Appearance
Index Lifecycle Management
本文介绍索引生命周期管理(Index Lifecycle Management,简称ILM)。
1. 什么是ILM
在介绍ILM之前,我们需要介绍一下时序数据与内容数据:
时序数据(Time Series Data):时序数据是指随时间推进而不断产生的流式数据,每一条数据都有一个精确的时间戳(
@timestamp)。时序数据具有以下特点:- 只增不改 (Append-only):数据一旦写入,极少会被修改;
- 价值随时间递减:最近 1 小时的日志最重要,1 年前的日志可能只有在审计时才有用;
- 海量且高速:数据量通常极大(如每秒万级写入);
典型的时序数据有日志、监控指标 (Metrics,例如CPU 使用率)、应用链路追踪 (APM)。
内容数据(Content Data):内容数据代表一组相对稳定的实体对象集合,更接近于传统数据库中的“表”数据。内容数据具有以下特点:
- 频繁更新 (Update-heavy):数据会不断被修改。例如,一件商品的库存、价格或描述会经常变动;
- 价值持久恒定:无论商品是 1 天前上架还是 100 天前上架,只要它没下架,搜索价值就是一样的;
- 随机访问:用户可能搜索任何一个时间点创建的实体,没有明显的“时间偏好”;
典型的内容数据有商品信息、用户信息、知识库文章等等。
针对时序数据的价值随事件递减以及海量的特性,如果我们将所有的数据都存放在同一个索引,那么单个索引将会变得巨大,存储和搜索也面临着巨大的挑战,因此,根据时序数据的特点,我们可以考虑:
- 根据时间段存储时序数据,例如将一个月的数据存放在一个索引中;
- 针对时序数据的价值随事件递减,那么我们可以将近期的数据存放在高性能的 NVMe/SSD 硬盘和 CPU 性能优秀的机器上,将历史数据存放在大容量、低成本的机械硬盘(HDD)上;
为了实现以上目的,ES提出了节点角色和ILM:
节点角色(Node Role):每次启动一个ES实例,就是启动了一个节点,每个节点都有角色,关于数据的角色有
data、data_content、data_hot、data_warm、data_cold、data_frozen;参考链接:https://www.elastic.co/docs/deploy-manage/distributed-architecture/clusters-nodes-shards/node-roles
ILM(Index Lifecycle Management):ILM可以将索引移动到不同的节点上,并且创建新的索引来接收最新的数据;
2. 索引生命周期
ILM定义了5个索引生命周期(phase):
- Hot:索引经常被更新和查询;
- Warm:索引偶尔被更新,但是仍然经常被查询;
- Cold:索引偶尔或完全不被更新,偶尔查询;数据仍然需要被查询,但是此时查询速度慢是可以接受的;
- Frozen:索引不被更新,很少被查询;查询速度极慢也是可以的;
- Delete:索引不再被需要,可以安全删除;
索引在在生命周期之间迁移,是根据索引的年龄(age)来定的,同样地,各个生命周期也定了了索引最小年龄(min_age),只有索引的年龄大于该生命周期的最小年龄,那么该索引才能进入该生命周期。
例如,设置了5个索引生命周期,各个生命周期的min_age如下:
| 周期 | min_age |
|---|---|
| hot | - |
| warm | 7d |
| cold | 14d |
| frozen | 28d |
| delete | 58d |
IMPORTANT
注意,hot阶段并没有设置min_age,因为索引一创建,就会在hot阶段。
假设在2025-12-01创建了索引A,那么最开始索引A在hot周期;
索引A在hot周期待了7天后,此时索引的年龄达到了7d,此时达到了warm周期的min_age,那么该索引就会进入warm周期。
索引A在warm周期又待了7天后(注意,是7天而不是14天),此时索引的年龄为14d,此时达到了cold周期的min_age,因此索引就会进入cold周期。其他周期依次类推。
IMPORTANT
因此,我们需要注意,在各个周期配置的min_age,应该是递增的,即在cold周期配置的min_age不能小于在warm周期配置的min_age。
如果设置周期的min_age为0,那么表示索引进入该周期后,执行完必要的动作(actions)后,就会进入下一周期。
IMPORTANT
如果某个索引被rollovered,那么该索引的年龄会从rollovered时间开始计算,而不是创建时间。
3. 周期动作
在索引生命周期中,我们可以定义多个动作,当索引进入该生命周期后,这些动作就会执行,以实现不同的目的。每个周期支持的动作不同,具体如下表:
| Action | Hot | Warm | Cold | Frozen | Delete |
|---|---|---|---|---|---|
| Allocate | ✕ | ✓ | ✓ | ✕ | ✕ |
| Delete | ✕ | ✕ | ✕ | ✕ | ✓ |
| Downsample | ✓ | ✓ | ✓ | ✕ | ✕ |
| Force merge | ✓ | ✓ | ✕ | ✕ | ✕ |
| Migrate | ✕ | ✓ | ✓ | ✕ | ✕ |
| Read-only | ✓ | ✓ | ✓ | ✕ | ✕ |
| Rollover | ✓ | ✕ | ✕ | ✕ | ✕ |
| Searchable snapshot | ✓ | ✕ | ✓ | ✓ | ✕ |
| Set priority | ✓ | ✓ | ✓ | ✕ | ✕ |
| Shrink | ✓ | ✓ | ✕ | ✕ | ✕ |
| Unfollow | ✓ | ✓ | ✓ | ✓ | ✕ |
| Wait for snapshot | ✕ | ✕ | ✕ | ✕ | ✓ |
下面介绍几个重点的动作。
3.1 Rollover
只作用在hot周期。
当索引满足Rollover的条件时,ILM会创建一个新的索引,并且将具有读属性的别名指向新的索引,要实现Rollover,索引需要满足以下条件:
索引名称必须以
名称-数字(*^.*-\d+$*)的方式命名,例如logs-000001;- 当索引发生Rollover时,ILM会会识别索引名末尾的数字,将该数字+1,使用新数字创建新索引,如
logs-000002;
虽然
my-index-1也可以工作,但生产环境建议使用my-index-000001(6 位数字)。原因:这能确保在文件系统和 Kibana 列表中,索引可以按照正确的逻辑顺序排序(否则
index-10可能会排在index-2前面)。- 当索引发生Rollover时,ILM会会识别索引名末尾的数字,将该数字+1,使用新数字创建新索引,如
index.lifecycle.rollover_alias必须配置为Rollover操作的别名;该索引为该别名下的写索引;
假设现在my_policy为ILM,如果要为index-000001索引配置Rollover,那么创建索引时,配置如下:
json
PUT index-000001
{
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "my_data"
},
"aliases": {
"my_data": {
"is_write_index": true
}
}
}当发生Rollover时,ES内部会执行以下步骤:
解析序号:系统读取当前索引名
index-000001,识别末尾数字并加 1,计算出新索引名为index-000002;创建新索引:
- 根据关联的索引模板(如果有的话)创建物理索引
index-000002; - 如果没有模板,它会复制旧索引的部分 Settings;
- 根据关联的索引模板(如果有的话)创建物理索引
权限转移(核心):别名权限转移
- 将
index-000001的别名my_data的is_write_index设为false; - 将
index-000002的别名my_data的is_write_index设为true;
现在,
my-data别名指向两个索引index-000001和index-000002,但只有index-000002接受写入。- 将
现在介绍Rollover是什么时候发生的。
在Rollover配置中,至少需要包含一个以max开头的属性,可以包含0个或多个以min开头的属性。如果Rollover配置为空,那么该Rollover无效。
只要有一个以max开头的属性满足,并且所有以min开头的属性满足时,Rollover就会发生。
注意,默认情况下,空索引不会发生Rollover。
下面介绍Rollover属性:
max_age:当索引生命(从索引创建时间开始)达到该时间后,Rollover就会发生;max_docs:当索引(只计算主分片)包含的文档数量达到该值后,Rollover就会发生。注意,索引中的文档并不包含最后一次刷新refresh后添加的文档,因为这些文档还没有刷新到索引中;max_size:当索引(只计算主分片)的大小(以字节为单位)达到该值后,Rollover就会发生;max_primary_shard_size:当任意一个索引的主分片大小(以字节为单位)达到该值后,Rollover就会发生;max_primary_shard_docs:当任意一个索引的主分片中包含的文档数量达到该值后,Rollover就会发生;min_age:只有索引生命达到该时间后,Rollover才会发生;min_docs:只有索引(只计算主分片)包含的文档数量达到该值后,Rollover才会发生;min_size:只有索引(只计算主分片)的大小(以字节为单位)达到该值后,Rollover才会发生;min_primary_shard_size:只有任意一个索引的主分片大小(以字节为单位)达到该值后,Rollover才会发生;min_primary_shard_docs:只有任意一个索引的主分片中包含的文档数量达到该值后,Rollover才会发生;
IMPORTANT
空索引不会发生Rollover,即使索引达到了设置的max_age值;
通过设置"min_docs": 0,可以解决该问题;也可以设置indices.lifecycle.rollover.only_if_has_documents: false。
IMPORTANT
默认情况下,当主分片包含的文档数量达到了2亿时,Rollover会发生。
例如,配置索引文档大小达到100gb时,触发Rollover:
json
{
"rollover": {
"max_size": "100gb"
}
}3.2 Read Only
作用周期:hot、warm、cold
该动作的作用是将索引设置为只读的,禁止在索引上执行写操作。
如果要在hot周期使用该动作,那么Rollover动作必须存在。
使用Read Only例子:
json
{
"readonly": {}
}3.3 Shrink
作用周期:hot、warm
Shrink动作的作用是将索引设置为只读的,然后将创建一个拥有更少分片的新索引(新索引的名称为shrink-<random-uuid>-<original-index-name>),将旧索引数据“复制”到新索引中。Shrink动作完成后,旧索引会被删除,原先指向旧索引的别名会指向新索引。
TIP
Shrink动作内部已经自动包含了“设置索引为只读”的逻辑,因此,不需要再显式地设置Read Only动作。
IMPORTANT
在Shrink动作期间,ILM会把旧索引的所有分片分配到一个节点上,然后执行Shrink。Shrink之后,ILM会根据分片分配规则,把新索引的分片分配到合适的节点上。
如果要在hot周期使用该动作,那么Rollover动作必须存在。
Shrink会取消索引index.routing.allocation.total_shards_per_node配置,意味着所有分片都可以分配到一个节点上。
下面是Shrink动作的属性:
number_of_shards:指定shrink后分片的数量,注意,原索引的主分片数必须能被新索引的主分片数整除。为了保证数据搬迁的高效和一致性,Elasticsearch 在执行收缩时并不是重新进行“哈希计算(Re-hashing)”,而是直接合并底层的分片,即将原有的多个主分片直接组合成一个新的主分片。
假设旧索引的主分片数量为9,那么可以将新索引的主分片数设置为3,意味着每个新分片将正好包含原先的 3 个分片;如果想把 9 个分片缩减为 2 个,那么每个新分片就无法平均分配旧分片(
),这在底层的分片合并逻辑中是不被允许的。 IMPORTANT
虽然
shrink动作能减少分片数量,但要注意单个分片的大小。官方建议单个分片的大小最好保持在 10GB - 50GB 之间。如果原本有 9 个分片,每个 50GB(总计 450GB),强行 Shrink 到 1 个分片,那么这单个分片就是 450GB,这会导致该索引在后续的移动、恢复(Recovery)和查询时变得非常沉重,极易引发性能问题。
max_primary_shard_size:设置新索引的分片大小(以字节为单位)最大值,ES会自动计算新索引分片数量(注意,新索引分片数量仍然是旧索引分片数的因子);当设置该值后,新索引的分片大小不会超过该值;假设原索引有60个分片,设置新索引的分片大小为50gb:
- 假设原索引大小为100gb,那么新索引有2个主分片;
- 假设原索引大小为1000gb,那么新索引有20个主分片;
- 假设原索引大小为4000gb,那么新索引有60个主分片;
WARNING
注意,
number_of_shards和max_primary_shard_size互相冲突,在Shrink动作配置中,只能有一个配置存在;allow_write_after_shrink:是否允许新索引在Shrink完成后,允许写操作,默认值为false;
下面的例子,将旧索引分片数缩减到1个:
json
{
"shrink": {
"number_of_shards": 1
}
}3.4 Migrate
作用周期:warm、cold
Migrate会根据当前索引生命周期,将索引移动到符合该生命周期的节点,也就是说,将处于warm周期的索引移动到具有data_warm角色的节点,将处于cold周期的索引移动到具有data_cold角色的节点。该项功能是通过修改index.routing.allocation.include._tier_preference索引设置来实现的。ILM会自动在wam和cold周期注入Migrate动作,如果要禁用该动作,可以设置enable: false。
在warm周期,ILM会设置index.routing.allocation.include._tier_preference为data_warm,data_hot,即把索引移动到到data_warm节点,如果ES集群中没有data_warm节点,则移动到data_hot节点。
在cold周期,ILM会设置index.routing.allocation.include._tier_preference为data_cold,data_warm,data_hot,同理,先将索引移动到data_cold节点,如果没有,则移动到data_warm节点,如果还没有,移动到data_hot节点。
在下面的例子中,显式地禁用Migrate动作:
json
{
"migrate": {
"enabled": false
}
}3.5 Allocate
作用周期:warm、cold
Allocate的作用是修改索引副分片数量,以及配置分片分配规则(即允许哪个节点拥有分片)。
Allocate的属性如下:
number_of_replicas:副分片的数量;total_shards_per_node:单节点能拥有的分片数量,如果设置为-1,表示不限制分片数量;include:当节点自定义属性满足一个include中指定的配置时,说明该节点可以拥有索引分片;exclude:当节点自定义属性全不满足exclude中指定的配置时,说明该节点可以拥有索引分片;require:当节点自定义属性全满足require中指定的配置时,说明该节点可以拥有索引分片;
下面的例子说明Allocate动作将索引副分片数量设置为1,并且要求节点拥有自定义属性box_type:cold,才能拥有该索引分片:
json
{
"allocate": {
"number_of_replicas": 1,
"require": {
"box_type": "cold"
}
}
}3.6 Set Priority
作用周期:hot、warm、cold
Set Priority设置索引的优先级,决定当集群发生重启或故障恢复时,索引被加载(恢复)的先后顺序。值越大,优先级越高。
当 Elasticsearch 集群整体重启(比如系统维护、停电)或者某个节点宕机恢复时,成千上万个分片(Shards)需要重新分配和恢复。
- 没有优先级的情况:集群会随机或者按字母顺序恢复索引。如果这时候活跃热日志还没恢复,而几年前的旧冷索引抢占了带宽,业务写入就会报错。
- 有了优先级(Set Priority):可以强制要求 Hot 索引最先启动。只有当 Hot 索引恢复完毕,系统才去处理 Warm 和 Cold 索引。
在标准的 ILM 策略中,官方推荐“阶梯式”优先级配置如下:
| 阶段 (Phase) | 建议优先级数值 | 逻辑原因 |
|---|---|---|
| Hot | 100 | 最高优先级。必须保证正在写入的数据和最新的查询最先可用。 |
| Warm | 50 | 次高。已经不再写入,但仍有较频繁的查询需求。 |
| Cold | 0 | 最低。通常是归档数据,晚几个小时恢复也没关系。 |
set_priority 永远是一个阶段进入后的第一个动作。
设置优先级例子如下:
json
{
"set_priority": {
"priority": 50
}
}4. 周期动作的执行顺序
我们可以在一个周期中定义多个动作,当索引进入新的周期后,会开始执行各个动作,但是动作的执行顺序是有要求的。
详细的周期动作执行顺序:https://www.elastic.co/docs/manage-data/lifecycle/index-lifecycle-management/index-lifecycle
我们以warm周期为例,会按照以下顺序执行动作:
- Set Priority:设置优先级;
- Read Only:设置索引为只读的;
- Allocate:修改索引副分片数量,以及设置分片分配规则;
- Migrate:将索引移动到
data_warm节点; - Shrink:将索引的主分片集中到一个
data_warm节点,然后执行Shrink操作,最后,根据Allocate设置的分片分配规则,将主分片分配到其他data_warm节点;
5. 应用ILM
本小节介绍如何使用ILM。分为以下三个步骤:
- 创建ILM策略;
- 创建索引模板,并使用ILM策略;
- 创建初始索引;
5.1 创建ILM策略
我们可以使用以下API创建ILM策略:
- 定义了hot周期,执行两个动作,设置优先级以及Rollover策略,当索引中文档数量达到2时,执行Rollover动作;
- 定义了warm周期,设置
min_age为5m,表示Rollover后5分钟,旧索引进入warm周期,之后开始执行readonly、allocate(将副分片数量设置为0)、migrate(ILM自动注入,将索引移到data-warm节点)、和shrink(将新索引的主分片数量设置为1)动作;
json
# 创建ILM策略
PUT _ilm/policy/my_policy-2
{
"policy": {
"phases": {
"hot": {
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_docs": 2
}
}
},
"warm":{
"min_age": "5m",
"actions": {
"readonly": {},
"allocate": {
"number_of_replicas": 0
},
"shrink": {
"number_of_shards": 1
}
}
}
}
}
}5.2 创建索引模板
然后创建索引模板,应用之前创建的ILM策略:
json
# 创建索引模板
PUT _index_template/ilm_template-2
{
"index_patterns": ["ilm2-test-*"],
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"index.lifecycle.name": "my_policy-2",
"index.lifecycle.rollover_alias": "ilm-write"
},
"aliases":{
"ilm-read":{}
}
}
}5.3 创建初始索引
创建第一个索引,注意以下事项:
- 索引名称需要符合索引模板匹配规则,并且以数字结尾;
- 设置在索引模板中
index.lifecycle.rollover_alias相同的别名,并且设置第一个索引为可写索引;
json
# 创建第一个索引
PUT ilm2-test-000001
{
"aliases": {
"ilm-write": {
"is_write_index": true
}
}
}5.4 效果演示
首先向受管理的索引中写入2个文档:
json
POST /ilm-write/_doc/1?refresh=true
{
"msg": "1"
}
POST /ilm-write/_doc/2?refresh=true
{
"msg": "2"
}然后,等待一段时间后(默认值为10分钟),ILM会检查受管理的索引是否达到了动作执行标准。
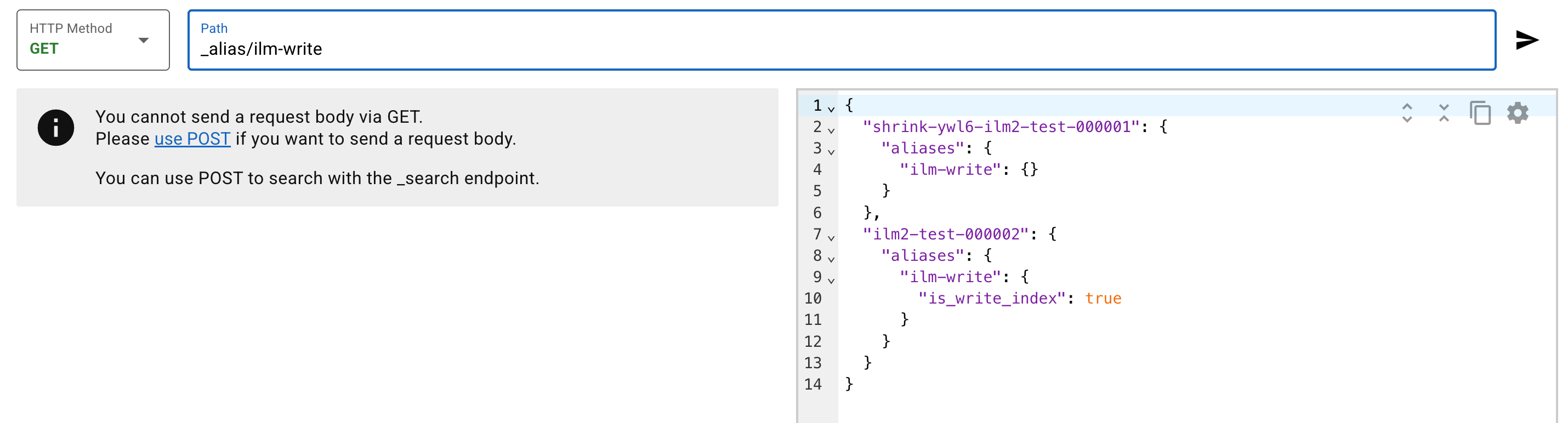
此时ILM发现ilm2-test-000001索引达到了Rollover标准,执行Rollover动作,创建ilm2-test-000002索引,并且ilm-write别名指向ilm2-test-000001和 ilm2-test-000002 索引,但是 ilm2-test-000002 索引变为可写索引(is_write_index为true),ilm2-test-000001 索引变为不可写索引(is_write_index为false)。
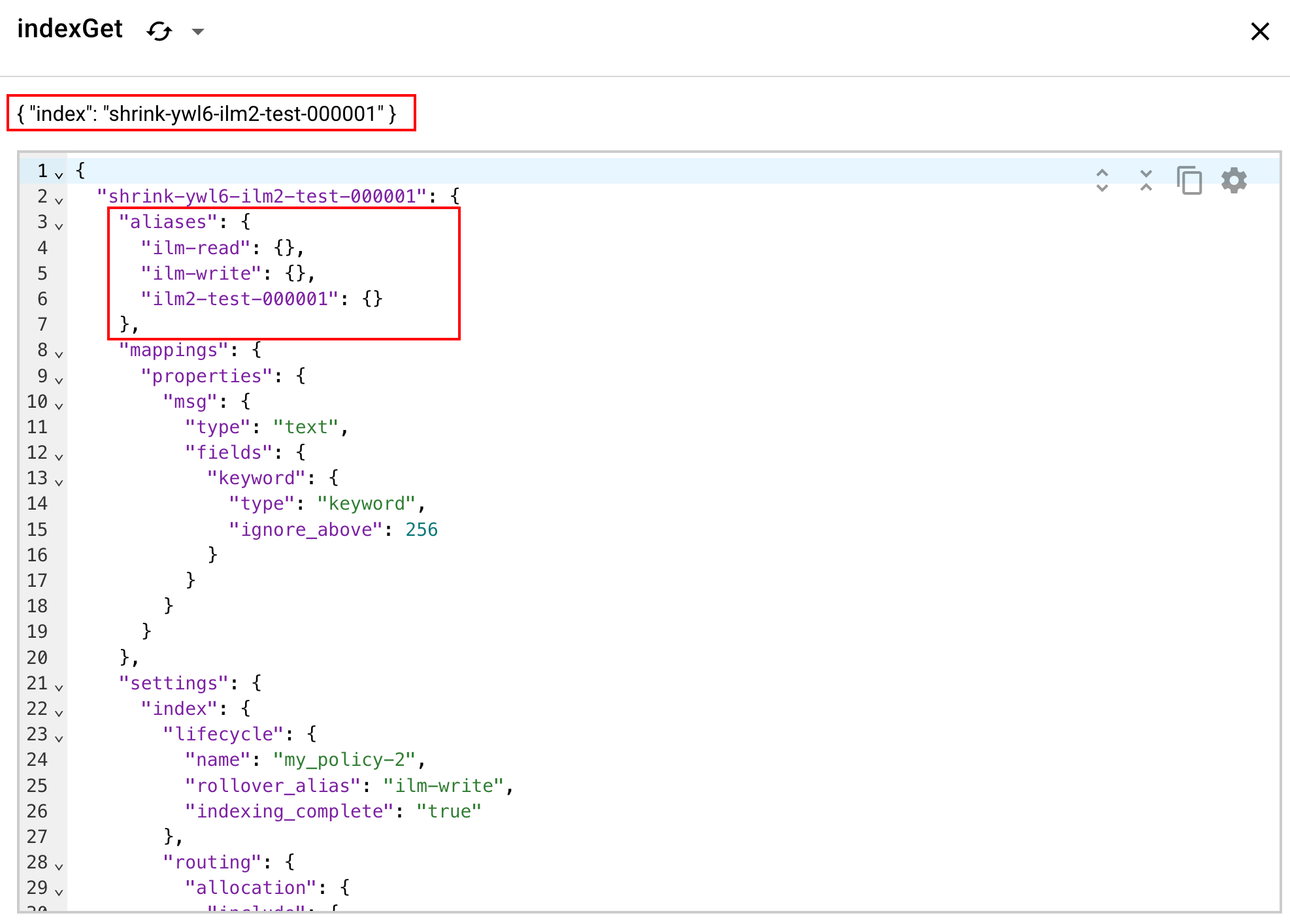
ilm2-test-000001 经过Rollover 5分钟后,进入warm周期,开始执行readonly、allocate、migrate和shrink动作,最终,创建一个名为_shrink-ywl6-ilm2-test-000001_ 的新索引,ilm2-test-000001 索引被删除,原先指向_ilm2-test-000001_ 的别名指向shrink创建的新索引,并且添加名为ilm2-test-000001的别名指向_shrink-ywl6-ilm2-test-000001_ 索引。
下图表示 ilm-write 别名指向两个索引,其中最新的索引是可写的:
下图表示 ilm2-test-000001索引经过warm阶段的动作后,只剩下一个主分片:

下图表示经过 shrink 后,创建的新索引具有的别名:
5.5 注意事项
5.5.1 ILM检查时间间隔
我们可以使用以下API查看ILM的检查时间间隔:
json
GET _cluster/settings?include_defaults=true&filter_path=**.indices.lifecycle.poll_interval结果如下:
json
{
"persistent": {
"indices": {
"lifecycle": {
"poll_interval": "5m"
}
}
},
"transient": {
"indices": {
"lifecycle": {
"poll_interval": "1m"
}
}
}
}默认值为10分钟(以上结果是经过修改后的)。
我们可以使用以下API修改ILM的检查时间间隔:
json
# 临时修改,ES集群重启后失效
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "1m"
}
}
# 永久修改,ES集群重启后仍然有效
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "5m"
}
}5.5.2 查看索引的生命周期
如果我们要查看某个索引的生命周期,可以使用以下API:
json
GET {index-name}/_ilm/explain结果如下:
json
{
"indices": {
"shrink-ywl6-ilm2-test-000001": {
"index": "shrink-ywl6-ilm2-test-000001",
"managed": true,
"policy": "my_policy-2",
"lifecycle_date_millis": 1766822491747,
"age": "27.92m",
"phase": "warm",
"phase_time_millis": 1766822791819,
"action": "complete",
"action_time_millis": 1766822852586,
"step": "complete",
"step_time_millis": 1766822852586,
"shrink_index_name": "shrink-ywl6-ilm2-test-000001",
"phase_execution": {
"policy": "my_policy-2",
"phase_definition": {
"min_age": "5m",
"actions": {
"readonly": {},
"allocate": {
"number_of_replicas": 0,
"include": {},
"exclude": {},
"require": {}
},
"shrink": {
"number_of_shards": 1
}
}
},
"version": 1,
"modified_date_in_millis": 1766822181749
}
}
}
}其中 phase 属性表明了该索引的生命周期。
参考资料
[1] https://www.elastic.co/docs/manage-data/lifecycle/index-lifecycle-management
[2] https://www.elastic.co/docs/reference/elasticsearch/index-lifecycle-actions