Appearance
搜索、分词与倒排索引
本文介绍搜索、倒排索引和分词的概念,并通过Lucene实践加深理解。
1. 什么是搜索
搜索是指从大量信息中查找和获取所需数据或内容的过程。
搜索通常涉及输入关键词、短语或其他查询条件,然后由系统(如搜索引擎、数据库或应用程序)根据算法或索引返回相关结果。
搜索可以分为如下几类:
- 本地搜索:例如,在本地word文档中搜索关键字;
- 站内搜索:例如,在京东、淘宝等网站内搜索特定商品;
- 全网搜索:在谷歌、百度等网站中搜索;
搜索通常通过搜索引擎实现,涉及多个步骤,包括数据收集、数据预处理、索引构建、查询处理、结果排序与展示等。
搜索引擎有如下实现:
Apache Lucene:开源全文检索库,负责索引构建和查询处理,广泛用于Elasticsearch、Solr等。
Elasticsearch:基于Lucene的分布式搜索引擎,支持大规模数据和复杂查询。
Solr:另一个基于Lucene的搜索平台,适合企业级应用。
数据库内置全文检索:如MySQL的FULLTEXT索引、PostgreSQL的tsvector。
2. 搜索步骤简介
搜索包含数据收集、数据预处理、索引构建、查询处理、结果排序与展示等步骤。
数据收集:从各种来源(如网页、文档、数据库、社交媒体)收集需要搜索的文本数据,使用的技术有爬虫、数据库引入等;
数据预处理:主要是将各来源的数据进行规范化存储,包括:
分词:将文本拆分为单词或短语(tokens)。例如,中文需要使用分词算法(如基于词典或机器学习的中文分词工具)。
去除停用词:过滤掉无意义的常见词(如“的”,“是”等)。
词干提取/词形还原:将单词转换为基本形式(如“running”转为“run”)。
大小写转换:统一大小写以确保一致性。
索引构建:全文检索的核心数据结构是倒排索引,它将文本分词后的每个词(term)映射到包含该词的文档列表及其位置。
查询处理:执行用户的查询意图,包括:
- 查询条件解析:将用户输入的查询条件(如“人工智能应用”)被解析为词语或短语(分词)、去除停用词、词干提取、大小写转换等;
- 查询扩展:主要包括同义词扩展(例如,将“人工智能”扩展为“AI”等)、拼写纠错(如将“artifical intelligence”纠正为“artificial intelligence”)等;
- 查询执行:在倒排索引中查找与查询词匹配的文档,按用户指定条件过滤文档,并计算文档与查询条件的相关度;
结果排序与展示:使用算法(如BM25、TF-IDF)计算每个文档与查询的相关性得分,按照相关性得分进行排序或按照用户指定的条件进行排序,对结果进行分页、去重或聚类,并最终返回给用户;
接下来将介绍在搜索技术中的两个关键技术:分词与倒排索引,并使用lucene实践演示,首先在项目中引入lucene:
xml
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>9.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analysis-common</artifactId>
<version>9.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>9.11.0</version>
</dependency>3. 分词
分词是指将文本转换为单词的步骤。
3.1 分词步骤与实现
在lucene中,分词被称为Tokenization,文本经过分词后转换为索引单位—token或term,称为词元。
Plain text passed to Lucene for indexing goes through a process generally called tokenization. Tokenization is the process of breaking input text into small indexing elements – tokens.
分词分为三个步骤:
- pre-tokenization:分词前处理,主要对原始文本进行处理,包括HTML标签移除、改变或移除满足匹配模式的字符串等;
- tokenization:分词处理,将经过处理的原始文本切分为词元;
- post-tokenization:分词后处理,主要是对词元进行处理,包括停用词过滤、词干提取、同义词扩展等;
在lucene中,三个步骤通过三类组件来实现:
- pre-tokenization:主要通过
CharFilter来实现, - tokenization:主要通过
Tokenizer来实现, - post-tokenization:主要通过
TokenFiletr来实现,
上述组件封装在Analyzer中,关系如下:
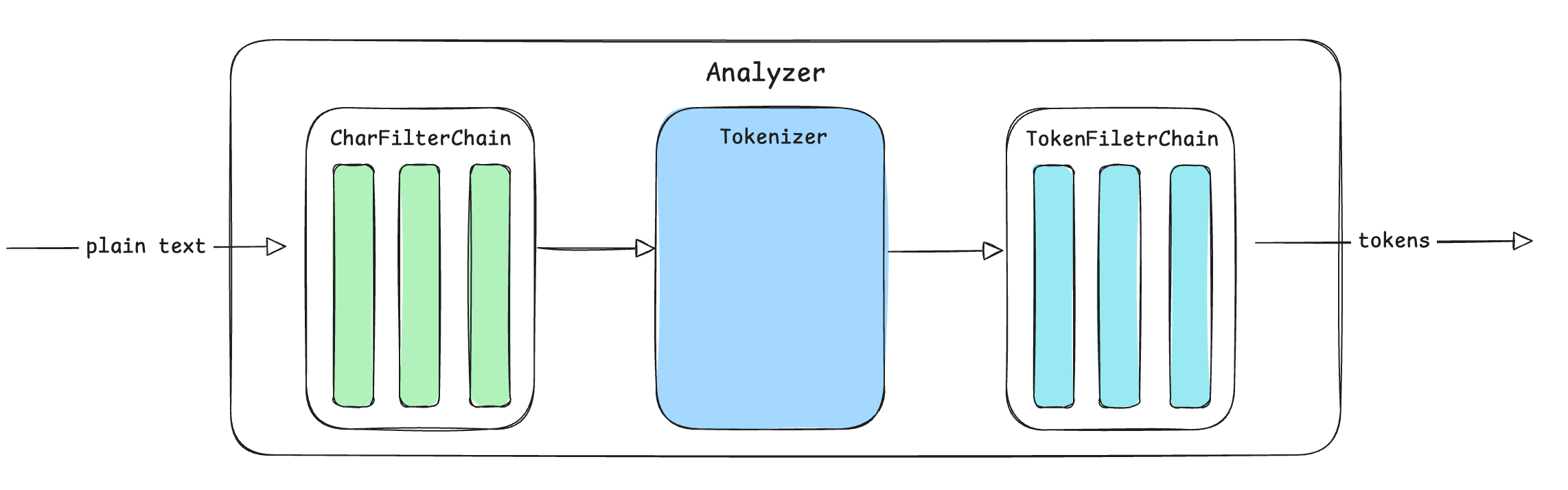
也就是说,Analyzer将CharFiletr、Tokenizer和TokenFilter集成在一起,我们只需要调用Analyzer就可以将原始文本转换为tokens,在Analyzer内部依次经过CharFilter链、Tokenizer和TokenFilter链处理。
3.2 分词实践
3.2.1 CharFilter
CharFilter 是一个字符流过滤器,用于在分词之前对输入文本进行预处理(例如,规范化字符、替换特定字符等),它本质上是对 Reader 的包装。
java
public abstract class CharFilter extends Reader {
}例如,以下演示CharFilter链的作用:
java
import org.apache.lucene.analysis.charfilter.HTMLStripCharFilter;
import org.apache.lucene.analysis.charfilter.MappingCharFilter;
import org.apache.lucene.analysis.charfilter.NormalizeCharMap;
import org.apache.lucene.analysis.pattern.PatternReplaceCharFilter;
import java.io.StringReader;
import java.io.IOException;
import java.util.regex.Pattern;
public class CharFilterExample {
public static void main(String[] args) throws IOException {
String input = "<html><body><p>café123</p></body></html>";
StringReader reader = new StringReader(input);
// 1. 创建 HTMLStripCharFilter,用于去除HTML标签
HTMLStripCharFilter htmlStripCharFilter = new HTMLStripCharFilter(reader);
// 2. 创建 MappingCharFilter,用于替换字符
// 定义字符映射规则(例如,将 "é" 替换为 "e")
NormalizeCharMap.Builder builder = new NormalizeCharMap.Builder();
builder.add("é", "e");
NormalizeCharMap charMap = builder.build();
// 创建 MappingCharFilter
MappingCharFilter mappingCharFilter = new MappingCharFilter(charMap, htmlStripCharFilter);
// 3. 创建 PatternReplaceCharFilter,用于正则表达式替换
// 将数字替换为空格
PatternReplaceCharFilter patternReplaceCharFilter = new PatternReplaceCharFilter(
Pattern.compile("\\d+"),
" ",
mappingCharFilter
);
// 读取处理后的字符流
StringBuilder result = new StringBuilder();
int c;
while ((c = patternReplaceCharFilter.read()) != -1) {
result.append((char) c);
}
System.out.println("CharFilter 输出: " + result.toString().trim());
}
}结果输出:
txt
CharFilter 输出: cafe3.2.2 Tokenizer
Tokenizer 负责将字符流拆分为词元(tokens),是分析器的核心分词组件。Tokenizer 是一个 TokenStream 的子类,可以直接生成词元序列,常见的 Tokenizer 包括 StandardTokenizer、WhitespaceTokenizer 等。
Lucene 的 TokenStream(包括 Tokenizer 和 TokenFilter)使用一种基于属性的机制来处理词元。每个词元可以携带多个属性(如文本内容、位置、偏移量等)。
CharTermAttribute 是 TokenStream 中最常用的属性之一,用于存储词元的文本内容(即分词后的单词或短语)。
其他常见属性包括:
TermFrequencyAttribute:存储词元的词频,也就是该词元的出现次数。TypeAttribute:存储词元的类型。OffsetAttribute:存储词元的起始和结束偏移量。
以下例子演示Tokenizer的使用:
java
import org.apache.lucene.analysis.standard.StandardTokenizer;
import org.apache.lucene.analysis.tokenattributes.*;
import java.io.StringReader;
import java.io.IOException;
public class TokenizerExample {
public static void main(String[] args) throws IOException {
// 输入文本
String input = "I love learning Lucene 123 你好";
StringReader reader = new StringReader(input);
// 创建 Tokenizer
StandardTokenizer tokenizer = new StandardTokenizer();
tokenizer.setReader(reader);
// 增加词元属性
CharTermAttribute termAttr = tokenizer.addAttribute(CharTermAttribute.class);
TypeAttribute typeAttribute = tokenizer.addAttribute(TypeAttribute.class);
TermFrequencyAttribute termFrequencyAttribute = tokenizer.addAttribute(TermFrequencyAttribute.class);
OffsetAttribute offsetAttribute = tokenizer.addAttribute(OffsetAttribute.class);
// reset() 初始化或重置 TokenStream(如 Tokenizer)的状态,使其准备好从头开始处理输入的字符流。
tokenizer.reset();
// incrementToken() 获取下一个词元
// 将 TokenStream 移动到下一个词元,并更新相关属性(如 CharTermAttribute)以反映当前词元的信息。
while (tokenizer.incrementToken()) {
System.out.println("Token: " + termAttr.toString());
System.out.println(" Term Frequency: " + termFrequencyAttribute.getTermFrequency());
System.out.println(" type: " + typeAttribute.type());
System.out.println(" Offset: " + offsetAttribute.startOffset() + " - " + offsetAttribute.endOffset());
}
// 关闭资源
tokenizer.end();
tokenizer.close();
}
}结果如下:
txt
Token: I
Term Frequency: 1
type: <ALPHANUM>
Offset: 0 - 1
Token: love
Term Frequency: 1
type: <ALPHANUM>
Offset: 2 - 6
Token: learning
Term Frequency: 1
type: <ALPHANUM>
Offset: 7 - 15
Token: Lucene
Term Frequency: 1
type: <ALPHANUM>
Offset: 16 - 22
Token: 123
Term Frequency: 1
type: <NUM>
Offset: 23 - 26
Token: 你
Term Frequency: 1
type: <IDEOGRAPHIC>
Offset: 27 - 28
Token: 好
Term Frequency: 1
type: <IDEOGRAPHIC>
Offset: 28 - 29可以看到,Tokenizer可以将文本进行分词,并获取词元的各个属性。需要注意以下几点:
TokenStream基于属性机制,需要添加相关属性,才能获取到属性值;TokenStream基于流式机制,reset()方法可以理解为将指针指向流中的开始位置;incrementToken()用于获取下一个词元,并更新内部相关属性值为下一个词元的属性;
3.2.3 TokenFilter
TokenFilter 是一个词元过滤器,用于对 Tokenizer 生成的词元流进行处理(例如,转换为小写、移除停用词、词干提取等)。它依赖于 TokenStream(通常来自 Tokenizer 或另一个 TokenFilter)。
TokenFilter也是TokenStream的子类:
java
public abstract class TokenFilter extends TokenStream implements Unwrappable<TokenStream> {
}所以TokenFilter也是基于属性机制的。
以下的例子演示TokenFilter的使用:
java
import org.apache.lucene.analysis.StopFilter;
import org.apache.lucene.analysis.en.KStemFilter;
import org.apache.lucene.analysis.standard.StandardTokenizer;
import org.apache.lucene.analysis.core.LowerCaseFilter;
import org.apache.lucene.analysis.synonym.SynonymGraphFilter;
import org.apache.lucene.analysis.synonym.SynonymMap;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.CharsRef;
import java.io.StringReader;
import java.io.IOException;
public class TokenFilterExample {
public static void main(String[] args) throws IOException {
// 输入文本
String input = "She LOVES Lucene, which is a search engine.";
StringReader reader = new StringReader(input);
// 创建 Tokenizer
StandardTokenizer tokenizer = new StandardTokenizer();
tokenizer.setReader(reader);
// 1. 创建 LowerCaseFilter,用于将词元转换为小写
LowerCaseFilter lowerCaseFilter = new LowerCaseFilter(tokenizer);
// 2. 创建 StopFilter,用于过滤停用词
StopFilter stopFilter = new StopFilter(lowerCaseFilter, StopFilter.makeStopSet("is", "a"));
// 3. 创建 KStemFilter,用于词干提取,例如 loves 转换为 love
KStemFilter kStemFilter = new KStemFilter(stopFilter);
// 4. 创建 SynonymGraphFilter,用于同义词扩展
SynonymMap.Builder builder = new SynonymMap.Builder();
builder.add(new CharsRef("love"), new CharsRef("like"), true);
SynonymMap synonymMap = builder.build();
SynonymGraphFilter synonymGraphFilter = new SynonymGraphFilter(kStemFilter, synonymMap, true);
// 添加词元属性
CharTermAttribute termAttr = synonymGraphFilter.addAttribute(CharTermAttribute.class);
// 获取词元
synonymGraphFilter.reset();
while (synonymGraphFilter.incrementToken()) {
System.out.println("Token: " + termAttr.toString());
}
// 关闭资源
synonymGraphFilter.end();
synonymGraphFilter.close();
}
}结果如下:
txt
Token: she
Token: like
Token: love
Token: lucene
Token: which
Token: search
Token: engine从结果可以看出:
She和LOVES都转换为了小写,这是LowerCaseFilter的作用;is和a没有出现在词元中,这是StopFilter的作用,过滤掉了停用词;LOVES没有出现在词元中,而是love,这是KStemFilter的作用,用于提取词干;like出现在了词元中,这是SynonymGraphFilter的作用,添加了同义词;
3.2.4 Analyzer
在 Apache Lucene 中,Analyzer 是用于将文本分解为词元(tokens)的核心组件,它封装了 CharFilter、Tokenizer 和 TokenFilter 的处理流程。通过组合这些组件,Analyzer 提供了一种便捷的方式来预处理文本,用于索引或查询。
以下案例演示了StandardAnalyzer的用法:
java
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import java.io.IOException;
import java.io.StringReader;
public class AnalyzerExample {
public static void main(String[] args) throws IOException {
// 原始文本
String text = "This is a sample text for analysis.";
// 停用词列表,一行表示一个停用词
String stopWords = "a\nan\nthe\nis";
// 创建标准分词器
Analyzer analyzer = new StandardAnalyzer(new StringReader(stopWords));
// 创建分词流
TokenStream tokenStream = analyzer.tokenStream("contents", text);
// 获取分词结果
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(tokenStream.getAttribute(CharTermAttribute.class).toString());
}
// 关闭资源
tokenStream.end();
tokenStream.close();
analyzer.close();
}
}结果如下:
txt
this
sample
text
for
analysisTIP
StandardAnalyzer封装了哪些组件?
通过分析StandardAnalyzer的源码:
java
protected TokenStreamComponents createComponents(final String fieldName) {
final StandardTokenizer src = new StandardTokenizer();
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new LowerCaseFilter(src);
tok = new StopFilter(tok, stopwords);
return new TokenStreamComponents(
r -> {
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
src.setReader(r);
},
tok);
}可以发现标准分析器封装了以下组件
StandardTokenizer:按单词边界分词,支持多语言。LowerCaseFilter:将词元转换为小写。StopFilter:移除停用词。
注意,标准分析器没有封装CharFilter组件。
TIP
为什么可以直接获取到词元的文本属性CharTermAttribute?
StandardAnalyzer使用的是StandardTokenizer, 在StandardTokenizer实现中,默认加入了词元以下属性:
java
public final class StandardTokenizer extends Tokenizer {
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
private final PositionIncrementAttribute posIncrAtt =
addAttribute(PositionIncrementAttribute.class);
private final TypeAttribute typeAtt = addAttribute(TypeAttribute.class);
}所以可以直接获取上述词元属性,不用自己再手动添加。
TIP
tokenStream(final String fieldName, final String text)中,field有什么用?
field 参数是一个字符串,表示正在处理的文本所属的字段名称。有以下作用:
支持字段特定的分析规则
Lucene 允许为不同的字段(如标题、内容、标签等)配置不同的分析器或分析规则。例如,标题字段可能只需要简单分词,而内容字段可能需要词干提取和同义词扩展。
field参数告诉Analyzer当前处理的文本属于哪个字段,从而应用对应的分析逻辑。在自定义
Analyzer中,可以通过重写createComponents(String fieldName)方法,根据field返回不同的TokenStreamComponents。java@Override protected TokenStreamComponents createComponents(String fieldName) { StandardTokenizer tokenizer = new StandardTokenizer(); if ("title".equals(fieldName)) { // 标题字段:仅分词和小写 return new TokenStreamComponents(tokenizer, new LowerCaseFilter(tokenizer)); } else { // 内容字段:分词、小写、词干提取 TokenStream stream = new LowerCaseFilter(tokenizer); stream = new PorterStemFilter(stream); return new TokenStreamComponents(tokenizer, stream); } }支持字段级别的索引
在 Lucene 索引中,文档通常包含多个字段(如 title、content、author),每个字段的文本可以独立分析和存储。
field参数指定了当前TokenStream对应的字段名,确保分析结果与正确的字段关联。在索引构建或查询时,Lucene 使用字段名区分不同字段的词元流,从而实现字段级别的搜索。
例如:
构建倒排索引时:
- 字段 title:输入“Learning Lucene” -> 分词为“learning”、“lucene”。
- 字段 content:输入“Lucene is powerful” -> 分词为“lucene”、“power”。
查询时,可以指定搜索
title:Learning或content:powerful,field参数帮助分析器正确处理查询文本。
3.3 自定义Analyzer
3.3.1 继承Analyzer类
除了使用Lucene定义好的标准分析器,我们也可以继承Analyzer类,定义自己的分析器,主要重写两个方法:
protected TokenStreamComponents createComponents(String fieldName):用来定义Tokenizer和TokenFilter,可以根据field定义不同的组合;protected Reader initReader(String fieldName, Reader reader):用来定义CharFilter,也可以根据field定义不同的CharFilter链;
如下,自定义分析器:
java
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.LowerCaseFilter;
import org.apache.lucene.analysis.StopFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.charfilter.HTMLStripCharFilter;
import org.apache.lucene.analysis.en.KStemFilter;
import org.apache.lucene.analysis.en.PorterStemFilter;
import org.apache.lucene.analysis.standard.StandardTokenizer;
import java.io.Reader;
import java.util.List;
import java.util.Set;
public class MyAnalyzer extends Analyzer {
private List<String> stopWords;
public MyAnalyzer(List<String> stopWords) {
super();
this.stopWords = stopWords;
}
@Override
protected TokenStreamComponents createComponents(String fieldName) {
StandardTokenizer tokenizer = new StandardTokenizer();
if ("title".equals(fieldName)) {
// 标题字段:分词、小写、停用词过滤
return new TokenStreamComponents(tokenizer,
new LowerCaseFilter(new StopFilter(tokenizer, StopFilter.makeStopSet(stopWords))));
} else {
// 内容字段:分词、小写、词干提取、停用词过滤
TokenStream stream = new LowerCaseFilter(tokenizer);
stream = new KStemFilter(stream);
stream = new StopFilter(stream, StopFilter.makeStopSet(stopWords));
return new TokenStreamComponents(tokenizer, stream);
}
}
@Override
protected Reader initReader(String fieldName, Reader reader) {
if ("content".equals(fieldName)) {
// 仅对 content 字段移除 HTML
return new HTMLStripCharFilter(reader);
}
return reader;
}
}使用自定义分析器,并检查不同字段的分词结果:
java
public class MyAnalyzerExample {
public static void main(String[] args) throws IOException {
String text = "<h1>She loves lucene, a serach engine.</h1>";
System.out.println("原始内容:" + text);
// 创建自定义分词器
MyAnalyzer analyzer = new MyAnalyzer(Arrays.asList("is", "a"));
System.out.println("----------内容字段(content)分词结果------------");
TokenStream tokenStream = analyzer.tokenStream("content", text);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(tokenStream.getAttribute(CharTermAttribute.class).toString());
}
tokenStream.end();
tokenStream.close();
System.out.println("----------标题字段(title)分词结果------------");
tokenStream = analyzer.tokenStream("title", text);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(tokenStream.getAttribute(CharTermAttribute.class).toString());
}
tokenStream.end();
tokenStream.close();
analyzer.close();
}
}结果如下:
txt
原始内容:<h1>She loves lucene, a serach engine.</h1>
----------内容字段(content)分词结果------------
she
love
lucene
serach
engine
----------标题字段(title)分词结果------------
h1
she
love
lucene
serach
engine
h1可以看到,对于不同字段,即使是相同的内容,处理结果也不同。
3.3.2 CustomerAnalyzer
在Lucene中,也提供了CustomerAnalyzer,我们可以装配三大组件实现自定义分析器,例如:
java
public static void main(String[] args) throws IOException {
// 自定义CustomAnalyzer
CustomAnalyzer analyzer = CustomAnalyzer.builder()
.addCharFilter(HTMLStripCharFilterFactory.class)
.addCharFilter(PatternReplaceCharFilterFactory.class, "pattern", "\\d+", "replacement", " ")
.withTokenizer(StandardTokenizerFactory.class)
.addTokenFilter(LowerCaseFilterFactory.class)
.addTokenFilter(KStemFilterFactory.class)
.addTokenFilter(StopFilterFactory.class)
.build();
// 分词
String text = "<div> She loves Java 8 and I like Python 3 <div>";
TokenStream tokenStream = analyzer.tokenStream("", text);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(tokenStream.getAttribute(CharTermAttribute.class).toString());
}
tokenStream.end();
tokenStream.close();
analyzer.close();
}TIP
分析如何为CharFilter或TokenFilter指定参数?
在CustomerAnalyzer的构造器中,提供了通过工厂方法创建过滤器,例如:
java
public Builder addCharFilter(Class<? extends CharFilterFactory> factory, String... params)
throws IOException {
return addCharFilter(factory, paramsToMap(params));
}
public Builder addCharFilter(
Class<? extends CharFilterFactory> factory, Map<String, String> params) throws IOException {
Objects.requireNonNull(factory, "CharFilter name may not be null");
charFilters.add(
applyResourceLoader(newFactoryClassInstance(factory, applyDefaultParams(params))));
componentsAdded = true;
return this;
}其中的参数params是如何作用的?
通过newFactoryClassInstance()源码可以看到,参数params最终被转换为Map,传递给了指定工厂类的构造方法:
java
public static <T extends AbstractAnalysisFactory> T newFactoryClassInstance(
Class<T> clazz, Map<String, String> args) {
// 省略异常处理
return clazz.getConstructor(Map.class).newInstance(args);
}我们以PatternReplaceCharFilterFactory为例,就是从Map集合中,按照属性名称找到对应的值,并且给工厂属性赋值:
java
public class PatternReplaceCharFilterFactory extends CharFilterFactory {
public static final String NAME = "patternReplace";
private final Pattern pattern;
private final String replacement;
public PatternReplaceCharFilterFactory(Map<String, String> args) {
super(args);
pattern = getPattern(args, "pattern");
replacement = get(args, "replacement", "");
if (!args.isEmpty()) {
throw new IllegalArgumentException("Unknown parameters: " + args);
}
}
@Override
public Reader create(Reader input) {
return new PatternReplaceCharFilter(pattern, replacement, input);
}
}最终,通过调用create()方法,从工厂类中找到对应的值,构建PatternReplaceCharFilter。
3.4 中文Analyzer
本小节介绍有关中文分词器的实现。
3.4.1 SmartChineseAnalyzer
在Lucene中提供了中文分词器的实现SmartChineseAnalyzer,使用如下:
java
public class SmartChineseAnalyzerExample {
public static void main(String[] args) throws IOException {
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
String text = "这是一个中文分词的例子。";
TokenStream tokenStream = analyzer.tokenStream("contents", text);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(tokenStream.getAttribute(CharTermAttribute.class).toString());
}
tokenStream.end();
tokenStream.close();
analyzer.close();
}
}结果如下:
txt
这
是
一个
中文
分
词
的
例子可以发现,结果并不理想。
3.4.2 IKAnalyzer
第三方实现了中文分词器,效果更好。
首先引入依赖:
xml
<dependency>
<groupId>com.github.magese</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.5.0</version>
</dependency>然后就可以使用IKAnalyzer,在使用之前,有几点需要明确:
IKAnalyzer支持两种模式:- 智能模式
new IKAnalyzer(true):使用智能分词策略,最小化输出分词结果; - 非智能模式
new IKAnalyzer(false):使用非智能分词模式,这也是默认的模式,会细粒度输出所有可能的切分结果;
- 智能模式
IKAnalyzer支持两种词典:ext_dict:扩展词典,对于该文件中的词语,会被视为一个整体,这对于某些特定领域非常合适,例如,深度学习可能会被分为两个词元深度和学习,如果在扩展词典中加入深度学习,那么整个词会作为一个词元;ext_stopwords:停用词词典,该文件中的词语,不会被输出为词元;
下面演示IKAnalyzer的使用,首先在类路径下配置IKAnalyzer.cfg.xml文件,配置两种词典:
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 配置是否加载默认词典 -->
<entry key="use_main_dict">true</entry>
<!-- 配置自己的扩展字典,多个用分号分隔 -->
<entry key="ext_dict">ext.dic;my_ext.dic</entry>
<!-- 配置自己的扩展停止词字典,多个用分号分隔 -->
<entry key="ext_stopwords">stopword.dic;my_stopword.dic</entry>
</properties>然后在同级目录下创建两个文件my_ext.dic和my_stopword.dic:
txt
深度学习txt
的案例代码如下:
java
public class IKAnalyzerExample {
public static void main(String[] args) throws IOException {
String text = "这是一个中文分词的例子。深度学习。";
IKAnalyzer ikAnalyzer = new IKAnalyzer(true);
TokenStream tokenStream = ikAnalyzer.tokenStream("contents", text);
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(tokenStream.getAttribute(CharTermAttribute.class).toString());
}
tokenStream.end();
tokenStream.close();
ikAnalyzer.close();
}
}结果如下:
txt
Load extended dictionary:ext.dic
Load extended dictionary:my_ext.dic
Load stopwords dictionary:stopword.dic
Load stopwords dictionary:my_stopword.dic
这是一个
中文分词
例子
深度学习结果符合预期。
4. 倒排索引
在搜索中,倒排索引(inverted index)是核心的结构,用于加快搜索速度,本小节介绍有关倒排索引的知识。
4.1 索引结构
在这一小节中,我们从简单到复杂,构建倒排索引结构。
假设,现在我们有以下三段文本(每段文本就是一个文档):
txt
文档1:今天天气很好
文档2:天气很好很晴朗
文档3:今天是星期一首先,对每一个文档进行分词处理,分词结果如下:
txt
文档1分词结果:今天、天气、很好
文档2分词结果:天气、很好、晴朗
文档3分词结果:今天、星期一倒排索引就是词元(Term/token)到文档的映射,也就是说某个词元属于哪个文档。
倒排索引最简单的结构如下:
txt
今天 -> [文档1, 文档3]
天气 -> [文档1, 文档2]
很好 -> [文档1, 文档2]
晴朗 -> [文档2]
星期一 -> [文档3]当用户输入查询词(如“今天天气”)时,首先对用户输入的查询词进行同样的分词处理,结果为[今天、天气],然后系统查找倒排索引,找到包含“今天”和“天气”的文档。对结果进行交集、并集等操作,返回相关文档,结果返回[文档1、文档2、文档3]。
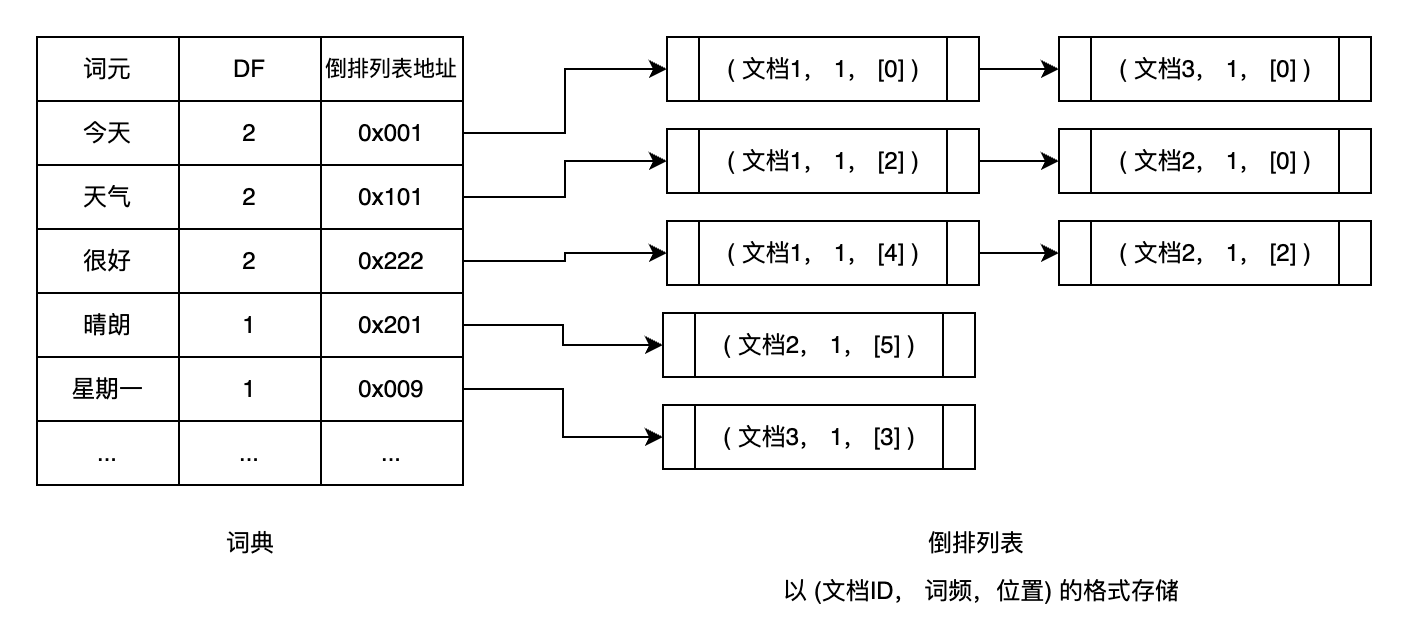
在实际使用中,倒排索引通常由两部分组成:
词典(Dictionary):存储所有唯一词元的集合,并且词元有序,并且还会存储DF(Documen Frequency)和指向倒排列表的地址。
DF(Documen Frequency):包含该词元的文档总数;
倒排列表(Posting List):每个词元关联一个列表,记录包含该词元的文档ID以及其他信息(如词频、位置等),这个列表称为倒排列表。在每一个倒排列表中,按照文档ID进行排序。
词频:某个词元在文档中出现的次数;
词元位置:某个在文档中出现的位置,通常以偏移量来表示;
所以,实际上的倒排索引结构如下:
4.2 索引压缩
在上面的结构中,如果我们的文档数量不多,只有几百几千个,那么效果很好,可是,加入我们的文档数量非常多,达到上千万甚至上亿,那么存储倒排索引将会消耗大量磁盘空间,并且也会增加IO次数导致搜索效率变低,所以,压缩倒排索引就显得非常重要了。
压缩倒排索引分为两部分内容:词典的压缩、倒排列表的压缩。
4.2.1 词典的压缩
假设在词典中,为每个词元分配20个字节的大小,为DF分配4个字节大小,为倒排列表地址分配4字节大小,则单条词元占据28个字节大小,假设总共有40万条词元,如果将所有词元按照数据形式加载进内存,则总共占据
在《Introduction to Information Retriveval》一书中(参考资料[2]),英语词元的平均长度为8,也就是8字节,所以使用固定20个字节的大小存储词元是非常浪费的,平均每个词元浪费了12个字节大小,并且,这种方式无法存储超过20个字节大小的词元。
Using fixed-width entries for terms is clearly wasteful. The average length of a term in English is about eight characters, so on average we are wasting twelve characters in the fixed-width scheme. Also, we have no way of storing terms with more than twenty characters.
通过把所有的词元存储为一个长字符串(Dictionary-as-a-string storage),可以解决上述问题:
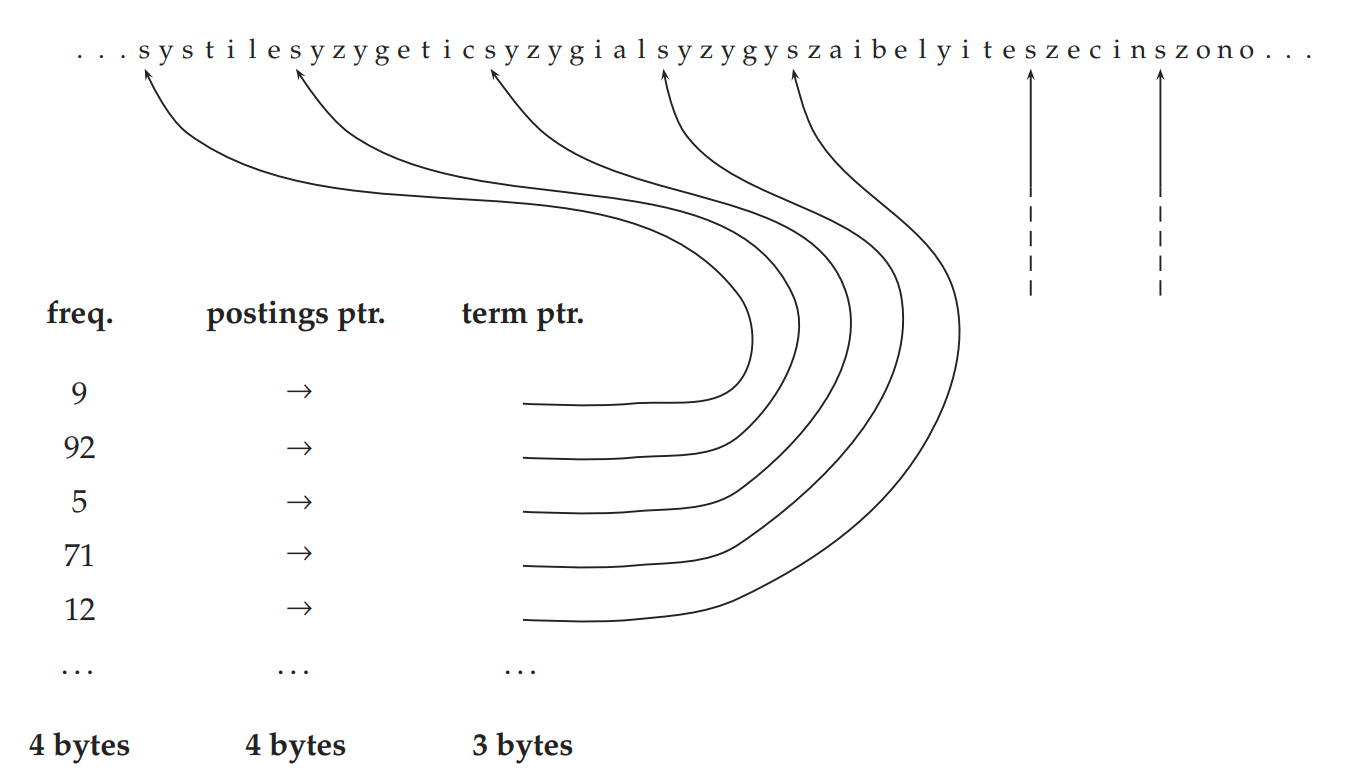
也就是说,将所有词元紧密相连,形成一串很长的字符串,然后在词典中,使用词元指针,指向该词元在长字符串中的位置。
如果有40万个词元,平均每个词元长度为8个字节,那么该字符串所占空间为 $400000 \times 8 = 3.2 \times 10^6 $ 位,也就是说地址空间,我们需要
使用这种方式,整个词典的大小为 $400000 \times (4+4+3+8) = 7.6MB $ (4字节的DF,4字节的倒排列表地址,3字节的词元地址,8字节的平均词元大小),有效地将词典从最初的11.2MB压缩到7.6MB。
我们还可以进一步压缩词典的大小,使用块存储的方式(Blocked Store),块存储的思想是将k个词元分为一组(称为块),然后在该组内的每个词元前面,使用1个字节表示词元长度,在词典中,只存储每组第一个词元的地址。
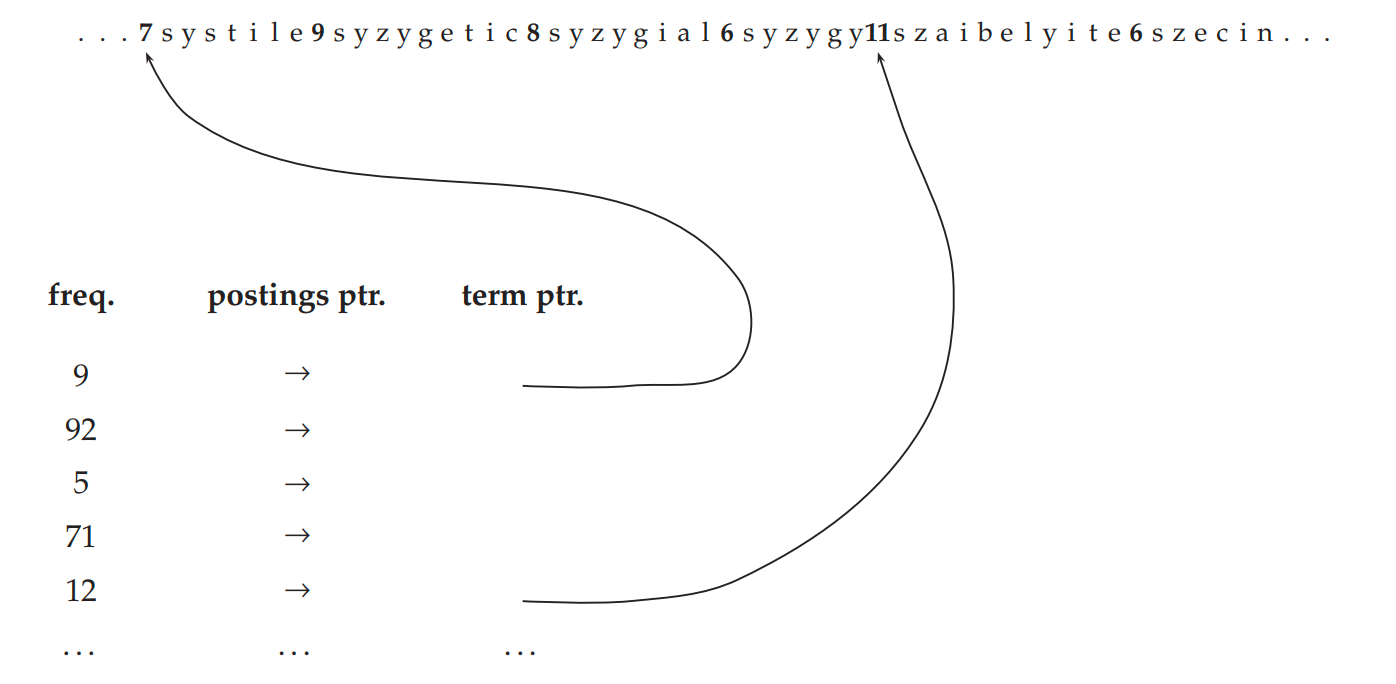
例如,如上将4个词元(k=4)分为一组,那么每组的词元指针减少了
对于40万个词元,按照4个词元为一组的方式进行分组,那么可以分为10万组,每组减少5个字节,总共减少 $100000 \times 5 ≈ 0.5MB $,因此,整个词典的大小约为 $7.6 - 0.5 = 7.1MB $。
通过这种方式,只要我们不断提高k的值,例如极端情况下,将40万个词元分为一组,那么整个词典所占空间将会来到该方法的极致,6.8MB,计算方式如下
但是,随着k值的不断提高,查询效率也会越来越慢,因为在每组内,是通过顺序查找的方式来比较词元的。
例如,有如下有序词元:
txt
a b c d e f g h假设k=1,即不分组,那么按照二分查找算法,平均查找次数为2.625次。
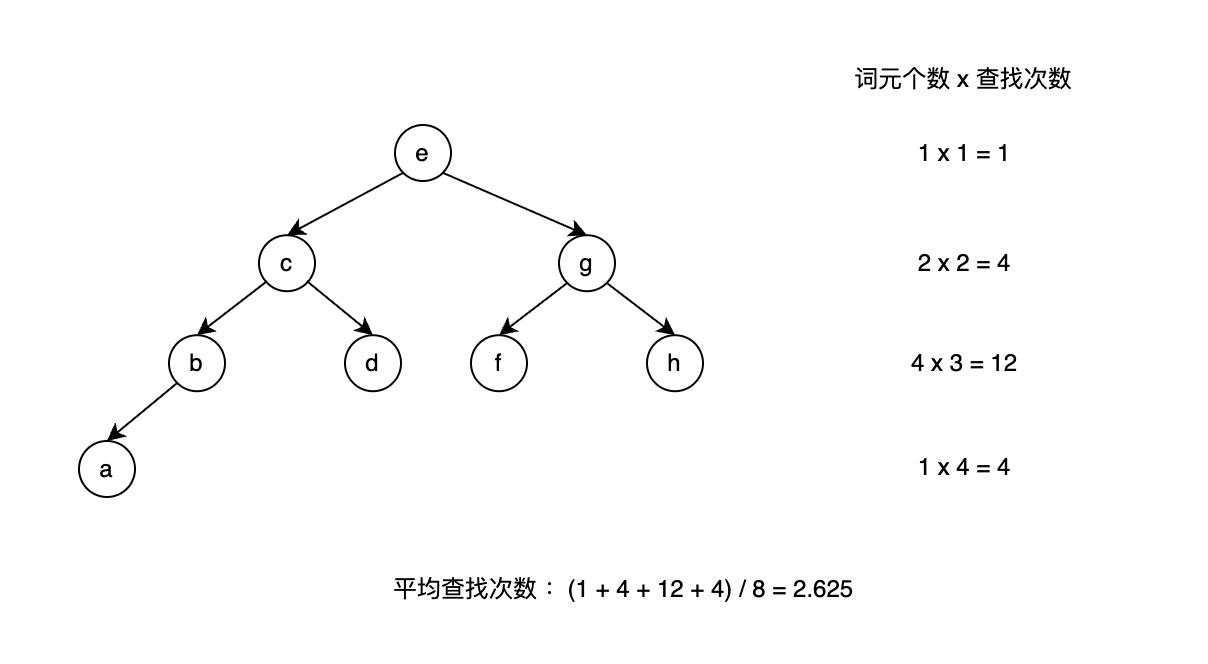
假设k=8,即每8个为一组,则退化为单链表,平均查找次数为
因此,虽然提高k的值,有助于减少词典的大小,但是会对查询效率有影响,因此,在词典大小和查询效率之间取得平衡是k取值的关键。
在块存储的方式之上,我们可以利用多个单词有相同前缀的方式,进行前缀编码(front coding),如下:

automata、automate、automatic和automation都有相同的前缀automat,所以,经过前缀编码后,在块内部第一个词元中,使用特殊符号*表示前缀的结束,在后续词元中,使用特殊符号◇表示前缀automat,经过前缀编码后,可以发现占用大小进一步被压缩了。
4.2.2 倒排列表的压缩
对于倒排列表,其中每一项可能包含DocID、Term Frequency和Position,此处只介绍对DocID的压缩。
DocID的列表,我们可以看作是一串有序的数字压缩,例如,[1,2,99,121,122,2323,2329,3000]数字列表的压缩。
假设现在有800000(80万)个文档,postings的数量为1亿个,那么整个posting所占据的空间为:
- 首先要表示80万这个数字,那么每个数字需要
空间; - 有1亿个posting,那么总共的大小为
;
为了减少posting所占的空间大小,可以按照增量编码+变长编码的方法进行压缩。
增量编码(Delta Encoding):存储倒排列表中相邻文档ID的差值(增量),而不是直接存储原始ID。
例如,假设原始的DocID列表为[65536, 65537, 65538, 65539],那么存储差值后,DocID列表为[65536, 1, 1, 1](第一个数字保持不变)。
在posting list中,DocID通常是有序递增的,而且差值不会大于后一个数字,那么存储空间是会减少的。
变长编码(Variable Byte Encoding, VBE):将整数编码为字节序列,每个字节用后7位存储数据,第1位作为标志位指示是否还有后续字节,假设第1位标志位为0表示还有后续字节,为1表示没有后续字节。
例如,现有数字129,经过变长编码后,字节序列为00000001 10000001。
变长编码解决的问题是,对于范围较广的整数序列,可以用较小的空间存储,也就是说,每个整数找到能容纳自身的最小字节数,例如,数字1只需要用1个字节存储,而不是4个或8个字节来存储。
变长编码实现如下:
java
public class ByteUtils {
public static void main(String[] args) {
System.out.println("原始数据:");
List<Long> values = Arrays.asList(1L, 100L, 8989L, 32323L, 111221L, 123243232L, 123124339L);
System.out.println(values);
System.out.println("编码结果:");
List<Byte> encoded = new ArrayList<>();
for (Long value : values) {
List<Byte> bytes = vbeEncode(value);
encoded.addAll(bytes);
System.out.print(value + ": ");
bytes.forEach(b -> System.out.print(byteToBinary(b) + " "));
System.out.println();
}
System.out.println("解码结果:");
System.out.println(vbeDecodeNumbers(encoded));
}
/**
* 变长编码
* @param n 待编码的数字
* @return 编码后的字节数组
*/
public static List<Byte> vbeEncode(long n){
List<Byte> result = new ArrayList<>();
while (true){
long e = n % 128;
result.add(0, (byte) e);
if ((n = n >>> 7) == 0){
break;
}
}
Byte last = result.remove(result.size() - 1);
last = (byte) (last | 0x80);
result.add(last);
return result;
}
/**
* 对单个数字进行变长解码
* @param bytes 待解码的字节数组
* @return 解码后的数字
*/
public static long vbeDecode(List<Byte> bytes){
long result = 0;
for (int i = 0; i < bytes.size(); i++) {
byte b = bytes.get(i);
result = (result << 7) + (b & 0x7F);
}
return result;
}
/**
* 对多个数字进行变长解码
* @param bytes 变长编码的字节数组
* @return 解码后的多个数字
*/
public static List<Long> vbeDecodeNumbers(List<Byte> bytes){
List<Long> result = new ArrayList<>();
long number = 0;
for (int i = 0; i < bytes.size(); i++) {
byte b = bytes.get(i);
number = (number << 7) + (b & 0x7F);
if ((b & 0x80) != 0) {
result.add(number);
number = 0;
}
}
return result;
}
/**
* byte转二进制字符串
* @param b byte数字
* @return 二进制字符串
*/
private static String byteToBinary(byte b) {
return String.format("%8s", Integer.toBinaryString(b & 0xFF)).replace(' ', '0');
}
}5. Lucene实践
本小节介绍如何使用Lucene进行倒排索引与搜索的实践。
5.1 术语解析
在进行实践之前,先了解一下Lucene中的基本概念:
Index:索引,指的就是倒排索引;
Document:文档,文档可以理解为关系表中的一行数据,在一个索引Index中可以包含多个文档,当一个文档被放入索引时,会为文档分配一个序列号(Sequence Number,也叫DocID);
Field:字段,字段可以理解为关系表中的列,一个文档可以包含多个字段,字段是最小的数据单元;
Segment:段,一个索引Index包含一个或多个段,每个段可以理解为一个子索引,段内有自己的索引、文档并且可以搜索。
当我们将文档写入索引时,实际上是将文档写入内存中的缓冲区,当缓冲区容量达到一定阈值后,就会将缓冲区内的文档刷新保存到磁盘上,形成一个段,在刷新时,会构建倒排索引保存到段内。
在段内的文档,不可以被修改,可以被删除,但是删除方式是将要删除的文档ID(DocID)保存到另外的文件内,使用这种方式是避免随机IO,提高效率。
如果文档还在内存中的缓冲区,那么这些文档不能被搜索(因为倒排索引是在缓冲区刷新到磁盘形成段才形成的),所以Lucene提供的是近实时的查询,而不是实时的查询。
段是Lucene中索引保存形式的具体实现,当我们搜索时,是针对索引进行搜索的,所以Lucene需要遍历每个段的内容,对结果进行合并、处理删除的文档,所以,为了提高效率,Lucene会将多个段合并为一个段,在合并时,就会剔除掉被删除的文档。
DocID:文档ID,在将文档加入到索引时,由Lucene分配,但是,需要注意的是,DocID是段内唯一的,而不是索引内唯一的,也就是说,假设现在有两个段,段1内有100个文档,段2内有100个文档,在段1内的DocID,取值为
[1-100],段2内的DocID取值同样是[1-100]。那如何将DocID转换为索引层面上唯一的呢?其实只需要在段2内的DocID加上段1的文档数量即可,例如,段1的DocID转换为索引唯一ID,结果为
[1-100],段2的DocID转换为索引唯一ID,那么结果需要加上段1内的文档数量,结果为[101-200],假设现在段3内有150个文档,那么段3的DocID转换为索引唯一ID,需要加上段1+段2内的文档数量,结果为[200-350],依次类推。当段进行合并后,文档的DocID会发生改变,所以DocID是Lucene内部使用的,我们不能基于DocID进行文档判定和处理。
5.2 构建倒排索引
本小节使用Lucene创建索引,首先,将参考资料中的数据导入数据库:
bash
mysql -u 用户名 -p
source /path-to-your-sql/xxx.sql;然后我们在Java代码中通过连接数据库的方式,从数据库获取数据,并转换为文档,写入索引中。
使用classicmodels.products表,结构如下:
java
@Data
@TableName("classicmodels.products")
public class Product {
@TableId(value = "productCode", type = IdType.INPUT)
private String productCode;
@TableField("productName")
private String productName;
@TableField("productLine")
private String productLine;
@TableField("productScale")
private String productScale;
@TableField("productVendor")
private String productVendor;
@TableField("productDescription")
private String productDescription;
@TableField("quantityInStock")
private Integer quantityInStock;
@TableField("buyPrice")
private BigDecimal buyPrice;
@TableField("MSRP")
private BigDecimal MSRP;
}然后编写测试编码,构建索引:
java
@SpringBootTest
@ContextConfiguration(classes = DemoApplication.class)
public class SaveDocumentExample {
@Autowired
private ProductMapper productMapper;
@Test
public void saveDocument() throws IOException {
List<Product> products = productMapper.selectList(null);
saveDocument(products);
}
private void saveDocument(List<Product> products) throws IOException {
// 创建索引目录
FSDirectory directory = FSDirectory.open(Paths.get("product_index"));
// 创建标准分词器
StandardAnalyzer analyzer = new StandardAnalyzer();
运行测试代码后,在项目下会生成一个名为product_index的文件夹,这就是Lucene的索引目录。

为了后续演示,我们再创建一个名为product_index_1的索引,该索引是通过分批写入文档创建而来的,代码如下:
java
@Test
public void saveDocument() throws IOException {
List<Product> products = productMapper.selectList(null);
// 分批写入文档,每批10个文档
int batchSize = 10;
for (int i = 0; i < products.size(); i += batchSize) {
List<Product> batch = products.subList(i, Math.min(i + batchSize, products.size()));
saveDocument(batch);
}
//saveDocument(products);
}创建结果如下:
5.3 Field解析
5.3.1 三个重要的属性
当我们构建文档时,会往文档中添加多个字段Field,本文介绍Field的特性。
Field是文档(Document)的基本组成单元,代表了文档中的一块信息,例如标题、正文、作者、创建日期等。每个Field都由一个名称(name)和一个值(value)组成。然而,一个Field的行为远不止于此,其核心在于一系列控制其如何被索引、存储和用于搜索的属性。
在Lucene中,Field类关键属性如下:
java
public class Field implements IndexableField {
protected final IndexableFieldType type;
protected final String name;
protected Object fieldsData;
}name:定义了字段的名称;fieldsData:定义了字段的值;type:定义了字段的属性;其实现类FieldType提供了关于Field字段的多种控制。
java
public class FieldType implements IndexableFieldType {
private boolean stored;
private boolean tokenized = true;
private boolean storeTermVectors;
private boolean storeTermVectorOffsets;
private boolean storeTermVectorPositions;
private boolean storeTermVectorPayloads;
private boolean omitNorms;
private IndexOptions indexOptions = IndexOptions.NONE;
private boolean frozen;
private DocValuesType docValuesType = DocValuesType.NONE;
private int dimensionCount;
private int indexDimensionCount;
private int dimensionNumBytes;
private int vectorDimension;
private VectorEncoding vectorEncoding = VectorEncoding.FLOAT32;
private VectorSimilarityFunction vectorSimilarityFunction = VectorSimilarityFunction.EUCLIDEAN;
private Map<String, String> attributes;
}首先我们介绍三个重点属性:
- stored:表示该字段是否被存储,也就是说,如果文档中的该字段设置为不存储,那么从Lucene中查出该文档后,该文档没有该字段;
- tokenized:表示该字段是否被分词;
- indexOptions:这是一个枚举值,表示该字段是否被索引,换句话说,该字段的内容(不管是分词前的原始内容还是分词后的词元)是否会被放入倒排索引的词典中,取值如下:
NONE:不索引;DOCS:索引,但是在posting list中只存储文档ID,即DocID;DOCS_AND_FREQS:索引,在posting list中存储DocID和词频(也就是说该词元在字段值中出现的次数);DOCS_AND_FREQS_AND_POSITIONS:索引,在posting list中存储DocID、词频和位置;DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:索引,在posting list中存储DocID、词频、位置和偏移量;
这三个重点属性,可以组成一个三元组,形成不同的搭配(对于是否被索引,我们只关注是与否,而不关注索引存储的内容),三元组完整列表如下(0表示否,1表示是):
| stored 是否存储 | tokenized 是否分词 | indexed 是否索引 | 是否有意义 | 备注 |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 该字段既不存储,也不索引 |
| 0 | 0 | 1 | 1 | 不存储,但是可以通过该字段找到文档, 例如,文章内容很长,如果存储会浪费大量空间,如果只想要lucene提供搜索功能,之后通过文章ID从数据库获取文章内容,那么就可以 |
| 0 | 1 | 0 | 0 | 不存储,不索引,无意义 |
| 0 | 1 | 1 | 1 | 同2 |
| 1 | 0 | 0 | 1 | 有意义,对于某些字段,例如URL, 有必要存下来,但是一般不会根据该字段进行检索 |
| 1 | 0 | 1 | 1 | 有意义,对于商品编码、ID这类字段, 不需要分词,但是需要通过这些字段检索文档 |
| 1 | 1 | 0 | 0 | 无意义,分词的目的是为了检索,如果只分词不检索,只会浪费CPU |
| 1 | 1 | 1 | 1 | 有意义,对于长文本,进行分词检索非常必要,这也是搜索提出的目的 |
综上所属,有5种有效的配置(要么提供存储功能,要么提供检索功能):
不存储,不分词,检索
不存储,分词,检索;
存储,不分词,不检索;
存储,不分词,检索;
存储,分词,检索;
基于以上属性的取值不同,Lucene定义了很多Field的子类,例如:
java
public final class StringField extends Field {
// 不存储(默认值)、不分词,检索
public static final FieldType TYPE_NOT_STORED = new FieldType();
// 存储,不分词,检索
public static final FieldType TYPE_STORED = new FieldType();
static {
TYPE_NOT_STORED.setOmitNorms(true);
TYPE_NOT_STORED.setIndexOptions(IndexOptions.DOCS);
TYPE_NOT_STORED.setTokenized(false);
TYPE_NOT_STORED.freeze();
TYPE_STORED.setOmitNorms(true);
TYPE_STORED.setIndexOptions(IndexOptions.DOCS);
TYPE_STORED.setStored(true);
TYPE_STORED.setTokenized(false);
TYPE_STORED.freeze();
}
private BytesRef binaryValue;
private final StoredValue storedValue;
public StringField(String name, String value, Store stored) {
super(name, value, stored == Store.YES ? TYPE_STORED : TYPE_NOT_STORED);
binaryValue = new BytesRef(value);
if (stored == Store.YES) {
storedValue = new StoredValue(value);
} else {
storedValue = null;
}
}
}java
public final class TextField extends Field {
// 不存储、分词、索引
public static final FieldType TYPE_NOT_STORED = new FieldType();
// 存储、分词、索引
public static final FieldType TYPE_STORED = new FieldType();
static {
TYPE_NOT_STORED.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS);
TYPE_NOT_STORED.setTokenized(true);
TYPE_NOT_STORED.freeze();
TYPE_STORED.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS);
TYPE_STORED.setTokenized(true);
TYPE_STORED.setStored(true);
TYPE_STORED.freeze();
}
private final StoredValue storedValue;
public TextField(String name, String value, Store store) {
super(name, value, store == Store.YES ? TYPE_STORED : TYPE_NOT_STORED);
if (store == Store.YES) {
storedValue = new StoredValue(value);
} else {
storedValue = null;
}
}
}5.3.2 DocValuesType属性
在FieldType类中,还存在一个重要属性docValuesType:
java
private DocValuesType docValuesType = DocValuesType.NONE;如果某个字段设置了DocValuesType属性,那么Lucene就会为该字段设置一个从 docID 到字段值的映射(DocValues),例如,现在有一个字段值为numeric类型,那么映射可能如下:
txt
DocID(1) --> 1000.0
DocID(2) --> 2899.0
DocID(3) --> 10000.0
DocID(4) --> 999.9
DocID(5) --> 1200.0DocValues的作用是加快排序、聚合和范围查询。
假如我们的需求是找出商品描述包含“手机”的商品,并且按照商品的价格进行排序,返回价格最低的10件商品。
如果现在只有倒排索引,那么过程如下:
- 首先,在倒排索引中找到“手机”这个词元对应的posting list,假设其中包含5000个posting,也就是说有5000个文档包含“手机”关键字;
- 之后要对这5000个商品进行价格排序,那么就需要从磁盘文件中读取这5000个文档的内容,从文档中获取价格,然后按照这些价格进行排序返回;
- 可想而之,进行5000次随机磁盘IO,速度非常慢,查询效率不可接受;
如果现在有DocValues,那么查询和排序过程如下:
- 首先,在倒排索引中找到“手机”这个词元对应的posting list,假设其中包含5000个posting,也就是说有5000个文档包含“手机”关键字;(这一步相同);
- 然后,将对应的商品价格
DocValues从磁盘加载到内存中,并通过DocID从DocValues中获取价格,对这些价格进行排序,这一步只涉及1次随机磁盘IO,之后都是内存操作; - 最后,通过排好序的DocID,进行10次随机磁盘IO,返回文档内容;
可以发现,有了DocValues,排序效率大大提升。
由于Lucene中的索引包含多个段,每个段的排序返回结果最终会被合并和重新排序,以生成最终的全局排序返回结果。
DocValuesType是一个枚举值,取值如下:
NONE:不建立从文档ID到字段值的映射,这是默认值;当一个字段只用于搜索(通过倒排索引),而不需要进行排序、聚合或范围查询时,选择该选项;
例如,一篇新闻文章的正文字段,希望用户能够搜索正文内容,但通常不会根据正文内容来排序或聚合。
NUMERIC:用于对每个字段都只有一个值的数值类型字段(如整数、浮点数)进行排序、聚合和高效的范围查询;例如,销量字段
sales: 1024,可以按销量排序,或找出销量最高的商品。BINARY:用于存储每个字段的一个原始二进制数据块。这种类型不进行排序,但可以用来存储一些非文本但又需要通过文档ID获取的原始数据。SORTED:用于对每个字段都只有一个值的字符串字段进行排序和分组。它的实现方式是为所有唯一的字符串创建一个有序的“值池”,然后每个文档只存储一个指向这个值池的索引,从而节省空间。
例如,为作者字段
author: "Alice"创建DocTypes,可以按作者姓名对文章进行排序。SORTED_NUMERIC:用于对每个字段都包含多个数值的字段进行聚合。由于一个文档可以有多个值,它不支持直接排序,但可以用于聚合计算(如统计总和、平均值等)。
例如,用户评分
user_ratings: [5, 4, 5, 3],可以计算一个产品的平均用户评分。SORTED_SET:用于对每个字段都包含多个字符串值的字段进行聚合和分组,这是实现多值标签聚合统计的理想选择。例如,文章标签
tags: ["科技", "AI", "未来"],可以统计每个标签下的文章数量,找出最受欢迎的标签。
IMPORTANT
由于DocValues要求数据类型强一致性,所以要求设置DocValues的字段值的数据类型要相同。
在Lucene中,基于DocValuesType的设置不同,也定义了一些字段类,例如:
java
public class NumericDocValuesField extends Field {
public static final FieldType TYPE = new FieldType();
static {
// 设置DocValuesType为NUMERIC
TYPE.setDocValuesType(DocValuesType.NUMERIC);
TYPE.freeze();
}
public NumericDocValuesField(String name, Long value) {
super(name, TYPE);
fieldsData = value;
}
}TIP
由于字段的DocValuesType和是否存储、索引等属性是相互独立的,所以如果需要存储、索引该字段,需要单独设置,如下:
java
// 设置price字段的DocValues属性
document.add(
new NumericDocValuesField(
"price",
product.getBuyPrice().multiply(new BigDecimal(100)).longValue()));
// 设置price字段需要存储
document.add(
new StoredField(
"price",
product.getBuyPrice().multiply(new BigDecimal(100)).longValue()));如果需要其他属性,例如分词、索引等,还可以使用其他Field实现类。
5.4 搜索/查询
5.4.1 查询基本框架
下面列出Lucene中查询的基本框架:
java
public class GoodsSearchExample {
public static void main(String[] args) throws Exception {
// 打开索引
FSDirectory directory = FSDirectory.open(Paths.get("product_index"));
// 创建索引读取器
IndexReader reader = DirectoryReader.open(directory);
// 创建查询解析器
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询条件
Query quantityInStockQuery = LongField.newExactQuery("quantityInStock", 68);
// 执行查询
TopDocs results = searcher.search(quantityInStockQuery, 10);
// 输出结果
System.out.println("Total hits: " + results.totalHits);
for (ScoreDoc scoreDoc : results.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
// 输出分数
System.out.println(scoreDoc.score);
// 输出文档内容
System.out.println(doc);
}
// 关闭资源
reader.close();
directory.close();
}
}大致步骤如下:
- 打开索引,创建索引读取器;
- 创建查询解析器;
- 构建查询条件;
- 执行查询,解析结果;
在下面的内容中,我们主要关注如何构建不同的查询条件。
5.4.2 等值查询
对于数值类型,在IntField、LongField、FloatField、DoubleField这些类中,定义了静态方法,可以构建数值类型的等值查询,例如:
java
Query quantityInStockQuery = LongField.newExactQuery("quantityInStock", 68);
// 执行查询
TopDocs results = searcher.search(quantityInStockQuery, 10);对于字符串类型,可以使用TermQuery来构建,如下:
java
TermQuery productCodeQuery = new TermQuery(new Term("productCode", "S10_1678"));
// 执行查询
TopDocs results = searcher.search(productCodeQuery, 10);5.4.3 范围查询
对于数值类型,在IntField、LongField、FloatField、DoubleField这些类中,定义了静态方法,可以构建数值类型的范围查询,例如:
java
Query quantityInStock = LongField.newRangeQuery("quantityInStock", 68, 1000);
// 执行查询
TopDocs results = searcher.search(quantityInStock, 10);5.4.4 IN 查询
对于数值类型,如果要实现IN查询,在IntField、LongField、FloatField、DoubleField这些类中,同样定义了静态方法,例如:
java
Query quantityInStockInQuery = LongField.newSetQuery("quantityInStock", 68, 737, 551);
// 执行查询
TopDocs results = searcher.search(quantityInStockInQuery, 10);对于字符串类型,如果要实现IN查询,可以使用替代形式 OR 查询,具体查看复杂查询。
5.4.5 全文查询
对于全文查询,即构建倒排索引的初衷,具体可构建如下:
java
// 指定需要查询的字段,以及分词器
QueryParser queryParser = new QueryParser("productDesc", new StandardAnalyzer());
// 指定查询条件
Query query = queryParser.parse("wheel door");
// 执行查询
TopDocs results = searcher.search(query, 10);5.4.6 复杂查询
复杂查询是指多个查询组合而成的查询,我们可以使用BooleanQuery来构建,如下:
java
// 全文查询条件
QueryParser queryParser = new QueryParser("productDesc", new StandardAnalyzer());
Query query = queryParser.parse("wheel door");
// 等值查询条件
Query quantityInStockQuery = LongField.newExactQuery("quantityInStock", 68);
// 复杂查询条件
BooleanQuery booleanQuery = new BooleanQuery.Builder()
.add(query, BooleanClause.Occur.MUST)
.add(quantityInStockQuery, BooleanClause.Occur.MUST)
.build();
// 执行查询
TopDocs results = searcher.search(booleanQuery, 10);在构建复杂查询条件时,各个查询条件如何关联,由BooleanClause.Occur取值决定,取值如下:
MUST:文档必须匹配此子查询,如果一个文档不满足MUST子句,该文档将不会出现在最终的搜索结果中。示例:
BooleanQuery.Builder().add(query1, Occur.MUST).add(query2, Occur.MUST)等同于query1 AND query2,只有同时满足query1和query2的文档才会被返回。SHOULD:文档应该匹配此子查询,SHOULD子句是可选的,它不影响文档是否被返回,但会影响文档的得分,也就是说:不匹配
SHOULD子查询条件的文档也可以被返回,不过得分较低;匹配
SHOULD子句的文档会获得更高的相关性分数,从而在结果列表中排名更靠前;
示例:
BooleanQuery.Builder().add(query1, Occur.SHOULD).add(query2, Occur.SHOULD)等同于query1 OR query2。文档只需满足其中一个查询即可被返回,但同时满足两者的文档得分会更高。特别注意: 如果一个
BooleanQuery中只包含SHOULD子句,则至少需要匹配一个子句才能返回结果。但如果已经有MUST或FILTER子句,SHOULD子句就只起到加分作用。MUST_NOT:文档必须不匹配此子查询,任何匹配MUST_NOT子句的文档都会被排除在搜索结果之外。MUST_NOT不影响得分,只用于过滤。示例:
BooleanQuery.Builder().add(query1, Occur.MUST).add(query2, Occur.MUST_NOT)等同于query1 AND NOT query2。文档必须匹配query1,同时不能匹配query2。特别注意:
MUST_NOT不能单独使用。一个只包含MUST_NOT子句的BooleanQuery不会返回任何结果,因为它没有“肯定”的匹配条件。它必须与MUST或SHOULD子句结合使用。FILTER: 文档必须匹配此子查询,并且其得分不参与计算。FILTER子句的行为类似于MUST,它是一个硬性过滤条件。但它有一个关键区别:它对文档的得分没有影响。也就是说,一个文档必须满足FILTER条件才会出现在结果中,但是其得分不会增加。示例:
BooleanQuery.Builder().add(query1, Occur.MUST).add(query2, Occur.FILTER)。文档必须同时匹配query1和query2,但最终得分只由query1决定。
5.4.7 短语查询
所谓短语查询,是指两个词必须挨在一起才能匹配上的查询。例如,现在提供的查询短语是blue book,那么只有文档中的内容包含blue book这个短语,才能匹配上,如果是book which is blue这样的形式,在之前的全文查询中可以匹配,但是在短语查询中无法匹配。
短语查询的使用方式如下:
java
PhraseQuery.Builder builder = new PhraseQuery.Builder();
builder.add(new Term("content", "blue"));
builder.add(new Term("content", "book"));
builder.setSlop(2);
PhraseQuery query = builder.build();在第5行,我们设置了slop,这表示blue和book之间最多可以分隔2个词,也就是说blue wonderful book也能匹配上查询短语blue book。
我们也可以使用QueryParser来构建短语查询:
java
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query query = parser.parse("\"blue book\"~2");当在查询字符串中用双引号将词语括起来时,QueryParser 会自动将其解析为 PhraseQuery。如果要设置slop,则在查询短语后用~表示要设置的slop。
MultiPhraseQuery 是一种强大的查询类型,它允许在一个短语查询中为特定位置指定多个可能的词语。
例如,如果想搜索 "Java and Python" 或 "Java or Python",那么使用 MultiPhraseQuery 就非常合适,它可以在第二个位置匹配 "and" 或 "or" 这两个词。
MultiPhraseQuery 继承自 PhraseQuery,但它在每个位置上可以添加一个或多个 Term,可以将其视为一个拥有多个“词语集”的短语查询。
add(Term term): 与PhraseQuery相同,向下一个位置添加一个单独的词。add(Term[] terms): 这是MultiPhraseQuery独有的方法,它向下一个位置添加一个词语数组。这意味着该位置的文档必须包含数组中的任一词语才能匹配。add(Term[] terms, int position): 允许在指定的位置添加词语数组,这使得可以跳过某些位置(也就是说,被跳过的位置可以是任何词)。
java
MultiPhraseQuery.Builder builder = new MultiPhraseQuery.Builder();
builder.add(new Term[]{new Term("content", "great"), new Term("content", "good")});
builder.add(new Term("content", "book"));
MultiPhraseQuery query = builder.build();如上面的例子,可以匹配great book和good book。
5.5 删除与更新文档
5.5.1 删除文档
在Lucene中,删除文档可以通过两种方式:
java
// 基于Term的删除
public long deleteDocuments(Term... terms);
// 基于Query的删除
public long deleteDocuments(Query... queries);IMPORTANT
注意,返回值并不代表删除的文档数量,而是 Returns: The sequence number for this operation。所以,一般情况下,我们不需要返回值。
在使用上推荐使用基于Query的删除。
演示基于Query的删除:
java
public class DeleteDocumentExample {
public static void main(String[] args) throws IOException {
FSDirectory directory = FSDirectory.open(Paths.get("product_index"));
IndexWriter writer = new IndexWriter(directory, new IndexWriterConfig());
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 构建查询条件
BooleanQuery booleanQuery = new BooleanQuery.Builder()
.add(new TermQuery(new Term("productCode", "S18_3856")), BooleanClause.Occur.SHOULD)
.add(new TermQuery(new Term("productCode", "S18_4027")), BooleanClause.Occur.SHOULD)
.build();
// 删除前,查询满足条件的文档数
TopDocs topDocs1 = searcher.search(booleanQuery, 10);
System.out.println("删除前--查询结果总数: " + topDocs1.totalHits);
// 删除满足条件的文档并提交删除操作
writer.deleteDocuments(booleanQuery);
writer.commit();
writer.close();
// 删除后,再次查询满足条件的文档数
reader = DirectoryReader.openIfChanged(reader);
searcher = new IndexSearcher(reader);
TopDocs topDocs2 = searcher.search(booleanQuery, 10);
System.out.println("删除后--查询结果总数: " + topDocs2.totalHits);
reader.close();
directory.close();
}
}结果为:
txt
删除前--查询结果总数: 2 hits
删除后--查询结果总数: 0 hits在上面的例子中,需要注意的是,删除后需要再次获取新的索引读取器,否则删除后,仍然能查询到被删除的文档,原因如下:
IndexReader 负责读取索引,当一个 IndexReader 实例被创建时,它会获得索引在那一时刻的一个快照。这个快照包含了所有已提交的文件段(Segment),以及每个文件段中被标记为删除的文档列表。
当执行删除操作后,如果不重新获取IndexReader,那么删除操作对旧的 IndexReader 是不可见的,因为它还在使用它创建时的那个旧快照。因此无法感知到删除操作。
所以,在每次写入操作并提交后,索引读取器(IndexReader)必须刷新或重新打开,以获取最新的索引状态。推荐使用 DirectoryReader.openIfChanged() 获取最新的索引读取器。
5.5.2 更新文档
在Lucene中,其实并不允许在原地更新文档,所谓的更新文档分为两步:
- 根据查询条件删除文档;
- 将新文档加入到索引中;
在Lucene中,提供了updateDocuments()方法将上述两步组合原子操作,演示如下:
java
public class UpdateDocumentsExample {
public static void main(String[] args) throws IOException {
FSDirectory directory = FSDirectory.open(Paths.get("product_index"));
IndexWriter writer = new IndexWriter(directory, new IndexWriterConfig());
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询条件
TermQuery query = new TermQuery(new Term("productCode", "S24_1578"));
// 更新前查询文档并显示
TopDocs topDocs = searcher.search(query, 10);
System.out.println("-----更新前文档-----");
showDocment(searcher, topDocs);
// 构建更新的文档
Document updateDoc = new Document();
updateDoc.add(new StringField("update", "yyyes", Field.Store.YES));
updateDoc.add(new StringField("productCode", "S24_1578", Field.Store.YES));
// 更新文档
writer.updateDocuments(query, List.of(updateDoc));
writer.commit();
writer.close();
// 更新后查询文档并显示
reader = DirectoryReader.openIfChanged(reader);
searcher = new IndexSearcher(reader);
System.out.println("-----更新后文档-----");
topDocs = searcher.search(query, 10);
showDocment(searcher, topDocs);
reader.close();
directory.close();
}
private static void showDocment(IndexSearcher searcher, TopDocs topDocs) throws IOException {
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = searcher.storedFields().document(scoreDoc.doc);
System.out.println(document);
}
}
}结果如下:
txt
-----更新前文档-----
Document<stored,indexed,tokenized,omitNorms,indexOptions=DOCS<productCode:S24_1578> stored,indexed,tokenized<productName:1997 BMW R 1100 S> stored,indexed,tokenized<productDesc:Detailed scale replica with working suspension and constructed from over 70 parts> stored<quantityInStock:7003> stored<price:6086>>
-----更新后文档-----
Document<stored,indexed,tokenized,omitNorms,indexOptions=DOCS<update:yyyes> stored,indexed,tokenized,omitNorms,indexOptions=DOCS<productCode:S24_1578>>IMPORTANT
注意,updateDocuments()方法中,第二个参数传入的是文档列表,这是因为更新操作是先删除后新增,新增可以多个,所以是传入多个文档。
5.6 查看倒排索引
本小节介绍如何在Java代码中查看倒排索引的结构。
代码如下:
java
public class IndexInspector {
public static void main(String[] args) throws Exception {
// 1. 打开索引目录
Directory directory = FSDirectory.open(Paths.get("product_index"));
try (IndexReader reader = DirectoryReader.open(directory)) {
// 2. 遍历索引中的每个段 (Segment)
for (LeafReaderContext leafContext : reader.leaves()) {
LeafReader leafReader = leafContext.reader();
System.out.println("============== Segment ==============");
System.out.println("最大文档数(包含删除的):" + leafReader.maxDoc());
System.out.println("有效文档数:" + leafReader.numDocs());
System.out.println("删除的文档数:" + leafReader.numDeletedDocs());
// 3. 获取指定字段的词典信息
// 假设我们要查看 "productDesc" 字段
Terms terms = leafReader.terms("productDesc");
if (terms != null) {
// 4. 获取词典的迭代器
TermsEnum termsEnum = terms.iterator();
System.out.println("Term | Doc Freq");
System.out.println("----------------------------------");
// 5. 遍历词典中的每一个词项
BytesRef term;
while ((term = termsEnum.next()) != null) {
String termText = term.utf8ToString();
int docFreq = termsEnum.docFreq(); // 获取文档频率
System.out.printf("%-20s | %d\n", termText, docFreq);
// 6. 遍历该词项的倒排列表
PostingsEnum postingsEnum = termsEnum.postings(null, PostingsEnum.ALL);
int docId;
while ((docId = postingsEnum.nextDoc()) != PostingsEnum.NO_MORE_DOCS) {
int freq = postingsEnum.freq(); // 获取词频 (TF)
System.out.printf(" -> Doc ID: %d, TF: %d\n", docId, freq);
// 遍历位置信息
for (int i = 0; i < freq; i++) {
int position = postingsEnum.nextPosition();
System.out.printf(" -> Position: %d\n", position);
}
}
}
}
}
}
}
}部分结果如下:
txt
============== Segment ==============
最大文档数(包含删除的):110
有效文档数:106
删除的文档数:4
Term | Doc Freq
----------------------------------
1 | 32
-> Doc ID: 3, TF: 1
-> Position: 51
-> Doc ID: 10, TF: 1
-> Position: 0
-> Doc ID: 11, TF可以看到,在第一个段内,总文档数为110个,其中有效的文档数为106个。之后就是分词后的词元信息,列出了该词元在哪个文档中又出现,并且词频和位置也一并列出了。
5.7 DocValuesType实践
我们以SortedNumericDocValuesField为例,介绍DocValuesType的使用。
首先,SortedNumericDocValuesField代表包含多个数值,但是,在文档中添加时,并不是以数组的形式添加字段,而是多次添加。
java
private static Directory saveIndex() throws IOException {
Directory directory = FSDirectory.open(Paths.get("index_demo_01"));
IndexWriterConfig config = new IndexWriterConfig();
IndexWriter writer = new IndexWriter(directory, config);
Document doc1 = new Document();
doc1.add(new StringField("userId", "101", Field.Store.YES));
doc1.add(new SortedNumericDocValuesField("userRatings", 5));
doc1.add(new SortedNumericDocValuesField("userRatings", 10));
doc1.add(new SortedNumericDocValuesField("userRatings", 5));
doc1.add(new SortedNumericDocValuesField("userRatings", 3));
writer.addDocument(doc1);
Document doc2 = new Document();
doc2.add(new StringField("userId", "102", Field.Store.YES));
doc2.add(new SortedNumericDocValuesField("userRatings", 2));
doc2.add(new SortedNumericDocValuesField("userRatings", 1));
writer.addDocument(doc2);
writer.commit();
writer.close();
directory.close();
return directory;
}之后,我们就可以查看DocValuesType。
java
private static void checkDocValues() throws IOException {
Directory directory = FSDirectory.open(Paths.get("index_demo_01"));
IndexReader reader = DirectoryReader.open(directory);
reader.leaves().forEach(leaf -> {
// 获取segment读取器
LeafReader leafReader = leaf.reader();
int docs = leafReader.numDocs();
System.out.println("Segment中文档数量:" + docs);
for (int i = 0; i < docs; i++) {
try {
// 获取 SortedNumericDocValues
SortedNumericDocValues ratingsDocValues = leafReader.getSortedNumericDocValues("userRatings");
// 移动到当前文档的DocValues值
if (ratingsDocValues != null && ratingsDocValues.advanceExact(i)) {
System.out.println("SortedNumericDocVales数量:" + ratingsDocValues.docValueCount());
long sum = 0;
int count = 0;
// 遍历该文档的所有评分
for (int j = 0; j < ratingsDocValues.docValueCount(); j++) {
long rating = ratingsDocValues.nextValue();
System.out.print(rating+" ");
sum += rating;
count++;
}
System.out.println();
double averageRating = (double) sum / count;
System.out.println("DocID: " + i + " 的平均评分是: " + String.format("%.2f", averageRating));
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
});
reader.close();
directory.close();
}结果如下:
txt
Segment中文档数量:2
SortedNumericDocVales数量:4
3 5 5 10
DocID: 0 的平均评分是: 5.75
SortedNumericDocVales数量:2
1 2
DocID: 1 的平均评分是: 1.50可以发现,在SortedNumericDocVales中的数字,都是按照从小到大的顺序排列的。
ratingsDocValues.advanceExact(int docID) 用于快速访问对应文档的DocValues
5.8 Reader体系
在Lucene中,IndexReader是整个索引读取器的基础,这是一个抽象类。
当一个 IndexReader 被创建时,它会获得索引在那一刻的一个快照(Snapshot),这个快照包含了所有已提交(Committed)的文件段。当IndexReader被创建打开后,IndexWriter对索引的更改操作,对已打开的Reader是不可见的,当需要这些更改可见时,需要重新打开读取器,或者使用如 public static DirectoryReader openIfChanged(DirectoryReader oldReader )的方法,以获取更高的性能。
IndexReader有两种类型:
LeafReader:LeafReader代表一个单一的、不可分割的文件段(segment)。一个 Lucene 索引由一个或多个文件段组成,每个文件段都是一个独立的、功能完整的索引。LeafReader就是访问这些独立小索引的接口。它提供了直接访问索引底层所有数据结构的能力,我们可以直接通过
LeafReader获取:- Stored fields (存储字段):
LeafReader.document(int docID)。 - Doc values (文档值):
LeafReader.getNumericDocValues(String field)等。 - Terms (词条):
LeafReader.terms(String field),这是倒排索引的关键。 - Postings (倒排列表):
TermsEnum接口,可以获取哪些文档包含某个词条。
- Stored fields (存储字段):
CompositeReader:CompositeReader不直接读取索引数据,而是由一个或多个LeafReader或其他CompositeReader组成。它像一个路由器,将读取请求分发给其内部的子读取器(Sub-readers)。它只能提供一些高层、聚合性的信息,例如:
- 文档总数:
CompositeReader.numDocs()。 - 存储字段:
CompositeReader.document(int docID)。它会根据文档 ID 找到正确的子读取器,然后让子读取器来获取字段。
DirectoryReader是CompositeReader的一个典型实现。它代表整个索引,这个索引可能包含多个文件段,每个文件段都对应一个LeafReader。DirectoryReader将请求路由到正确的LeafReader上。- 文档总数:
6. 相关度算法
假设现在有一个很大的文档集,满足查询条件的文档有成千上万个,将所有满足查询条件的文档全部返回给用户,显然是不合适的,因此,需要将最合适的数个数十个文档返回给用户,如何判断哪些文档是用户最想要的,那么评判文档与查询条件的相关度就显得很必要了,这就是相关度算法的作用,为查询条件q和文档d的组合(q,d)给出一个分数,分数越大,表示该文档越匹配查询条件,因此应该返回给用户。
6.1 模型介绍
6.1.1 TF_IDF
TF-IDF(term frequency–inverse document frequency)是一种用于计算某个词元在一个文档中评分的计算方法。它通过词频(TF)和逆文档频率(IDF)两个指标的乘积来计算,其中TF表示词在文档中出现的次数与文档总词数的比值,而IDF表示词的稀有程度。TF-IDF值越大,说明该词在文档中越重要。
首先定义词频:
逆文档频率的提出,是因为各个词元的重要性不想等,例如,"的"、"是"这样的词几乎每篇文档都有,无法区分文档,重要性偏低,而"人工智能"、"好莱坞"这样的词只在特定领域的文档中才会出现,对文档区分度较高,因此重要性较高。
假设文档集中文档总数为N,在文档集中包含某词元x的文档数为
则TF- IDF计算如下:
对于某个查询q,可能包含多个词元,设包含的词元集合为Q,则最终该查询q与文档t的TF- IDF计算如下:
6.1.2 BM25
BM25(Best Matching 25)是一种用于信息检索(Information Retrieval)和文本挖掘的算法,它被广泛应用于搜索引擎和相关领域。BM25 基于 TF-IDF(Term Frequency-Inverse Document Frequency)的思想,但对其进行了改进以考虑文档的长度等因素。
完整的BM25算法如下:
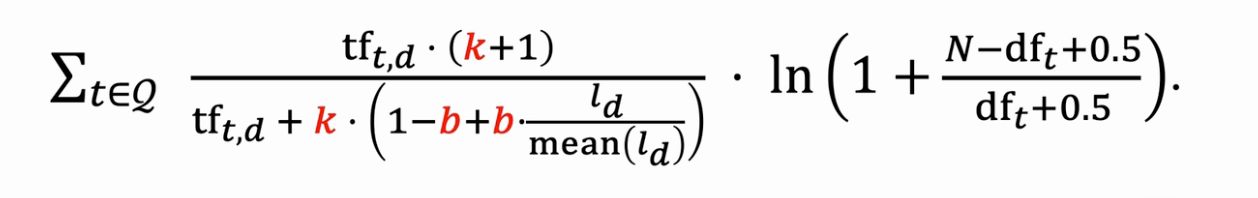
其中:
- Q 表示由查询词q划分出的词元集合;
- t 表示查询词切分后的词元;
表示词元t在文档d中的出现次数; 表示文档d的词元长度; 表示文档集的平均文档长度; 表示包含该词元t的文档数; - N 表示整个文档集的文档数量;
- k, b 是自定义参数,是为了最佳化(optimization)而设计的参数,通常 k 会在 1.2 - 2.0 之间, b 则是在 0 - 1 之间,通常预设为 0.75。在数学意义上,k是决定词元出现次数到底重不重要的参数,0表示不重要,1表示重要;b 是决定文件长度到底重不重要的参数,0表示不重要,1表示重要。
6.1.3 词距模型
TF-IDF和BM25都是词袋模型,也就是说只考虑词频,不考虑顺序和上下文。
词距模型不仅考虑词的频率,还考虑词与词在文档之间的距离,距离越近,代表匹配度越高,相关性得分越高。
6.2 Lucene实践
本小节介绍在Lucene中是怎样为查询条件和文档进行打分的。
6.2.1 默认实现
在Lucene中,对文档相关性得分进行计算的类是org.apache.lucene.search.similarities.Similarity,有多种实现,从Lucene 6.0开始,默认使用BM25Similarity实现类计算文档得分。
在Lucene中,我们可以使用searcher.explain来查看得分计算过程:
java
private static void search() throws IOException, ParseException {
FSDirectory directory = FSDirectory.open(Paths.get("index_demo_02"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query query = parser.parse("great book");
TopDocs topDocs = searcher.search(query, 10);
System.out.println("Total hits: " + topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("得分:" + scoreDoc.score);
System.out.println("文档内容:" + doc);
System.out.println("解释:");
Explanation explain = searcher.explain(query, scoreDoc.doc);
System.out.println(explain);
}
reader.close();
directory.close();
}部分结果如下:
txt
得分:0.37596816
文档内容:Document<stored<id:1> stored,indexed,tokenized<title:Lucene in Action> stored,indexed,tokenized<content:a Lucene in Action is a great book>>
解释:
0.37596816 = sum of:
0.29767057 = weight(content:great in 0) [BM25Similarity], result of:
0.29767057 = score(freq=1.0), computed as boost * idf * tf from:
0.6931472 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:
1 = n, number of documents containing term
2 = N, total number of documents with field
0.42944783 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:
1.0 = freq, occurrences of term within document
1.2 = k1, term saturation parameter
0.75 = b, length normalization parameter
8.0 = dl, length of field
7.0 = avgdl, average length of field
0.0782976 = weight(content:book in 0) [BM25Similarity], result of:
0.0782976 = score(freq=1.0), computed as boost * idf * tf from:
0.18232156 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:
2 = n, number of documents containing term
2 = N, total number of documents with field
0.42944783 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:
1.0 = freq, occurrences of term within document
1.2 = k1, term saturation parameter
0.75 = b, length normalization parameter
8.0 = dl, length of field
7.0 = avgdl, average length of field可以看到,5-15行,就是计算词元"great"和文档1的相关性得分过程,也就是BM25算法的实现过程。
6.2.2 boost修改得分
在上面的计算公式中,我们发现有boost,这是用于修改文档相关性得分的,也就是说,在BM25算法计算出一个文档得分后,再乘上boost的值,作为最终的文档得分。boost修改得分是通过BoostQuery来实现的,BoostQuery 可以给任何查询应用一个乘法权重:
- 原理:它将 Lucene 基础查询的得分乘以一个浮点数。
- 使用场景:对特定字段、特定词项或整个子查询进行加权。
使用例子如下,假设文档标题具有更高的重要性,我们将其BM25得分乘以10,提升其重要性:
java
private static void search() throws IOException, ParseException {
FSDirectory directory = FSDirectory.open(Paths.get("index_demo_02"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser1 = new QueryParser("title", new StandardAnalyzer());
QueryParser parser2 = new QueryParser("content", new StandardAnalyzer());
Query query1 = parser1.parse("action");
Query query2 = parser2.parse("great book");
BoostQuery boostQuery = new BoostQuery(query1, 10f);
BooleanQuery query = new BooleanQuery.Builder()
.add(boostQuery, BooleanClause.Occur.SHOULD)
.add(query2, BooleanClause.Occur.SHOULD)
.build();
TopDocs topDocs = searcher.search(query, 10);
System.out.println("Total hits: " + topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("得分:" + scoreDoc.score);
System.out.println("文档内容:" + doc);
System.out.println("解释:");
Explanation explain = searcher.explain(query, scoreDoc.doc);
System.out.println(explain);
}
reader.close();
directory.close();
}部分结果如下:
Details
txt
得分:3.526637
文档内容:Document<stored<id:1> stored,indexed,tokenized<title:Lucene in Action> stored,indexed,tokenized<content:a Lucene in Action is a great book>>
解释:
3.526637 = sum of:
3.1506689 = weight(title:action in 0) [BM25Similarity], result of:
3.1506689 = score(freq=1.0), computed as boost * idf * tf from:
10.0 = boost
0.6931472 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:
1 = n, number of documents containing term
2 = N, total number of documents with field
0.45454544 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:
1.0 = freq, occurrences of term within document
1.2 = k1, term saturation parameter
0.75 = b, length normalization parameter
3.0 = dl, length of field
3.0 = avgdl, average length of field
0.29767057 = weight(content:great in 0) [BM25Similarity], result of:
0.29767057 = score(freq=1.0), computed as boost * idf * tf from:
0.6931472 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:
1 = n, number of documents containing term
2 = N, total number of documents with field
0.42944783 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:
1.0 = freq, occurrences of term within document
1.2 = k1, term saturation parameter
0.75 = b, length normalization parameter
8.0 = dl, length of field
7.0 = avgdl, average length of field
0.0782976 = weight(content:book in 0) [BM25Similarity], result of:
0.0782976 = score(freq=1.0), computed as boost * idf * tf from:
0.18232156 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:
2 = n, number of documents containing term
2 = N, total number of documents with field
0.42944783 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:
1.0 = freq, occurrences of term within document
1.2 = k1, term saturation parameter
0.75 = b, length normalization parameter
8.0 = dl, length of field
7.0 = avgdl, average length of field除了使用BoostQuery修改得分,我们还可以使用FunctionScoreQuery修改得分。
FunctionScoreQuery 提供了更复杂的得分修改能力,它允许基于文档的属性来动态调整得分。
- 原理:结合BM25计算出的原始得分和新的得分函数计算出的分数,成为新的分数。
- 使用场景:根据文档的发布时间、受欢迎度、点击量等因素来调整排名。
构造方法如下:
java
public FunctionScoreQuery(Query in, DoubleValuesSource source) {
this.in = in;
this.source = source;
}Query in:原始查询条件;DoubleValuesSource source:新的得分函数;
使用案例如下:
java
private static void search() throws IOException, ParseException {
FSDirectory directory = FSDirectory.open(Paths.get("index_demo_02"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query query = parser.parse("great book");
FunctionScoreQuery functionScoreQuery = new FunctionScoreQuery(
query, DoubleValuesSource.fromLongField("id"));
TopDocs topDocs = searcher.search(functionScoreQuery, 10);
System.out.println("Total hits: " + topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("得分:" + scoreDoc.score);
System.out.println("文档内容:" + doc);
System.out.println("解释:");
Explanation explain = searcher.explain(functionScoreQuery, scoreDoc.doc);
System.out.println(explain);
}
reader.close();
directory.close();
}DoubleValuesSource.fromLongField("id")表示文档中id字段的值成为新的得分。
注意,id需要是NumericDocValuesField类型:
document.add(new NumericDocValuesField("id", 1)); document.add(new StoredField("id", 1));
结果如下:
txt
得分:2.0
文档内容:Document<stored<id:2> stored,indexed,tokenized<title:Lucene for Dummies> stored,indexed,tokenized<content:Lucene for Dummies is a book>>
解释:
2.0 = weight(FunctionScoreQuery(content:great content:book, scored by double(id))), result of:
2.0 = double(id)
得分:1.0
文档内容:Document<stored<id:1> stored,indexed,tokenized<title:Lucene in Action> stored,indexed,tokenized<content:a Lucene in Action is a great book>>
解释:
1.0 = weight(FunctionScoreQuery(content:great content:book, scored by double(id))), result of:
1.0 = double(id)上面的例子是直接是将新的得分函数计算出来的分数进行替换,得到新的分数,在更多情况下,我们需要结合原始得分,我们可以自己编写表达式实现,如下:
java
// 创建并编译表达式
Expression expr = JavascriptCompiler.compile("_score * ln(popularity)");
// 为表达式中的变量 如 _score 、 popularity 等绑定值
SimpleBindings bindings = new SimpleBindings();
bindings.add("_score", DoubleValuesSource.SCORES);
bindings.add("popularity", DoubleValuesSource.fromIntField("popularity"));
// 创建FunctionScoreQuery
Query query = new FunctionScoreQuery(
originalQuery,
expr.getDoubleValuesSource(bindings));注意,需要引入以下依赖包:
xml
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-expressions</artifactId>
<version>9.11.0</version>
</dependency>7. 总结
本文总结了分词与倒排索引的相关知识,并以Lucene为例,实践了相关概念。
在搜索工程中,主要可以分为两大步:构建索引与查询。
在构建索引时,基础结构是域(Field),多个Field组成文档,针对不同的类型,可以构建不同的数据结构以加快查询、排序和聚合等操作。针对文本text类型,可以构建倒排索引。首先,将文本类型进行分词,形成词典和倒排列表(posting list)的倒排索引结构,并且,为了节省空间,可以应用不同的压缩算法压缩词典和倒排列表。
词典可以顺序存储进磁盘,也可以按照B+树的结构存储进磁盘。
在查询时,如果是文本查询,可以将查询词按照同样的分词规则进行分词,并针对每个词元,去倒排索引中查询出倒排列表,将所有的倒排列表合并起来,形成完整的查询结果。最后,应用相关性算法,计算每个文档与查询词的相关性,将相关性最高的文档按照指定数量返回,形成查询结果。
Lucene虽然直接使用的情况不多,但是Lucene是ElasticSearch的基础,学习Lucene,对于后续学习ES也有帮助。
前前后后、磨磨蹭蹭花了一个多月才整理完这篇文章,只能说对整体结构了解了大概,还有很多细节需要完善了解,在后续的学习中继续补充。
参考资料
[1] 案例数据:https://www.mysqltutorial.org/getting-started-with-mysql/mysql-sample-database/
[2] Introduction to Information Retriveval : https://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf
[3] basic concepts in Lucene : https://www.alibabacloud.com/blog/analysis-of-lucene---basic-concepts_594672
[5] 【相关性03:文本匹配(TF-IDF、BM25、词距)】 https://www.bilibili.com/video/BV1XT421Q7fw/
附录
luke介绍
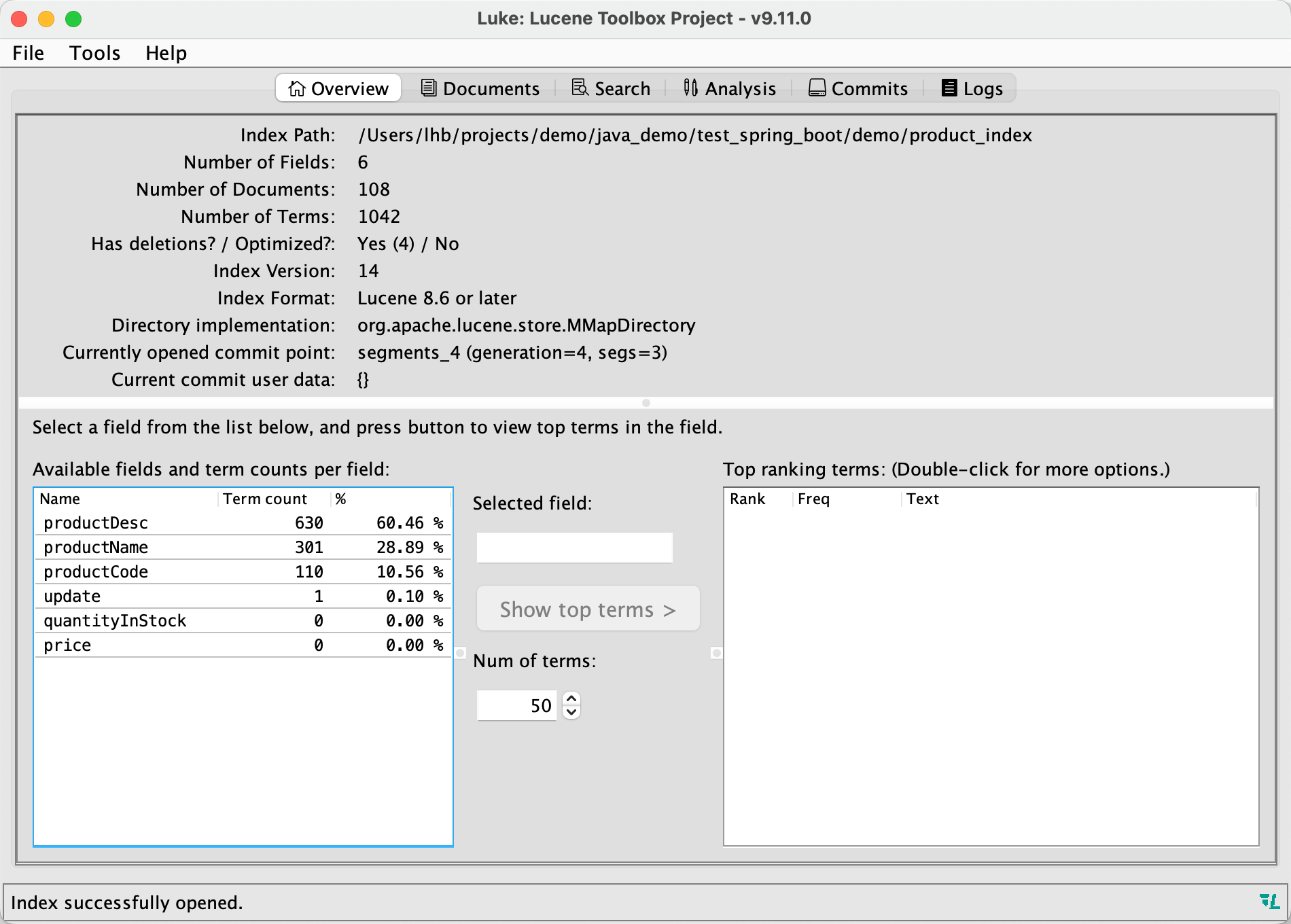
luke是Lucene体系下的工具软件,可以用来帮助我们查看索引,下面介绍如何启动luke:
首先在项目中引入luke依赖:
xml
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-luke</artifactId>
<version>9.11.0</version>
</dependency>然后,在IDEA手动创建一个启动配置,选择启动类:
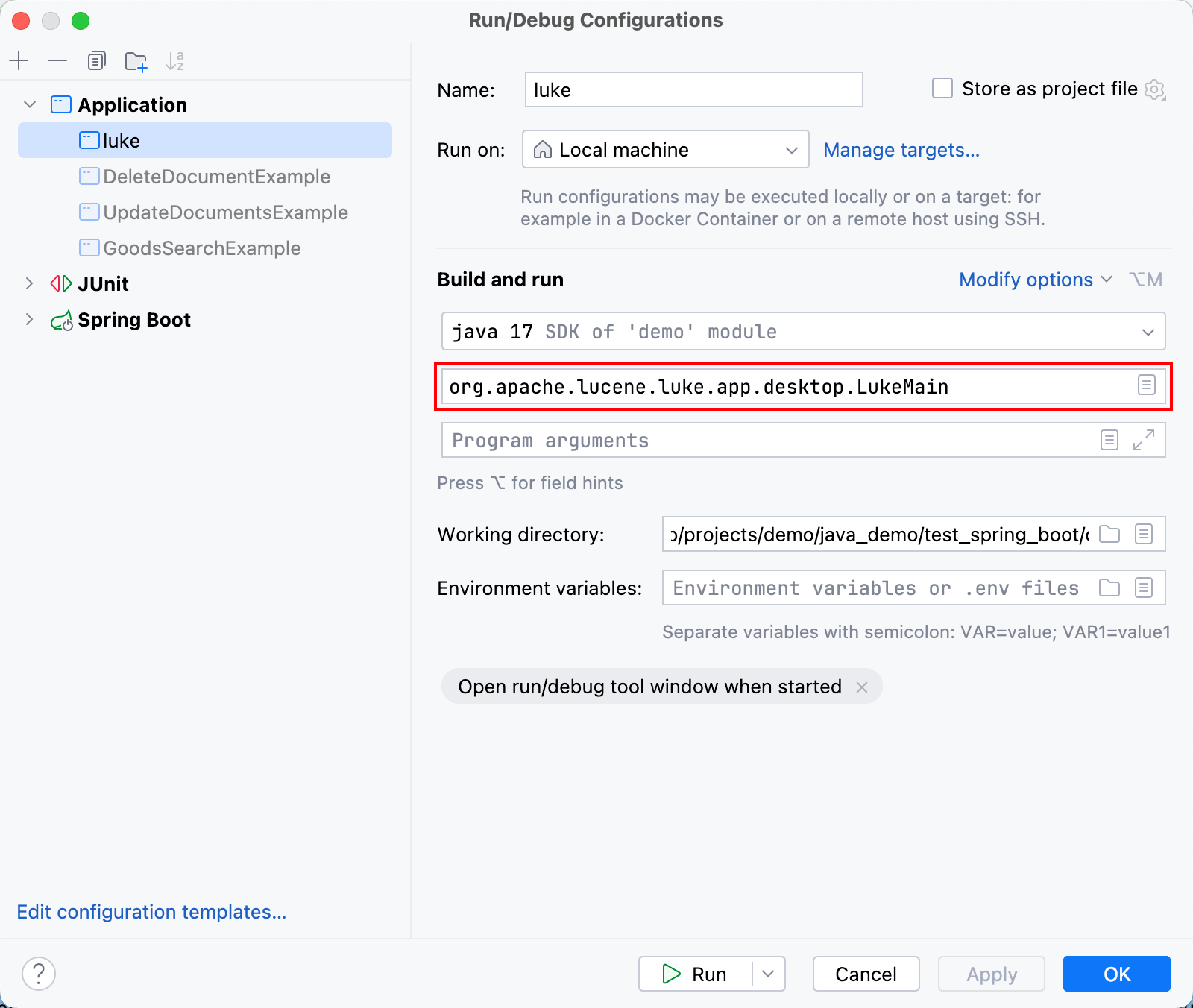
启动luke程序,界面如下:
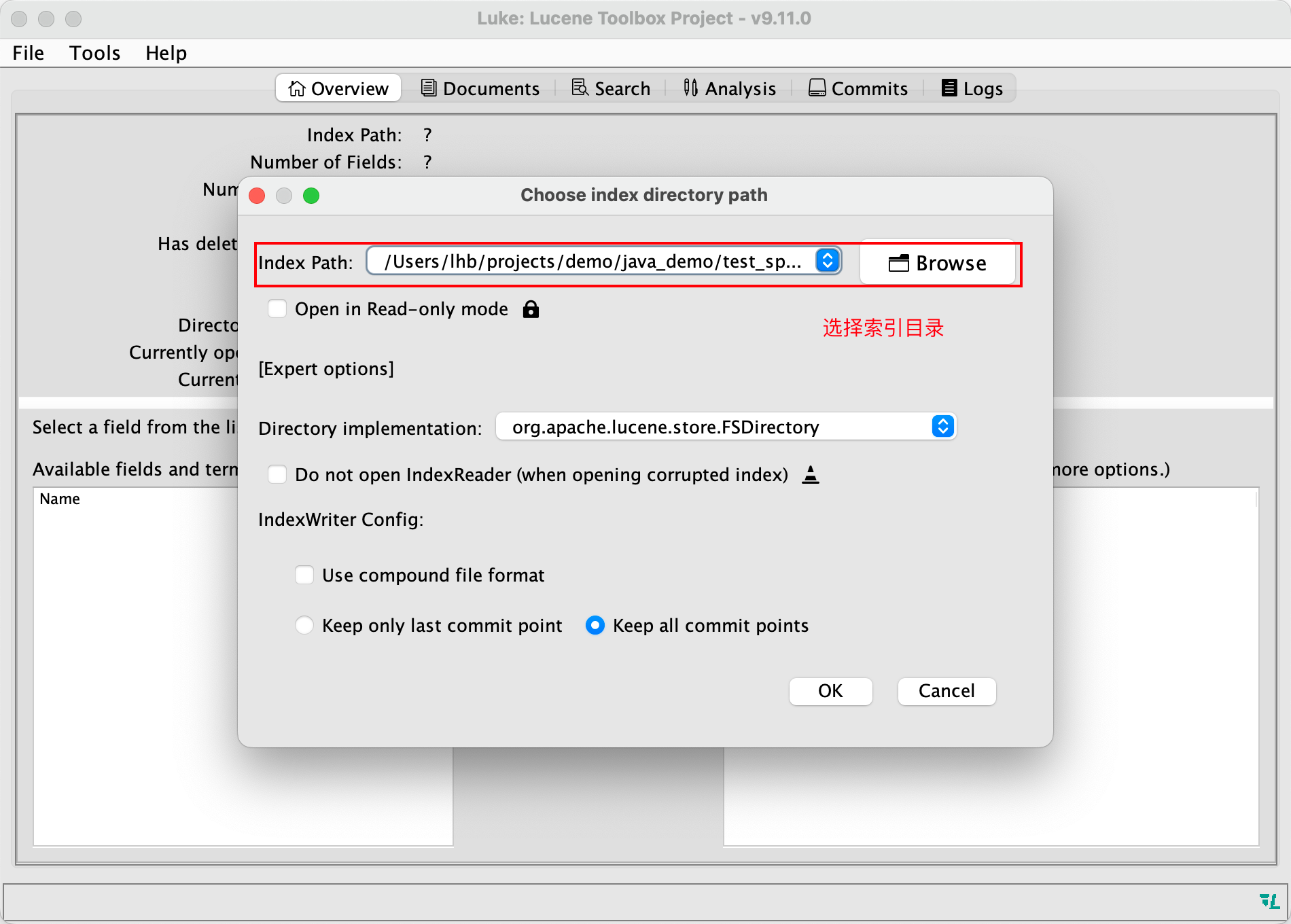
首先选择一个索引目录,然后我们就可以查看选择的索引相关信息,并且也可以执行分词、搜索等功能: