Appearance
Elasticsearch 入门
本文介绍如何Elasticsearch(以下简称ES)的基础概念,以及对索引、文档的增删改查操作。
1. 概念介绍
在ES中,索引(Index)是存储的基本单位,索引(Index)是由文档(Document)组成的。
索引(Index)由名称唯一标识。
索引(Index)由以下三大部分组成:
文档 Document
在ES中,数据存储在文档(Document)中,文档格式为JSON,以下就是文档的示例:
json{ "_index": "my-first-elasticsearch-index", "_id": "DyFpo5EBxE8fzbb95DOa", "_version": 1, "_seq_no": 0, "_primary_term": 1, "found": true, "_source": { "email": "john@smith.com", "first_name": "John", "last_name": "Smith", "info": { "bio": "Eco-warrior and defender of the weak", "age": 25, "interests": [ "dolphins", "whales" ] }, "join_date": "2024/05/01" } }在文档中,有以下字段需要关注:
_index:索引(Index)的名称,标识该文档属于哪个索引;_id:文档(Document)的ID,在索引中唯一标识该文档,该ID可以手动指定或由ES自动创建;_version:文档的版本号,用于乐观锁;_source:源数据,即我们创建文档时传入的数据;
元数据字段 Metadata fields
文档包含数据和元数据,元数据字段是存储关于文档信息的系统字段。在ES中,元数据字段由下划线
_作为前缀,例如:_index:索引(Index)的名称;_id:文档ID;
映射 Mappings
每个索引都有一个 映射(mapping),或者说是模式(schema),用来定义文档中的字段应该如何被索引。这个映射决定了每个字段的 数据类型,如何对该字段进行索引,以及如何存储它。
2. 环境搭建
本小节介绍如何在Docker环境下启动ES和Kibana。
什么是kibana?
简单来说,Kibana 就是 Elasticsearch 的用户界面。如果没有 Kibana,Elasticsearch 就像一个强大的数据库,但缺少一个方便、直观的窗口来查看和理解里面的内容。Kibana 弥补了这一点,能够以图形化的方式,从数据中发现价值。
首先创建网络:
bash
docker network create es-network然后启动ES,注意以单节点模式启动:
bash
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name=es --net es-network -d elasticsearch:7.17.28然后启动Kibana:
bash
docker run -d --name kibana --net es-network -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://es:9200" kibana:7.17.28-e "ELASTICSEARCH_HOSTS=http://es:9200":指定ES的地址,由于kibana和ES是在同一个网络下,所以可以直接使用容器名作为主机地址;
当启动成功后,在浏览器中输入http://localhost:5601,访问kibana主页:
3. API说明
ES提供了RESTful 风格的API来操作,并且支持幂等性,先查看附录1中有关幂等性的介绍。
在kibana中,提供了图形化的界面来发起API调用,在菜单中找到Management,然后打开Dev Tools:
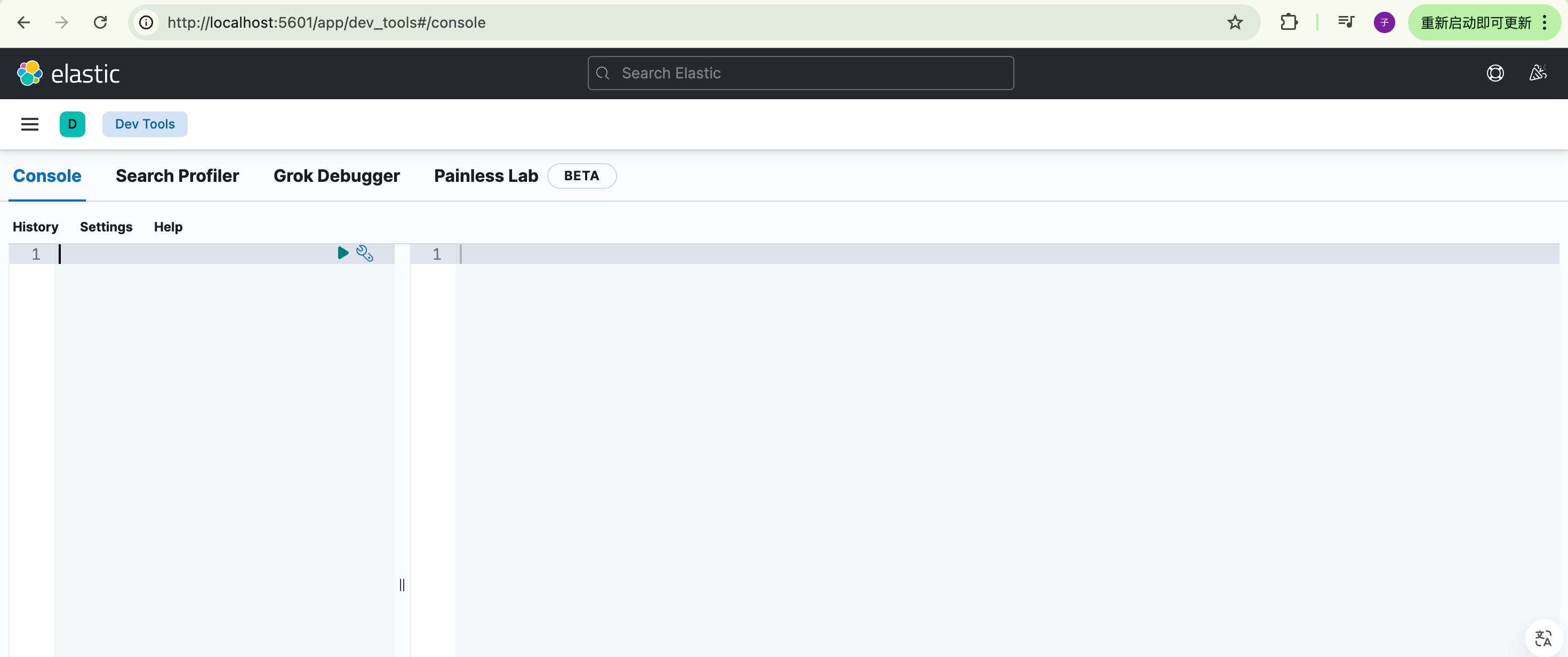
左边是API调用面板,右边是结果。
4. 索引操作
本小节介绍有关索引(Index)的增删改查操作。
4.1 创建索引
可以使用以下接口创建索引:
txt
PUT /{index}{index}表示索引名称;- 在请求体中,可以指定索引别名、索引设置和映射,此处不涉及;
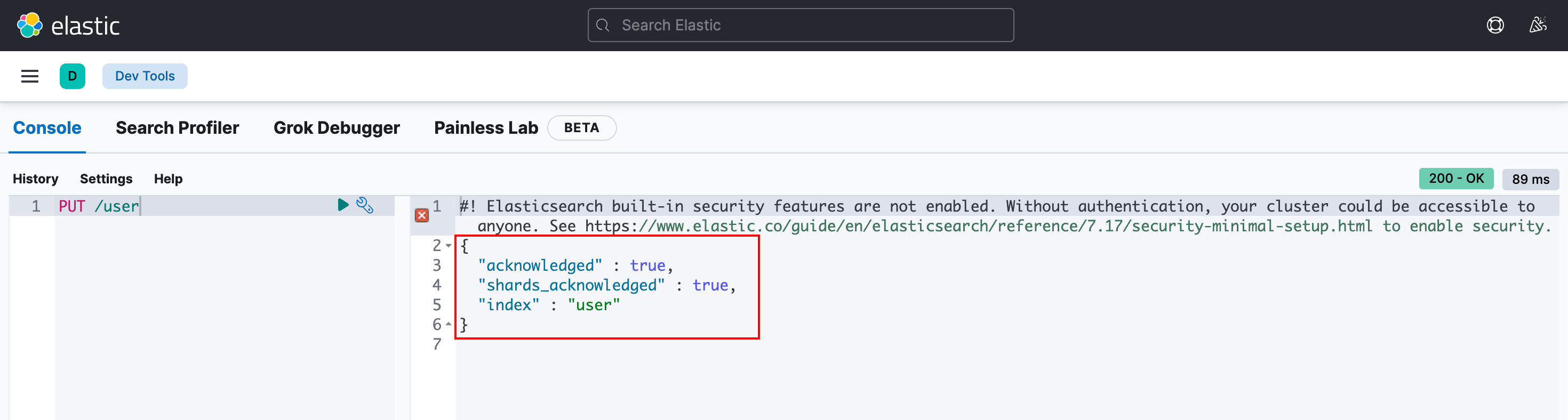
例如,在kibana中创建一个user索引:
4.2 查看索引
可以使用以下接口查看索引信息:
txt
GET /{index}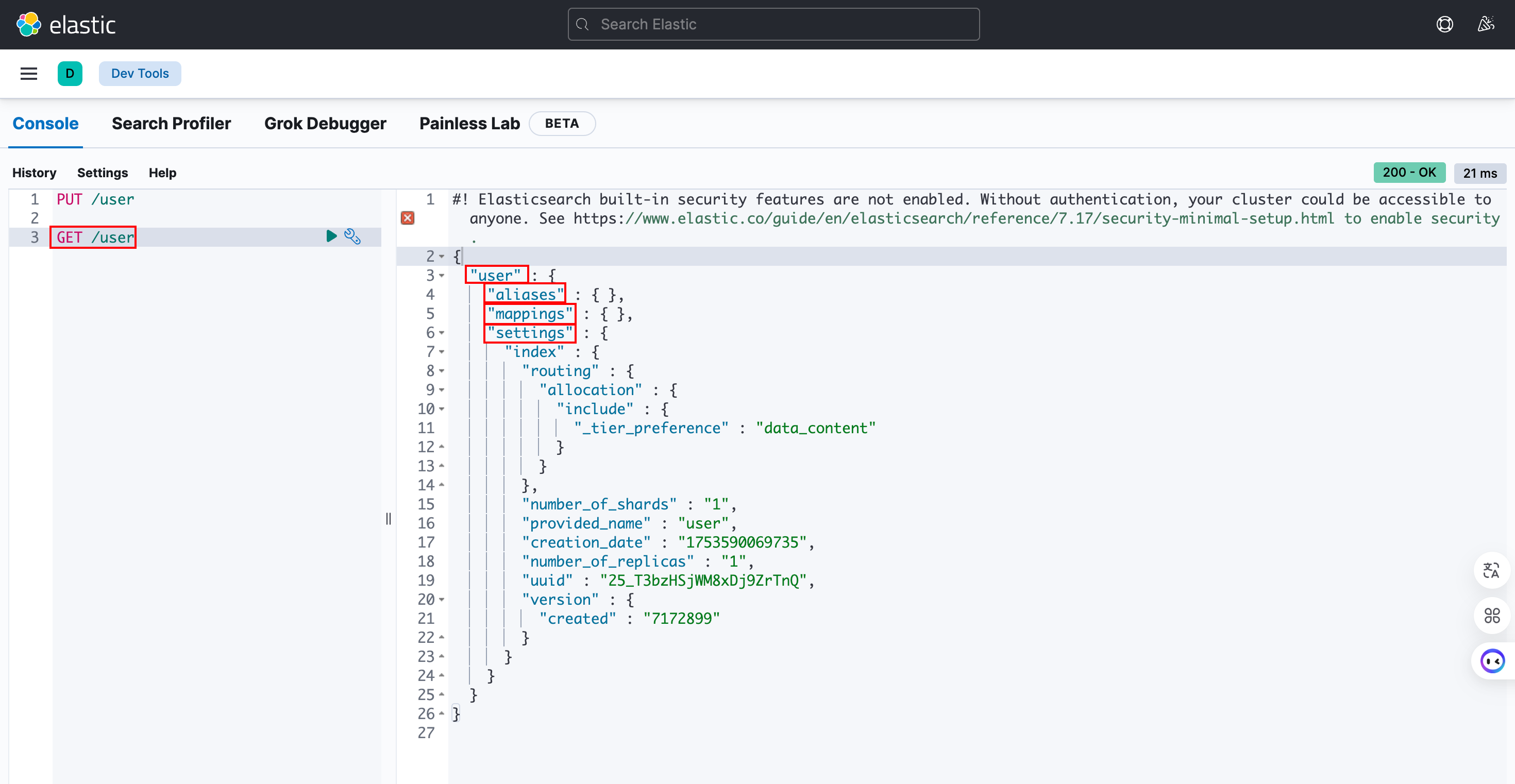
可以看到,结果以三部分返回:索引别名、映射和设置,这与创建索引时的请求体参数互相对应。
4.3 删除索引
可以使用以下方式删除索引:
txt
DELETE /{index}删除索引会删除索引中的文档、元数据和分片。

5. 文档操作
本小节介绍有关文档的增删改查操作。
5.1 创建文档
有两组方式可以创建文档。
5.1.1 _create
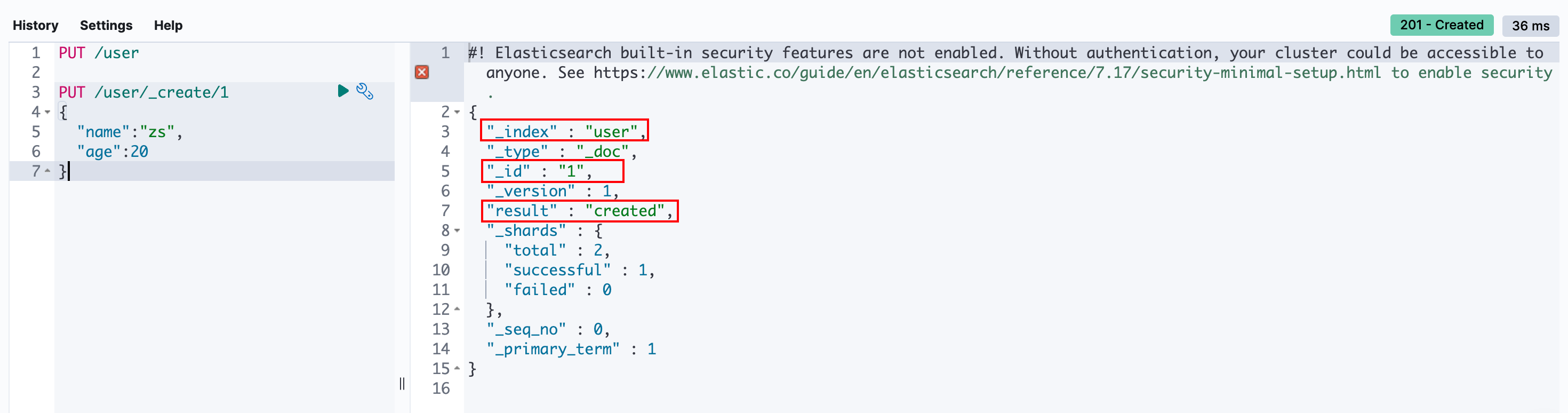
可以使用以下方式创建文档:
txt
PUT /{index}/_create/{id}
{数据}
POST /{index}/_create/{id}
{数据}{index}:表示索引名称;{id}:表示文档ID,需手动指定;- 该路径支持POST和PUT方法;
- 在请求体中携带源数据;
例如:
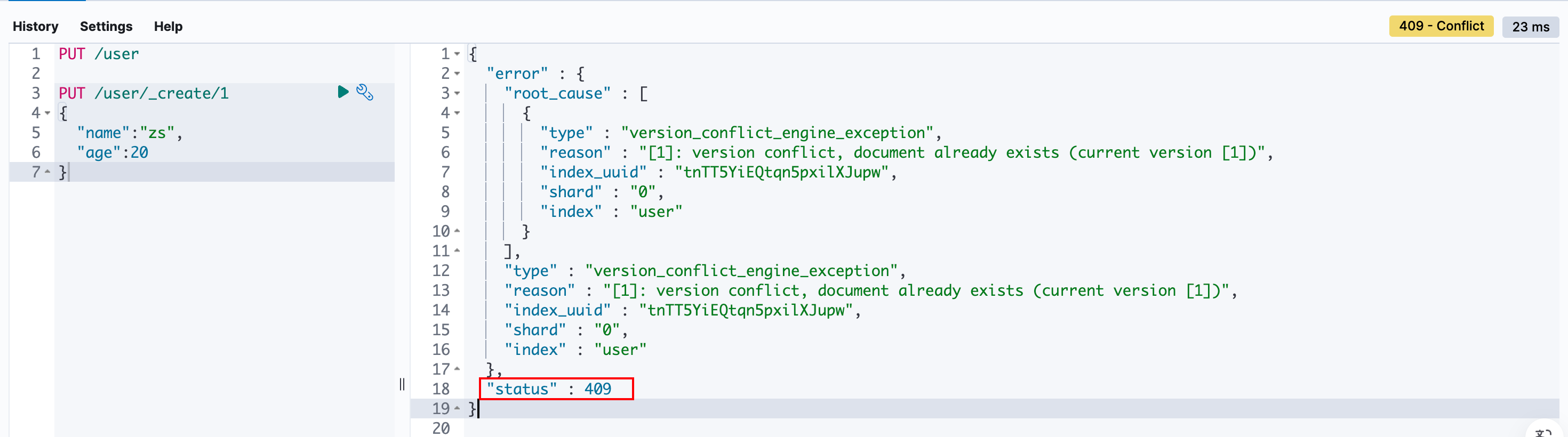
如果创建文档时,相同ID的文档已存在索引中,将会返回409错误:
5.1.2 _doc
使用_doc方式创建文档的接口如下:
txt
POST /{index}/_doc
PUT /{index}/_doc/{id}
POST /{index}/_doc/{id}POST /{index}/_doc:使用这种方式创建的文档,ID由ES自动创建: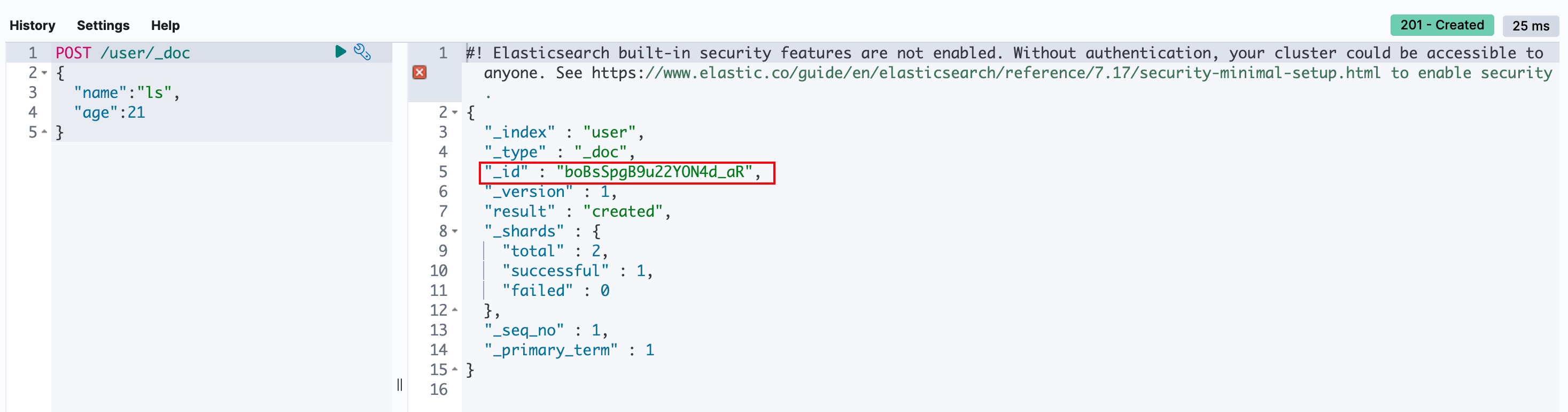
注意:使用这种方式创建文档,是非幂等性的。
PUT /{index}/_doc/{id}和POST /{index}/_doc/{id}:使用这两种方式创建文档,和使用_create方式创建文档类似,不同之处在于,使用这种方式创建文档时,如果相同ID的文档已存在索引中,不会报错,而且会全量覆盖。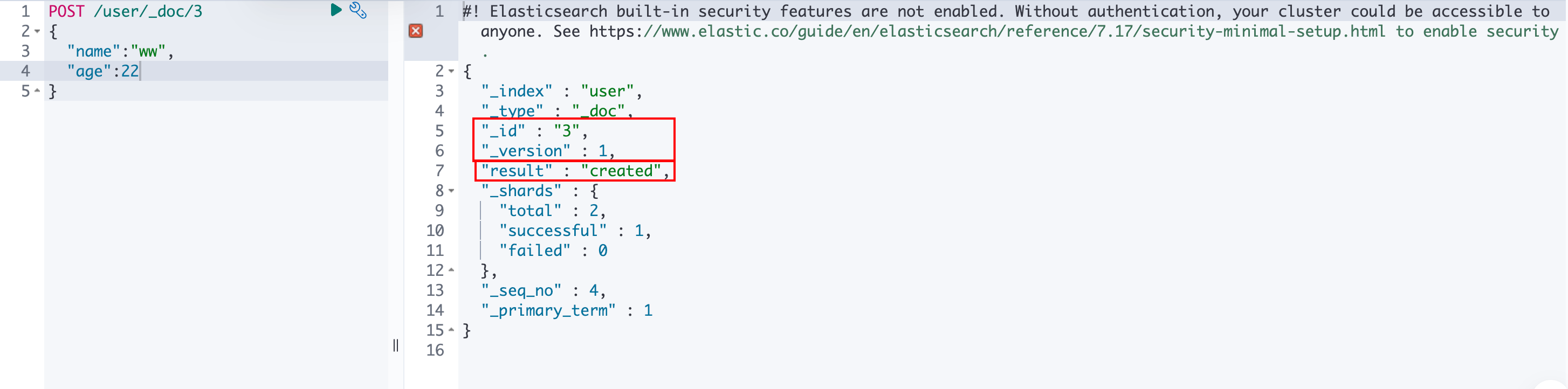
第二次创建相同ID的文档,可以看到
result为updated,而且_version为2,表示更新了: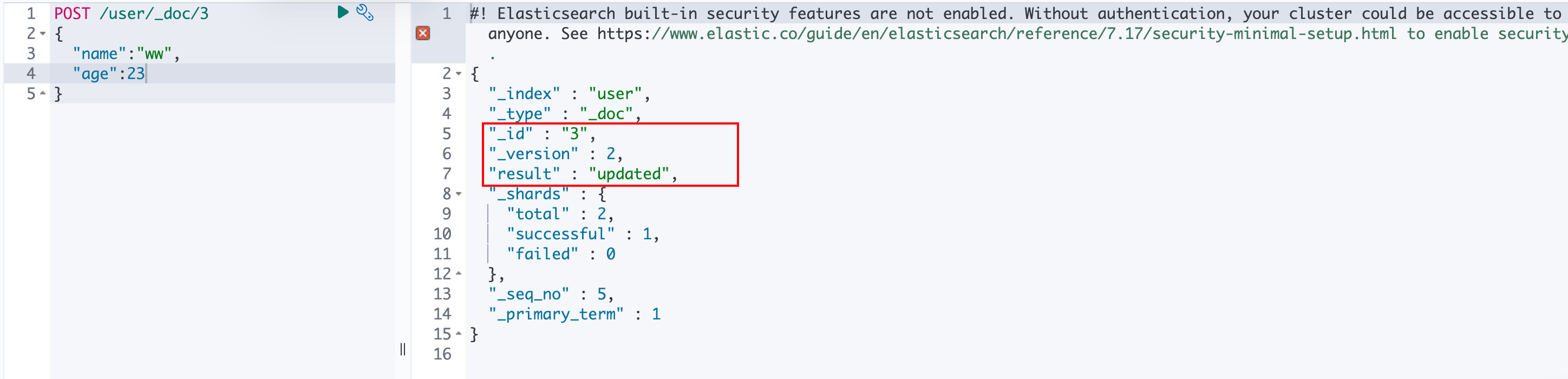
5.2 查询文档
可以通过以下方式查询文档:
txt
GET /{index}/_doc/{id}例如:
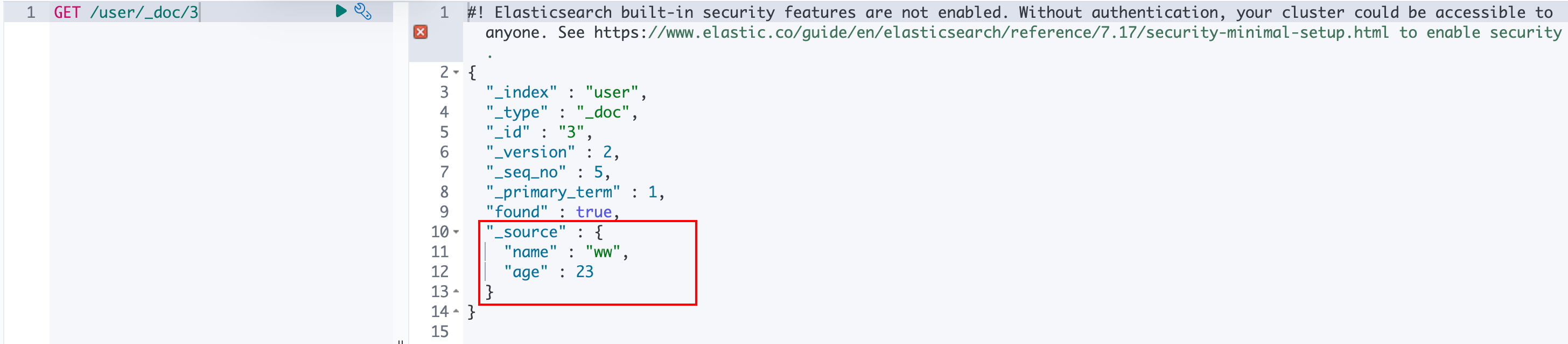
可以看到,源数据在_source字段中。
可以使用_source_includes查询参数,指定要返回的源数据字段:
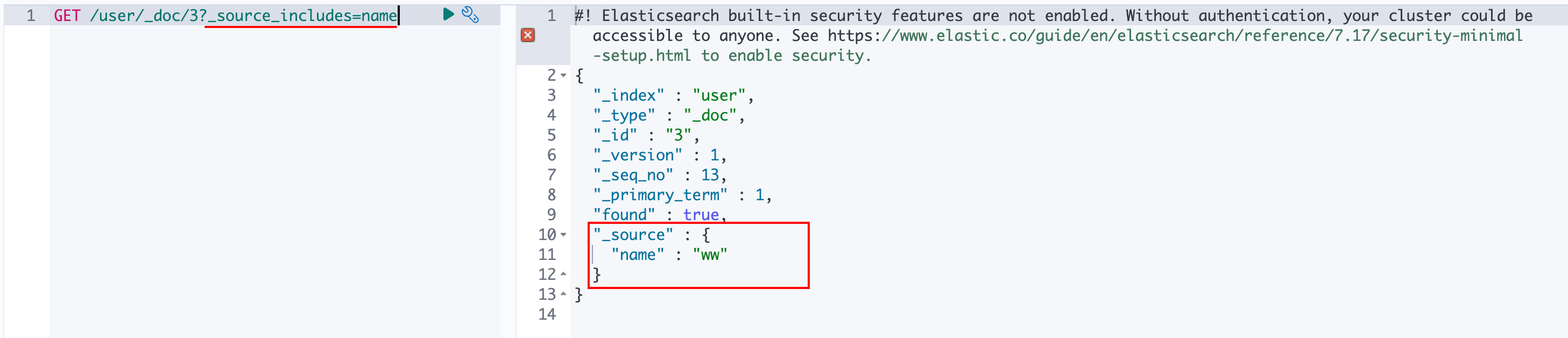
5.3 更新文档
更新文档分为覆盖更新和部分更新。
5.3.1 覆盖更新
覆盖更新是指用新的源数据覆盖旧的源数据,在创建文档时,使用_doc方式,指定相同的ID便可以覆盖更新整个文档:
txt
PUT /{index}/_doc/{id}
POST /{index}/_doc/{id}5.3.2 部分更新
部分更新可以使用如下接口:
txt
POST /{index}/_update/{id}在请求体中的doc字段指定要更新的字段,例如:
json
{
"doc":{
"name":"ww new",
"age": 30,
"address": "广州"
}
}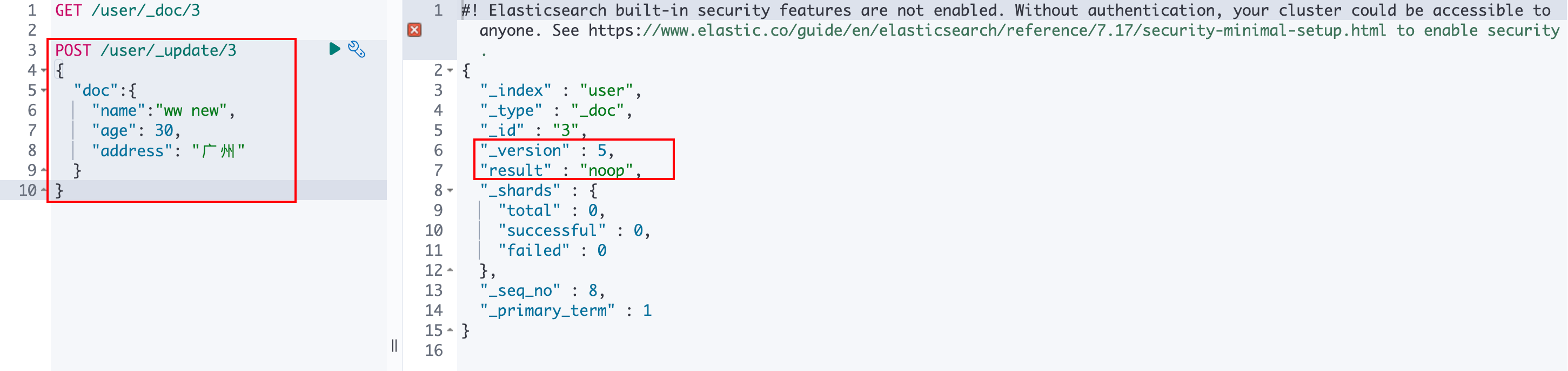
可以发现,部分更新不仅可以更新已有的字段,还可以添加新的字段。
多次执行部分更新,会发现_version的值没有改变,说明部分更新不会影响版本号。
5.4 删除文档
可以使用以下接口删除文档:
txt
DELETE /{index}/_doc/{id}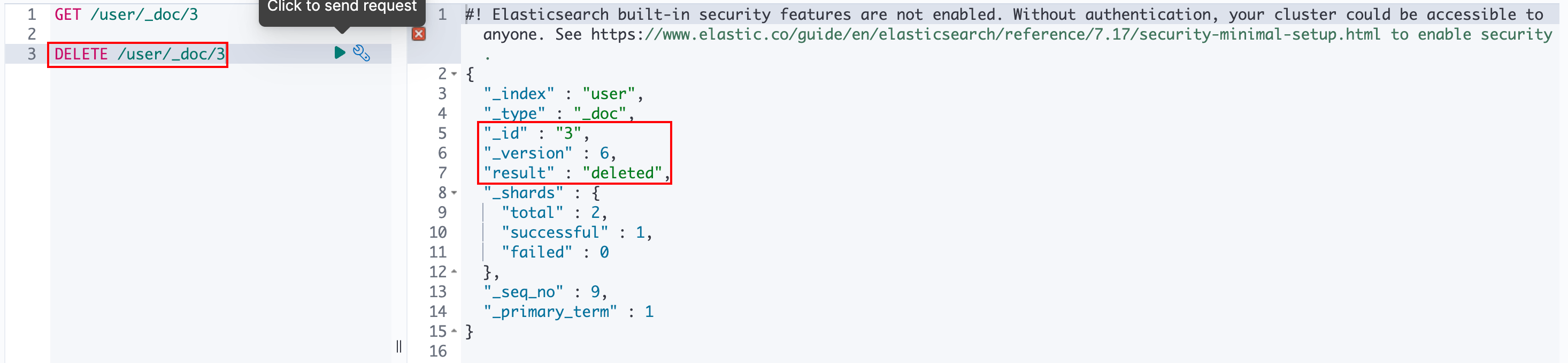
在结果中,发现文档_version的值增加了1,为什么删除文档还会导致文档版本号加1呢?
这是因为ES实行了懒删除策略,当调用接口执行删除操作时,只是将文档标记为待删除状态,后面通过异步操作执行实际的删除操作。
我们可以通过以下方式验证懒删除:
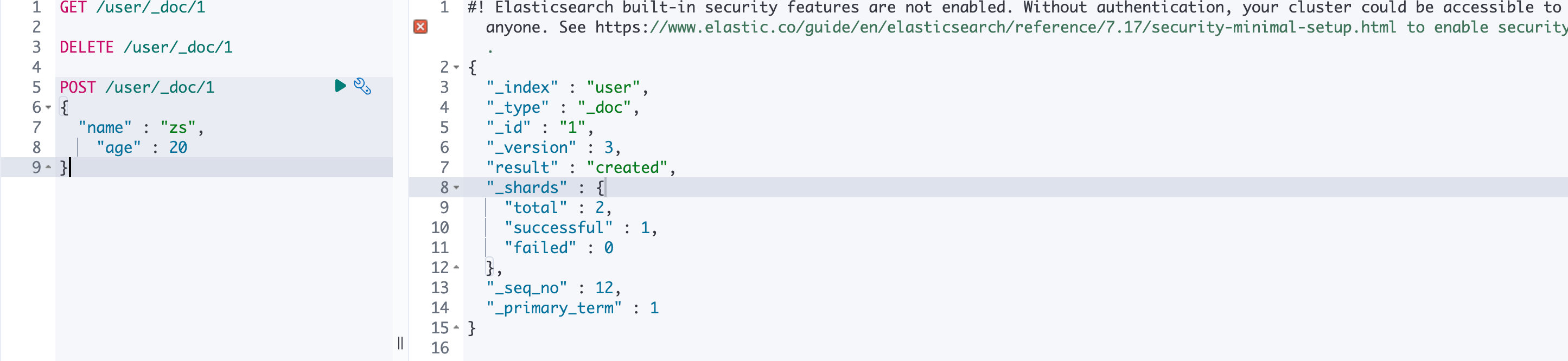
- 首先执行
GET操作,发现版本号为1; - 然后执行
DELETE操作,发现版本号为2; - 然后执行
POST创建操作,发现版本号为3,而不是1,说明执行删除操作时,文档并没有实际删除;
参考文档
[1] 概念介绍:https://www.elastic.co/docs/manage-data/data-store/index-basics
[2] 索引操作:https://www.elastic.co/docs/api/doc/elasticsearch/group/endpoint-indices
[3] 文档操作:https://www.elastic.co/docs/api/doc/elasticsearch/group/endpoint-document
附录
1. 幂等性
幂等性是指一个操作或函数,在执行多次后,其结果与执行一次的效果是完全相同的。换句话说,多次调用不会产生额外的副作用。
以下是HTTP的常用方法,有关幂等性的介绍:
GET 请求(获取资源):
- 幂等:无论请求
/users/123多少次,用户的状态都不会改变,每次都会返回相同的数据(除非数据在外部被修改)。
- 幂等:无论请求
PUT 请求(更新或替换资源):
- 幂等:如果用
PUT /users/123更新一个用户,即使发送多次相同的PUT请求,用户的数据也只会更新一次(或者被替换成相同的新数据),不会产生新的用户。 - 如果
PUT用于创建资源(当资源不存在时),那么第一次调用会创建,后续调用如果内容相同则不会有额外副作用,依然是幂等的。
- 幂等:如果用
DELETE 请求(删除资源):
- 幂等:删除
/users/123,第一次调用会删除成功。后续再调用DELETE /users/123,虽然可能返回 404 Not Found(表示资源已不存在),但从服务器状态的角度来看,该资源已经不存在,不会再次被删除或产生其他改变,因此也是幂等的。
- 幂等:删除
POST 请求(创建资源):
- 非幂等:每次发送
POST /users请求,都可能在服务器上创建一个新的用户资源,并可能返回一个不同的资源 ID。因此,多次POST请求会产生多个不同的资源。
- 非幂等:每次发送
PATCH 请求(局部更新资源):
通常非幂等,但可以设计为幂等:
PATCH用于对资源进行局部修改。例如,PATCH /users/123将用户年龄增加 1。如果多次发送,每次都会增加年龄,因此是非幂等的。但如果PATCH是将某个字段设置为特定值,那么它就是幂等的。取决于其具体实现。