Appearance
Java NIO - 02 Buffer与Channel
本文主要介绍Buffer(以ByteBuffer为例)和Channel(以FileChannel为例)的使用。
1. Buffer
1.1 Buffer的结构
Buffer封装了一块内存区域(数组),并提供了一些方法进行数据的读写。Buffer分为读写模式,在写模式下可以向Buffer中写入数据;在读模式下,可以从Buffer中读取数据。
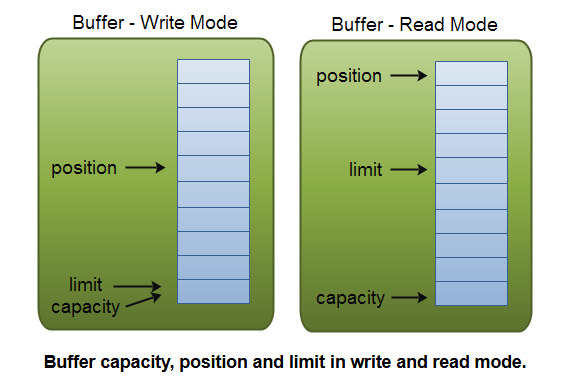
在Buffer内部,有三个属性需要关注:
capacity:表示数组容量,在Buffer创建时被设置,并且之后不能更改。
可以使用
buffer.capacity()方法获取 Buffer 的容量。position:position 表示Buffer当前读写操作的位置。 它是一个索引值,指向下一个要被读取或写入的字节的索引。
写模式:当向 Buffer 写入数据时 (例如使用 put() 方法),position 会自动向前移动,移动的距离等于写入的数据大小。
读模式:当从 Buffer 读取数据时 (例如使用 get() 方法),position 会自动向前移动,移动的距离等于读取的数据大小。
可以使用
buffer.position()方法获取当前的 position 值。limit:limit 表示 Buffer 中可读或可写数据的上限。 在写模式下,limit 表示最多可以写入多少数据,此时limit等于capacity;在读模式下,limit 表示最多可以读取多少数据,通常设置为实际有效数据的末尾。
可以使用
buffer.limit()方法获取当前的 limit 值。
Buffer 有以下实现:
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
1.2 基本使用
我们以ByteBuffer为例,介绍Buffer的基本使用。
1.2.1 创建Buffer对象
我们可以使用ByteBuffer.allocate()方法创建ByteBuffer对象:
java
ByteBuffer byteBuffer = ByteBuffer.allocate(8);
System.out.println(byteBuffer);
ByteBuffer directByteBuffer = ByteBuffer.allocateDirect(8);
System.out.println(directByteBuffer);txt
java.nio.HeapByteBuffer[pos=0 lim=8 cap=8]
java.nio.DirectByteBuffer[pos=0 lim=8 cap=8]HeapByteBuffer和DirectByteBuffer的区别:
HeapByteBuffer 和 DirectByteBuffer 都是 Java NIO (New I/O) 库中 ByteBuffer 接口的实现,它们的主要区别在于内存分配的位置。
HeapByteBuffer (堆缓冲区):
- 数据存储在 JVM 堆内存中,本质上是 JVM 管理的 Java 字节数组 (
byte[])。 - 通过
ByteBuffer.allocate(int capacity)方法创建。
DirectByteBuffer (直接缓冲区):
- 数据存储在 堆外内存 (也称为直接内存或本地内存) 中, 由操作系统直接管理,不属于 JVM 堆。
- 通过
ByteBuffer.allocateDirect(int capacity)方法创建。 DirectByteBuffer对象本身仍然在 JVM 堆上,但它包含一个指向堆外内存地址的引用。
1.2.2 写入数据
我们可以使用put()系列方法写入数据:
java
// 1. 创建buffer
ByteBuffer buffer = ByteBuffer.allocate(8);
// 2. 写入数据
buffer.put((byte) 'a'); // 写入单个字节
buffer.put("abc".getBytes(StandardCharsets.UTF_8)); // 写入一整个字节数组
buffer.put("abcde".getBytes(StandardCharsets.UTF_8),3,2); // 写入字节数组一部分
// 3. 输出写入结果
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));txt
java.nio.HeapByteBuffer[pos=6 lim=8 cap=8]
[97, 97, 98, 99, 100, 101, 0, 0]buffer.array() 可以获取底层的字节数组。
1.2.3 读取数据
我们可以使用get()系列方法读取数据:
java
// 1. 创建buffer对象并写入数据
ByteBuffer buffer = ByteBuffer.allocate(8);
buffer.put(new byte[]{97,97,98,98,50,51});
buffer.put(7, (byte) 98);
System.out.println("-----创建buffer并写入数据-----");
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));
// 2. 切换为读模式
buffer.flip();
System.out.println("-----切换为读模式-----");
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));
// 3. 读取一个字节
byte b = buffer.get();
System.out.println("-----读取一个字节后-----");
System.out.println(b);
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));
// 4. 读取一个字节数组
byte[] bytes = new byte[2];
buffer.get(bytes);
System.out.println("-----读取字节数组后-----");
System.out.println(Arrays.toString(bytes));
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));
// 5. 切换为写模式compact()
buffer.compact();
System.out.println("-----切换为写模式compact()-----");
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));
// 6. 切换为写模式clear()
buffer.clear();
System.out.println("-----切换为写模式clear()-----");
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));结果如下:
txt
-----创建buffer并写入数据-----
java.nio.HeapByteBuffer[pos=6 lim=8 cap=8]
[97, 97, 98, 98, 50, 51, 0, 98]
-----切换为读模式-----
java.nio.HeapByteBuffer[pos=0 lim=6 cap=8]
[97, 97, 98, 98, 50, 51, 0, 98]
-----读取一个字节后-----
97
java.nio.HeapByteBuffer[pos=1 lim=6 cap=8]
[97, 97, 98, 98, 50, 51, 0, 98]
-----读取字节数组后-----
[97, 98]
java.nio.HeapByteBuffer[pos=3 lim=6 cap=8]
[97, 97, 98, 98, 50, 51, 0, 98]
-----切换为写模式compact()-----
java.nio.HeapByteBuffer[pos=3 lim=8 cap=8]
[98, 50, 51, 98, 50, 51, 0, 98]
-----切换为写模式clear()-----
java.nio.HeapByteBuffer[pos=0 lim=8 cap=8]
[98, 50, 51, 98, 50, 51, 0, 98]关键点:
- 如果要读取数据,需要从写模式切换为读模式,调用
flip()方法; - 如果读取完后,需要切换为写模式,调用
compact()或clear()方法compact():如果还有数据没有读取完,则将剩余数据往前移,position重置为剩余数据后,之后从剩余数据后继续写入;clear():如果还有数据没有读取完,直接舍弃,position重置为0,从头开始写入数据;
get(int index)可以在不改变position位置的情况下读取指定索引处的数据;
1.2.4 rewind()
rewind()方法可以将position重置为0,表示可以从头开始写入或者读取数据。
1.2.5 mark()和reset()
rewind()可以将position重置为0,而mark()和reset()可以将position重置为任意位置,使用方法是先调用mark()标志position的位置,之后调用reset()将position重置为标记的位置。
java
ByteBuffer buffer = ByteBuffer.allocate(8);
buffer.put("abcde".getBytes(StandardCharsets.UTF_8));
buffer.flip();
buffer.get();
buffer.get();
// 标记位置
buffer.mark();
buffer.get();
buffer.get();
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));
// 重置位置
buffer.reset();
System.out.println(buffer);
System.out.println(Arrays.toString(buffer.array()));txt
java.nio.HeapByteBuffer[pos=4 lim=5 cap=8]
[97, 98, 99, 100, 101, 0, 0, 0]
java.nio.HeapByteBuffer[pos=2 lim=5 cap=8]
[97, 98, 99, 100, 101, 0, 0, 0]1.3 黏包半包分析
在 Java NIO 中,黏包 (黏包) 和 半包 (半包) 是在使用 TCP 协议进行网络通信时,由于 TCP 是面向流的协议特性而可能出现的数据传输问题。 这两个问题都与消息的边界在 TCP 传输过程中丢失有关。
1.3.1 黏包 (Packet Sticking / Packet Combining)
定义: 黏包指的是发送方发送的多个独立的数据包 (messages),在接收端被 TCP 协议合并成一个数据包进行接收。 接收端一次性从缓冲区读取到了多个消息的数据,这些消息粘连在一起,没有明确的边界。
发生原因:
- TCP Nagle 算法: 为了提高网络利用率,减少小数据包的发送,TCP 可能会将多个小的、连续发送的数据包合并成一个更大的数据包发送。
- 接收端缓冲区: 接收端 TCP 协议栈会将接收到的数据放入缓冲区。 如果应用程序读取数据的速度慢于数据到达的速度,缓冲区中可能会积累多个数据包,导致一次读取操作读取到多个消息。
示例:
假设发送端连续发送了两个数据包,分别是 Message 1 和 Message 2。
发送端: [Message 1] --> TCP 发送缓冲区 --> 网络 --> TCP 接收缓冲区 <-- 接收端 [Message 2] --> TCP 发送缓冲区 --> 网络 --> TCP 接收缓冲区 <-- 接收端 接收端可能一次性从缓冲区读取到: [Message 1][Message 2] // 黏在一起的数据接收端原本期望分别处理 Message 1 和 Message 2,但实际接收到的数据却黏在了一起,需要进行拆分才能正确处理。
1.3.2 半包 (Packet Splitting / Incomplete Packet)
定义: 半包指的是发送方发送的一个完整的数据包 (message),在接收端被 TCP 协议拆分成多个数据包进行接收。 接收端需要多次读取才能接收到完整的消息数据。
发生原因:
- TCP 数据包大小限制 (MSS/MTU): TCP 协议为了保证数据传输的可靠性和效率,会将数据包分割成不超过最大报文段长度 (MSS) 的片段进行传输。 如果一个应用层消息的大小超过 MSS,TCP 就会将其拆分成多个 TCP 数据包发送。
- 网络拥塞或链路层限制: 网络传输过程中,数据包可能会因为网络拥塞或链路层协议的限制而被分割成更小的片段。
- 接收端缓冲区大小限制: 接收端 TCP 协议栈的缓冲区大小是有限的。 如果发送端发送的数据包过大,接收端可能无法一次性接收完整,需要分多次接收。
示例:
假设发送端发送了一个数据包,是 Message 3。
发送端: [Message 3] --> TCP 发送缓冲区 --> 网络 (可能被分割) --> TCP 接收缓冲区 <-- 接收端 / \ / \ 接收端可能分多次从缓冲区读取到: [Message 3 的一部分] [Message 3 的剩余部分] // 被拆分成了多个部分接收端需要多次读取,并将读取到的数据片段拼接起来,才能还原出完整的 Message 3。
1.3.3 解决方法
为了在 NIO 应用中正确处理黏包和半包问题,需要在应用层协议中定义消息的边界,并在接收端进行消息的拆分和组装。 常见的解决方案包括:
消息长度字段 (Message Length Prefix):
- 在每个消息的头部添加一个固定长度的字段,用于标识消息体的长度。
- 接收端先读取固定长度的头部,解析出消息体的长度,然后根据长度读取完整的数据包。
- 优点: 实现简单,通用性强。
- 缺点: 如果消息长度字段本身在传输过程中出现半包,仍然需要处理。
[消息总长度 (固定长度)][消息体]固定长度消息 (Fixed Length Messages):
- 约定每个消息的长度是固定的。
- 接收端每次读取固定长度的数据作为一个完整消息。
- 优点: 实现非常简单。
- 缺点: 灵活性差,不适用于消息长度变化的应用场景,如果实际消息长度小于固定长度,会浪费带宽。
特殊分隔符 (Delimiter-Based Messages):
- 在每个消息的末尾添加一个特殊的、不会在消息内容中出现的分隔符 (例如
\r\n,\0, 特殊的字节序列)。 - 接收端在读取数据时,不断查找分隔符,当找到分隔符时,就认为找到了一个完整消息的边界。
- 优点: 灵活性较好,消息长度可以变化。
- 缺点: 需要选择合适的分隔符,并确保消息内容中不会出现分隔符,实现稍复杂,性能可能略低于长度字段方式。
[消息体][分隔符]- 在每个消息的末尾添加一个特殊的、不会在消息内容中出现的分隔符 (例如
更复杂的协议 (例如 Protocol Buffers, Thrift 等):
- 使用成熟的序列化框架,这些框架通常已经内置了消息边界处理机制。
- 优点: 功能强大,效率高,易于扩展,通常提供更丰富的功能 (如数据压缩、版本控制等)。
- 缺点: 引入额外的依赖,学习成本较高。
2. Channel
Channel译为管道,是用于获取数据的通道,与之前的IO流类似,但有一些不同:
- Channel是双向的,但流是单向的;
- Channel可以异步读写数据(FileChannel是阻塞式的);
- Channel总是从Buffer中读写数据;
Channel有以下实现:
FileChannel:从文件中读写数据;DatagramChannel:通过UDP读写数据;SocketChannel:通过TCP读写数据;ServerSocketChannel:监听TCP连接并为每个连接创建SocketChannel;
2.1 FileChannel 使用
接下来我们以FileChannel为例,讲解Channel的基本使用。
首先是创建FileChannel对象,不能直接打开FileChannel,我们可以通过以下方式获取FileChannel,他们都有getChannel()方法:
- 通过
FileInputStream获取FileChannel,获取的Channel只能读取数据; - 通过
FileOutputStream获取FileChannel,获取的Channel只能写出数据; - 通过
RandomAccessFile来获取FileChannel,获取的Channel能否读写根据构造RandomAccessFile的读写模式来确定;
java
// 通过RandomAccessFile来获取FileChannel,rw表示可读可写
try(RandomAccessFile randomAccessFile = new RandomAccessFile("src/main/resources/data.txt","rw")){
FileChannel channel = randomAccessFile.getChannel();
}catch (Exception e){
e.printStackTrace();
}Channel必须关闭,不过使用try-with-resource语法,会自动关闭RandomAccessFile,从而间接关闭Channel;
接下来我们就可以使用Channel读取文件数据了,首先准备数据文件:
txt
abcd
1234然后使用Buffer和Channel读取数据:
java
try(RandomAccessFile randomAccessFile = new RandomAccessFile("src/main/resources/data.txt","rw")){
FileChannel channel = randomAccessFile.getChannel();
// 将数据读取到Buffer中
ByteBuffer buffer = ByteBuffer.allocate(16);
channel.read(buffer);
// buffer切换到读模式并读取数据,最后切换为写模式
buffer.flip();
while (buffer.hasRemaining()){
System.out.print((char) buffer.get());
}
buffer.clear();
}catch (Exception e){
e.printStackTrace();
}同样也可以使用Buffer和Channel写入数据:
java
try(RandomAccessFile randomAccessFile = new RandomAccessFile("src/main/resources/a.txt","rw")){
FileChannel channel = randomAccessFile.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(8);
buffer.put("xyz".getBytes(StandardCharsets.UTF_8));
buffer.flip(); // 注意,在写入前需要切换为读取模式
channel.write(buffer);
buffer.clear();
}catch (Exception e){
e.printStackTrace();
}我们也可以直接在两个Channel之间传输数据:
java
try (
FileChannel inputChannel = new FileInputStream("src/main/resources/data.txt").getChannel();
FileChannel outChannel = new FileOutputStream("src/main/resources/out.txt").getChannel();
){
// 方式一:transferTo()
// inputChannel.transferTo(0, inputChannel.size(), outChannel);
// 方式二:transferFrom()
outChannel.transferFrom(inputChannel,0,inputChannel.size());
}catch (Exception e){
e.printStackTrace();
}关键点:
FileChannel.size()返回对应文件的大小;- 使用
transferTo()或transferFrom()传输文件:这种方式效率高,因为使用了零拷贝,即允许数据在两个通道之间直接传输,无需通过 CPU 中转。这减少了数据拷贝的次数,提高了传输效率。 - 但是,使用
transferTo()或transferFrom()传输文件时,在Windows系统下存在文件大小限制,如果文件超过2GB,则会出现文件传输失败的情况,由于transferTo()或transferFrom()返回实际传输的数据量,所以改进后的文件传输如下:
java
try (
FileChannel inputChannel = new FileInputStream("jwtdemo/src/main/resources/data.txt").getChannel();
FileChannel outChannel = new FileOutputStream("jwtdemo/src/main/resources/out.txt").getChannel();
){
// left表示未传输的数据量,初始化为文件大小
long left = inputChannel.size();
// 只要还有未传输的数据,则循环不会退出
while (left > 0){
// position 设置为inputChannel.size() - left
// transfered 表示实际传输的数据量
long transfered = outChannel.transferFrom(inputChannel, inputChannel.size() - left, inputChannel.size());
left -= transfered;
}
}catch (Exception e){
e.printStackTrace();
}FileChannel.force()
由于性能方面的考虑,操作系统通常会将数据缓存在内存中,而不是立即写入磁盘。这样做可以减少磁盘I/O操作,提高程序运行速度。但是,这也意味着写入到 FileChannel 中的数据可能不会立即持久化到磁盘上。
FileChannel.force() 方法的作用就是强制操作系统将缓存中的数据立即写入磁盘,确保数据的持久性。
public final void force(boolean meta) throws IOExceptionmeta:一个布尔值,表示是否同时将文件元数据(例如权限、时间戳等)写入磁盘。如果为true,则同时写入数据和元数据;如果为false,则只写入数据。
3. 分散读集中写
分散读是指将管道(Channel)中的数据读到多个缓冲区(Buffer)中;集中写是指将多个缓冲区(Buffer)的数据写到同一个管道(Channel)中。
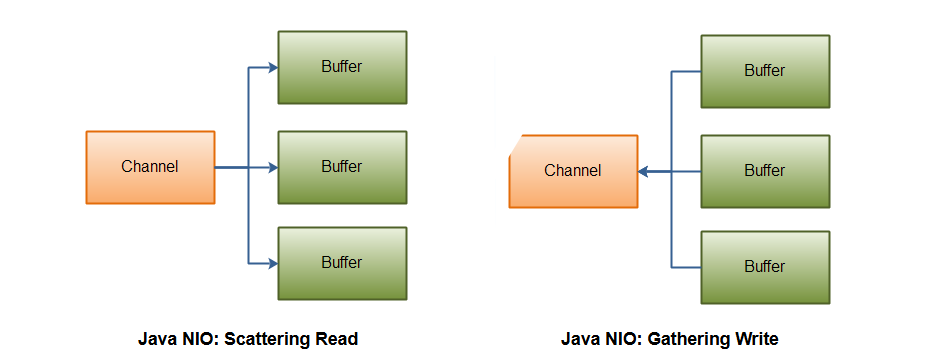
分散读例子:
java
try (
FileChannel channel = new RandomAccessFile("src/main/resources/data.txt","rw").getChannel();
){
// 下面三行是分散读
ByteBuffer buffer1 = ByteBuffer.allocate(4);
ByteBuffer buffer2 = ByteBuffer.allocate(8);
channel.read(new ByteBuffer[]{buffer1, buffer2});
// 下面代码是输出buffer中的内容,证明确实读到了不同的缓冲区
buffer1.flip();
while (buffer1.hasRemaining()){
System.out.print((char) buffer1.get());
}
buffer1.clear();
buffer2.flip();
while (buffer2.hasRemaining()){
System.out.print((char) buffer2.get());
}
buffer2.clear();
}catch (Exception e){
e.printStackTrace();
}集中写例子:
java
try (
FileChannel channel = new RandomAccessFile("jwtdemo/src/main/resources/gathering_write.txt","rw").getChannel();
){
ByteBuffer buffer1 = ByteBuffer.allocate(6);
buffer1.put("hello ".getBytes(StandardCharsets.UTF_8));
ByteBuffer buffer2 = ByteBuffer.allocate(6);
buffer2.put("world!".getBytes(StandardCharsets.UTF_8));
// 注意,缓冲区要切换到读模式
buffer1.flip();
buffer2.flip();
// 集中写
channel.write(new ByteBuffer[]{buffer1, buffer2});
}catch (Exception e){
e.printStackTrace();
}参考资料
[1] https://www.bilibili.com/video/BV1py4y1E7oA
[2] https://jenkov.com/tutorials/java-nio/buffers.html
[3] Gemini