Appearance
Logstash介绍
本文主要介绍如何使用Logstash。
1. Logstash介绍
1.1 概述
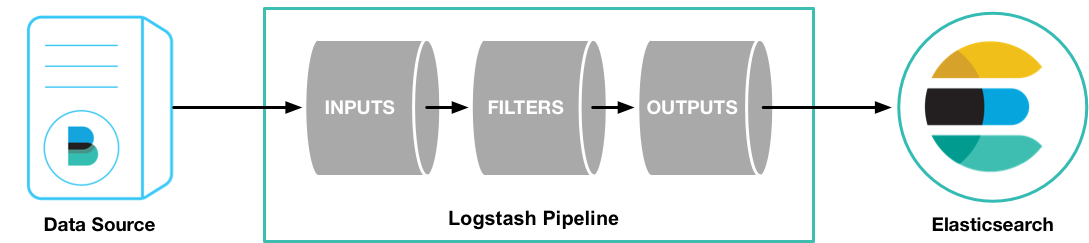
Logstash是开源的数据处理管道工具,主要负责从多个来源获取数据,处理数据,然后把处理后的数据输出到指定目的地。
因此,Logstash的数据处理三大阶段如下:
- 输入(input):用于接收数据,例如读取文件、监听端口、消费 Kafka、接收 syslog 等;
- 处理/过滤(filter):用于处理数据,例如解析日志、提取字段、改名、加时间戳、GeoIP、脱敏等;
- 输出(output):用于输出数据,例如写入 Elasticsearch、Kafka、文件、Redis、MongoDB 等;
我们可以在管道(pipeline)中定义以上的流程,如下图所示:
1.2 执行模式
Logstash事件(event)处理管道协调输入(input)、过滤器(filter)、输出(output)三者的执行,具体如下:
输入阶段 (Input Stage): 每个输入源都在自己的独立线程中运行。它们负责接收数据并将事件写入到一个中央队列 (Central Queue)。
中央队列: 这是一个中转站。默认情况下,它存在于内存中,但也可以配置在磁盘上。
工作线程 (Worker Threads): Logstash 会运行多个管道工作线程(Pipeline Worker Threads)。
每个工作线程从中央队列中取出一批 (Batch) 事件。
线程带着这批事件依次经过“过滤器(filter)”进行处理,最后通过“输出(output)”发送出去。
经过上面的了解,队列的位置(内存或磁盘)和大小、批次大小 (Batch size)和工作线程数量都是可以手动配置的,这直接影响 Logstash 的处理性能
2. 基础案例
本小节主要介绍在MacOS系统上,Logstash的安装以及基础案例。
2.1 安装Logstash
下载地址:https://www.elastic.co/downloads/logstash
下载完成后,将压缩包解压,注意,解压后的目录路径不要包含冒号:。Logstash主目录包含的文件和文件夹如下:
| 名称 | 描述 |
|---|---|
| bin | 存放二进制脚本,包括logstash用于启动Logstash、logstash-plugin用于安装插件 |
| config | 存放配置文件,包括: 1. logstash.yml:Logstash配置文件 2. pipelines.yml:用于定义多个管道 3. jvm.options:用于调整JVM参数 4. log4j.properties:用于调整Logstash的日志参数; |
| data | 由Logstash和插件使用的数据文件,例如队列持久化 |
| logs | 默认的日志目录,刚下载时没有 |
| vendor | 插件目录 |
| jdk.app | 用于运行Logstash的JDK |
Logstash是运行在JRE上的,因此,在下载时会自带JDK,并且在运行时默认使用自带的JDK。
如果要使用其他JDK,需要设置
LS_JAVA_HOME环境变量。
2.2 第一个案例
当下载解压Logstash后,进入Logstash主目录,执行以下命令:
bash
bin/logstash -e 'input { stdin { } } output { stdout {} }'-e参数表示在命令行中定义管道(用于快速测试),上述命令表示定义一个输入,从标准输入(键盘)获取,然后输出到标准输出(屏幕)。
待Logstash启动完成后,在命令行中随意输入内容,Logstash会获取该输入,并输出处理后的内容,结果如下:

2.3 定义pipeline
我们可以将pipeline保存在文件中,例如pipelines/first_pipeline.conf:
yaml
input{
stdin { }
}
output{
stdout { }
}之后,使用如下命令运行Logstash:
bash
bin/logstash -f pipelines/first_pipeline.conf-f参数使用指定的管道配置文件来运行Logstash。
3. 插件
本小节介绍Logstash中的插件。
3.1 input插件
input插件用于获取数据,插件列表:https://www.elastic.co/docs/reference/logstash/plugins/input-plugins。本小节以jdbc为例,介绍如何从MySQL数据库获取数据。
3.1.1 jdbc
jdbc输入插件用于从任意数据库获取数据到Logstash,我们可以使用cron表达式定时获取数据,或者只获取一次数据。SQL查询结果集中的每一行成为一个事件(event),结果集中的列成为事件中的字段(field)。
下面是jdbc的基础配置案例:
yaml
input {
jdbc {
jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "mysql"
jdbc_password => "xxx"
parameters => { "favorite_artist" => "Beethoven" }
statement => "SELECT * from songs where artist = :favorite_artist"
schedule => "* * * * *"
}
}jdbc_driver_library:指定JDBC驱动所在的路径;jdbc_driver_class:JDBC驱动类;jdbc_connection_string:JDBC链接串;jdbc_user:数据库用户;jdbc_password:数据库用户密码;parameters:参数,可用于SQL;statement:SQL 语句,其中可以使用:param的方式来引用参数值;schedule:cron表达式,表示SQL语句的执行频率;
除了以上基本参数,还有一些基本参数:
interval:与schedule功能相同,定义SQL语句的执行频率,例如10s,表示下一次执行是在上一次执行完成后10s才开始,可以理解为固定延迟;period:同样是定义SQL语句的执行频率,例如10s,表示下一次执行是在上一次执行开始后10s才开始,可以理解为固定频率;关于interval与period的区别,假设有个SQL需要执行12s,interval和period都设置为10s
interval:0s(SQL-1执行) -> 12s(SQL-1执行结束) -> 等待10s -> 22s(SQL2开始执行) -> 34s(SQL-2执行结束)
period: 0s(SQL-1执行) -> 10s(SQL-2开始执行) -> 12s(SQL-1执行结束) -> 22s(SQL-2执行结束)
可以发现,如果SQL执行事件过长或period设置的间隔过短,会造成上一个SQL还没结束,又继续执行下一个SQL,对数据库造成压力。
但是,JDBC input 在调度层面是单 worker 线程的,也就是说,同一个 JDBC input 实例(同一个插件配置)永远只能同时运行一个查询执行。如果上一个查询还没结束,下一次触发(无论 period、interval 还是 schedule)都会被忽略/跳过(不会排队,也不会并发执行)。
statement_filepath:如果SQL太长或者过于繁琐,那么可以把SQL写在文件中,通过statement_filepath指定文件路径;
除了以上的基本配置,还有一些特定场景下的配置。
处理大结果集:即一条SQL返回的行数很大,例如几十万行
jdbc_fetch_size:在jdbc插件中,设置该值来限制一次将结果集中的多少数据拉回,该配置没有默认值,如果没有设置,那么使用JDBC驱动的默认值。
假设我们使用的驱动是:
xml
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>9.4.0</version>
</dependency>JDBC驱动默认的fetch size为0,并且,JDBC驱动默认是不开启流式返回的!
以下代码判断是否开启流式返回:
java
private boolean useServerFetch() throws SQLException {
Lock connectionLock = checkClosed().getConnectionLock();
connectionLock.lock();
try {
return this.session.getPropertySet().getBooleanProperty(PropertyKey.useCursorFetch).getValue() && this.query.getResultFetchSize() > 0
&& this.query.getResultType() == Type.FORWARD_ONLY;
} finally {
connectionLock.unlock();
}
}需要同时满足以下三个条件:
useCursorFetch属性为 true: 这是在连接数据库的 URL 中配置的参数(例如jdbc:mysql://host/db?useCursorFetch=true)。如果全局没开启这个开关,这里直接返回false。fetchSize > 0: 在 Java 代码中必须显式调用了statement.setFetchSize(n),并且n大于 0。这告诉驱动程序每次“抓取”多少行。我们通过Logstash获取,显然不能设置Java代码,因此可以在数据库连接串中设置默认的fetchSize,例如jdbc:mysql://host/db?useCursorFetch=true&defaultFetchSize=1000;ResultSet类型为FORWARD_ONLY: 查询结果必须是只读且只能向前滚动的。如果你设置了结果集可以随机跳转(比如SCROLL_INSENSITIVE),则无法使用游标抓取。在Logstash的jdbc插件中,默认使用PreparedStatement,因此,结果集类型默认就是FORWARD_ONLY的;
综合以上条件,如果要在jdbc输入插件中设置fetch size,需要同时设置数据库连接串如下:
jdbc:mysql://host/db?useCursorFetch=true&defaultFetchSize=1000&useServerPrepStmts=true
除了使用fetch size方案来处理大结果集,我们也可以使用分页的方式,jdbc输入插件提供以下参数来分页:
jdbc_paging_enabled:是否启用分页功能,默认为false;jdbc_page_size:页大小,默认值为100000;jdbc_paging_mode:分页模式,可选值为auto,explicit,默认值为auto:auto:当设置分页模式为auto时,我们的SQL语句在执行前,会先执行一个count查询,用于统计结果集行数,如果行数大于0,那么会自动分为多个分页查询(通过LIMIT指定),其中分页大小由jdbc_page_size指定;explicit:当设置分页模式为explicit时,需要我们在SQL语句中手动设置分页,使用:size表示jdbc_page_size的值,:offset会根据:size的值自动计算。当查询返回的结果集行数不等于:size的值时,查询结束。例如:jsoninput { jdbc { statement => "SELECT id, mycolumn1, mycolumn2 FROM my_table WHERE id > :sql_last_value LIMIT :size OFFSET :offset", jdbc_paging_enabled => true, jdbc_paging_mode => "explicit", jdbc_page_size => 100000 } }什么时候需要使用
explicit分页模式?在
auto分页模式下,存在性能问题;SQL 很复杂,分页不能简单使用
count来计算结果集行数;Statement不是SQL,而是调用存储过程:
jsoninput { jdbc { statement => "CALL fetch_my_data(:sql_last_value, :offset, :size)", jdbc_paging_enabled => true, jdbc_paging_mode => "explicit", jdbc_page_size => 100000 } }
使用PreparedStatement的场景
PreparedStatement = “提前准备好”的 SQL 语句 + 占位符(?) + 参数安全绑定
它的工作流程:
- 先把 SQL 语句“准备”(prepare)好,发送给数据库,例如:select * from stu where name = ?;
- 数据库会对这条 SQL 进行语法解析、语义分析、生成执行计划(这一步最耗时);
- 之后每次执行时,只需要传递不同的参数值,不需要重新解析 SQL;
- 参数通过 ? 占位符来标记,驱动程序会负责安全地把参数值绑定进去;
在MySQL命令行工具中,实现如下:
sql-- 准备PreparedStatement, select_emp_by_no为名称 PREPARE select_emp_by_no from 'select * from employees where emp_no = ?'; -- 设置参数与执行 SET @empNo = 10001; EXECUTE select_emp_by_no USING @empNo; -- 清理PreparedStatement DEALLOCATE PREPARE select_emp_by_no;在 MySQL 驱动中,PreparedStatement 有两种底层实现:
- ClientPreparedStatement(默认):客户端模拟预编译,参数替换发生在 JVM 内,实际上,发送给MySQL的语句还是完整的拼接后SQL;
- ServerPreparedStatement(推荐生产):真正把 PREPARE 发到 MySQL 服务器执行(在数据库连接串中加
useServerPrepStmts=true参数开启);
在jdbc输入插件中,也支持PreparedStatement场景,具体配置如下:
use_prepared_statements:是否使用PreparedStatement,默认值为false;prepared_statement_bind_values:绑定的参数值;prepared_statement_name:发送给数据库的PreparedStatement名称;
案例如下:
json
input {
jdbc {
statement => "SELECT * FROM mgd.seq_sequence WHERE _sequence_key > ? AND _sequence_key < ? + ? ORDER BY _sequence_key ASC"
prepared_statement_bind_values => [1, 2, 4]
prepared_statement_name => "foobar"
use_prepared_statements => true
// ...
}
}增量更新场景:增量更新是指只同步自上次运行以来新增或变更的数据。主要由以下配置实现:
record_last_run:是否记录上次运行的追踪列最大值,默认值为true,当开启后,追踪值保存在last_run_metadata_path指定的文件中;last_run_metadata_path:用于保存追踪列的值,默认值为"<path.data>/plugins/inputs/jdbc/logstash_jdbc_last_run";use_column_value:是否开启“基于某一列的值”进行增量追踪,默认值为false;tracking_column:指定追踪列;tracking_column_type:追踪列的类型,可选值为numeric,timestamp,默认值为numeric;
如果开启了record_last_run,那么可以在Statement中使用:sql_last_value来表示追踪列的值。
- 如果没有开启
use_column_value,那么追踪列默认为SQL开始执行的时间。当SQL开始执行时,会从last_run_metadata_path中获取上次的执行时间(默认为1970-01-01 00:00:00),赋值给:sql_last_value,在SQL中使用;SQL执行结束后,会将本次SQL开始执行的时间点写入last_run_metadata_path中,供下次使用; - 如果开启了
use_column_value,那么写入的值就不是SQL开始执行的时间,而是自己执行的追踪列;
下面的案例演示了基于修改时间的增量同步:
json
input {
jdbc {
statement => """
SELECT * FROM users
WHERE updated_at > :sql_last_value
AND updated_at < NOW() -- 防止未来时间
ORDER BY updated_at ASC
"""
# === 增量核心配置 ===
use_column_value => true
tracking_column => "updated_at" # 用时间戳列
tracking_column_type => "timestamp"
record_last_run => true
last_run_metadata_path => "/xxx/users_last_time.yml"
}
}时区转换问题:Elasticsearch和Logstash是用UTC时间来存储时间的,如果数据库时间不是UTC时间,那么就需要进行时区转换。
jdbc_default_timezone:设置数据库的时区,默认没有值,那么数据库时间会被当作 JVM 的默认时区(即 Logstash 进程运行所在机器的时区)来解释,除了设置该项,也可以在数据库连接串中使用serverTimezone=Asia/Shanghai设置;plugin_timezone:jdbc插件时间,可选值为utc,local,默认值为utc;
当设置以上参数时,时区转换会发生在两个地方:
- 当从数据库查询时间数据后,认为该时间是
jdbc_default_timezone时区的时间,会将其转换为UTC时区的时间; - 当SQL中使用了
:sql_last_value并且类型为时间戳时,由于存储:sql_last_value都是以UTC时间存储的,如果设置了plugin_timezone,那么会将存储的:sql_last_value转换为plugin_timezone指定的时区,再将其转换为jdbc_default_timezone指定的时区进行查询;综上所诉,plugin_timezone没鸟用!
例如,现在数据库中存在以下数据:

然后配置如下:
json
input{
jdbc {
jdbc_driver_library => "/Applications/apache-maven-3.8.8/repo/com/mysql/mysql-connector-j/9.4.0/mysql-connector-j-9.4.0.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/demo?useSSL=false&useCurlFetch=true&defaultFetchSize=1000"
jdbc_user => "root"
jdbc_password => "xxx"
statement => "SELECT * FROM stu where created_at < :sql_last_value"
jdbc_default_timezone => "Asia/Shanghai"
plugin_timezone => "utc"
# schedule => "* * * * *"
}
}
output{
stdout { }
}结果如下:
json
{
"id" => 1,
"created_at" => 2026-01-11T07:10:38.000Z,
"@timestamp" => 2026-01-11T07:49:53.823236Z,
"@version" => "1",
"name" => "zs"
}可以发现在屏幕显示时created_at被转换为UTC时间了。
并且查看/Users/xxx/projects/logstash-9.2.3/data/plugins/inputs/jdbc/logstash_jdbc_last_run路径中保存的sql_last_value的值,结果是UTC时间,如下:
txt
--- !ruby/object:DateTime '2026-01-11 07:58:24.022610000 Z'在日志中,可以看到SQL如下:
txt
[2026-01-11T15:58:24,038][INFO ][logstash.inputs.jdbc ][main][15ede8e7c160889a4fc8a17d11d96d3c88321d1484314654d4e4f04aae104c20] (0.002305s) SELECT * FROM stu where created_at < '2026-01-11 15:57:46'3.1.2 input公共配置
每个input插件都有其独特的配置,也有一些公共配置,如下:
| 配置 | 类型 | 是否必需 |
|---|---|---|
add_field | hash | No |
codec | codec | No |
enable_metric | boolean | No |
id | string | No |
tags | array | No |
type | string | No |
add_field:向事件中添加字段,例如:jsonadd_field => { "field1" => "value1" "field2" => "value2" }codec:在数据到达 input 插件之前(或从 input 插件读取出来之前),直接对原始输入数据进行解码/编码,而不需要在 pipeline 中额外加一个 filter 插件来处理。enable_metric:在 Logstash 中,input 插件默认会记录所有可用的 metrics(如 events_in, events_out, duration_in_millis 等),这些指标会通过 Logstash 的监控 API、Prometheus exporter 或 xpack monitoring 暴露出来。如果想针对某个特定 input 实例禁用 metrics 收集(例如性能敏感或减少日志噪声),可以设置enable_metrics => false;id:为input插件实例设置ID,如果没有手动设置,Logstash会自动产生一个;推荐手动设置,有利于监控和日志查找;tags:为事件添加任意数量的标签;type:为事件添加type字段;
3.2 filter插件
3.2.1 mutate
mutate用来对数据字段执行一系列操作,例如重命名、替换、更新等。
| 操作命令 | 作用描述 | 示例配置 | 常见用途 |
|---|---|---|---|
| add_field | 添加新字段 如果事件中有同名的字段,那么新添加的值和原值会成为数组 | add_field => { "env" => "prod" } | 添加标签、环境变量、组合字段 |
| remove_field | 删除字段(支持数组删除多个) | remove_field => [ "tmp_field", "debug" ] | 清理无用字段、减少存储大小 |
| rename | 重命名字段 如果目标字段名称已存在,那么目标字段旧值会被替换 | rename => { "old_name" => "new_name" } | 规范化字段名(如 src_ip → source_ip) |
| replace | 替换字段值(覆盖原有值) 如果目标字段不存在,那么会添加新字段 | replace => { "status" => "%{http_status}" } | 合并字段、格式化 |
| update | 只在字段存在时更新值(不存在不创建) | update => { "count" => "%{count} + 1" } | 安全更新,避免意外新增字段 |
| convert | 转换字段类型(string → integer/float/boolean/date 等) | convert => { "age" => "integer" "price" => "float" "active" => "boolean" } | 类型规范化(ES 映射要求) |
| gsub | 对字段进行正则替换(类似 Ruby 的 gsub) | gsub => [ "message", "[^a-zA-Z0-9]", "_" ] | 清理特殊字符、脱敏 |
| split | 把字符串按分隔符拆分成数组 | split => { "tags" => "," } | 把逗号分隔的标签拆成数组 |
| join | 把数组字段拼接成字符串 | join => { "tags" => "," } | 反向操作 split |
| lowercase / uppercase | 转小写/大写 | lowercase => [ "username" ] | 统一大小写 |
| strip | 去除字段首尾空格 | strip => [ "description" ] | 清理脏数据 |
| coerce | 设置默认值 如果一个字段存在,但是值为null,设置为默认值 | coerce => {"field1" => "default_value" } |
TIP
注意,add_field和remove_field是公共配置,不仅在mutate插件中可以使用,在其他filter插件中也可以使用。
mutate 插件内部会按配置的顺序逐个执行,但同一个 mutate 块内的操作顺序不一定严格保证(例如 add_field 和 remove_field 可能并行)。
官方推荐:如果多个操作之间有依赖关系(比如先 rename 再 convert,再 add_field),建议拆成多个独立的 mutate 块:
filter {
mutate { rename => { "old_ip" => "new_ip" } } # 第一步:重命名
mutate { convert => { "new_ip" => "string" } } # 第二步:转换类型
mutate { add_field => { "ip_type" => "ipv4" } } # 第三步:添加新字段
}这样能严格保证顺序,避免意外。
3.2.2 ruby
ruby插件用于执行ruby代码,主要有两种方式定义ruby代码:
code:直接在插件里通过code属性定义ruby代码,例如:jsonfilter { ruby { code => "具体代码" } }path:通过path属性定义ruby脚本文件,在文件中编写代码,例如:jsonfilter { ruby { # Cancel 90% of events path => "/etc/logstash/drop_percentage.rb" script_params => { "percentage" => 0.9 } } }script_params用于传递参数;在脚本文件
.rb中,需要编写以下两个方法:register(params):可选的,用于接收script_params传递的参数;filter(event):必须的,用于接收事件(event),并且返回事件数组;
例如:
ruby# 接收参数 def register(params) @drop_percentage = params["percentage"] end # 定义处理方法 def filter(event) if rand >= @drop_percentage return [event] else # 如果返回空数组,表示丢弃该事件 return [] end end
例如,下面的ruby插件用于将_分割的字段名称改为小驼峰命名:
json
filter{
mutate {
add_field => {
"my_id" => "test"
"[content][type_id]" => "example"
"[content][user_name]" => "sample_user"
}
}
ruby {
code => '
def snake_to_camel(snake)
snake.split("_").map.with_index { |w, i| i == 0 ? w : w.capitalize }.join("")
end
def deep_convert(obj)
case obj
when Hash
obj.transform_keys { |k|
(k.is_a?(String) && k =~ /_/ && !k.start_with?("@")) ? snake_to_camel(k) : k
}.transform_values { |v| deep_convert(v) }
when Array
obj.map { |v| deep_convert(v) }
else
obj
end
end
# 主逻辑
original = event.to_hash.dup
converted = deep_convert(original)
# 清空旧字段(保留 @ 开头的元数据)
original.keys.each do |k|
event.remove(k) unless k.start_with?("@")
end
# 写入新字段
converted.each do |k, v|
event.set(k, v) unless k.start_with?("@")
end
'
}
}TIP
如果要在add_field中添加嵌套对象,字段命名应为[content][type_id],而不是content.type_id
也可以在ruby中添加字段和嵌套对象:
txt
ruby {
code => '
event.set("content", {
"type_id" => "example",
"user_name" => "sample_user"
})
event.set("my_id", "test")
'
}3.2.3 jdbc_streaming
jdbc_streaming插件会执行一段SQL,并且把结果保存在事件里以target指定的字段中(以数组形式)。并且,jdbc_streaming会把结果集保存在LRU缓存中,并带有过期时间。
jdbc_streaming与jdbc input插件工作原理类似,不同的配置如下:
target:将结果集保存在哪个字段(以数组形式),该配置没有默认值,必须设置,如果没有设置,会报错!parameters:指定参数,类型为hash,在SQL中,可以使用:param_name的形式使用参数,例如:jsonjdbc_streaming { statement => "select * from demo where name = :name or id = :id" parameters => { "name" => "zs" "id" => "[id]" } }在SQL中
:name会被替换为zs,[id]表示字段中id字段值。default_hash:当 SQL 查询没有返回任何结果时,为事件提供一组默认的“保底”字段。default_hash的类型为hash, Key(键名) 必须与 SQL 语句查出来的 Column Name(列名) 完全一致。例如:jsonjdbc_streaming { statement => " select c.`name` as course, g.grade as grade from grade g left join course c on g.course_id = c.id where g.stu_id= 2 " target => "grades" default_hash => { "course" => "unknown" "grade" => 0 } }结果为:
json{ "id" => 1, "@timestamp" => 2026-01-13T13:02:30.208725Z, "tags" => [ [0] "_jdbcstreamingdefaultsused" ], "name" => "zs", "@version" => "1", "created_at" => 2026-01-11T07:10:38.000Z, "grades" => [ [0] { "course" => "unknown", "grade" => 0 } ] }use_cache:是否使用LRU缓存,默认值为true;cache_size:缓存条目数,默认值为500,当达到缓存条目数后,最近最少使用的条目会被替换;cache_expiration:缓存过期时间,默认值为5,时间单位为秒(s),也可以使用小数,例如0.25,代表250毫秒。假设某次SQL发生错误时,没有返回数据,那么会导致缓存中保存着空数据,此时会从
default_hash中获取值填充到事件中,直至缓存过期,否则之后的同样参数的SQL查询,都会使用default_hash中的默认数据。在
jdbc_streaming中,同样支持PreparedStatement,以MySQL为例,连接串设置如下:txtjdbc:mysql://localhost:3306/mydatabase?cachePrepStmts=true&prepStmtCacheSize=250&prepStmtCacheSqlLimit=2048&useServerPrepStmts=true
例如,原始事件来源于jdbc查询学生表,然后根据学生ID查询成绩:
json
filter {
jdbc_streaming {
jdbc_driver_library => "/Applications/apache-maven-3.8.8/repo/com/mysql/mysql-connector-j/9.4.0/mysql-connector-j-9.4.0.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/demo?useSSL=false&useCurlFetch=true&defaultFetchSize=1000&cachePrepStmts=true&prepStmtCacheSize=250&prepStmtCacheSqlLimit=2048&useServerPrepStmts=true"
jdbc_user => "root"
jdbc_password => "xxx"
statement => "
select c.`name` as course, g.grade as grade
from grade g
left join course c on g.course_id = c.id
where g.stu_id= ?
"
target => "grades"
use_prepared_statements => true
prepared_statement_name => "select_grades_by_stu_id"
prepared_statement_bind_values => [ "[id]" ] # [id]表示事件中的id字段
default_hash => {
"course" => "unknown"
"grade" => 0
}
}
}3.2.4 grok
grok插件用于将任意的文本按照正则表达式解析为结构化的数据。
dissect也可以将文本解析为结构化的数据,两者的区别在于:dissect没有使用正则表达式,更快。
grok基础
grok使用了Oniguruma作为正则表达式实现库,在grok中,如果要使用正则表达式匹配模式并且命名,语法如下:
txt
(?<field_name>pattern)例如,下面的正则表达式将匹配10-11位包含0-9和A-F的文本,并且命名为queue_id:
txt
(?<queue_id>[0-9A-F]{10,11})例如,如果我们的事件中包含message字段,并且内容如下:
txt
"message": "190239889A 990239889B"在grok插件中实现如下:
json
grok {
match => { "message" => "(?<queue_id>[0-9A-F]{10,11})" }
}match表示要匹配的字段及其模式,后续详解
经过解析后,事件内容如下:
json
{
"message": "190239889A 990239889B",
"queue_id": "190239889A"
}message文本中第一个匹配正则表达式[0-9A-F]{10,11}的文本被提取出来,作为queue_id字段的值。
假设
message的值为123456789ABC,那么queue_id的值为123456789AB。
除了直接在match中使用正则表达式,我们可以把正则表达式命名,单独放在模式文件中,并且在grok插件中引用。
首先,在运行bin/logstash时,终端所在的当前工作目录下创建名称为patterns的目录。
然后,在该目录下创建一个名为my_pattern的文件(文件名称不重要),内容如下:
txt
# contents of ./patterns/my_pattern:
QUEUEID [0-9A-F]{10,11}自定义正则表达式名称语法规则如下:
txt
模式名称 正则表达式之后,在grok中引用该模式,并且使用命名模式的方式匹配文本:
json
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{QUEUEID:queue_id}" }
}pattern_dir:表示自定义模式文件所在目录;.表示在运行bin/logstash时,终端所在的当前工作目录;%{QUEUEID:queue_id}:表示匹配规则,语法如下txt%{SYNTAX:SEMANTIC:DATA_TYPE}SYNTAX:正则表达式名称,可以是自己定义的(例如QUEUEID),也可以是grok内置的名称,完整列表:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/grok-patternsSEMANTIC:表示匹配的内容应该放到哪个字段,就是目标字段名称,例如queue_id;DATA_TYPE:默认情况下,grok匹配的内容保存为字符串,如果向将匹配的内容转换为其他数据类型,可以指明DATA_TYPE,现在只支持int和float数据类型;
以上就是grok的基础使用,现在讲解grok的配置:
match:用于定义要匹配的字段以及匹配模式,格式为hash,例如:txtgrok { match => { "message" => "Duration: %{NUMBER:duration} Speed: %{NUMBER:speed}" "extra" => "%{WORD:other_info}" } }也可以针对一个字段,分多次进行匹配:
txtfilter { grok { match => { "message" => [ "%{IP:client_ip} %{WORD:method}", # 模式 A "%{IP:client_ip}" # 模式 B ] } # 默认 break_on_match => true break_on_match => false } }break_on_match:默认情况下,break_on_match是开启的。 如果在match中定义了一个包含多个模式(Patterns)的数组,Logstash 会按顺序从上往下匹配。只要其中一个模式匹配成功,Logstash 就会直接跳出该grok块,不再尝试后面的模式。如果将此参数设为
false,Logstash 会尝试运行数组中的每一个模式,无论前面的有没有匹配成功。例如,需要从同一行日志中提取多组互不相关的结构:
txtfilter { grok { match => { "message" => [ "ID: %{NUMBER:id}", "User: %{WORD:user}" ]} break_on_match => false } }pattern_definitions:用于定义模式名称和正则表达式,类型为hash,使用这种方式定义的命名正则表达式只能在该grok插件中使用,例如:jsongrok { pattern_definitions => { "QUEUEID" => "[0-9A-Z]{10,11}" } match => { "message" => [ "%{QUEUEID:queue_id}", "%{QUEUEID:queue_id_2}" ] } break_on_match => false }patterns_dir:用于定义命名的正则表达式所在目录,建议使用绝对路径;target:提取后的内容字段放在哪里,没有默认值,表示直接放在事件根路径下;overwrite:表示要覆盖的字段,类型为数组,例如:txtgrok { pattern_definitions => { "QUEUEID" => "[0-9A-Z]{10,11}" } match => { "message" => [ "%{QUEUEID:message}" ] } break_on_match => false overwrite => [ "message" ] }解析完成后,原
message字段内容会被解析后的值覆盖重写。如果要覆盖嵌套对象里的字段,需要使用对象引用语法:
txtgrok { match => { "somefield" => "%{NUMBER} %{GREEDYDATA:[nested][field][test]}" } overwrite => [ "[nested][field][test]" ] }
3.3 output插件
output插件用于将事件(event)写出到指定的目的地。
3.3.1 elasticsearch
3.3.1.1 基本设置
elasticsearch插件用于将事件存入ES中,基本属性如下:
hosts:指定ES的连接地址,默认值为[//127.0.0.1],可以指定多个ES节点地址,插件将会使用负载均衡策略来发送请求;user:连接ES的用户名;password:连接ES的用户密码;index:指定写入索引名称;document_id:指定文档ID,默认会自动生成,如果想使用自己的ID,可以获取事件中的字段,例如%{[id]};action:指定对文档执行什么操作,可选值如下:index:索引文档(如果文档 ID 不存在,就新建;如果文档 ID 已经存在,就删除旧文档并存入新文档);create:新建文档(如果文档 ID 已经存在,操作会报错);update:通过文档ID更新文档;delete:通过文档ID删除文档;
doc_as_upsert:是否启用upsert,即文档ID存在就部分更新(而不是覆盖整个文档),不存在就插入,默认值为false,如果要启用upsert,应该将action设置为update;
下面的例子说明了最基本的插件使用,将事件保存到指定的索引中,并使用业务主键ID,启用upsert:
json
elasticsearch {
hosts => ["http://localhost:9200"]
user => "elastic"
password => "your_strong_password123"
index => "stu_info"
document_id => "%{id}"
action => "update"
doc_as_upsert => true
data_stream => false
manage_template => false
ilm_enabled => false
}使用以上的配置,可以发现我们禁用了索引模板管理,如果在ES中没有自定义索引模板,那么ES将使用字段自动映射,结果可能不是我们想要的。
3.3.1.2 索引模板
在elasticsearch插件中可以启用索引模板管理,自定义索引模板,相关配置如下:
manage_template:是否启用索引模板管理;template_name:索引模板名称;template:定义了索引模板内容文件所在路径;template_overwrite:是否使用Logstash的索引模板覆盖ES中同名的索引模板,默认值为false,如果启用该项配置,那么每次 Logstash 启动并建立连接时,它会无视 ES 中是否已存在该模板,直接用它自己加载的模板文件(通过template参数指定的,或者内置的)去覆盖 ES 里的旧模板。
下面是自定义索引模板的例子:
json
elasticsearch {
hosts => ["http://localhost:9200"]
user => "elastic"
password => "your_strong_password123"
index => "stu_info-01"
document_id => "%{id}"
action => "update"
doc_as_upsert => true
manage_template => true
template_name => "stu_info_template"
template => "/Users/xxx/projects/logstash-9.2.3/config/my_stu_index_template.json"
template_overwrite => true
data_stream => false
ilm_enabled => false
}json
{
"index_patterns": ["stu_info-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"queue_id": {
"type": "keyword"
},
"id": {
"type": "integer"
},
"name": {
"type": "keyword"
},
"message": {
"type": "text"
},
"created_at": {
"type": "date"
},
"@timestamp": {
"type": "date"
}
}
},
"aliases": {
"stu": {}
}
}
}可以发现在ES中,成功按照配置创建了索引模板,并且索引也成功应用了模板。
3.3.1.3 ILM
在elasticsearch插件中,也可以启用ILM管理,相关设置如下:
ilm_enabled:是否启用ILM管理;ilm_policy:ILM策略的名称,需要我们提前在ES中自定义ILM策略,然后在Logstash中引用;ilm_pattern:ILM管理的索引名称模式,默认值为{now/d}-000001,模式必须以数字结尾;ilm_rollover_alias:用于ILM管理的别名,当指定了ilm_rollover_alias,那么index的值将被忽略,最终,生成的索引名称为ilm_rollover_alias+-+ilm_pattern`;
例如,假设在ES中已经有名为my-filebeat-test-ilm-policy的ILM策略(当索引文档数超过2时,会发生Rollover),配置如下:
json
elasticsearch {
hosts => ["http://localhost:9200"]
user => "elastic"
password => "your_strong_password123"
index => "stu_info-01"
document_id => "%{id}"
action => "update"
doc_as_upsert => true
manage_template => true
template_name => "stu_info_template"
template => "/Users/xxx/projects/logstash-9.2.3/pipelines/my_stu_index_template.json"
template_overwrite => true
ilm_enabled => true
ilm_policy => "my-filebeat-test-ilm-policy"
ilm_rollover_alias => "stu_info_ilm"
ilm_pattern => "000001"
data_stream => false
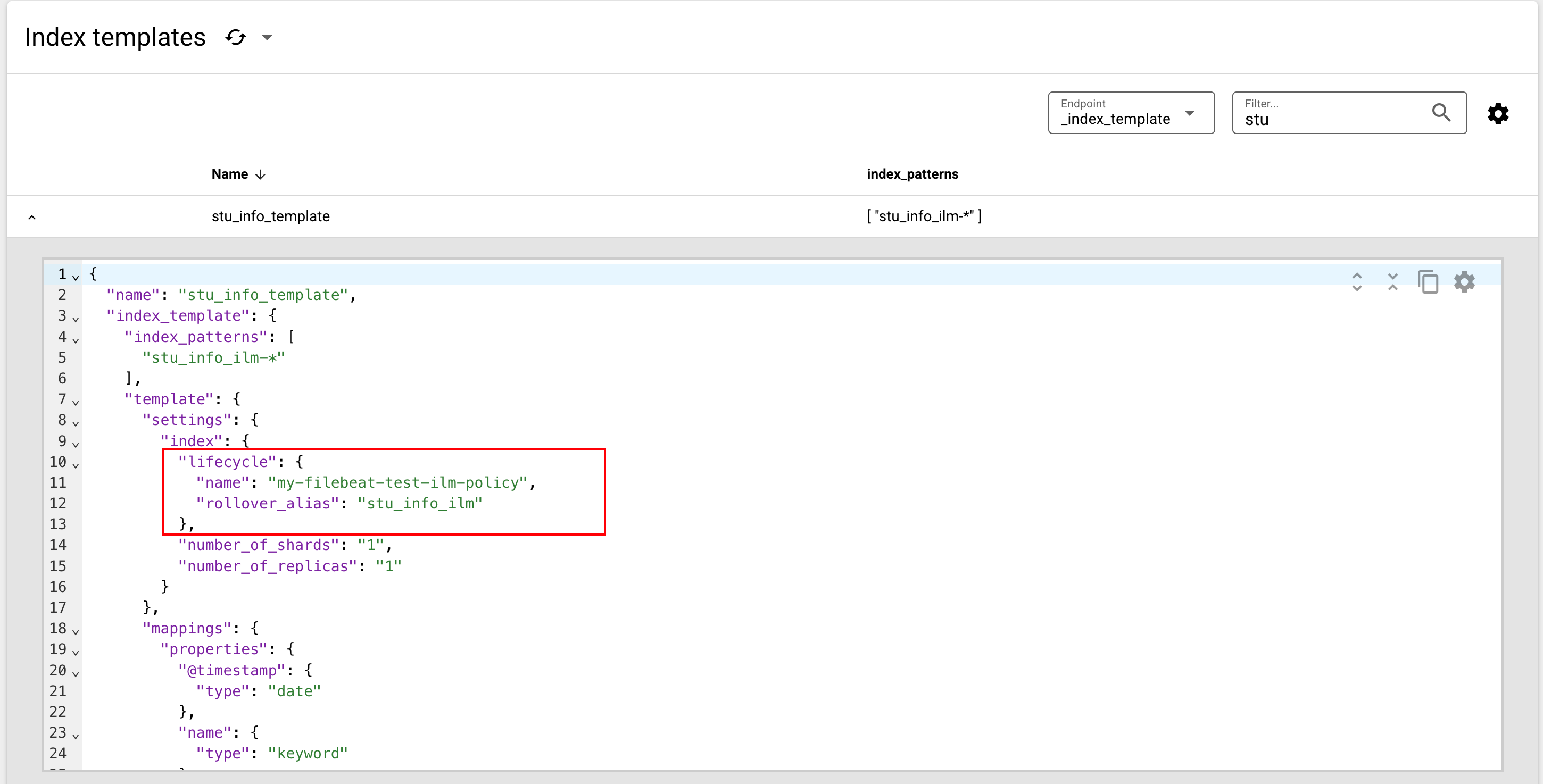
}会发现索引模板stu_info_template的配置中添加了ILM相关配置:
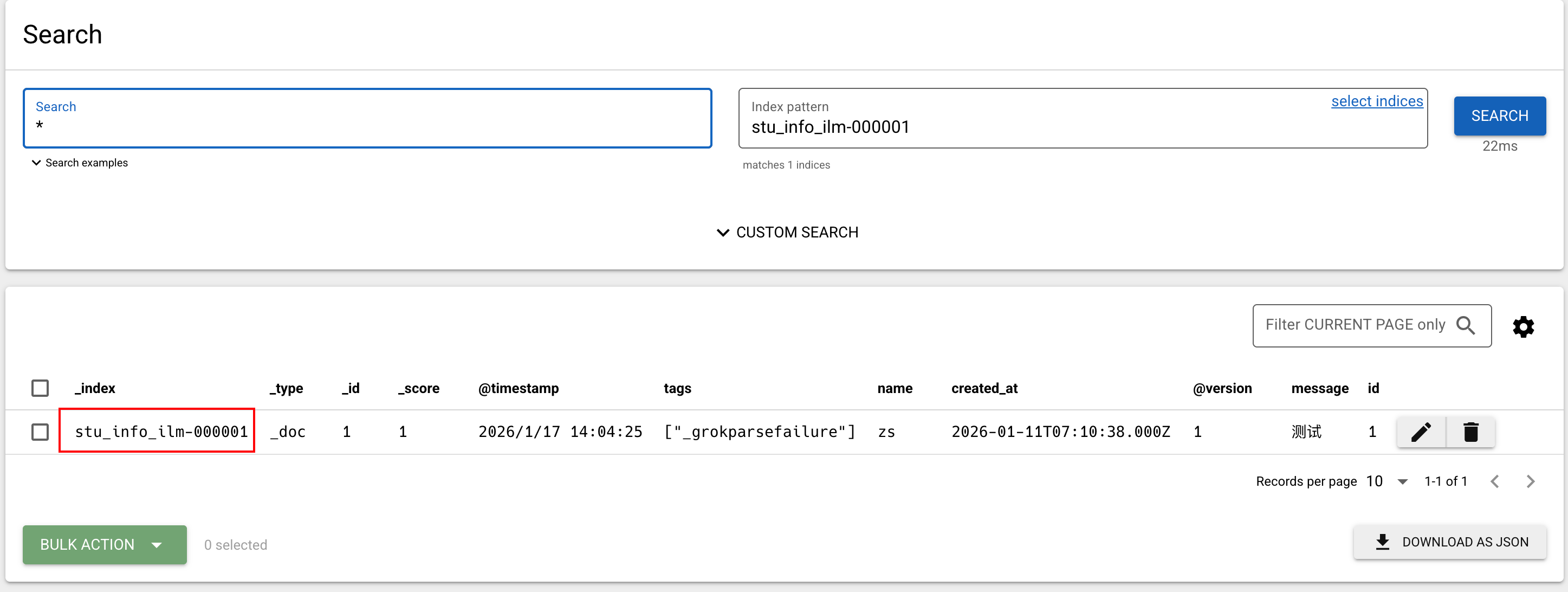
并且生成了stu_info_ilm-000001的索引:
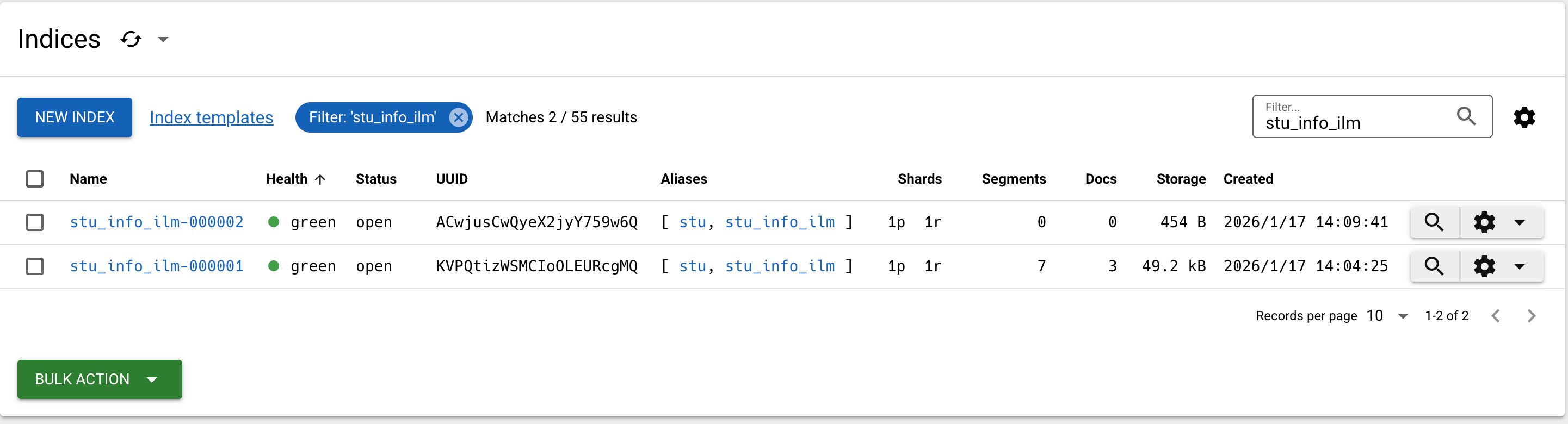
向索引中写入更多数据,会发现ILM正常发挥作用:
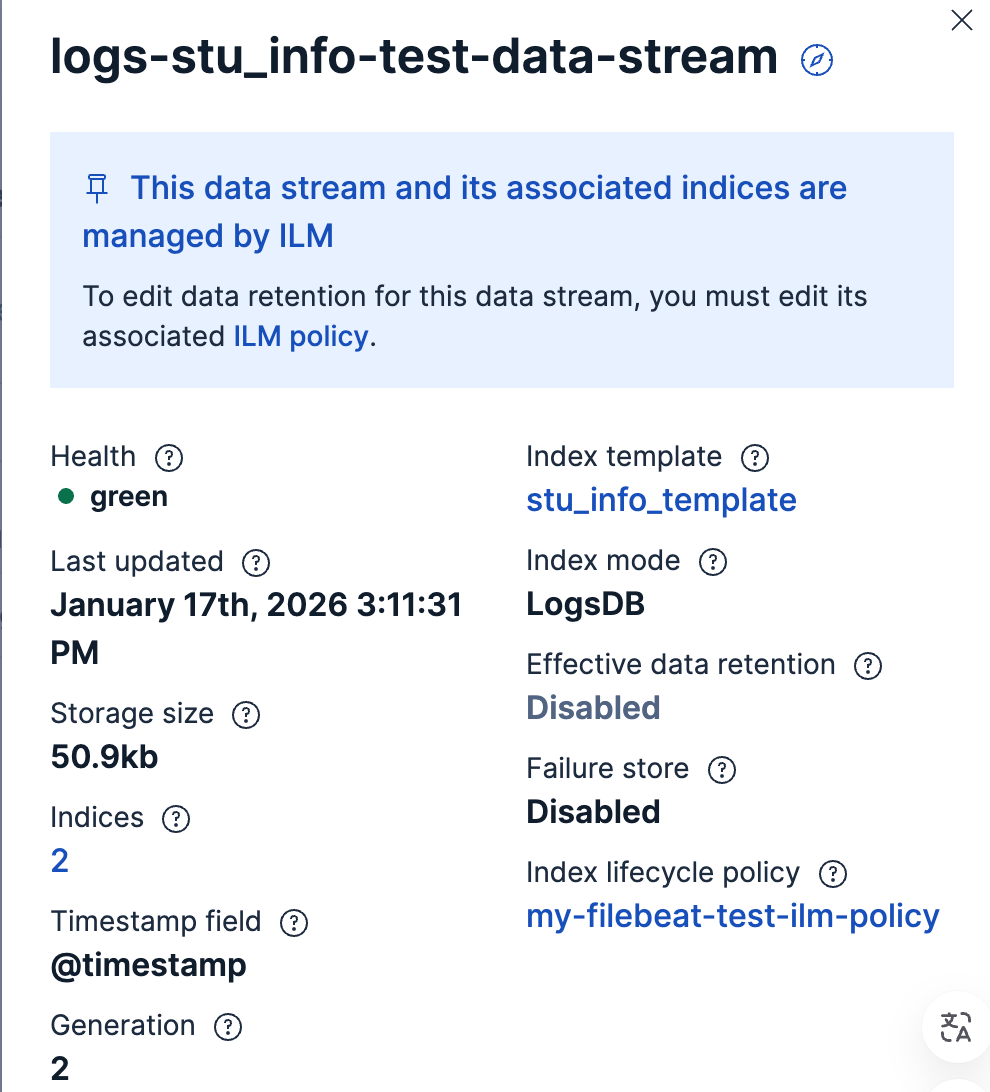
3.3.1.4 Data Stream
在elasticsearch插件中也可以使用Data Stream,主要配置如下:
data_stream:是否启用Data Stream,如果设置为true,那么必须启用ecs_compatibility;ecs_compatibility:是否启用ECS,可选值为disabled、v1和v8;data_stream_type:数据流类型,可选值为logs(日志)、metrics(指标)、synthetics(探测)或traces(追踪),默认值为logs;data_stream_dataset:数据集,默认值为generic;data_stream_namespace:命名空间,默认值为default;IMPORTANT
最终数据流的名称会由
data_stream_type+data_stream_dataset+data_stream_namespace构成;data_stream_auto_routing:是否通过事件中指定的字段来将事件路由到相应的数据流中,即会根据事件中字段%{[data_stream][type]}-%{[data_stream][dataset]}-%{[data_stream][namespace]}的值,来生成数据流名称,如果事件中缺少相关字段,将会使用对应的配置:data_stream_type,data_stream_dataset和data_stream_namespace;默认值为true;data_stream_sync_fields:如果事件中缺少相关字段(%{[data_stream][type]}-%{[data_stream][dataset]}-%{[data_stream][namespace]}),是否自动添加,默认值为true;
TIP
如果要启用Data Stream,需要在索引模板中启用Data Stream,并且匹配的模式需要满足数据流名称。
并且,需要在ES侧管理索引模板,在Logstash中不能再管理索引模板。
在索引模板中引用ILM策略名称。
索引模板不能再加别名。
索引模板调整如下:
json
{
"name": "stu_info_template",
"index_template": {
"index_patterns": [
"logs-stu_info-test-*"
],
"template": {
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "1",
"index.lifecycle.name": "my-filebeat-test-ilm-policy"
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"name": {
"type": "keyword"
},
"created_at": {
"type": "date"
},
"id": {
"type": "integer"
},
"message": {
"type": "text"
},
"queue_id": {
"type": "keyword"
}
}
}
},
"composed_of": [],
"priority": 500,
"data_stream": {
"hidden": false,
"allow_custom_routing": false
}
}
}TIP
如果启用了Data Stream,那么需要把action设置为create,并且不能有ILM和索引模板的配置:
json
elasticsearch {
hosts => ["http://localhost:9200"]
user => "elastic"
password => "your_strong_password123"
document_id => "%{id}"
action => "create"
data_stream => true
ecs_compatibility => "v8"
data_stream_type => "logs"
data_stream_dataset => "stu_info"
data_stream_namespace => "test-data-stream"
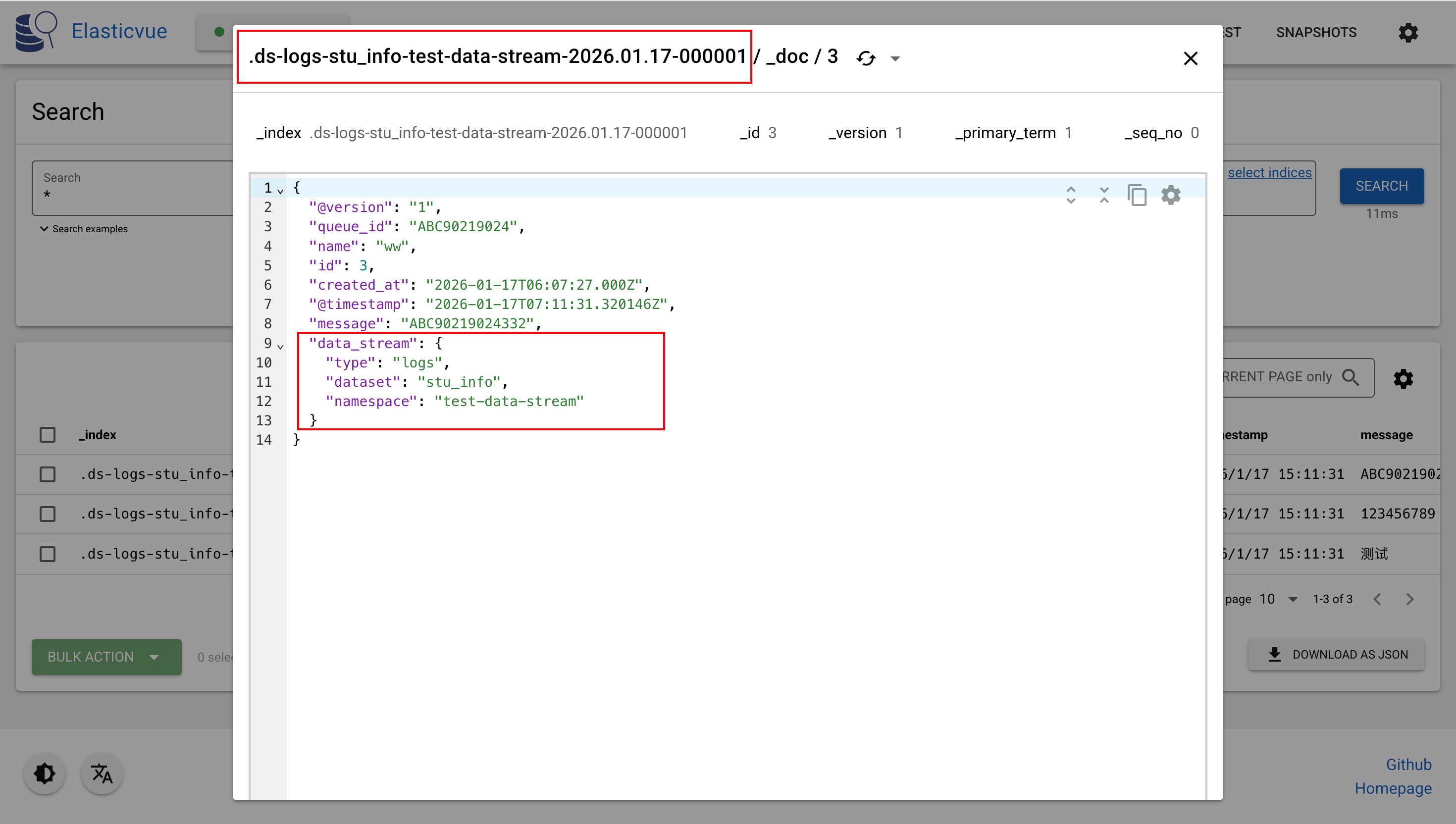
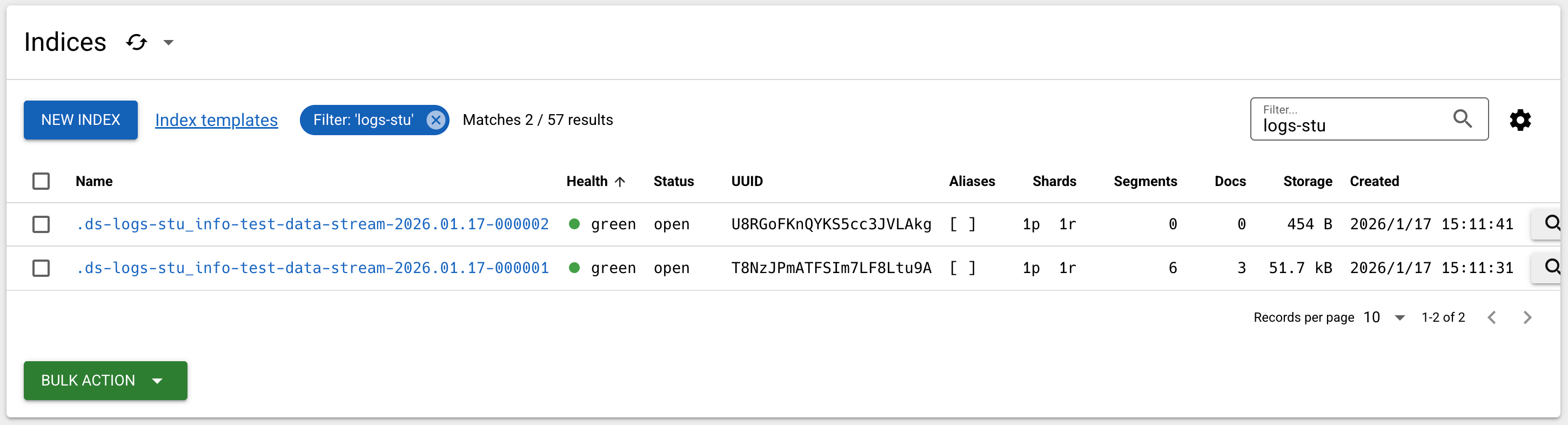
}结果如下:
3.3.1.5 其他设置
除了以上的应用场景,elasticsearch还有一些其他设置。
HTTP压缩:
compression_level:发送给ES的HTTP压缩等级,默认值为1,可选值为0-9的整数,值越大表示压缩率越高,但CPU耗时也更高,值为0表示禁用压缩;
重试与死信队列:
elasticsearch插件使用bulk API 来导入数据,当整个 bulk 请求因为网络问题或HTTP 状态码不是 200 时(例如 502、503、504、429、413 等),插件会无限重试(indefinitely retry)。没有最大重试次数限制,这是为了尽量保证数据不丢失。重试间隔采用指数退避 + 封顶策略:
- 从
retry_initial_interval开始(默认 2 秒),可修改; - 每次失败后等待时间翻倍;
- 最高等待时间不超过
retry_max_interval(默认 64 秒),可修改;
对于单条文档级别(Bulk Response 中的每条 item)的重试 / 处理策略,会根据返回码不同,采取不同的处理方式:
| Elasticsearch 返回的 item 状态码 | 当前处理方式(8.x 主流版本) | 是否可配置 | 备注 |
|---|---|---|---|
| 网络异常、超时 | 放入重试队列 → 指数退避重试 | 是(retry_initial_interval 等) | 通常会无限重试 |
| 429 (Too Many Requests) | 放入重试队列 → 指数退避重试 | — | 集群过载最常见场景 |
| 503 | 放入重试队列 → 指数退避重试 | — | 集群临时不可用 |
| 409 (Version Conflict) | 直接丢弃 + 打印 warning | 可通过 retry_on_conflict 加大 ES 端重试次数 | 插件不再负责重试 409,推荐在 ES 端重试(性能更好) |
| 400 (Bad Request) | 送入 Dead Letter Queue(如果开启) | 可通过 dlq_custom_codes 扩展 | 通常是 mapping 冲突、非法字段等不可恢复错误 |
| 404 (Not Found) | 送入 Dead Letter Queue(如果开启) | 可通过 dlq_custom_codes 扩展 | 常见于 update/delete 操作目标文档不存在 |
| 其他非预期错误(如 500) | 大多数情况下 → 无限重试整个 bulk | — | 除非明确配置进 DLQ |
为了确保消息不丢失,可以配置死信队列(Dead Letter Queue,DLQ),指定哪些状态码的事件需要放入死信队列,配置如下:
txt
dlq_custom_codes => [400, 404, 409, 413]4. 高级设置
本小节介绍有关Logstash的相关概念与配置。
4.1 keystore
在之前的配置文件中,MySQL、ES的用户密码是直接明文写在文件中的,显然这是不安全的,因此,Logstash提供了keystore来存储敏感信息,即以键值对的形式存储敏感信息(敏感信息会加密存储在keystore中),然后在配置文件中通过键的方式获取值,这样就避免了敏感信息的泄露。
为了使用keystore,首先需要创建,在bin目录下有logstash-keystore的脚本,使用如下命令创建keystore:
bash
bin/logstash-keystore create允许keystore无密码保护,之后就成功创建了,会提示在以下路径成功创建了keystore:
txt
Created Logstash keystore at /Users/xxx/projects/logstash-9.2.3/config/logstash.keystore之后,我们就可以向keystore中添加键值对了,语法如下:
bash
bin/logstash-keystore add MYSQL_PWD ES_PWD运行上述命令后,会依次提示输入对应键的值。
之后,在配置文件中,就可以使用如下语法访问对应键的敏感信息了:
txt
${KEY}例如:
json
input{
jdbc {
// ...
jdbc_password => "${MYSQL_PWD}"
}
}如果要查看keystore中的所有键,使用如下命令:
bash
bin/logstash-keystore list如果要删除keystore中的对应键值对,使用如下命令:
bash
bin/logstash-keystore remove ES_PWD4.2 访问事件字段
在Logstash管道中,通常包含三个阶段:输入(input)阶段产生事件,过滤(filter)阶段修改事件,输出(output)阶段传送事件。
在过滤和输出阶段,我们会有访问事件字段的需求,Logstash也提供了相应的方法来访问对应的字段,基本语法为:
txt
[fieldname]如果访问的是根部字段,可以省略外面的中括号,但是不建议。
如果访问嵌套字段,那么可以使用如下方法:
txt
[fieldname][sub_fieldname]例如,假设现在有如下事件:
json
{
"agent": "Mozilla/5.0 (compatible; MSIE 9.0)",
"ip": "192.168.24.44",
"request": "/index.html",
"response": {
"status": 200,
"bytes": 52353
},
"ua": {
"os": "Windows 7"
}
}要想访问ua.os字段,使用[ua][os]语法,要想访问ip字段,使用[ip]语法(虽然也可以直接使用ip,但是不推荐)。
sprintf 格式
在 Logstash 中,sprintf 格式是一种非常有用的语法,它的核心作用是:把字段的内容提取出来,并插入到另一个字符串中。
其基本语法格式是:
txt
%{[field_name]}基于上面的事件,可以使用%{[response][status]}方式获取到值:200。
sprintf格式强大之处在于可以使用java时间格式的方式访问当前时间,语法如下:
txt
%{{yyyy-MM-dd HH:mm:ss}}上述语法会输出当前日期:2026-01-17。
也可以使用如下特殊值,来输出当前时间:
txt
%{{TIME_NOW}}sprintf还支持废弃的joda时间格式,语法如下:
txt
%{+FORMAT}例如,在filter阶段添加以下字段:
json
mutate {
add_field => {
# java 格式
"now1" => "%{{yyyy-MM-dd HH:mm:ss}}"
# 特殊值 TIME_NOW
"now2" => "%{{TIME_NOW}}"
# joda 格式
"now3" => "%{+YYYY-MM-dd HH:mm:ss}"
}
}输出如下:
json
{
"now3" => "2026-01-17 12:52:00",
"now2" => "2026-01-17T12:52:00.689616Z",
"now1" => "2026-01-17 12:52:00"
}4.3 条件逻辑
在有些时候,需要根据不同条件执行不同的动作,例如,当事件中的日志等级为debug时,需要丢弃该事件。
Logstash也提供的条件逻辑,语法如下:
ruby
if EXPRESSION {
...
} else if EXPRESSION {
...
} else {
...
}EXPRESSION是布尔表达式,返回true或false,可以使用的操作符如下:
比较运算符:
==,!=,<,>,<=,>=正则表达式:
=~,!~包含运算符:
in,not in逻辑运算符:
and,or,nand,xor,!
例如,当日志等级为debug时,丢弃该事件:
json
filter {
if [loglevel] == "debug" {
drop { }
}
}在以下情况中,if [foo]返回false:
[foo]不存在事件中;[foo]存在,但是值为null或false;
@metadata字段
@metadata是一个特殊的字段,并不会出现在最终的事件中,因此,我们可以将其作为一个临时存放数据的地方,而不用清除字段:
json
input { stdin { } }
filter {
grok { match => [ "message", "%{HTTPDATE:[@metadata][timestamp]}" ] }
date { match => [ "[@metadata][timestamp]", "dd/MMM/yyyy:HH:mm:ss Z" ] }
}
output {
stdout { codec => rubydebug }
}4.4 多管道配置
假设现在我们需要读取程序日志以及从MySQL同步数据到ES,如果按照现有的知识,有以下两种方案:
- 开启两个Logstash实例,一个读取程序日志,一个同步MySQL数据;
- 开启一个Logstash实例,在一个管道文件中写入多个输入源,并且在过滤和输出阶段使用条件逻辑,执行不同的动作;
以上两种方案都有缺点,Logstash提供了第三种方案:多管道配置。
编写多个管道文件(例如,一个管道用于读取程序日志,一个管道用于同步MySQL数据),然后,在pipelines.yml中配置管道,格式如下:
yaml
- pipeline.id: my-pipeline_1
path.config: "/etc/path/to/p1.config"
pipeline.workers: 3
- pipeline.id: my-other-pipeline
path.config: "/etc/different/path/p2.cfg"
queue.type: persistedpipeline.id:管道ID,需唯一;path.config:管道配置文件地址;pipeline.workers:用于该管道的处理线程数;queue.type:用于该管道的队列类型;
上面两个配置是可选的,如果没有配置,则会使用logstash.yml中的配置。
当启动Logstash实例(没有参数)时,会从pipelines.yml中读取管道配置,并且启动所有管道。
如果启动Logstash实例时有参数(-e或-f),那么Logstash会忽略
pipelines.yml文件
TIP
当使用多管道时,需要注意,Logstash 默认会为每个管道分配等同于 CPU 核心数 的 Worker 线程。
如果有 8 核 CPU,开了 4 个管道,如果不手动限制,Logstash 会尝试启动 4×8=32 个线程。这会导致 CPU 频繁进行上下文切换,性能反而下降。因此,需要在 pipelines.yml 中手动指定每个管道的 pipeline.workers。
4.5 队列与数据持久化
当输入(input)插件获取事件后,会把事件发送到队列中,供worker获取进行后续的过滤和输出。Logstash提供两种队列:内存队列和持久化队列。
4.5.1 内存队列
默认情况下,Logstash使用内存有限队列在输入和过滤阶段之间缓存事件。
内存队列优点在于易于配置、管理,更高的吞吐量。
但是,内存队列具有容易丢失数据的缺点,以及难以应对数据爆发增长。
内存队列的大小由两个参数决定:
pipeline.batch.size:输入插件一次性发送到队列的事件数量,默认值为125;pipelines.workers:用于从队列中获取事件进行过滤、输出处理的worker线程数,默认值为主机CPU核心数;
内存队列的大小是以上两个参数的乘积。
4.5.2 持久化队列
由于内存队列具有容易丢失数据的缺点,Logstash提供了持久化队列(Persistent Queue,简称PQ),会把事件保存到磁盘空间中。
默认情况下,持久化队列是关闭状态的,如果要启用持久化队列,在logstash.yml中配置如下:
yaml
queue.type: persisted
# 默认值为内存队列
# queue.type: memory如果是想针对单个管道配置持久化队列,在pipelines.yml中配置。
当启用后,会在path.queue配置中指定的目录下创建持久化队列相关的文件,默认值为path.data/queue。
持久化队列的工作流程如下:
- 入队 (Ingest):输入插件接收到数据,立即将其写入磁盘上的“头页”(Head Page)。
- 落盘同步 (Fsync):根据配置(如
queue.checkpoint.writes),Logstash 强制将数据刷入物理磁盘。此时,即便掉电,数据也已安全。 - 处理 (Processing):Filter 和 Output 线程从磁盘读取数据进行加工。此时磁盘上的数据并不会立即删除。
- 确认与清理 (ACK & Checkpoint):只有当 Output 确认数据已成功发送(如 ES 返回 200),Logstash 才会标记该数据为“已处理”。当一个页面文件内的所有数据都被确认后,该页面文件才会被删除。
持久化队列在磁盘上由三类文件组成:
数据页 (Page Files): 实际存储数据的地方。文件名类似
page.1,page.2。每个文件大小固定(默认 64MB)。数据页分为两种:头页(Head Page)和尾页(Tail Page)。
头页是当前唯一活跃的可写文件,所有新进来的事件都会按顺序排在文件末尾(Append Only)。
当头页达到
queue.page_capacity(默认 64MB)时,它就会被“封存”,身份转变为尾页(此时会创建新的头页)。一旦变成尾页,里面的内容就再也不会被修改。Filter 和 Output 线程会从最早的尾页开始读取数据。只有当一个尾页里所有的事件都被 Output 确认(ACK)后,这个文件才会被整体删除。检查点文件 (Checkpoint Files): 这是持久化队列的灵魂。它记录了:
- 哪些数据已经写入了。
- 哪些数据已经被 Output 确认处理完了。
- 当前的读写位置在哪里。
锁文件 (.lock): 确保只有一个 Logstash 实例能操作这个队列目录。
根据以上关于持久化队列的原理,现在理解相关配置就变得容易了(注意,以下配置是针对单个管道的):
queue.page_capacity:页大小,默认值为64MB;queue.max_bytes:队列的总大小限制,默认值为1GB;queue.checkpoint.writes:当写入多少事件后,调用一次fsnyc进行落盘同步,默认值为1024,即写入1024个事件后,调用fsync,这些事件才会真正保存到磁盘中,此时就算突然断电也不会丢失数据。换句话说,如果此时写了500个事件,如果突然发生断电,那么这500个事件没有落盘,仍然会丢失。如果要确保每个事件都不会丢失,设置queue.checkpoint.writes: 1;queue.checkpoint.acks:当输出端完成输出后,会向队列发送确认(ACK)信号,队列在接收到多少个确认信号后,才会更新检查点文件(checkpoint),以更新哪些事件被处理了。默认值为1024。如果队列接收到了500个事件的确认信号,此时突然断电,由于这500个事件的确认信号还没有被写入检查点文件,Logstash重启后,worker线程仍然会读取这500个事件进行过滤、输出处理,所以,有可能会造成事件的重复发送,需要输出端进行去重。如果要保证没有事件被重复发送,设置queue.checkpoint.acks: 1;
所以,持久化队列仍然有一些限制:
- 如果突然发生断电,那么没有被checkpoint的数据仍然会丢失或重复发送;
- 如果数据发送端不遵循请求-响应(request-response)模式,那么无法使用持久化队列。因为发送端发完就认为成功(无 ACK 机制),Logstash 即使收到但崩溃前未处理完,发送端不会重发;
4.5.3 死信队列
默认情况下,如果一个事件由于映射错误(Mapping Error)、条件逻辑错误等问题,导致这些事件处理失败,无法发送到输出端,Logstash会把这些事件丢弃,如果发生这种情况,仍然有丢失数据的问题。
Logstash提供了死信队列机制,用于处理这种情况。
死信队列目前只适用于elasticsearch 输出插件以及条件逻辑错误(if ... else if ... else中的比较错误,例如将字符串与数字进行比较)。
死信队列工作图如下:
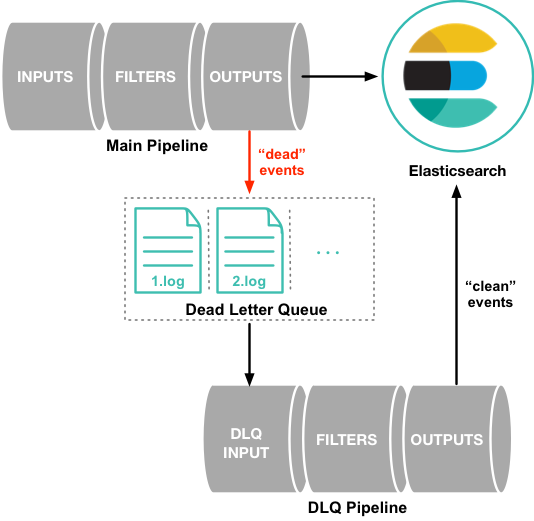
当出现上述问题时,Logstash会发送一条死信消息到死信队列,该死信消息包括以下内容:
- 原始事件;
- 描述死信产生原因的元数据;
- 插件信息;
- 消息进入死信队列的时间戳;
在Logstash中也提供了dead_letter_queue输入插件,用于读取死信队列中的事件,参考:https://www.elastic.co/docs/reference/logstash/dead-letter-queues#processing-dlq-events
默认情况下,死信队列处于关闭状态,如果要启用,在logstash.yml配置文件中使用如下配置:
yaml
dead_letter_queue.enable: true默认情况下,死信队列相关文件会保存在path.data/dead_letter_queue目录,并且按管道分组,如果要修改该目录,使用如下配置:
yaml
path.dead_letter_queue: "path/to/data/dead_letter_queue"