Appearance
Beat介绍
本文主要介绍Beat的概念,并以Filebeat为例,说明其使用方法。
1. 什么是Beat
Beat是Elastic Stack中的轻量级数据采集器,负责从各种数据源收集数据并将其发送到Elasticsearch或Logstash进行存储和分析。 Beat家族包括多种类型的Beat,如Filebeat、Metricbeat、Packetbeat等,每种Beat针对不同的数据类型和使用场景进行了优化。
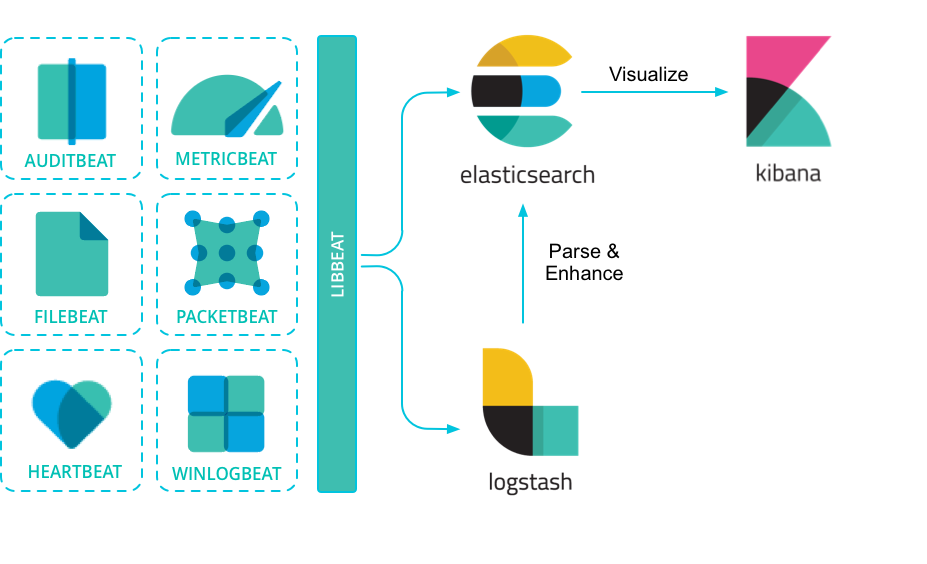
什么是LIBBEAT?
libbeat 是 Elastic Beats 框架的核心库(core library),简单来说,它是所有 Beats(比如 Filebeat、Metricbeat、Packetbeat 等)产品的底层基础和公共代码部分。
libbeat提供 Beats 框架的通用功能,例如:
- 配置解析(YAML 配置加载);
- 输出插件系统(支持 Elasticsearch、Logstash、Kafka、Redis、文件等输出);
- 采集器(publisher)管道和队列管理;
- ACK 机制和重试逻辑(保证数据至少投递一次);
- 监控指标暴露(/stats 接口);
- 日志系统;
- 信号处理、优雅关闭等;
所有官方 Beats(Filebeat、Metricbeat 等)都是在 libbeat 的基础上开发出来的轻量级代理(shipper),它们只实现自己特有的数据采集逻辑,其他通用的功能全部复用 libbeat。也就是说,libbaet是发送机,Filebeat、Metricbeat、Packetbeat 等只是在libbeat基础上拥有不同的车身外观。
2. Filebeat介绍
Filebeat,见名知意,主要是从文件中采集数据,发送到ES或logstash,更狭隘地说,是从日志文件中采集数据。
2.1 工作原理
当启动Filebeat后,会启动一个或多个input,用于读取在配置文件中指定的日志目录;对于定位到的每个日志文件,Filebeat会启动一个harvester。harvester会一行行读取日志文件中的内容,并将每行日志发送给libbeat(Beats的公共包),libbeat会将日志事件进行包装,并发送给在配置文件中指定的目的地。
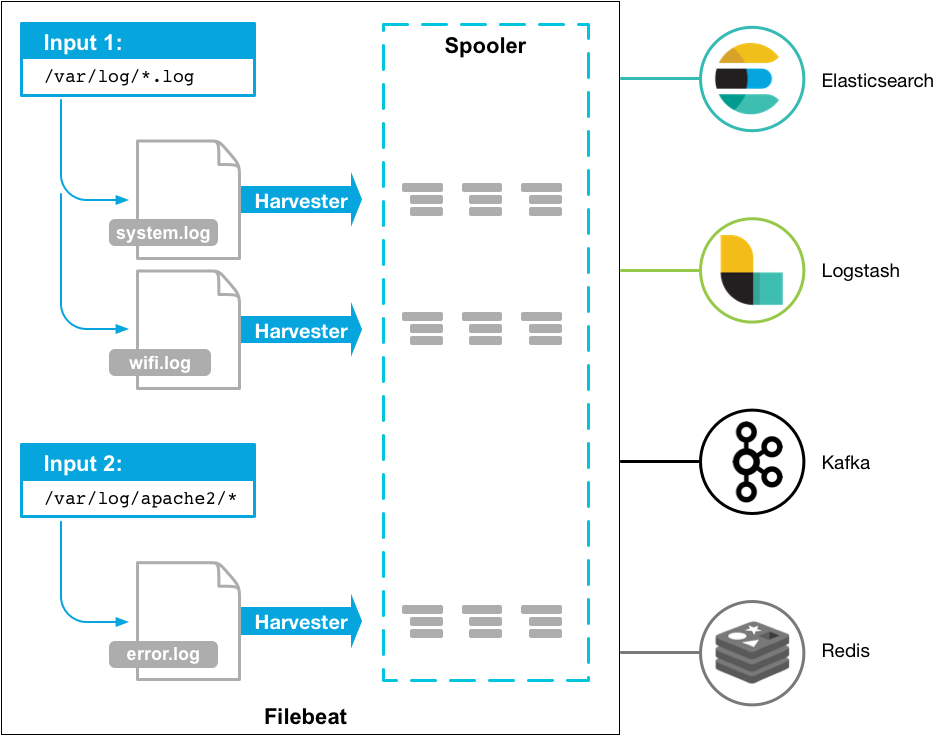
因此,Filebeat的两大组件为Input和Harvester。
2.2 快速开始
在开始之前,请确保ElasticSearch和Kibana已启动。下面的流程在MacOS上实现,并且ES和Kibana在Docker中运行。
ES和Kibana版本:7.17.28
首先,使用如下命令下载和解压Filebeat(注意版本一致):
bash
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.28-darwin-x86_64.tar.gz
tar xzvf filebeat-7.17.28-darwin-x86_64.tar.gz然后,在filebeat.yml配置文件中配置输出路径ElasticSearch的地址,以及Kibana的地址:
yaml
output.elasticsearch:
hosts: ["https://localhost:9201"]
# username: "filebeat_internal"
# password: "YOUR_PASSWORD"
# ssl:
# enabled: true
# ca_trusted_fingerprint: "b9a10bbe64ee9826abeda6546fc988c8bf798b41957c33d05db736716513dc9c"
setup.kibana:
host: "localhost:5601"然后,在filebeat.yml配置文件中配置要读取的日志文件路径:
yaml
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /Users/xxx/logs/nacos/config.log上述配置表示从/Users/xxx/logs/nacos/config.log日志文件中读取日志,并发送到ES中。
最后,启动Fileabeat:
bash
sudo ./filebeat -e上述命令以超级用户权限,在前台(Foreground)启动 Filebeat,并将所有 Filebeat 的运行时日志信息直接输出到你的终端屏幕上。
注意,在生产环境中,Filebeat 应该以服务(Daemon)的形式在后台运行,并使用标准的日志文件来记录状态,而不是使用
-e参数。
最后,观察ES中,会发现多了一个索引:
接下来,配置Kibana,在Kibana中查看索引数据。
首先,在Management中选择Stack Management,然后在Kibana下选择Index Patterns,右上角选择Create index pattern:
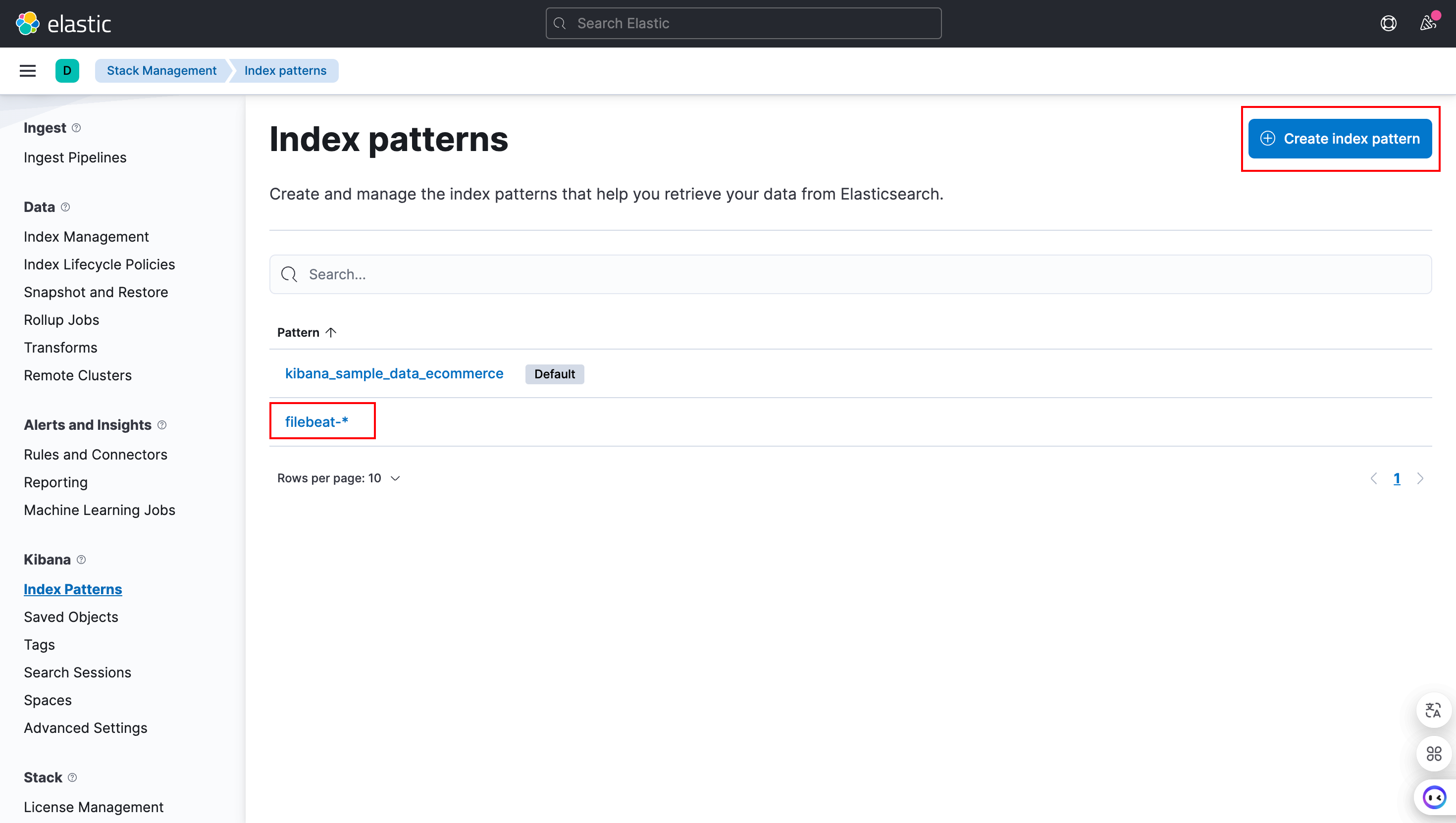
在Name处输入filebeat- ,在Timestamp field处选择*@timestamp**:
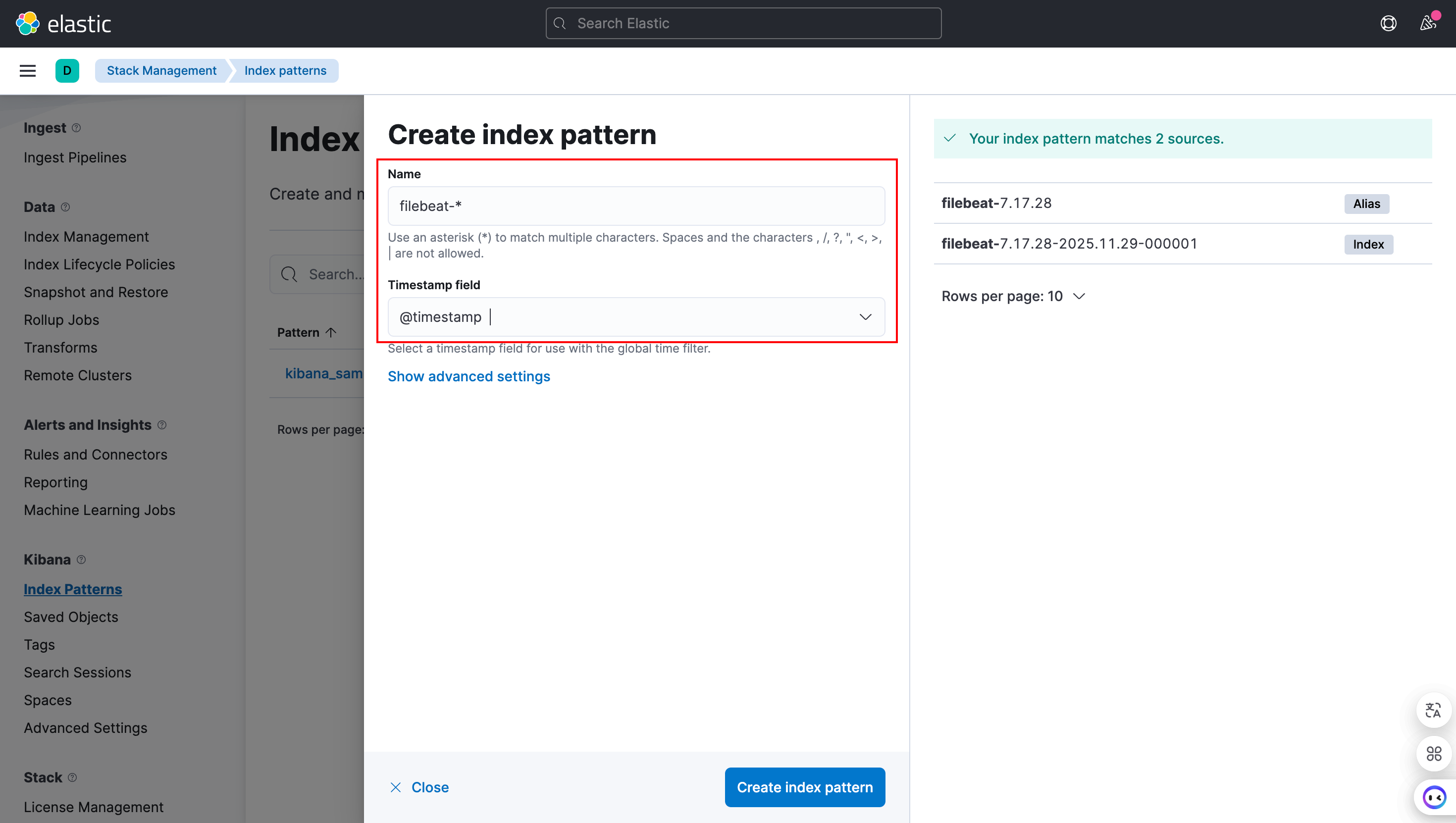
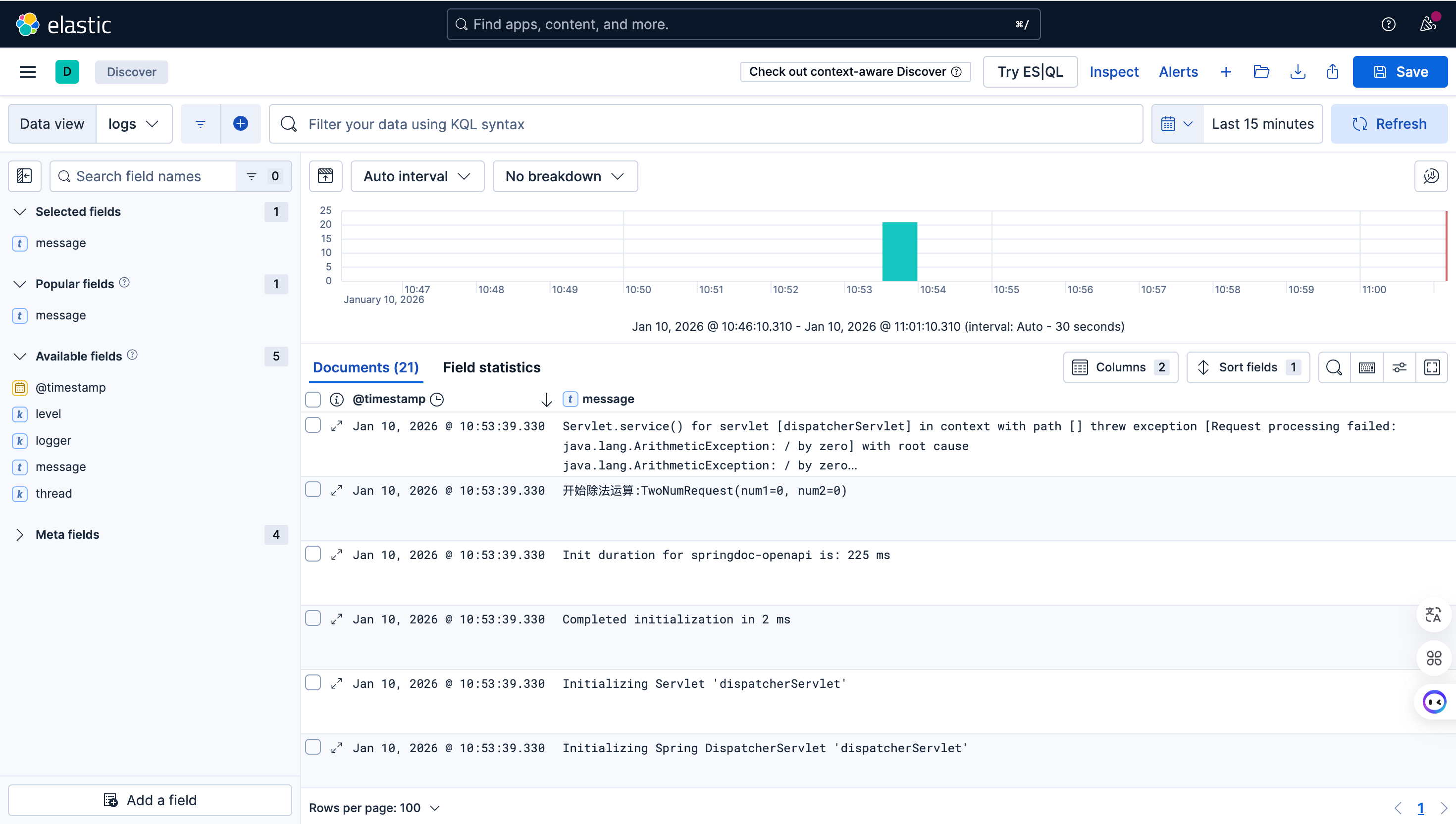
配置了之后,我们就可以在Kibana的Discover中查看数据了:
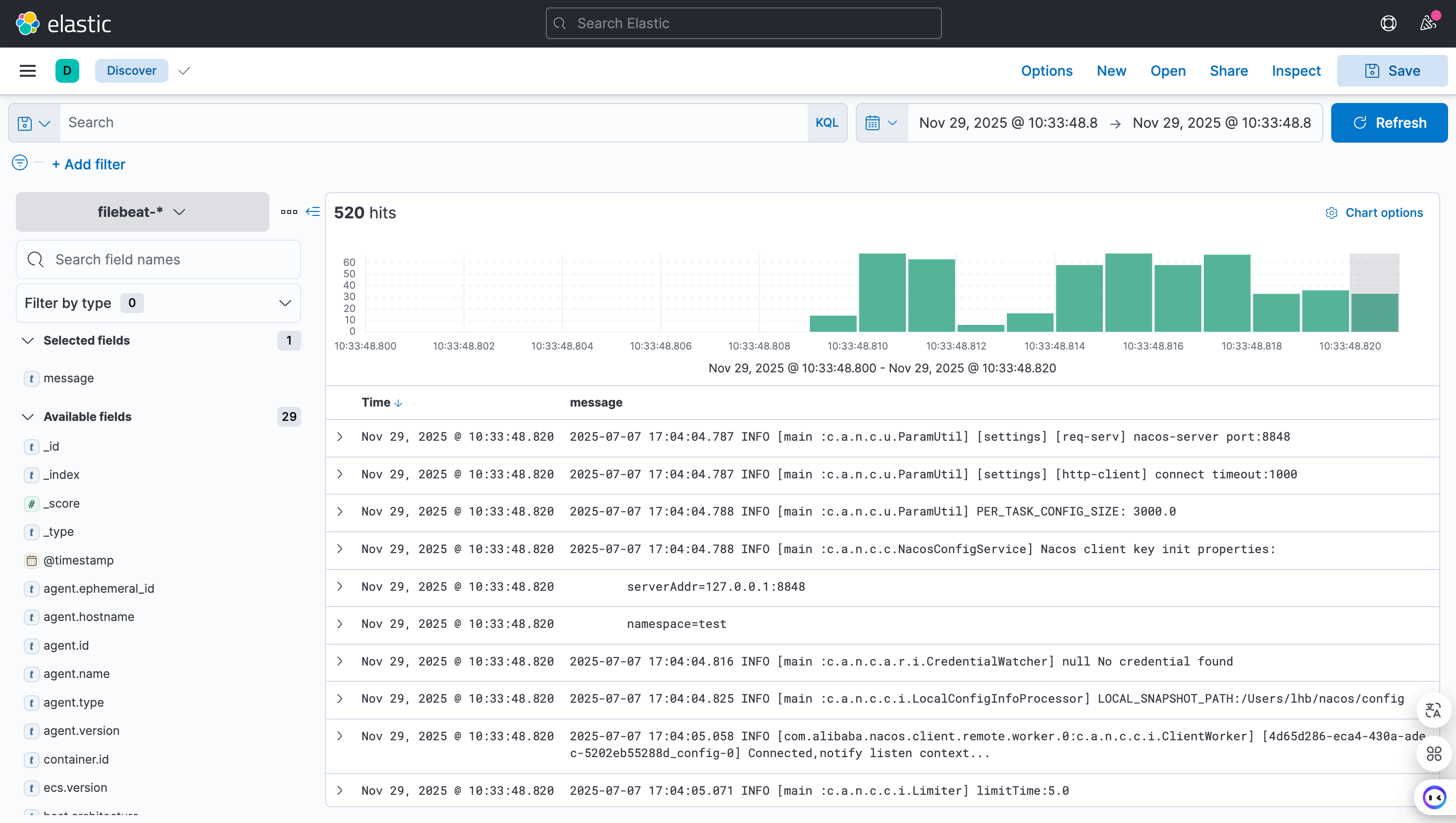
2.3 重要配置介绍
本小节介绍Filebeat的配置。
2.3.1 Inputs
Filebeat Inputs用于定义Filebeat要获取的数据在哪,这是一个数组,所以每个input以-开始。
类型为filestream的input的属性如下(参考链接):
type:公共属性,用于指定input的类型,如果是从文件中获取数据,则类型为
filestream,完整的类型列表如下:https://www.elastic.co/docs/reference/beats/filebeat/configuration-filebeat-options#filebeat-input-types。在inputs数组中,可以指定多个类型相同的input;id:公共属性,input的唯一标识符,在inputs数组中,必须唯一;
enabled:公共属性,标识input是否启用;
paths:用于指定要读取的文件或路径,数组;路径满足glob模式;
glob模式
是一套用于匹配文件路径名的模式匹配规则,简单来说,它是一种通过使用通配符 (Wildcards) 来描述文件或目录路径集合的方法。
通配符 含义 作用 示例 匹配结果 *星号 匹配零个或多个字符(除了路径分隔符 /)。log/*.log匹配 log/access.log、log/error.log、log/a.log?问号 匹配恰好一个字符。 file_?.txt匹配 file_1.txt、file_A.txt,但不匹配file_12.txt[]方括号 匹配方括号内任意一个字符或字符范围。 [a-c].txt匹配 a.txt、b.txt、c.txt**双星号 递归匹配零个或多个目录。 data/**/log.txt匹配 data/log.txt、data/a/log.txt、data/a/b/log.txtprospector.scanner.exclude_files:正则表达式数组,用于定义要忽略的文件;
include_lines:正则表达式数组,用于定义要获取的行需要满足的正则表达式(满足一个就可以);
exclude_lines:正则表达式数组,用于定义要丢弃的行需要满足的正则表达式(满足一个就可以);
如果同时指定了include_lines和exclude_lines,那么Filebeat先执行include_lines,然后再执行exlcude_lines。
parsers:定义了一系列解析器,用于对日志内容进行处理,包括
multiline,ndjson、container、syslog、include_message解析器;processors:定义了一系列处理器,用于对事件(event)进行处理;
下面是一个input配置示例:
yaml
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /var/log/*.log
prospector.scanner.exclude_files: ['\.gz$'] # 忽略.gz结尾的文件
include_lines: ["sometext"]
exclude_lines: ["^DBG"]
parsers:
- multiline:
type: count
count_lines: 3
processors:
- dissect:
tokenizer: '"%{service.pid|integer} - %{service.name} - %{service.status}"'
field: "message"
target_prefix: ""2.3.2 parsers的multiline
本小节主要介绍parsers中的multiline解析器。
在日志文件中,有可能某一个事件(event)跨越了多行,如果按照默认的配置,那么每行就会生成一个事件,最后会生成多个事件,而multiline解析器可以用来将跨越多行的事件组合成一个事件。
基本语法如下:
yaml
parsers:
- multiline:
type: pattern
pattern: '^\['
negate: true
match: after- type:表示如何确定哪几行是一个事件,取值如下:
- pattern:默认值,Filebeat识别一行是否是新事件的开始。所有不符合开始行模式的行,都作为前一个事件的延续。
- count:Filebeat 将指定数量的连续行聚合成一个事件。
- while_pattern:Filebeat找到第一行(事件的开始行)后,会持续(
while)将所有匹配pattern的后续行添加到该事件中,直到遇到第一个不匹配pattern的行。
- pattern:定义了一个正则表达式。Filebeat会使用这个正则表达式来检查每一行日志,来识别一行为新事件的开始行,或者识别一行为 前一个事件的延续行。
- negate:布尔值,取之为true或false:
- negate: true:表示 不匹配
pattern的行是当前事件的延续行。 - negate: false:表示 匹配
pattern的行是当前事件的延续行,即表示该行是新事件的开始行。
- negate: true:表示 不匹配
- match:新的行应该被合并到多行事件的前面还是后面:
- match: after:匹配的行或否定的行(即延续行)将被添加到前面匹配的行的后面。这适用于从事件的开始行开始匹配的场景。
- match: before:匹配的行或否定的行(即延续行)将被添加到前面匹配的行的前面。这适用于从事件的结束行开始匹配的场景。
- count_lines:当type为count时,指定多少行聚合成一个事件;
- max_lines:指定一个事件中最多有多少行,默认值为500;
例如,在java中,异常堆栈信息格式如下:
txt
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
... 1 more那么可以设置如下,将上面的多行异常堆栈信息聚合成一个事件:
yaml
parsers:
- multiline:
type: pattern
pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:'
negate: false
match: after2.3.3 processors
processors用于处理事件(event),包括移除字段、添加字段、处理字段内容、丢弃事件等,processors可以定义多个,事件按照processors定义的顺序依次进行处理,并最终进入output中指定的目的地:
txt
event -> processor 1 -> event1 -> processor 2 -> event2 -> output如何以及在哪配置processors
processors的基本配置格式如下:
yaml
processors:
- <processor_name>:
when:
<condition>
<parameters>
- <processor_name>:
when:
<condition>
<parameters>即processors是一个数组,其中可以定义多个processor,在每一个processor中可以定义需要满足的条件以及参数,当事件满足该processor的条件后,就会应用该processor。
可以使用如下的processors复杂配置:
yaml
processors:
- if:
<condition>
then:
- <processor_name>:
<parameters>
- <processor_name>:
<parameters>
...
else:
- <processor_name>:
<parameters>
- <processor_name>:
<parameters>
...当事件满足if中的条件后,则使用then中定义的processor,否则使用else中定义的processor。
在Filebeat中,processors既可以定义为全局的,也可以定义为局部的(针对某个input而言)。
全局的配置是针对所有的input的事件:
yaml
filebeat.inputs:
- type: filestream
processors:
- <processor_name>:
when:
<condition>
<parameters>局部的配置是针对单个input的事件:
yaml
filebeat.inputs:
- type: filestream
processors:
- <processor_name>:
when:
<condition>
<parameters>关于具体的processor,请查看2.4小节。
2.3.4 output
output是指明Filebeat将事件(event)发送到哪里去,本小节介绍Elasticsearch和File两种输出目的地。
Elasticsearch
将事件发送到Elasticsearch的基本配置如下:
yaml
output.elasticsearch:
enabled: true
hosts: ["https://myEShost-node1:9200", "https://myEShost-node2:9200"]
protocol: http
username: "filebeat_writer"
password: "YOUR_PASSWORD"
compression_level: 1
loadbalance: true
worker: 1
index: customer-index
indices:
- index: "warning-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "WARN"
- index: "error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "ERR"enabled:是否启用,默认值为true,表示启用;
hosts:是一个数组,表示ES的地址,由于ES可以集群部署,所以这里也可以指定多个ES节点的地址;
ES 节点的地址可以写成
URL或IP:PORT,例如:http://192.15.3.2,https://es.found.io:9230或192.24.3.2:9300,如果没有端口,那么使用9200作为默认端口。如果写成
IP:PORT格式,那么协议使用protocol中指定的协议;protocol:协议,可选值为http和https,默认值为http;如果在
hosts中使用IP:PORT格式,那么协议就会使用protocol中指定的协议;如果使用在hosts中使用URL格式,那么就会忽略protocol中的值,使用URL中的协议;username和password:表示访问ES的用户名和密码;filebeat总共可以使用以下三种方式访问ES:
用户名和密码:
yamloutput.elasticsearch: hosts: ["https://myEShost:9200"] username: "filebeat_writer" password: "YOUR_PASSWORD"API Key:
yamloutput.elasticsearch: hosts: ["https://myEShost:9200"] api_key: "ZCV7VnwBgnX0T19fN8Qe:KnR6yE41RrSowb0kQ0HWoA"api_key的格式为:id:api_key;PKI证书认证:
yamloutput.elasticsearch: hosts: ["https://myEShost:9200"] ssl.certificate: "/etc/pki/client/cert.pem" ssl.key: "/etc/pki/client/cert.key"
compression_level:gzip压缩等级,即把数据发送给ES前使用gzip压缩的等级,可选值为0-9之间的整数。如果设置为0,表示禁用压缩,从1-9,数字越大,表示压缩率越高,即发送的数据包越小,但是消耗的CPU资源越高,默认值为1;
loadbalance:在
hosts中可以指定多个ES地址,那么我们就可以决定是否同时向多个地址发送数据,loadbalance就是控制能否同时向多个地址发送数据,默认值为true;如果设置为false,那么Filebeat从
hosts中随机选择一个ES地址,然后发送数据,如果该ES地址连接失败了,那么会再选择另一个ES地址,继续发送数据;worker或workers:决定每个ES地址建立多少个连接,默认值为1;
index:决定数据发送到ES的哪个索引,如果没有指定,那么默认值为
filebeat-%{[agent.version]}-%{+yyyy.MM.dd}。当自定义索引名称时,需要同时配置
setup.template.name和setup.template.pattern;如果启用了索引生命周期管理(ILM,index lifecycle management),那么默认的索引名称为
filebeat-%{[agent.version]}-%{+yyyy.MM.dd}-%,例如filebeat-[version]-2025-01-30-000001,并且自定义的索引名称会被忽略;参考ILM配置:https://www.elastic.co/docs/reference/beats/filebeat/ilm。在自定义索引名称中,我们也可以使用事件(event)中的字段,例如
%{[fields.log_type]}-%{[agent.version]}-%{+yyyy.MM.dd},其中的%{[fields.log_type]}就表示事件中的log_type字段,例如所有log_type为normal的事件被发送到名为normal-[version]-2025-01-30的索引中,而所有log_type为critical的事件被发送到名为critical-[version]-2025-01-30的索引中。indices:定义了一组索引选择规则,当事件满足某个规则时,就会进入该规则指定的索引中,按照指定的规则顺序进行匹配,进入第一个满足的规则制定的索引;如果该事件不满足
indices中所有的规则,那么就会进入index中指定的索引;有两种方式可以指定
indices:方式一:index+when
yamloutput.elasticsearch: hosts: ["http://localhost:9200"] indices: - index: "warning-%{[agent.version]}-%{+yyyy.MM.dd}" when.contains: message: "WARN" - index: "error-%{[agent.version]}-%{+yyyy.MM.dd}" when.contains: message: "ERR"首先使用某个事件来判断其是否满足
when中指定的条件,如果满足,就进入indices.index中指定的索引名称,如果不满足,则继续匹配indices中的规则,如果不满足indices中的所有规则,那么该事件进入index中指定的索引;方式二:index+mappings+default
yamloutput.elasticsearch: hosts: ["http://localhost:9200"] indices: - index: "%{[fields.log_type]}" mappings: critical: "sev1" normal: "sev2" default: "sev3"首先从事件中取出
log_type字段,然后判断mappings中是否有满足匹配的规则,假设log_type的值为normal,那么进入sev2索引,如果mappings中没有满足的匹配规则,就进入default中指定的索引;注意,上述方式限制
mappings中的索引名称为字符串常量,也就是说不能使用格式化字符串,如%{[fields.log_type]};
File
File就是将事件发送到文件中,这种方式可以用来测试Filebeat是否有效。基本配置如下:
yaml
output.file:
enabled: true
path: "/tmp/filebeat"
filename: filebeat
rotate_every_kb: 10000
number_of_files: 7
permissions: 0600
rotate_on_startup: true
codec.json:
pretty: true
escape_html: falseenabled:是否启用该output,默认值为true;
path:用来存储输出文件的目录;
filename:输出文件的名称;
rotate_every_kb:每个文件的最大大小,以KB为单位,默认值为10240KB,也就是说每个文件最大10M,当输出文件到达该大小后,会输出到另一个文件;
number_of_files:表示输出文件目录下最大的文件数,默认值为7,支持的值为2-1024。当到达最大文件数时,最先创建的文件会被删除;
permissions:对输出文件的权限控制,默认值为0600,表示只有创建该文件的用户具有读写权限,其他用户都没有权限读写该文件;
rotate_on_startup:表示是否在Filebeat启动时创建新的输出文件,默认值为true;
codec:用于编码输出的事件,默认值为json,表示每个事件输出为一个json,并且一个json占据输出文件中的一行;
- pretty:表示不把json输出为一行,而是输出为可读性高的格式;默认值为false;
- escape_html:是否去除HTML表情,默认值为false;
除了使用json格式,还可以使用字符串格式,如下:
yamloutput.file: codec.format: string: "%{[@timestamp]} %{[message]}"表示将事件中的
@timestamp和message字段提取出来,拼接成一行输出;
2.4 processors
本小节介绍具体的processor。
https://www.elastic.co/docs/reference/beats/filebeat/filtering-enhancing-data
2.4.1 add_fields
add_fields处理器会在事件(event)中添加字段,语法如下:
yaml
processors:
- add_fields:
target: project
fields:
name: myproject
id: "574734885120952459"- target:新添加的字段应该放在哪个字段下,默认值为
fields;如果要把新添加的字段放在根层级下,设置target为'',如target: ''; fields:要新添加的字段;
以上例子会在事件中添加如下内容:
json
{
"project": {
"name": "myproject",
"id": "574734885120952459"
}
}2.4.2 drop_fields
drop_fields用于移除事件中的字段,语法如下:
yaml
processors:
- drop_fields:
when:
condition
fields: ["field1", "field2", ...]
ignore_missing: falsewhen:只有满足条件时才会移除指定的字段,是可选的;fields:指定要移除的字段名称,也可以使用正则表达式,需要使用/包围,例如/reg_exp/;ignore_missing:当事件中不存在要移除的字段时,是否抛出错误,默认值为false,表示抛出错误,设置为true,表示不抛出错误;
注意,@timestamp和type字段不能被移除。
2.4.3 drop_event
drop_event用于抛弃整个事件,也就是说被抛弃的事件不会进入目的地,语法如下:
yaml
processors:
- drop_event:
when:
conditionwhen:当满足条件时,事件才会被抛弃,注意,该项是必须的;
2.4.4 rename
rename用来改变字段的名称,也可以用来改变字段的层级,语法如下:
yaml
processors:
- rename:
fields:
- from: "a.g"
to: "e.d"
ignore_missing: false
fail_on_error: truefields:是一个对象数组,其中每个对象有两个属性from和to,from定义了要改变的字段,to定义了新的字段名称;ignore_missing:当事件中不存在from中指定的字段时,是否抛出移除,默认值为false表示抛出移除;fail_on_error:如果设置为true,当发生错误时,rename处理阶段停止并返回原始事件,设置为false表示继续进行rename处理,默认值为true;
当进行如下设置时,也改变字段层级:
yaml
processors:
- rename:
fields:
- from: "a.g"
to: "e"2.4.5 dissect
dissect处理器用于将字符串用指定的格式进行分解,语法如下:
yaml
processors:
- dissect:
tokenizer: "%{key1} %{key2} %{key3|convert_datatype}"
field: "message"
target_prefix: "dissect"
overwrite_keys: true
trim_values: all
trim_chars: " "
ignore_failure: truetokenizer:定义了字符串格式,其中%{key3|convert_datatype}表示占位符,该位置的字符串会被解析为key3字段,并且转换为convert_datatype指定的格式;field:指定了事件中的哪个字段用来解析;target_prefix:将解析后的字段放在哪个字段里,默认值为dissect,如果要把解析后的字段放在根路径下,设置target_prefix: "";注意,如果事件中已经存在同名字段,则dissect处理器不会覆盖同名字段,如果需要覆盖,设置overwrite_keys为true;trim_values:定义要在哪移除字符,可选的值为none、left、right和all,默认值为none表示不移除;trim_chars:指定要移除哪些字符,默认值为" ",表示移除空格,如果要移除其他字符,将要移除的字符放在一个字符串中,例如" a",表示要移除空格和字符a;ignore_failure:是否忽略错误,默认值为false;如果设置为true,那么当dissect遇到错误时,会恢复原事件,并继续执行后续的处理器;如果设置为false,那么会抛出错误,并阻止后续处理器的执行;
2.5 索引模板与ILM
2.5.1 默认情况
如果不调整ES输出的目标索引,那么filebeat会做如下事:
创建名称为
filebeat的ILM策略,如下(已省略部分字段):json{ "filebeat": { "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max_age": "30d", "max_size": "50gb" } } } } }, "in_use_by": { "indices": [ "filebeat-7.17.28-2026.01.03-000001" ], "data_streams": [], "composable_templates": [ "filebeat-7.17.28" ] } } }创建名称为
filebeat-<version>的索引模板,部分内容如下:json{ "index_templates": [ { "name": "filebeat-7.17.28", "index_template": { "index_patterns": [ "filebeat-7.17.28-*" ], "template": { "settings": { "index": { "lifecycle": { "name": "filebeat", "rollover_alias": "filebeat-7.17.28" } } } } } } ] }创建名为
filebeat-<version>-<yyyy.MM.dd>-<seqNo>的索引,并使用别名filebeat-<version>;
2.5.2 调整索引模板
如果我们自己定义索引模板,那么可以如下设置:
yaml
filebeat.inputs:
- type: stdin
enabled: true
id: my-stdin-id
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "my-filebeat-test-01"
username: "elastic"
password: "your_strong_password123"
setup.kibana:
host: "localhost:5601"
setup.ilm.enabled: false
setup.template:
enabled: true
name: "my-filebeat-test"
pattern: "my-filebeat-test-*"
settings:
index.number_of_shards: 1
index.number_of_replicas: 0
fields: "my_fields.yaml"- 第8行,自定义索引名称
- 第15行,禁用ILM,如果ILM启用了,会忽略自定义的索引模板;
- 第17-24行,设置索引模板的内容
其中,setup.template.fields是自定义Mapping,内容如下:
yaml
- key: my_app
fields:
- name: desc
type: textkey作为分组键,在实际生成的索引模板中,desc并不会在my_app下。
然后,启动filebeat,查看索引模板:
txt
GET /_index_template/my-filebeat*json
{
"index_templates": [
{
"name": "my-filebeat-test",
"index_template": {
"index_patterns": [
"my-filebeat-test-*"
],
"template": {
"settings": {
"index": {
"mapping": {
"total_fields": {
"limit": "10000"
}
},
"refresh_interval": "5s",
"number_of_shards": "1",
"number_of_replicas": "0",
"max_docvalue_fields_search": "200",
"query": {
"default_field": [
"desc",
"fields.*"
]
}
}
},
"mappings": {
"_meta": {
"beat": "filebeat",
"version": "7.17.28"
},
"dynamic_templates": [
{
"strings_as_keyword": {
"mapping": {
"ignore_above": 1024,
"type": "keyword"
},
"match_mapping_type": "string"
}
}
],
"properties": {
"desc": {
"norms": false,
"type": "text"
}
},
"date_detection": false
}
},
"composed_of": [],
"priority": 150
}
}
]
}可以发现,生成的索引模板确实是我们自己定义的。
查看生成的索引及文档:
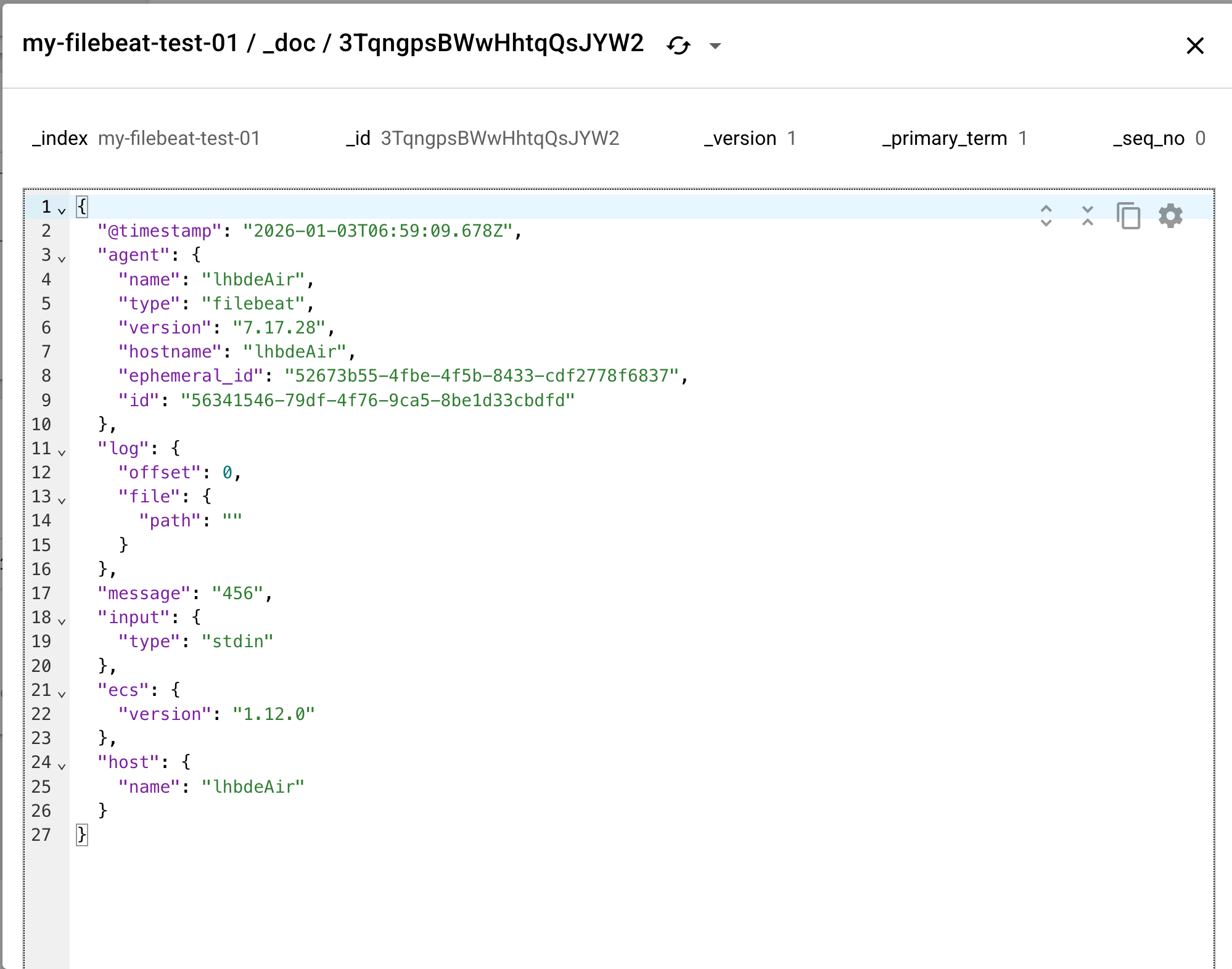
会发现有很多字段,并且没有自定义的 desc 字段:
- 很多其他的字段,这些字段是由filebeat自动生成的,当这些字段随文档进入索引时,ES会自动进行字段映射;
- 没有自定义的
desc字段,这是因为filebeat自动生成事件(文档)时,并没有包含该字段,我们可以使用processors添加;
在filebeat默认的fields.yml中,已经定义了很多字段,如果我们想添加自己的字段,不用重新定义,可以在filebeat.yml中使用如下配置:
yaml
setup.template.overwrite: true
setup.template.append_fields:
- name: test.name
type: keyword
- name: test.hostname
type: longsetup.template.overwrite:重写索引模板,默认值为false;setup.template.append_fields:声明自定义字段及其数据类型;
我们可以使用如下命令,查看要生成的索引模板:
bash
./filebeat export template2.5.3 ILM与Data Stream
如果是较老的Filebeat版本,参考一下配置:
yaml
setup.ilm.rollover_alias: "xxx"在较新的Filebeat版本中,如果开启了ILM,那么会优先使用ILM+Data Stream模式。
以下案例在Filebeat-9.1.9中演示,在MacOS中下载使用Filebeat-9.1.9:
txt
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-9.1.9-darwin-x86_64.tar.gz
tar xzvf filebeat-9.1.9-darwin-x86_64.tar.gzfilebeat.yml配置文件内容如下:
yaml
filebeat.inputs:
- type: stdin
enabled: true
id: my-stdin-id
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "my-filebeat-index-template"
username: "elastic"
password: "your_strong_password123"
setup.kibana:
host: "localhost:5601"
setup.ilm:
enabled: true
policy_name: "my-filebeat-test-ilm-policy"
policy_file: "ilm-policy.json"
setup.template:
enabled: true
name: "my-filebeat-index-template"
pattern: "my-filebeat-*"
settings:
index.number_of_shards: 1
index.number_of_replicas: 0
fields: "my_fields.yaml"
append_fields:
- name: test.name
type: keyword
- name: test.hostname
type: longILM策略定义ilm-policy.json内容如下:
Details
json
{
"policy": {
"phases": {
"hot": {
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_docs": 2
}
}
},
"warm":{
"min_age": "5m",
"actions": {
"readonly": {},
"allocate": {
"number_of_replicas": 0
},
"shrink": {
"number_of_shards": 1
}
}
}
}
}
}以上配置文件的效果如下:
由于开启了ILM,所以filebeat会使用在
setup.ilm.policy_file中的具体策略规则,创建以setup.ilm.policy_name为名的ILM策略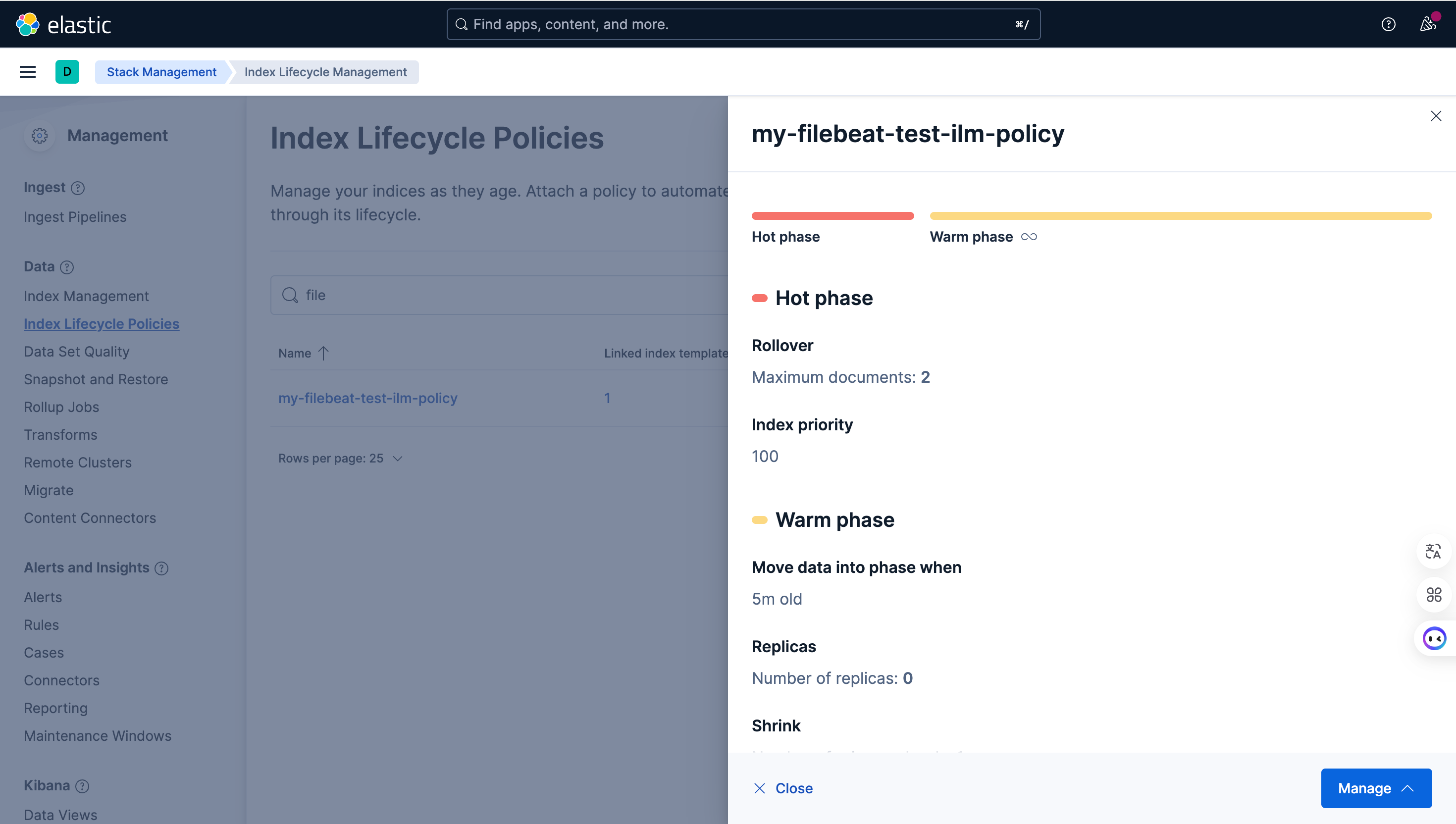
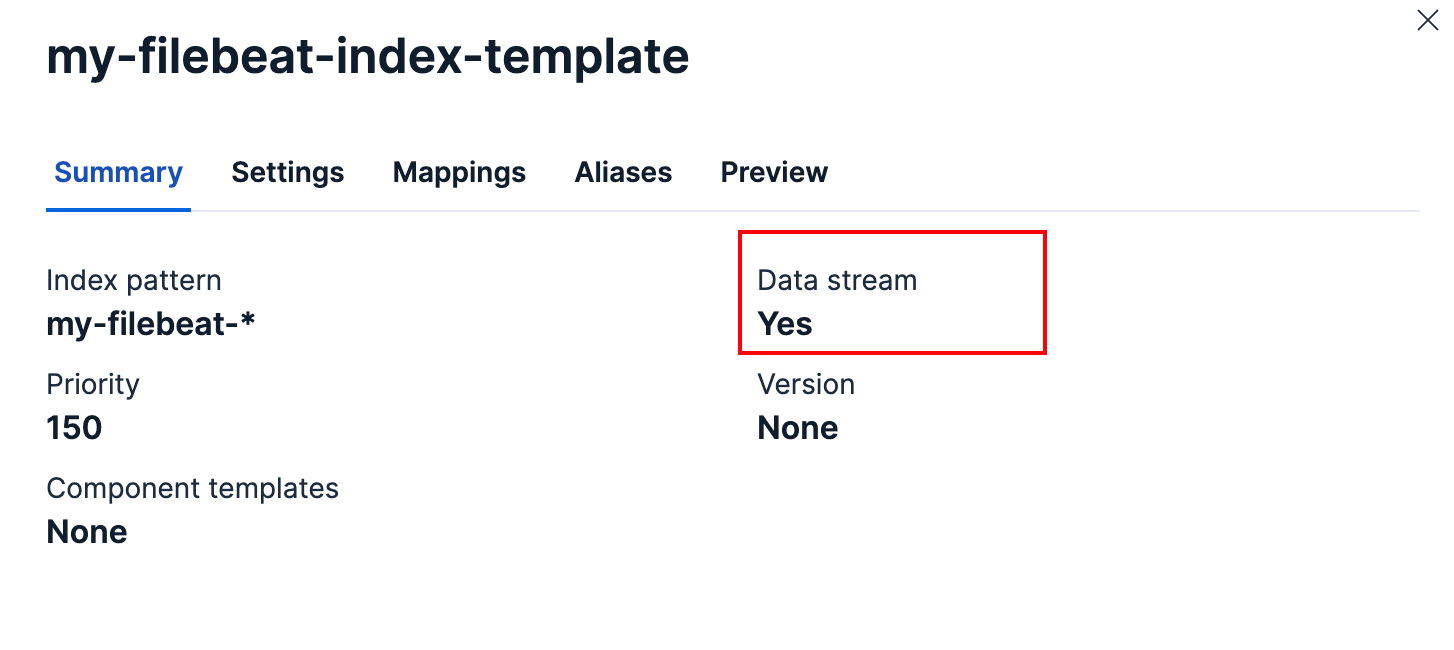
虽然在官方文档中,说开启了ILM,会忽略
setup.template.name和setup.template.pattern。WARNING
If index lifecycle management is enabled (which is typically the default),
setup.template.nameandsetup.template.patternare ignored.但是,实际测试下来,如果不设置这两个属性会报错,并且设置了会创建索引模板,并且开启了Data Stream模式:
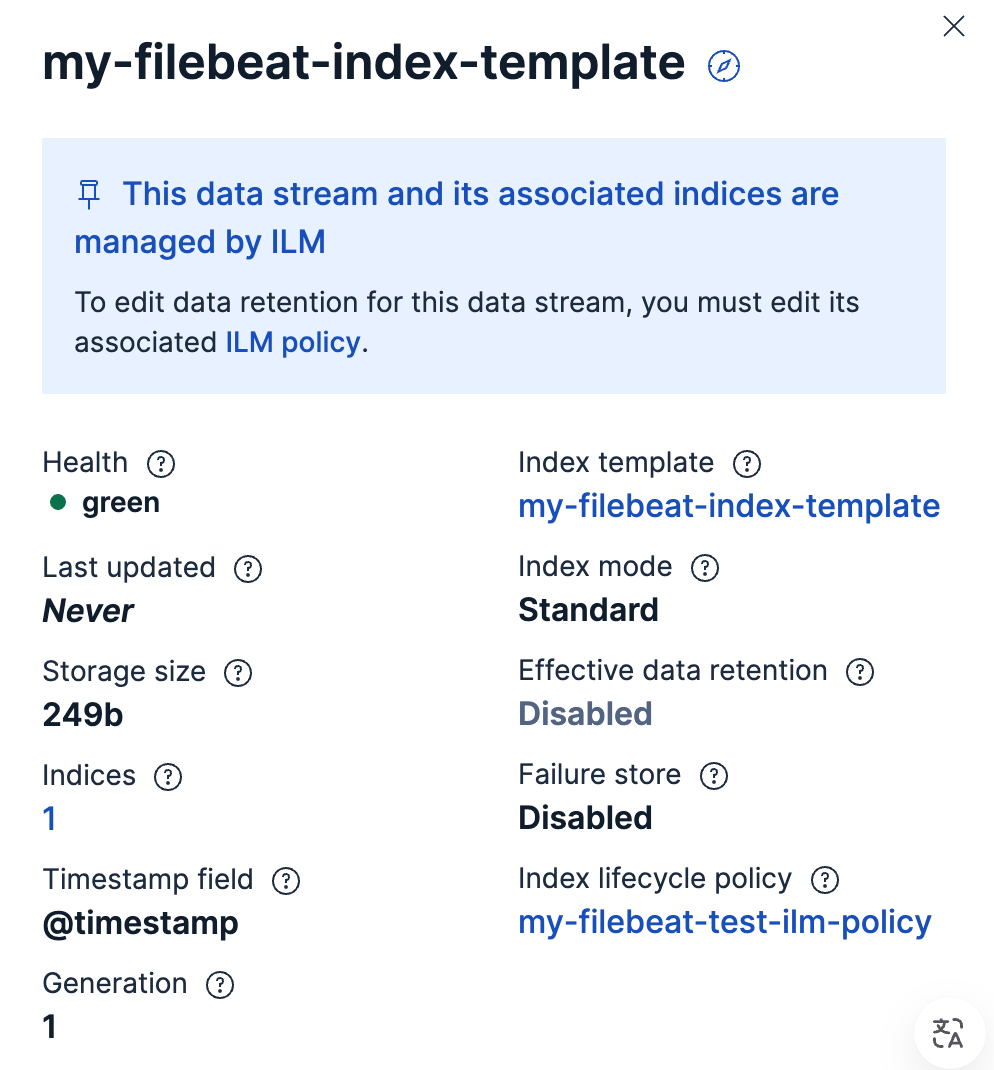
创建与索引模板同名的Data Stream:
一定要设置
output.elasticsearch.index的值,并且该值需要与setup.template.name的值相同,这样写入文档时才会写入到Data Stream中。如果不设置,那么
output.elasticsearc.index的默认值为filebeat-<version>,会导致事件(文档)写入到名称为filebeat-<version>的索引中,而不是Data Stream中: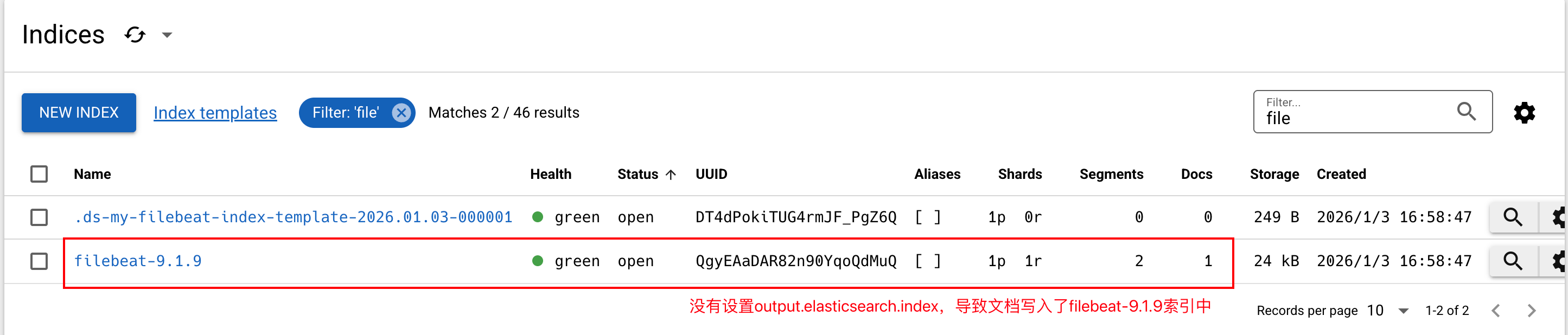
2.6 小结
Filebeat,或者说beats,内部使用了很多ILM和Data Stream的知识。
最开始我没学习ILM和Data Stream,想先了解Fileabeat的使用,但是发现看不懂,最后还是去补了ILM和Data Stream的知识后,再来学习Fileabeat的。
其实Filebeat,做的事就是想从Filebeat端,去创建ILM、Data Stream等内容,并且再加上Filebeat获取事件、解析事件等功能。其实学完下来,发现Filebeat不简单,或者说有点难以理解,很多地方设计不太合理(或者说和文档有出入)。
我认为最好的方法还是在ES端做好索引模板、ILM、Data Stream的创建与管理工作,在Filebeat端,只需要确定数据从哪输入,怎么处理,输出到哪的工作,推荐如下配置:
yaml
setup.ilm.enabled: false # 关闭 Filebeat 自动管理 ILM
setup.template.enabled: false # 关闭 Filebeat 自动加载/管理索引模板(最关键!)
output.elasticsearch:
hosts: ["https://es.example.com:9200"]
index: "logs-nginx-prod" # ← 直接写自己创建的数据流完整名称3. 实战案例
本小节介绍如何使用Filebeat,读取Spring Boot程序的日志到Elasticsearch中。
3.1 创建Spring Boot程序
完整项目地址:https://github.com/Lee-0o0/spring-boot-demo
主要查看日志配置logback.xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 将日志写入文件,并归档 -->
<appender name="ROLLINGFILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/springboot-demo.log</file>
<!-- 注意选取的是 SizeAndTimeBasedRollingPolicy -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 按天归档 -->
<fileNamePattern>logs/archive/springboot-demo-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- 单文件最大大小 -->
<maxFileSize>1MB</maxFileSize>
<!-- 保留历史天数(因为是按天归档的) -->
<maxHistory>60</maxHistory>
<!-- 日志总文件大小 -->
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
<!-- 日志内容格式 -->
<encoder>
<pattern>[%thread] %-5level %logger -%msg %n</pattern>
</encoder>
</appender>
<!-- 控制台输出日志 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%-4relative [%thread] %-5level %logger{35} -%kvp- %msg %n</pattern>
</encoder>
</appender>
<!-- 定义根日志记录器日志级别 -->
<root level="INFO">
<!-- ref的值需要与appender的name一致 -->
<appender-ref ref="ROLLINGFILE" />
<appender-ref ref="STDOUT" />
</root>
</configuration>3.2 配置Filebeat
在filebea.yml中配置如下:
yaml
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /Users/lhb/projects/demo/java_demo/spring-boot-demo/logs/*.log
prospector.scanner.exclude_files: ['\.gz$']
parsers:
- multiline:
type: pattern
pattern: '^\[|^[0-9]{4}'
negate: true
match: after
processors:
- dissect:
tokenizer: "[%{thread}] %{level->} %{logger} -%{message}"
field: "message"
target_prefix: "app"
- drop_fields:
fields: ["host", "input", "agent", "ecs", "log", "message"]
ignore_missing: true
- rename:
fields:
- from: "app.message"
to: "message"
- from: "app.level"
to: "level"
- from: "app.logger"
to: "logger"
- from: "app.thread"
to: "thread"
ignore_missing: true
fail_on_error: false
- drop_fields:
fields: ["app"]
ignore_missing: true
# output.console:
# pretty: true
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "app-logs-000001"
username: "elastic"
password: "your_strong_password123"
setup.kibana:
host: "localhost:5601"
setup.ilm:
enabled: true
policy_name: "app-logs-ilm-policy"
policy_file: "ilm-policy.json"
setup.template:
enabled: true
name: "app-logs"
pattern: "app-logs-*"
settings:
index.number_of_shards: 1
index.number_of_replicas: 0
fields: "my_fields.yaml"注意以下两点:
在
parsers中配置多行解析器,以处理出现异常的情况;在
dissect中解析日志时,使用->表示多余的空格,如%{level->};
my_fields.yml如下:
yaml
- key: my_app
fields:
- name: message
type: text
- name: level
type: keyword
- name: logger
type: keyword
- name: thread
type: keyword3.3 效果演示