Appearance
ES分布式基础
本文主要介绍ES分布式中的相关概念,以及如何在分布式环境下进行写入与查询的。
1. 术语介绍
本小节介绍集群、节点、分片的概念。
节点:一个节点就是一个ES实例服务;
集群:集群包含多个节点;
分片:在ES中,会将索引中的文档分布到多个分片上,一个分片包含多个文档。本质上,一个分片就是Lucene层面上的一个索引。ES将分片分为两种类型:主分片和副本分片。
- 主分片:主分片可以接受读写文档操作,所有的主分片组成了完整的ES索引,每个文档都会属于一个主分片;
- 副本分片:副本分片是主分片的复制,可以接受读文档的操作;副本分片可以用来保证服务的稳定性,并增加处理读取请求的能力;
可以理解为,在ES中,一个索引分为多个主分片,每个主分片又会有多个副本分片。关于索引的主分片数量和每个主分片的副本分片数量,都可以在创建索引时设置。
在ES中,分片会均匀分布在节点中。
2. 节点角色
在ES集群中,不同的节点扮演着不同的角色,承担不同的功能指责,完整的角色有:
master, data, data_content, data_hot, data_warm, data_cold, data_frozen, ingest, ml, remote_cluster_client, transfer;
我们可以在ES的配置文件elasticsearch.yml中配置节点的角色,例如:
yml
node.roles: [ master, data ]接下来主要介绍一下节点角色。
2.1 节点角色介绍
master:在ES集群中,只有一个活跃的主节点,主节点主要负责轻量级的集群工作,例如创建和删除索引,跟踪节点健康(确定哪个节点属于集群),分配分片(确定某个分片分配到哪个节点)等。对于集群来说,拥有一个稳定的主节点是至关重要的。但是,当主节点发生故障时,如果没有备用的节点,那么会造成整个集群不可用。所以,master节点角色即表示该节点时主节点候选节点,即该节点有资格担任主节点。当主节点发生故障时,或者集群启动时,ES会通过选举机制,从主节点候选节点中推选一个节点作为活跃主节点,其他主节点候选节点作为备份。为了避免单点故障,Elasticsearch 推荐配置至少 3 个主节点候选节点。如果要配置一个节点为主节点候选节点,配置如下:
yamlnode.roles: [ master ]在ES中,还有一种特殊的主节点候选节点:只拥有投票权的主节点候选节点。也就是说,在主节点选举中,这种类型的节点有投票权,但是,该节点永远不会被选举为主节点。要设置某个节点为只投票的主节点候选节点,配置如下:
yamlnode.roles: [ master, voting_only ]只有拥有master角色的节点,才可以配置voting_only
data:数据节点,数据节点存储着索引分片,并且可以处理数据相关的操作,比如CRUD、搜索、聚合。这些操作是I/O、内存和CPU密集型的。所以,监控数据节点的这些资源消耗情况,并且在过载时增加集群的数据节点,有助于保持集群健康稳定。data数据节点是通用的,ES还提供多维度、特定用途的数据节点,例如data_content、data_hot、data_warm、data_cold和data_frozen,一般情况下,使用data角色即可。要给节点分配数据节点角色,可设置如下:
yamlnode.roles: [ data ]ingest:数据处理节点,主要用于在文档进入索引前,处理文档,例如为文档增加字段、处理现有字段等。在新文档加入索引前,ES会判断新文档是否要经过数据处理(数据处理由管道pipeline定义,一个管道由一个或多个处理器processor(也可称为任务)组成),如果要经过数据处理,那么ES会使用具有
ingest角色的节点进行处理,然后才会将新文档加入到索引中。示意图如下:
如果要设置节点具有
ingest角色,可设置如下:yamlnode.roles: [ ingest ]根据数据处理器执行的操作类型和所需资源,拥有专门的数据处理节点是更稳健的,这些节点只执行这一特定任务,如上配置。
关于数据处理,请参考附录1。
remote_cluster_client:remote_cluster_client节点作为跨集群客户端,可以连接到其他集群,一旦连接到其他集群,那么就可以使用跨集群搜索API,搜索其他集群的数据,同样,也可以同步数据到其他集群。设置如下:yamlnode.roles: [ remote_cluster_client ]ml:ml是machine learning的简写,是指机器学习节点,专门用于运行机器学习(ML)作业。它不负责数据存储或查询,而是专注于自动化分析和预测,帮助用户从海量数据中发现异常、趋势和洞察。ML节点 利用内置的 ML 引擎,支持无监督学习(如异常检测)和监督学习(如分类、预测),无需外部 ML 框架。ML 作业 CPU/内存密集,推荐专用 ML 节点以避免影响数据节点性能。配置如下:
yamlnode.roles: [ ml ]在ES中,强烈推荐
ml节点同时配置remote_cluster_client角色:yamlnode.roles: [ ml, remote_cluster_client]transform:transform节点是一种专用节点角色,用于运行 Transform 任务。它不直接存储或查询数据,而是专注于批量数据转换和聚合,从源索引(source index)中提取、聚合和转换数据,生成新的目标索引(destination index)。这有助于创建汇总视图、减少数据冗余或优化分析性能,特别适合 BI 仪表板、报告或时间序列数据处理。Transform节点基于 ES 的聚合引擎(如 Pivot 和 Latest 变换),支持增量更新,避免全量重新处理。相比 Ingest Node(文档级实时预处理),Transform 更侧重批量/聚合级转换,是数据管道的“后处理”环节。
在ES中,也强烈推荐
transform节点同时配置remote_cluster_client角色:yamlnode.roles: [ transform, remote_cluster_client ]
2.2 纯协调节点
在ES中,还存在着一种特殊节点:纯协调节点(Coordinating-Only)。
什么是协调?协调包括以下工作:
- 接收和解析请求:从客户端(如 Kibana 或应用)接收搜索、聚合、更新等请求,解析查询 DSL(Domain Specific Language);
- 查询协调:将查询请求分发到相关数据节点(shards),收集分片结果;
- 结果合并与返回:从各个数据节点汇总结果,进行最终排序/分页,然后返回给客户端;
默认情况下,所有节点都可以充当协调节点。
在高负载或大规模集群,可以配置纯协调节点,避免数据节点资源被协调工作占用,提高整体查询性能和稳定性。配置纯协调节点如下:
yaml
node.roles: [ ]使用纯协调节点,需要保证请求路由到纯协调节点,如果配置错误,会导致数据节点承担协调工作(解析查询、分发子请求、合并结果),而纯协调节点闲置。
可以使用负载均衡器(如 HAProxy)将所有客户端请求指向 Coordinating-only 节点群(至少 3 个高可用)。
3. 使用docker搭建集群环境
3.1 第一次启动集群
使用docker搭建集群环境非常简单,使用docker-compose.yml文件即可:
yaml
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.28
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.28
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.28
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge其中有几项关于ES集群的配置需要关注:
cluster.name:集群名称;node.name:该节点的名称;cluster.initial_master_nodes:指定master-eligible角色的节点,主要用于集群第一次启动,如果集群成功启动后,应该移除该项配置;discovery.seed_hosts:指定集群中的节点,也就是说当一个节点启动时,会依次尝试连接discovery.seed_hosts列表中列出的地址。一旦连接到列表中的任何一个节点(通常是符合主节点资格的节点),它就会从该节点获取完整的集群状态信息,然后尝试加入到集群中;
注意,该集群中只有节点es01进行了端口映射,所以需要从9201端口访问。
然后使用以下命令启动ES集群:
bash
docker-compose upTIP
使用chrome 浏览器插件 Elasticvue连接到ES集群,观察集群状态
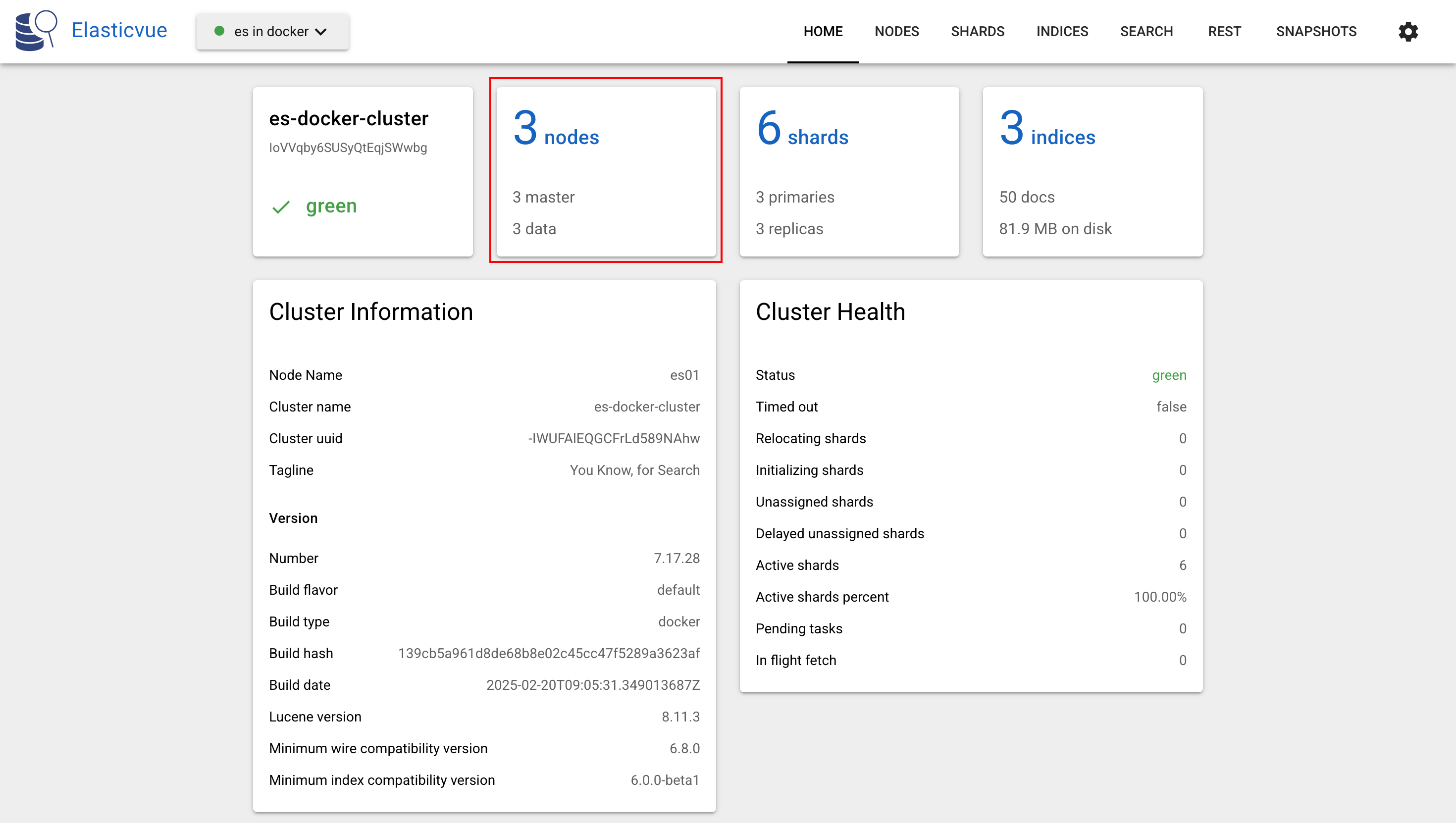
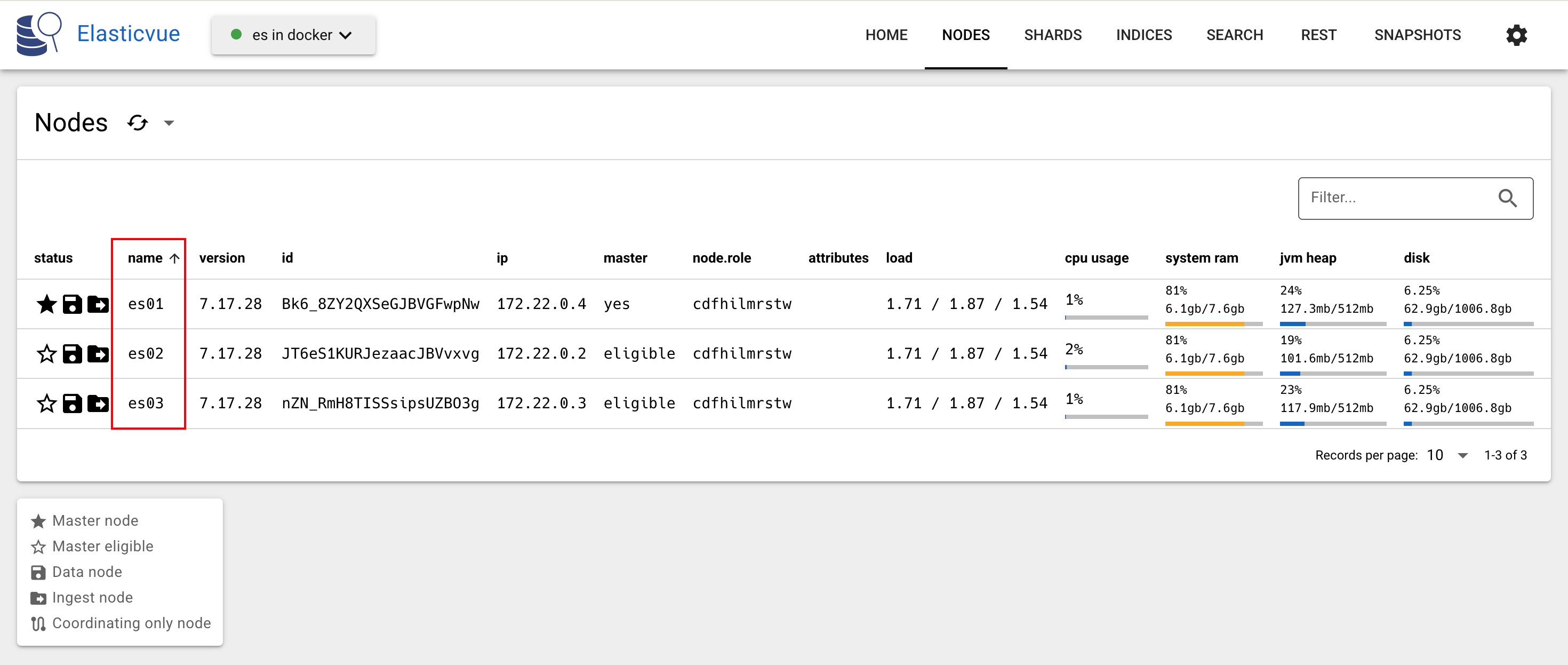
如果要使用kibana管理ES集群,可使用以下命令启动:
txt
docker run -d --name kibana-cluster --net es_elastic -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://es01:9200" kibana:7.17.28之后,访问http://localhost:5601/app/home#/即可。
3.2 节点加入集群
要将新节点加入到集群中,同样可以使用docker-compose的方式,内容如下,配置文件命名为node-add.yml:
yaml
services:
es04:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.28
container_name: es04
environment:
- node.name=es04
- node.roles=data,ingest
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data04:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data04:
driver: local
networks:
elastic:
driver: bridgenode.roles:定义节点的角色;
然后使用以下命令启动该节点:
bash
docker-compose -f node-add.yml up -d es04-f node-add.yml:指定配置文件的名称;-d:后台启动;es04:指定启动的服务名称;
之后,再次在 Elasticvue 插件中观察集群状态:

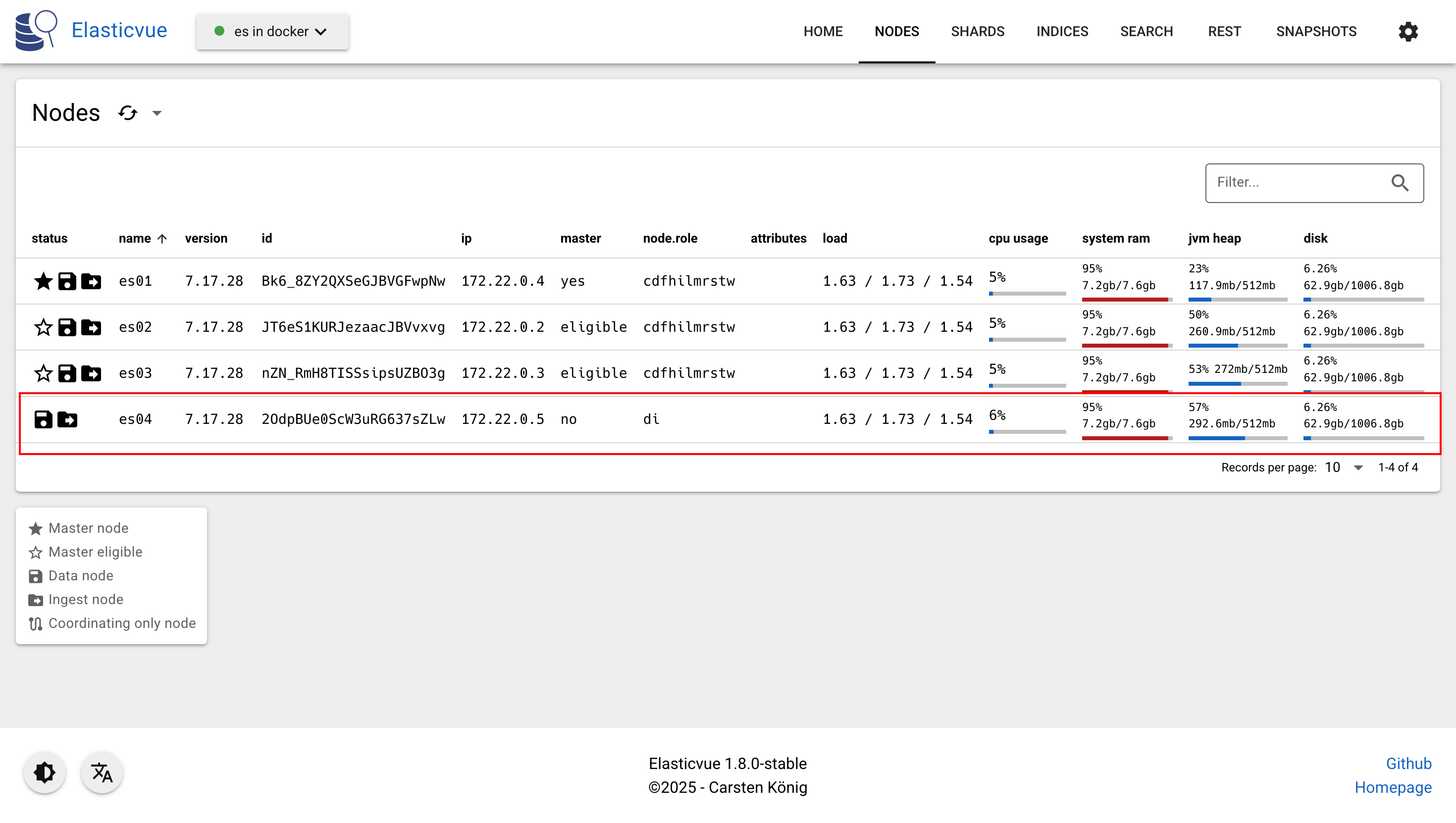
可以看到目前集群中有4个节点,并且 es04 节点的角色不包含 master-eligible 。
3.3 移除集群中的节点
请先完成第四小节的数据操作,对集群中的数据分布有更深一步理解后再进行集群中的节点移除。
经过第四小节的操作,我们知道节点上存储着分片,分片包含着索引数据,如果我们贸然移除集群中的节点,那么会导致数据丢失,从而导致索引数据不完整。所以,如果要安全地移除集群中的节点,可以按照如下步骤进行:
可选的,同步刷新,执行以下命令:
txtPOST _flush/synced注意,这一步会短暂地停止索引,如果停止索引是不可接受的,那么该步骤也可以跳过。
必须,获取要移除的节点名称,执行如下命令:
txtGET _cat/nodes?v上述命令会返回集群中的节点,我们可以确定要移除的节点名称;
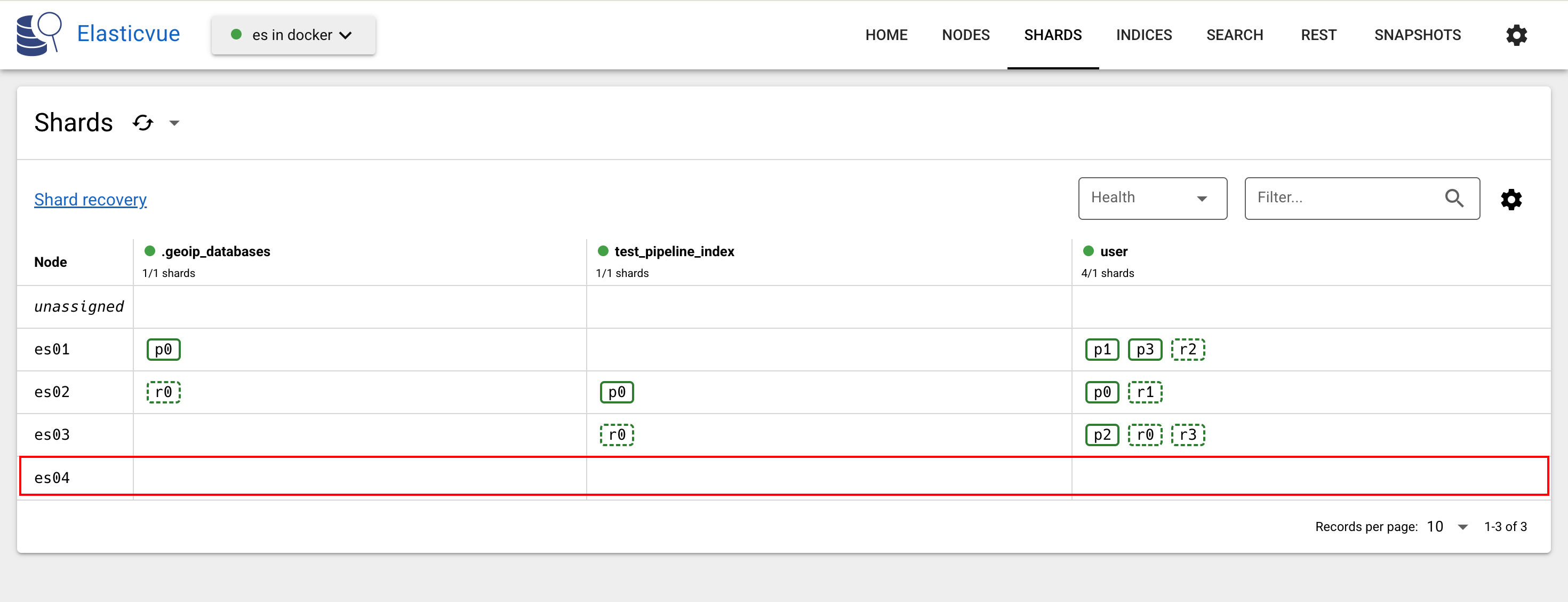
重要!!转移分片,由于节点上存储着分片,使用下面的命令将分片转移到其他节点上
txtPUT _cluster/settings { "persistent": { "cluster.routing.allocation.exclude._name": "<node_name>" } }例如,将节点es04上的分片转移到其他节点上,结果如下:
上述命令需要消耗一定时间,我们可以使用如下命令查看转移过程:
txtGET _cat/recovery?v&active_only=true只有分片完成转移后,才可以进行下一步。
关闭节点,例如,使用如下命令关闭节点:
txtsudo systemctl stop elasticsearch在docker环境下,可以直接关闭容器。
检查集群状态:
txtGET _cluster/health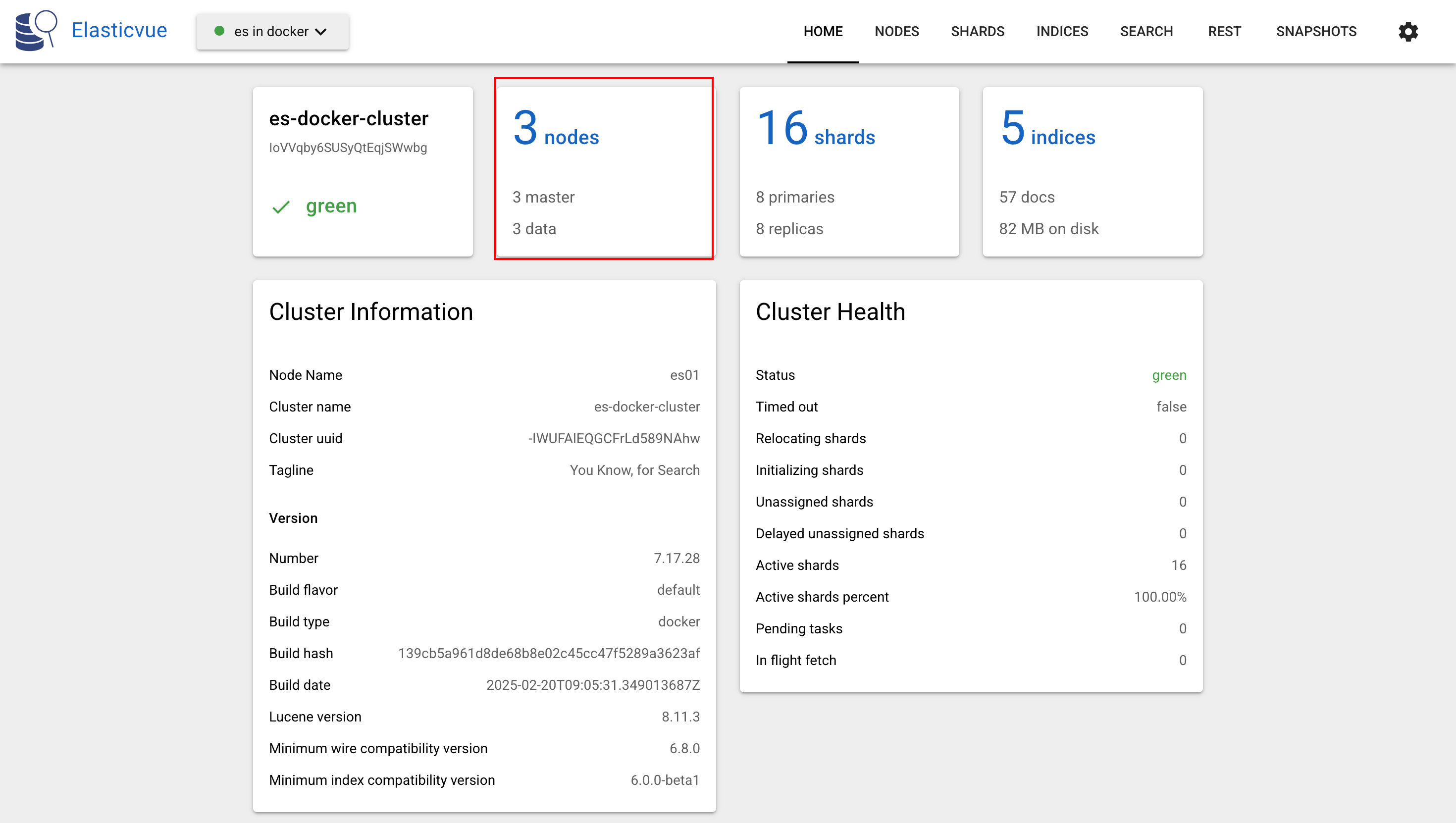
可以发现,集群中只有3个节点了,但是状态仍然是green,表示移除节点正常。
4. 集群中的数据操作
4.1 创建索引
在创建索引时,我们可以设置主分片和副本分片的数量:
number_of_shards:主分片的数量;number_of_replicas:每个主分片对应副本的数量;
txt
PUT /user
{
"settings":{
"index": {
"number_of_shards": 4,
"number_of_replicas": 1
}
},
"mappings":{
"properties":{
"name":{
"type":"keyword"
},
"birth":{
"type":"date",
"format":"yyyy-MM-dd"
},
"address":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above": 256
}
}
}
}
}
}创建完成后,在 Elasticvue 中查看分片分布状态:
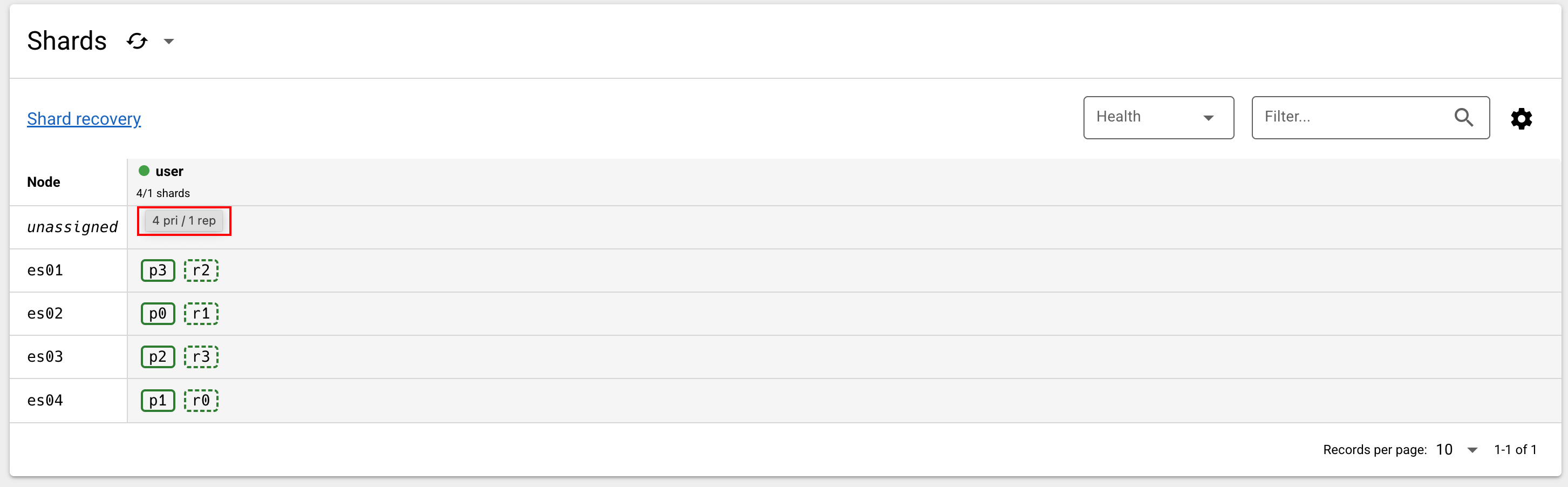
可以看到,主分片 p0 分布在了节点 es02上,主分片对应的副本分片 r0 在节点es04上,依次类推。
4.2 添加文档
为user索引中添加四条数据:
示例如下:
txt
POST /user_/doc/4
{
"name": "zl",
"birth": "1998-09-11",
"address": "北京"
}4.3 查看文档分布
4.3.1 查看某个文档在哪个分片上
如果要确定某个文档在哪个分片上,我们可以在搜索API上加上explain,如下:
txt
POST /user/_search?explain=true
{
"query": {
"ids": {
"values": [
"4"
]
}
}
}结果如下:
json
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 4,
"successful": 4,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_shard": "[user][3]",
"_node": "Bk6_8ZY2QXSeGJBVGFwpNw",
"_index": "user",
"_type": "_doc",
"_id": "4",
"_score": 1,
"_source": {
"name": "zl",
"birth": "1998-09-11",
"address": "北京"
},
"_explanation": {
"value": 1,
"description": "ConstantScore(_id:[fe 4f])",
"details": []
}
}
]
}
}从结果``_shard可以看出,_id`为4的文档位于第4个分片(从0开始)上:
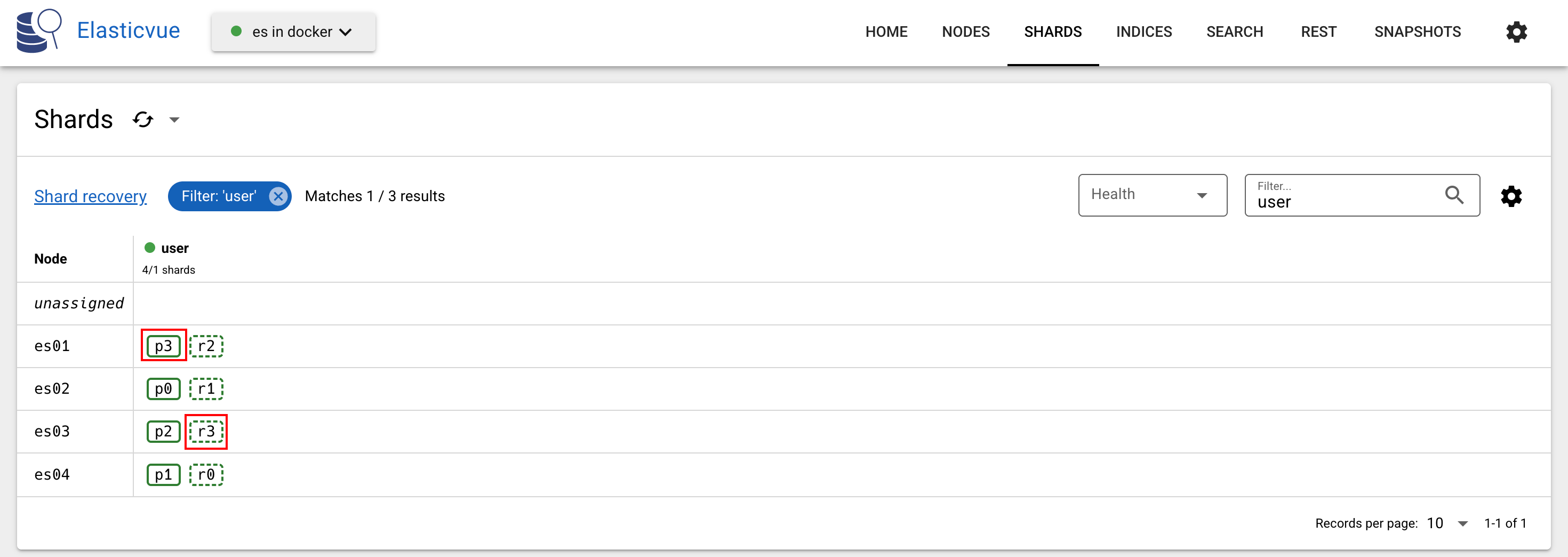
根据_node可以看出,该请求是由es01节点进行处理的:
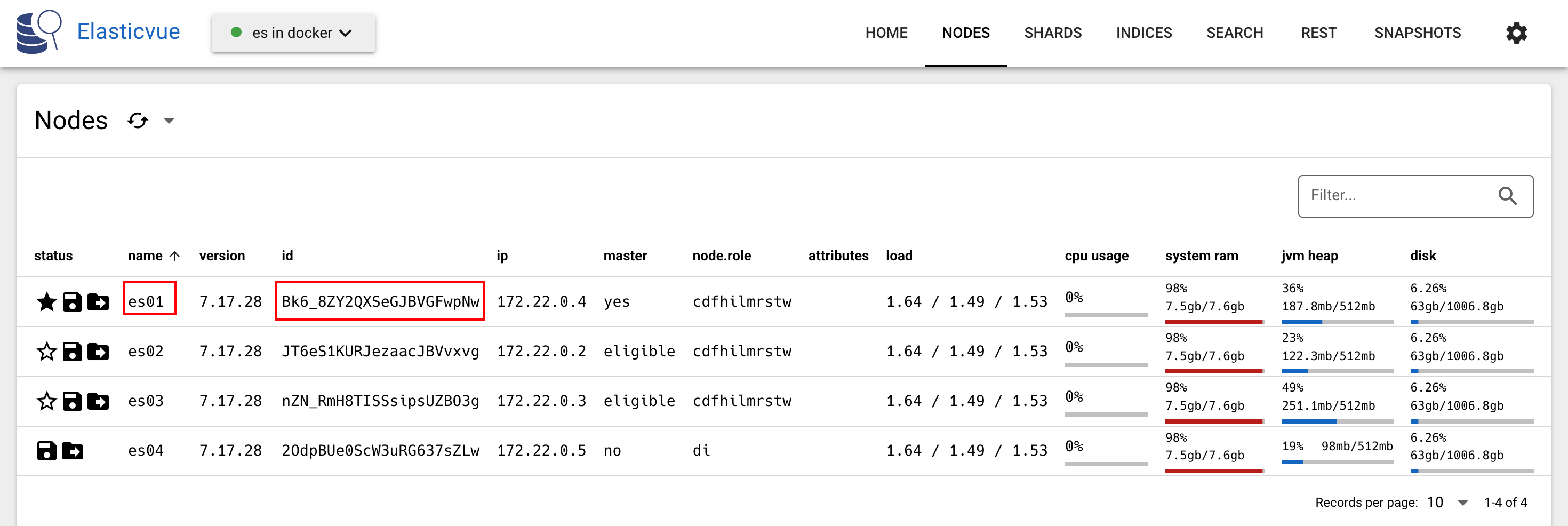
如果多次运行上述查询,会发现_node的值在es01和es03之间切换,表示请求在分片之间负载均衡。
4.3.2 查看某个分片包含哪些文档
如果要查看某个分片包含哪些文档,同样可以在查询API中指定要查询的分片,如下:
txt
POST /user/_search?preference=_shards:3
{
"query": {
"match_all":{}
}
}- 使用
preference请求参数,指定该查询要在哪个分片或着节点上执行,语法如下:preference=_shards:<shard>,<shard>:查询在指定的分片上执行;
- 结合
match_all查询,就可以查询出某分片上所有的文档,如果某分片包含的文档数量很大,则可以使用scroll或search after查询;
结果如下:
Details
json
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
// 省略数据 ...
},
{
// 省略数据 ...
}
]
}
}可以发现,第四个分片上只有2个文档。
5. 读写操作的流程
5.1 写操作流程
写操作(增加、修改、删除文档)的流程如下:
首先,写操作请求被协调节点接收,之后,协调节点根据文档ID(docID),将请求路由到对应的主分片上,该阶段称为协调阶段;
在协调阶段之后称为主分片阶段,在主分片上执行,主要完成以下任务:
校验接收到的写操作请求,如果有语法错误或不规范的地方,主分片拒绝执行写操作;
在主分片上执行写操作,在执行过程中,也会校验字段内容,如果必要拒绝执行(例如,对于Lucene来说字段值太长);
将写操作请求并发转发给当前的in-sync副本分片集合;
在主分片的所有副本分片中,有些副本分片可能掉线,所以并不会要求所有的主分片都执行写操作,而是选择一些网络连接情况良好、能执行写操作的副本分片组成in-sync集合。
副本分片执行写操作(这个阶段称为副本分片阶段),并且将执行结果返回给主分片,主分片最终将执行结果返回给客户端;
5.2 读操作流程
由于主分片和副本分片的机制,所以读操作可以由副本分片处理。
当某个节点接收到读操作请求时,该节点有责任将请求转发给相关的分片,组合各分片响应的结果,并最终返回给客户端,该节点称为协调节点。
读操作(根据DocID获取文档、搜索)的流程如下:
- 解析读请求,判断其涉及到的分片;
- 选择要转发的相关的分片,由于主分片和所有的in-sync副本分片都能处理读操作,所以此处需要根据相关算法选择活跃的分片,在ES中 ,使用自适应分片选择算法来选择分片;
- 将请求转发给第二步选择出来的分片;
- 组合各个分片返回的结果,并最终返回给客户端;
参考资料
[1] ingest:https://www.elastic.co/docs/manage-data/ingest/transform-enrich/ingest-pipelines
[2] ES in Docker:https://hub.docker.com/_/elasticsearch
[3] 移除节点(remove node from cluster):https://www.elastic.co/search-labs/blog/elasticsearch-remove-node
[4] 读写操作流程(reading and writing documents):https://www.elastic.co/docs/deploy-manage/distributed-architecture/reading-and-writing-documents
附录
1. ingest
注意,要使用ingest,需要集群中至少有一个节点具有ingest角色。
首先,创建管道pipeline:
管道定义了一系列任务(也称为processor,处理器),这些任务会被执行。具体的处理器列表可参考:https://www.elastic.co/docs/reference/enrich-processor/
例如,下面定义了名称为
my-pipeline的管道,其中具有三个处理器:set为文档设置名称为my-long-field的字段,值为10;set为文档设置名称为my-boolean-field的字段,值为true;lowercase将文档中名称为my-keyword-field的字段值转换为小写;
txtPUT _ingest/pipeline/my-pipeline { "description": "My optional pipeline description", "processors": [ { "set": { "description": "My optional processor description", "field": "my-long-field", "value": 10 } }, { "set": { "description": "Set 'my-boolean-field' to true", "field": "my-boolean-field", "value": true } }, { "lowercase": { "field": "my-keyword-field" } } ] }创建完管道后,我们就可以使用该管道了,有两种方式使用:
- 文档级:当把新文档加入到索引前,对该文档应用管道,改变该文档的数据;
- 索引级:对于任何要新加入到索引的文档,都应用管道,改变文档数据;
下面演示如何对新文档应用管道:
txtPOST /user/_doc?pipeline=my-pipeline { "name": "test", "address": "us", "birth": "2000-10-10", "my-keyword-field": "ABC" }- 使用请求参数
pipeline指定要应用的管道; - 必需要有名称为
my-keyword-field的字段,否则新建文档会失败;
在索引层面上应用管道,有两种管道:
- 默认管道(default pipeline):如果没有在文档级指定管道,那么就会在新文档上应用默认管道;
- 最终管道(final pipeline):在文档级的管道或索引级的默认管道执行后,最终管道会执行;
在索引层面上设置管道,既可以在创建索引时设置,也可以在索引创建完成后修改索引设置。
在创建索引时设置:
txtPUT /{index-name} { "settings":{ "index":{ "default_pipeline":"{pipeline-name}", "final_pipeline":"{pipeline-name}" } } }修改索引配置:
txtPUT /{index-name}/_settings { "settings":{ "index":{ "default_pipeline":"{pipeline-name}", "final_pipeline":"{pipeline-name}" } } }如果要为索引取消管道,直接将值设置为
null即可。删除管道:如果认为管道不再使用,那么可以删除管道,如下:
txtDELETE /_ingest/pipeline/{id}此处的
{id}就是管道名称。注意,如果该管道被索引使用,那么删除操作会失败。