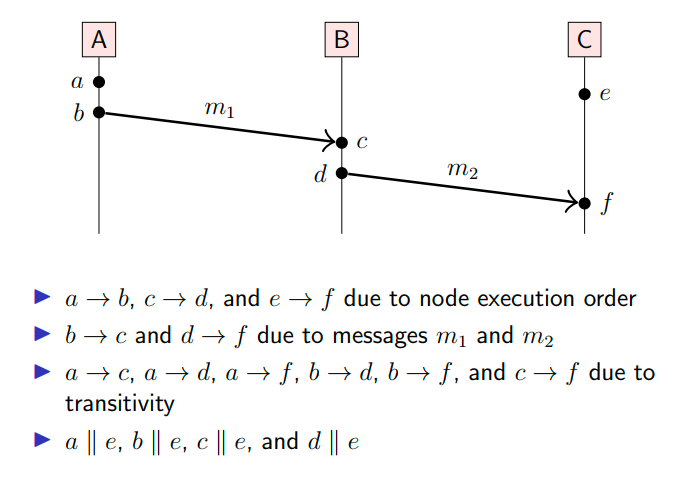
事件(event)是指在一个节点上发生的某件事,例如发送消息、接收消息或者本地的步骤执行。
如果事件
happens-before 靠以下三条基本规则建立:
- 程序顺序规则(Program Order):在同一个进程(或线程)中,按照代码顺序,前面的事件
先行发生于后面的事件 。 - 消息传递规则(Message Passing):一个进程发送消息的事件
,先行发生于另一个进程接收该消息的事件 。 - 传递性(Transitivity):如果
且 ,那么 。
如果两个事件之间无法通过上述规则推导出 happens-before 关系,那么这两个事件就是并发的(Concurrent)。也就是说,它们在逻辑上没有先后顺序,记做
如下是一些happens-before例子:
**因果关系(Causality)**是指一个事件(因)导致了另一个事件(果)的发生,两者之间存在着驱动或依赖的必然联系。
在不同学科中,如何确定两件事的因果关系,有着不同的标准。
如果事件A happens-before 事件B,那么关于事件A和事件B的因果关系,从现实来说,只能认为事件A可能影响了时间B的发生,即happens-before是因果关系的必要条件,但不是充分条件。
必要条件:要想发生B,A是必须具备的条件,但有了A不一定能保证B发生。
充分条件:只要有A,就一定会有B。
但是,因果关系是一个哲学问题,在计算机中无法完全确认两个事件的因果关系,因此在分布式系统中,如果 A happens-before B,那么就认为 A 和 B 具有因果关系。
为什么要确认因果关系(即happens-before关系),是因为因果顺序不能调换,先有因,才能有果。如果两个事件具有因果关系,那么不同节点,接收这两个事件的顺序就必须是先因后果。
2.2 消息顺序问题
我们来看这样一个场景,用户(节点)A向用户B和用户C发生消息m1;用户B接收到m1消息后,向用户A和用户C发送消息m2(假设m2是对m1的回应);由于网络问题,m1消息到达用户C有延迟,导致在用户C看来,先接收到消息m2,再接收到消息m1,示意图如下:
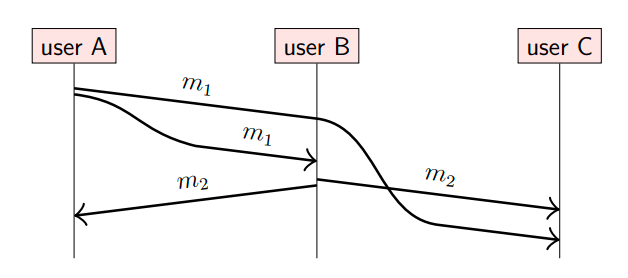
也就是说,m1 happens-before m2,即m1是因,m2是果。在用户C看来,结果就让人迷惑不解,怎么先看到果,再看到因?
将以上场景以计算机领域问题为例,假设m1是创建数据表stu,m2是向表stu中插入一条数据,如果节点C先看到插入操作,再看到建表操作,并按照这种顺序执行,那么就会导致问题。
为了保证消息顺序,我们可以在发送消息时,带上节点时间戳,即(t1,m1)和(t2,m2)。但是,由于时钟漂移的原因,使用物理时间戳仍然不能决定消息顺序,例如,假设节点A的时间稍微比节点B的时间快,假设现在节点A的时间是12:00:00.500,节点B的时间是12:00:00.000,即节点A发出消息m1时,时间-消息对是(12:00:00.500, m1)。假设消息m1到达节点B的网络延迟是200毫秒,在节点B处理消息耗时100毫秒,那么节点B发出消息m2时,时间-消息对是(12:00:00.300, m2)。
并且,由于网络延迟的原因,节点C仍然先接收到m2消息,然后接收到m1消息。此时节点C认为m2消息是因,m1消息是果,如下图所示:
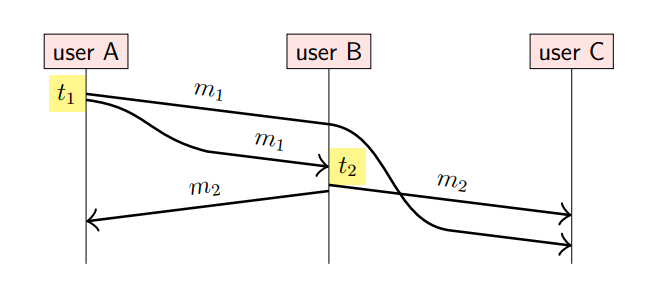
可见,即使使用了物理时间戳,由于时钟漂移的问题,仍然无法判定事件顺序。
3. 逻辑时钟
物理时钟是计算流逝的时间,而逻辑时钟是计算发生的事件。
只要 a happens-before b,那T(a) < T(b),其中T(a)、T(b)表示a、b的逻辑时间。
接下来介绍两种逻辑时钟:Lamport时钟和Vector时钟。
3.1 Lamport 时钟
Lamport时钟描述如下:
- 首先,在每个节点初始化时,维护一个本地变量
t(通常为一个整数),即逻辑时间,用于统计发生的事件; - 当有本地事件发生时,将逻辑时间加1,即
t=t+1; - 当需要发送消息m时,将逻辑时间加1,然后将逻辑时间t和消息m一起发送,即
(t,m); - 当接收到消息
(t' , m')时,将t'与本地逻辑时间t取较大值,然后将本地逻辑时间设为较大值+1,即t = max(t', t) + 1;
伪代码如下:
txt
on initialisation do
t := 0 ⊲ each node has its own local variable t
end on
on any event occurring at the local node do
t := t + 1
end on
on request to send message m do
t := t + 1;
send (t, m) via the underlying network link
end on
on receiving (t′, m) via the underlying network link do
t := max(t, t′) + 1
deliver m to the application
end onLamport时钟具有如下特点:
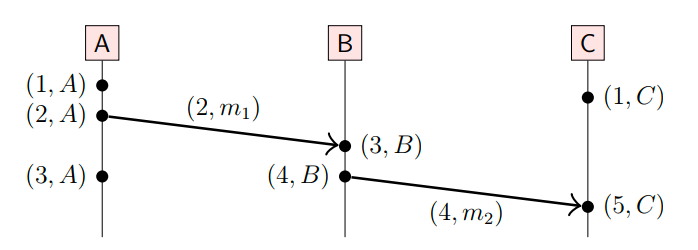
- 如果 a happens-before b,那么T(a) < T(b),其中T(a)、T(b)表示a、b的Lamport逻辑时间;
- 但是,如果T(a) < T(b),我们不能推断出 a happens-before b,只能确定 b not happens-before a,如下的(3, A)和(4, B);
- 如果 T(a) = T(b),也不能说a、b事件是同一事件,如下的(3, A)和(3, B);
Lamport时钟例子:
3.2 Vector 时钟
给定两个事件的Lamport时间,我们无法确定两个事件的先后关系,因此,Vector 时间被提出来解决这个问题。
Lamport 时间使用一个整数来表示逻辑时间,而Vector使用整数列表来表示逻辑时间。描述如下:
- 假设在分布式系统中有n个节点,
; - 每个节点都有逻辑时间,记录当节点本地发送的事件数量,即
节点上有逻辑时间 ; - 从整个分布式系统上看,有n个节点,那所有节点的逻辑时间,就可以形成列表,记为
,注意,每个节点都会记录其他节点的逻辑时间,可以使用Map结构时间,其中key为节点ID,value为该节点的逻辑时间; - 当在节点
发生事件(包括发送消息)时,将节点 上的逻辑时间 ,即 ; - 当节点
发送消息m时,将该节点记录的全局逻辑时间随同该消息m一起发送,即 ; - 当节点
接收到消息时,逐一对比接收到的全局逻辑时间与本地逻辑时间,取两者之间的较大值,更新为 的本地时间,然后将 的本地时间+1(表示接收消息);
伪代码如下:
txt
on initialisation at node Ni do
T := 〈0, 0, . . . , 0〉 ⊲ local variable at node Ni
end on
on any event occurring at node Ni do
T[i] := T[i] + 1
end on
on request to send message m at node Ni do
T[i] := T[i] + 1;
send (T, m) via network
end on
on receiving (T′, m) at node Ni via the network do
T[j] := max(T[j], T′[j]) for every j ∈ {1, . . . , n}
T[i] := T[i] + 1;
deliver m to the application
end on下面是Vector时间例子:
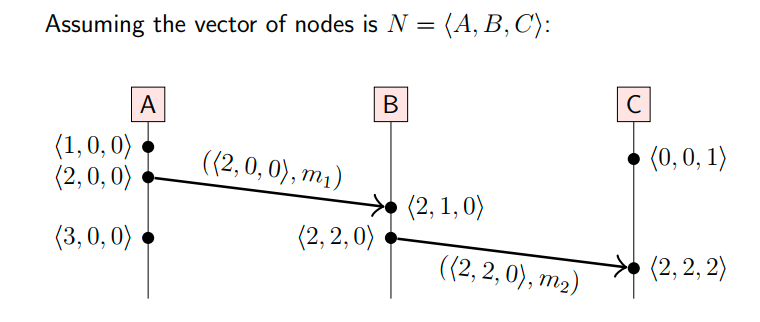
在Vector时间中,每个事件都关联一个Vector时间,例如B节点发送消息m2事件关联Vector时间为[2,2,0],表示在这个事件发生之前,A节点的2个事件,B节点的2个事件(包括自身),C节点的0个事件是已知的。
关于Vector时间,我们定义如下规则(假设系统中有n个节点):
当且仅当 ; - $T \le T' $ 当且仅当
; 当且仅当 ; 当且仅当 ;
对于两个事件a、b,各自的Vector时间分别设置为 V(a)、V(b),那么有如下属性:
假设在一个三节点的系统(假设节点为
由于
注意,Vector只能确定两个事件的先后关系,如果两个时间不可比,例如
3.3 全序与偏序
偏序 vs 全序的核心区别在于:集合里的任意两个元素,能不能都拉出来“比个大小”。
偏序(Partial Order)
定义: 集合中只有部分元素之间可以比较大小,有些元素之间是无法比较的(称为并发或独立)。
通俗例子: 观影列表,《复仇者联盟 1》
《复仇者联盟 2》 《复仇者联盟 4》,必须先看 1 才能完全看懂 4,这是可比的。但《复仇者联盟 1》 和 《流浪地球》,这两部电影在剧情上毫无关联,先看哪部、后看哪部,甚至两台电脑同时放,都不会影响对彼此剧情的理解,这就是不可比。 特点: 允许“并列”或“不相关”的存在。
全序(Total Order)
定义: 集合中的任意两个元素都必须能比较大小,不能存在“无法比较”的情况。
通俗例子: 实数轴(1, 2, 3...) 或者 考试成绩排名。任意两个人,要么 A 分数高,要么 B 分数高,要么并列(也可以通过学号区分,强行分出先后)。
特点: 所有元素排成一条绝对的直线,没有分叉。
在分布式系统中,happens-before、Lamport时钟、Vector时钟的特点如下:
Happens-before(因果关系):是一种偏序关系。
如果两个事件
和 发生在不同的进程,且它们之间没有任何消息往来(无论直接还是间接),那么它们就无法确定先后。我们称 和 是并发的(Concurrent,记作 )。 Lamport 时间:是一种全序关系(通过加偏门规则)
如果单纯看时间戳,可能两个节点都产生了时间戳
3。为了强行排出全序,Lamport 规定:如果时间戳相同,就比节点 ID(比如节点1 小于 节点2的 )。这样,所有事件都能排成一条绝对的线。Vector 时间:是一种偏序关系
向量时钟完美契合了 Happens-before 的偏序本质。即对于两个向量,如果不能推出大于或小于关系,那么表示两个事件是并发的,即不可比。
总结对比表
| 概念 | 本质是全序还是偏序? | 一句话大白话 | 关键特征 |
|---|---|---|---|
| Happens-before | 偏序 | 分布式系统中“因果关系”的定义。 | 有因果的能比,没因果的(并发)不能比。 |
| Lamport 时间 | 全序(强行加进程ID) | 用一个数字强行给所有事件排个绝对的一二三名。 | 简单,但无法通过数字大小认出因果关系。 |
| Vector 时间 | 偏序 | 用一组数字精准记录每个事件了解到的历史。 | 完美还原因果关系,能一眼看出两个事件是否是并发的。 |
4. 多播算法
4.1 介绍
在许多网络中,只提供点对点通信,也就是消息只发送给一个接收者。
多播,就是在点对点通信基础上,将消息发送给多个接收者。
在多播算法中,需要理解**接收(receive)和交付(deliver)**两个概念:
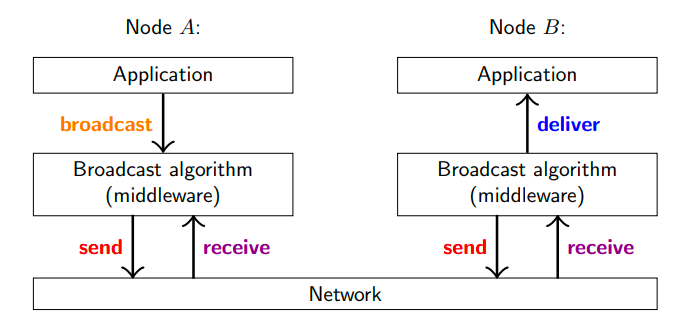
- 接收:是指中间件(多播算法)接收到消息;
- 交付:是指中间件将消息传输给上层应用;
在接收和交付之间,是有延迟的,中间件可能缓存消息,然后再交付。
多播算法,需要解决两个问题(即接收和交付两个问题):
- 如何确保每条消息都能被每个节点接收?
- 如何确保交付消息的顺序是正确的?
4.2 接收问题
我们来看下面这样一个场景,节点A使用可靠连接(重传+去重)发送消息m1给B和C节点,但是由于网络原因,消息在到达节点B过程中丢失了,而节点A在重传之前也崩溃了,此时,节点B就永远接收不到消息m1了:
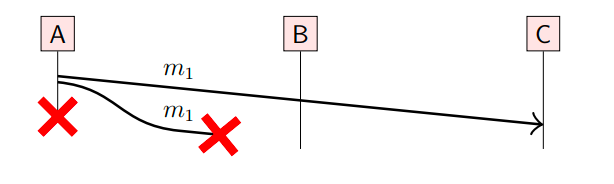
为了确保每条消息都能被每个节点接收,我们可以借助消息接收者,让消息接收者再传播消息。在不可靠的底层网络(Best-effort)之上,多播算法主要根据**“何时触发重传”**分为两种核心思想:
- 主动思想: 节点收到消息后立刻主动扩散消息:
- Eager Reliable Broadcast:收到就强行向所有人转发,无故障时开销大(
),但容错极高; - Gossip Protocols:收到后定期随机挑选邻居口口相传,属于概率性保证,扩展性极强;
- Eager Reliable Broadcast:收到就强行向所有人转发,无故障时开销大(
- 被动思想: 平时节点各过各的,绝不盲目转发,只有触发特定条件(检测到发送者下线了)才重传;
4.2.1 Eager reliable broadcast
Eager reliable broadcast的思想是,在一个有n个节点的系统中,每个节点在第一次接收到消息时,会将该消息转发给其余 n-1 个节点。
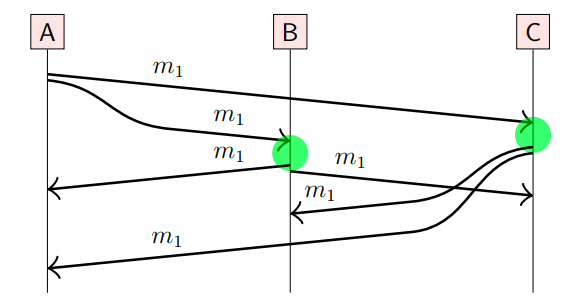
这种算法可以有效解决消息丢失的问题,但是代价是效率低下,在没有节点故障的条件下,每条消息会被发送
4.2.2 Gossip protocols
为了解决Eager reliable broadcast效率低下的问题,很多优化算法被提了出来,例如Gossip协议。
Gossip协议的主要思想是,如果一个节点要广播消息,她不会将消息发送给全部节点,而是随机选取几个节点进行广播;接收到消息的节点,又随机选取几个节点进行广播,依次类推,最终所有节点都会收到消息。
Gossip算法的优点是资源消耗小,但缺点是并不保证所有节点都会收到消息,假设在随机节点选取过程中,某个节点总是被忽略,那么该节点就收不到消息,并且Gossip算法对于消息到达所有节点有延迟,即消息可能要在网络里晃荡好几秒,所有节点才能接收到消息。
但通过合理的参数配置,大概率下,使用Gossip算法会使得所有节点都收到消息。
4.2.3 Lazy reliable broadcast
Lazy reliable broadcast是相对于Eager reliable broadcast而言的,Eager reliable broadcast是接收者在第一次接收到消息后,转发该消息给所有发送者,但Lazy reliable broadcast并不是,它要求只有在检测到发送者崩溃下线时,才会转发消息。
在学术理论中,Lazy reliable broadcast是基于Best-effort连接+完美故障检测器实现的,即仍然使用Best-effort连接发送消息,然后完美故障检测器发现发送者崩溃后,启动Lazy reliable broadcast算法,具体如下:
- 首先,发送者在发送消息时,会给每条消息打上唯一的标签,即节点ID+消息序列号;
- 接收者在接收到消息后,会把该消息缓存起来;
- 一旦完美故障检测器触发
crash(sender)事件,所有活着的节点在同一个逻辑时刻都会醒过来,并且每一个节点都会立刻调用bebBroadcast(尽力而为广播)把自己手里所有的来自崩溃发送者的历史缓存消息广播出去;
在学术理论中,Lazy reliable broadcast有一个缺点:当发送者节点下线后,如果所有节点都广播缓存消息,会造成网络风暴,占据大量带宽。
因此,在工程落地Lazy reliable broadcast时,做了以下改进:
如果接收者检测到发送者健康存活,接收者因为网络抖动漏掉了
seq=4的消息(直接收到了序号为 5 的消息),它不会惊动全网,而是通过点对点(Unicast)向发送者发起一个 NACK 请求:“我缺了 4,请补发”。发送者从本地缓存掏出 4 定向补发。整个过程对其他节点完全透明。如果接收者检测到发送者下线,首先为了防止网络分区带来的“误判误杀”,接收者会发起局部投票。只有当超过半数(Quorum)的存活节点都一致认为发送者“下线”了,故障恢复流程才合法启动。
为了避免网络风暴,存活节点绝对不立刻广播完整的历史消息体。大家只在存活节点间广播极其轻量的“状态摘要”(例如:节点 A 喊一句:“我手里的遗产到
seq=9”,节点 B 喊一句:“我手里的遗产到seq=10”)。所有存活节点互相查漏补缺,最终全员对齐到存活的最高序列号(即
seq=10)。
4.3 交付顺序问题
我们通过以上算法,实现了消息的可靠传输,即保证每条消息都能被每个存活节点接收。
为了保证交付顺序,即避免出现节点A先后发出消息m1和m2,节点B先接收到消息m2,然后交付m2,之后再接收到m1并交付的问题,必需解决消息交付顺序问题。
下面介绍一些算法,规定并解决了消息交付顺序。
4.3.1 FIFO broadcast
在FIFO多播算法中,规定如果m1和m2都是由同一个节点发出的消息,并且是 send(m1) → send(m2),那么在任何节点上,m1必须先于m2交付。
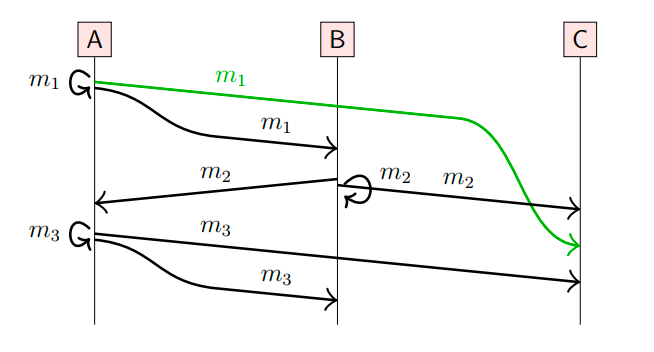
如上展示了在一个三节点的系统中,如果按照FIFO实现多播算法,那么m1必须先于m3交付,所以以下的交付顺序都是有效的:
(m2, m1, m3),(m1, m2, m3), (m1, m3, m2)
从以上交付顺序中,我们可以看到,m2在m1之前交付也是有效的,但可能是不合理的,如果send(m1) happens-before send(m2)。
所以,FIFO多播算法只规定了同节点消息交付顺序,没有规定不同节点的消息交付顺序。
TIP
注意,在上图中,m1, m2, m3 在发送时,都有一个回环箭头,表示在该节点广播的消息也会发送到该节点。
4.3.2 causal broadcast
causal 广播规定,如果send(m1) → send(m2),那么m1必须先于m2交付,即在FIFO的基础上,规定了不同节点的消息交付顺序。
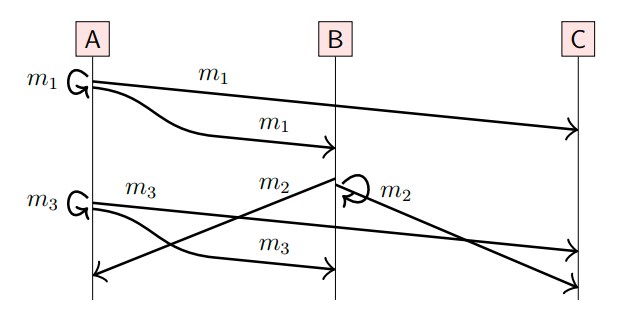
如上,我们有两个happens-before关系需要满足:send(m1) → send(m3), send(m1) → send(m2),但是send(m2)和send(m3)的关系无法确定,因此以下两个消息交付顺序都是有效的:
(m1, m2, m3), (m1, m3, m2)
4.3.3 total order broadcast
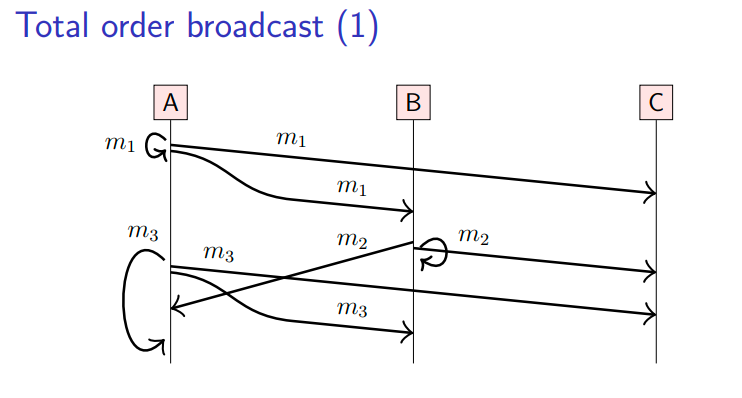
total order 广播算法规定,在所有节点上,消息的交付顺序必须完全一致。
例如以上causal 广播算法案例中,节点B以(m1, m2, m3)顺序交付消息,节点C以(m1, m3, m2)顺序交付消息,这就不符合total order广播算法。
为了实现total order广播算法,需要节点缓存消息,这就是为什么消息需要发送到本身节点上的原因(回环箭头)。
如下图,在所有节点上,消息以(m1, m2, m3)顺序交付(节点A需要缓存m3消息,等待m2消息才进行交付):
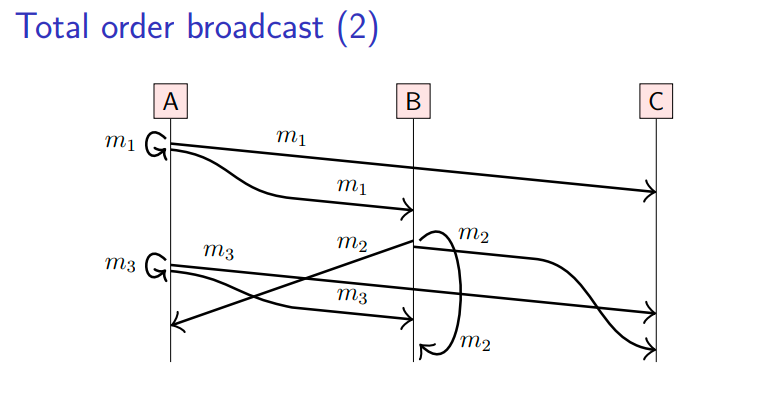
又或者如下图,在所有节点上,消息以(m1, m3, m2)顺序交付(节点B需要缓存m2消息,等待m3消息才进行交付):
4.3.4 FIFO-total order broadcast
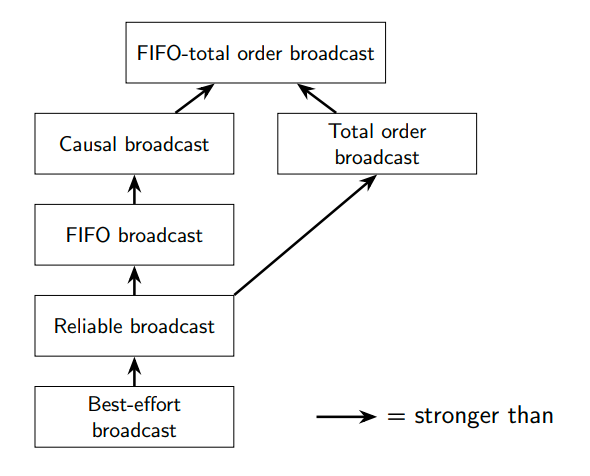
FIFO-total order广播算法,结合了FIFO和total order的特点:
- 同一节点发送的消息必须按序交付;
- 所有节点按同一顺序交付消息;
FIFO-total order广播算法暗含了causal广播算法。假设跨节点的因果交互 (
- 因果要求:节点
是先收到 ,然后才发送 的。也就是说,在节点 的视角里,时间线上 发生于 之前。为了满足因果律,所有节点都必须先收 再收 。 - 如何满足:
- 注意看节点
的行为:节点 已经收到了 ,并且还没有发送 (更别提收到自己发的 了)。 - 因此,在节点
本地,它的接收顺序必然是:先 ,后 。 - 此时,Total Order(全序) 站了出来。全序承诺:“只要有一个节点(这里是节点 B)的接收顺序是先
后 ,那么所有节点的接收顺序都必须是先 后 。”
- 注意看节点
整个广播算法关系图如下:
4.4 多播算法伪代码实现
4.4.1 FIFO算法实现
txt
on initialisation do
sendSeq := 0;
delivered := 〈0, 0, . . . , 0〉;
buffer := {}
end on
on request to broadcast m at node Ni do
send (i, sendSeq, m) via reliable broadcast
sendSeq := sendSeq + 1
end on
on receiving msg from reliable broadcast at node Ni do
buffer := buffer ∪ {msg}
while ∃sender, m. (sender, delivered[sender], m) ∈ buffer do
deliver m to the application
delivered[sender] := delivered[sender] + 1
end while
end on- 首先初始化节点,在每个节点初始化三个参数:
sendSeq:表示当前节点已广播的消息数量(也就是下一次广播的消息序号),初始化为0;delivered:表示在当前节点上,已交付的其他节点的消息序号,假设系统有n个节点,那么就有n-1个条目(去除自身),通常采用map实现,key为节点ID,value为在该节点上已交付的key节点消息数量;buffer:表示在该节点上缓存的待交付消息,每个缓存体由三部分内容组成:发送节点ID,消息序号,消息本身;
- 当节点
(表示该节点ID为 i)需要广播消息时,发送(i, sendSeq, m); - 当节点
接收到来自节点 的消息时: - 首先将该消息缓存起来,保存到
节点的 buffer中; - 然后循环判断缓存中是否存在消息,满足 发送者ID为
i,消息序号为delivered[sender],如果有,就把该消息交付给上层应用,然后继续判断; - 由于使用的是循环,所以会一次性把缓存中应该交付的消息全都交付了,而不是一次只交付一条消息;
- 首先将该消息缓存起来,保存到
4.4.2 causal算法实现
txt
on initialisation do
sendSeq := 0;
delivered := 〈0, 0, . . . , 0〉;
buffer := {}
end on
on request to broadcast m at node Ni do
deps := delivered;
deps[i] := sendSeq
send (i, deps, m) via reliable broadcast
sendSeq := sendSeq + 1
end on
on receiving msg from reliable broadcast at node Ni do
buffer := buffer ∪ {msg}
while ∃(sender, deps, m) ∈ buffer. deps ≤ delivered do
deliver m to the application
buffer := buffer \ {(sender, deps, m)}
delivered[sender] := delivered[sender] + 1
end while
end on首先初始化时,与FIFO一样,初始化三个值:
sendSeq、delivered、buffer;在广播消息
m时:- 构建
deps,deps是一个向量,表示当前消息m依赖,即其他节点要交付消息m,必须要先交付deps中所指明的其他依赖消息; deps的构建通过复制本地节点的delivered向量,然后节点把deps向量中属于它自己的那一个元素(deps[i])修改为它当前的sendSeq;- 最后,节点将
(i, deps, m)打包发送出去,分别代表节点ID、当前消息的依赖、消息本身;
- 构建
当在节点
接收到消息 m时:- 首先将接收到的消息保存进缓存;
- 然后,循环判断缓存中的消息,是不是满足已交付标准:即判断本地节点已交付消息
delivered是不是大于等于消息deps,如果是则已满足交付标准- 如果满足交付标准,将该消息交付给上层应用,然后从缓存中移除消息,并将该消息节点在当前节点已交付的序列号+1;
4.4.3 total order算法实现
total order 广播算法实现稍微复杂一点,主要有两种方式:
领导者方式
- 某个节点被选为领导者;
- 其他节点如果要广播消息,首先将该消息发送给领导者节点;
- 领导者节点通过FIFO顺序,将该消息广播出去,由此实现了全局有序;
但该方式的缺点是,如果领导者节点崩溃下线,会导致整个系统无法广播消息,选出新的领导者比较困难。
Lamport时钟方式
- 首先节点在广播消息时,将节点ID、Lamport时钟、消息体打包广播出去;
- 在交付消息时,按照全局有序的顺序交付,也就是先,先交付Lamport时钟小的消息,如果一致,则比较节点ID;
在实践中,使用Lamport时钟方式实现total order广播算法,基本不可用。
假设当前节点接收缓冲区里有一条消息
不能。 因为网络是有延迟的。可能此时此刻,另一个远在天边的节点在很久之前发了一条时间戳是
- 如果节点现在就把
交付了,等会儿 的消息到了,全序(Total Order)就被打破了(因为先交付了 5,后交付了 4)。 - 所以,节点遇到了囚徒困境:我怎么知道网络里还有没有比
更小的、还在路上的消息?我该等多久?
为了打破上面的困境,系统引入了两个强制条件:
- FIFO 链路(FIFO Links):保证同一个节点发出的消息不会在路上“超车”。如果节点
先发了时间戳 ,后发了时间戳 ,那么接收方必然是先收到 ,再收到 。 - 向所有人等待(Wait from every node):当节点收到时间戳为
的消息时,它不急着交付。它会去检查自己维护的接收状态,直到它收到了来自全网“每一个节点”发来的、时间戳 的消息。
但是,以上解决方案会有以下问题:
连接数爆炸,任意两个节点之间都要维护 FIFO 信道(通常通过 TCP 连接实现),那么在一个包含
个节点的系统里,全网的连接总数将达到: ,当节点数 增加时,连接数呈二次方( )级增长。每个连接都要占用内存缓冲区、文件描述符和心跳检测资源。 空消息风暴:算法要求:必须等待“每一个节点”送来一条时间戳
的消息。 假设系统里有 100 个节点,其中 99 个节点现在很闲,完全不发业务消息,只有 1 个节点在疯狂发送消息。
为了让全网能交付这唯一节点的业务消息,另外 99 个空闲节点必须不断地发送“空消息(Null Message)/ 心跳”,仅仅为了把自己的 Lamport 时间戳往前推进并告诉别人,这导致网络中充满了大量的控制报文,带宽和 CPU 都在空转。
参考资料
[1] Introduction to Reliable and Secure Distributed Programming:https://file.siu.edu.vn/Thuvien/tai-lieu-so-khoa-KT-KHMT/18_Introduction to Reliable and Secure Distributed.pdf