Appearance
MySQL 事务和锁
本文介绍事务和锁的基本概念与使用。
1. 事务
1.1 什么是事务
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
以银行转账为例,现有一张账户表account,数据如下:
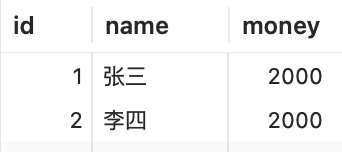
假设现在张三向李四转账1000元,那么流程如下:
- 查询张三余额,如果余额不足,则直接结束转账流程;如果余额充足,则进行转账流程;
- 张三账户金额扣除1000元;
- 李四账户金额增加1000元;
如果没有事务控制,那么假设在执行完第2步后由于程序错误、系统崩溃等原因,第3步没有执行,那么此时张三账户平白无故少了1000元,这显然是重大事故了。事务保证了当发生错误时,已执行的操作得到撤销,从而回退到事务开始执行前的状态,保证数据正确性。
1.2 使用事务
MySQL 对事务的支持主要依赖于存储引擎,最常用且支持事务的存储引擎是 InnoDB。
在MySQL中,使用事务有两种方式:隐式开启事务和显式开启事务。
1.2.1 隐式开启事务
默认情况下,每次 INSERT、UPDATE、DELETE 都会立即生效并持久化到数据库。我们可以使用如下命令查看DML语句事务是否自动提交:
sql
SELECT @@autocommit;
@@符号的含义
@@是 MySQL 中用于访问系统变量的语法。
@@global.variable_name:访问全局系统变量。@@session.variable_name或@@variable_name:访问当前会话(Session)的系统变量。
结果为1,表示已开启了自动提交。
我们可以使用如下命令,关闭当前回话的自动提交:
sql
SET @@autocommit = 0;之后,当我们执行DML(INSERT、UPDATE、DELETE )语句后,不会立即生效并持久化到数据库,如下:
打开两个命令行窗口,模拟两个会话,其中一个会话关闭自动提交,并修改张三的账户,使得余额减1000,另一个会话查询账户表,发现余额并没有减1000。
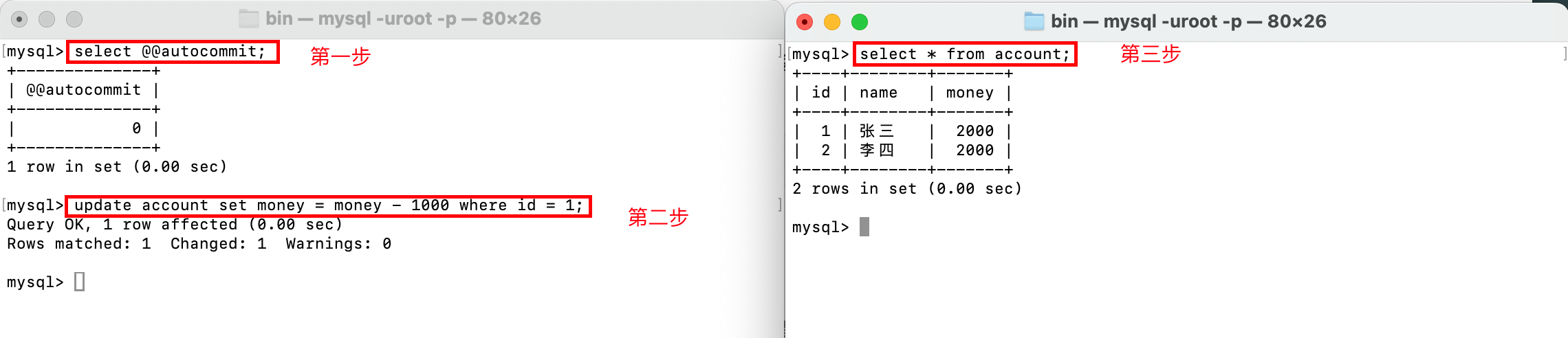
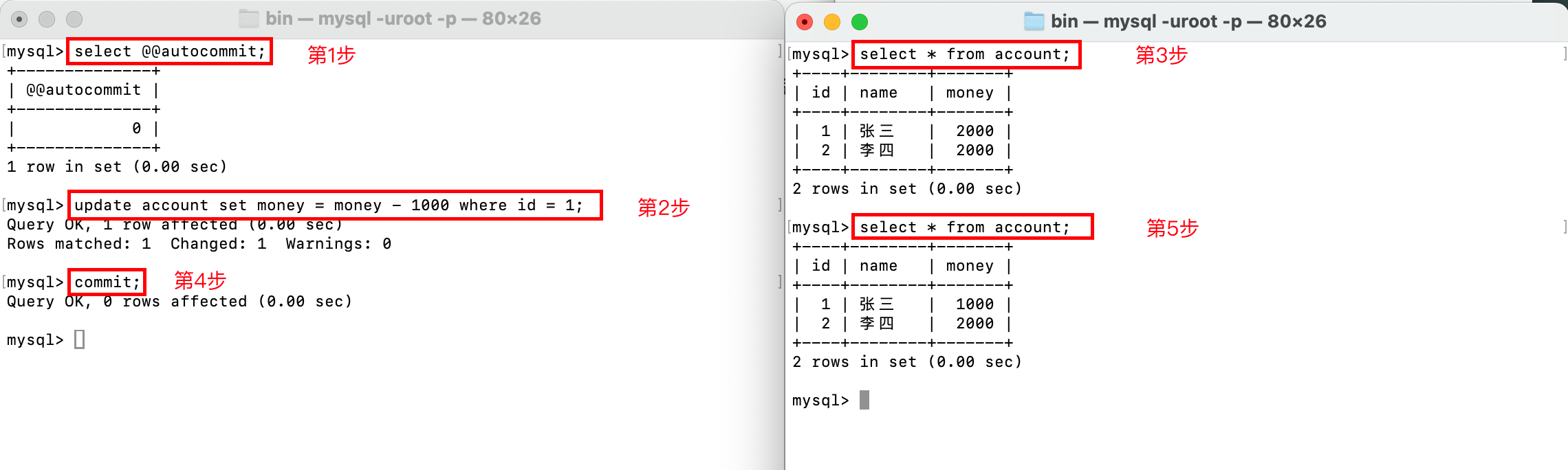
如果要使得DML操作生效,我们可以使用commit;命令,来提交从上次事务到本次commit;之间执行的命令:
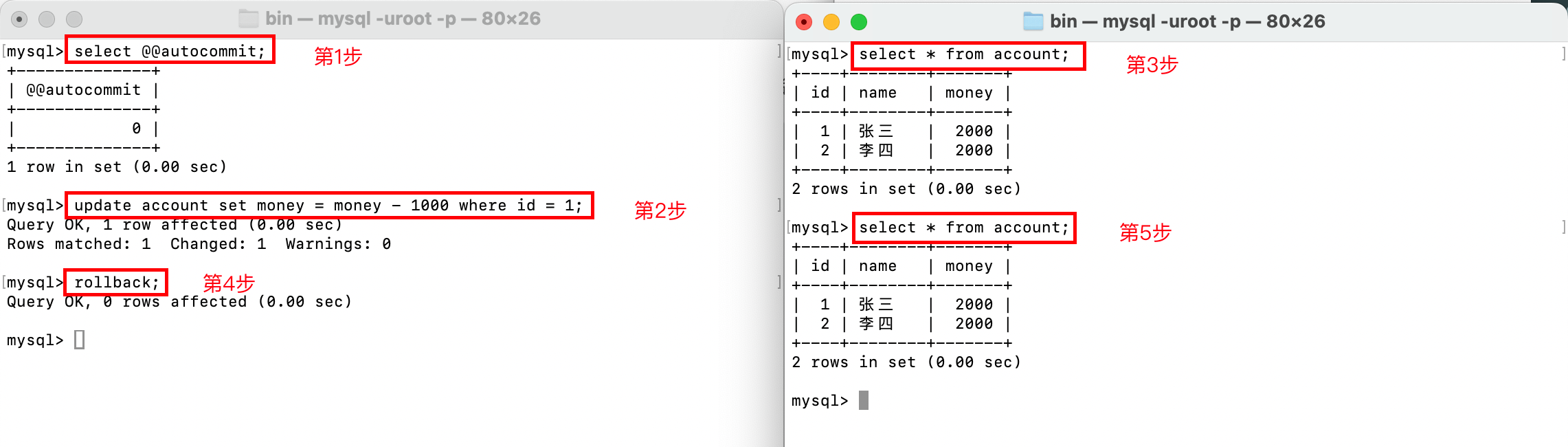
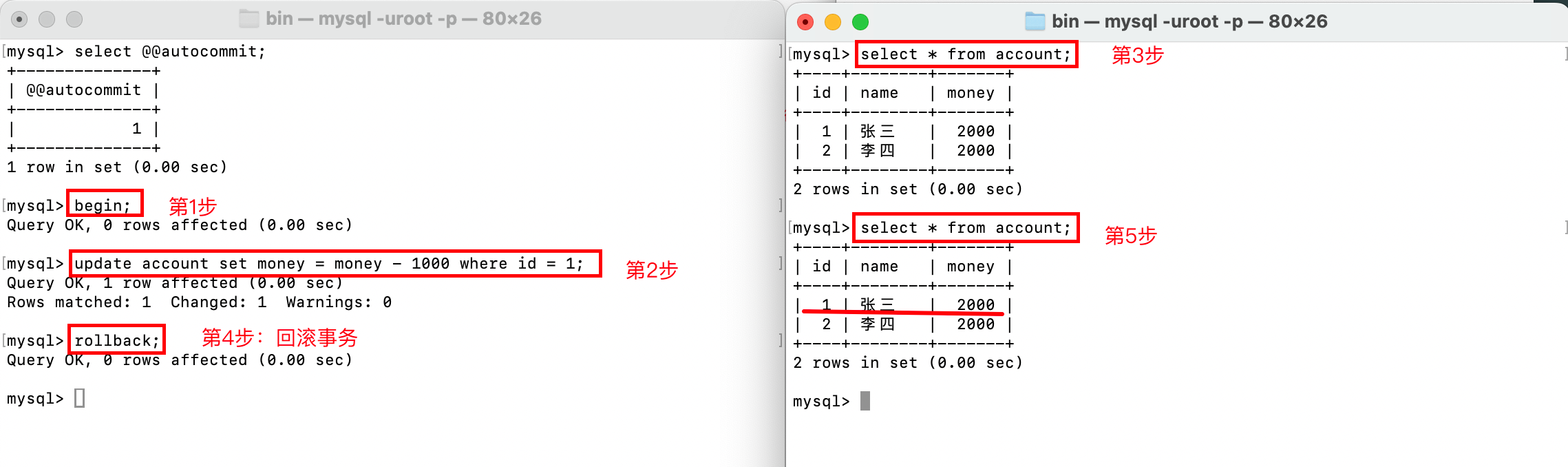
如果要撤销事务,则可以使用rollback;命令,使得从上次事务到本次rollback;之间执行的命令作废:
1.2.2 显式开启事务
在隐式开启事务情况下,如果关闭自动提交,有时候容易忘记提交或回滚,因此,在生产环境中,通常推荐开启自动提交 autocommit = 1,然后使用 START TRANSACTION; 来显式地控制事务。
在显式开启事务时,可以使用START TRANSACTION;或BEGIN;来开启事务,使用COMMIT;来提交事务,使用ROLLBACK;来回退事务。
如下,显式开启并提交事务:
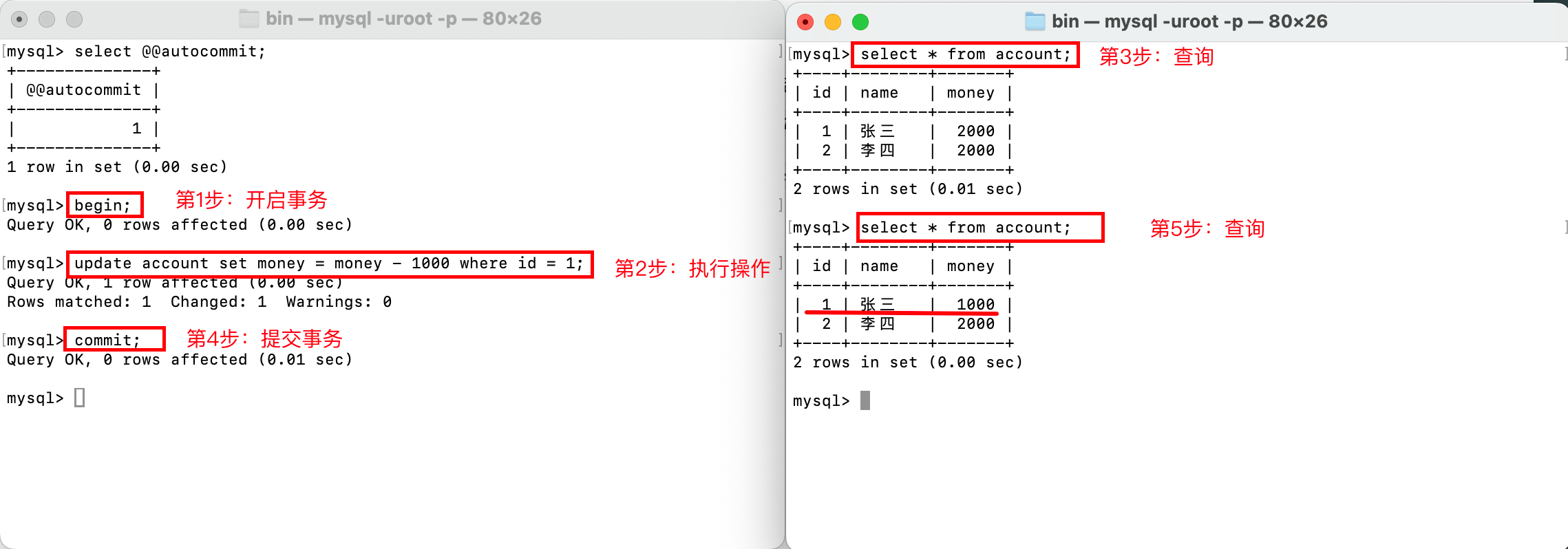
如下,显式开启事务,并回退事务:
1.3 事务四大特性
事务的四大特性分别为:
原子性(Atomicity):事务是一个不可分割的最小工作单元,事务中的所有操作要么全部成功完成,要么全部失败回滚。不会出现部分成功或部分失败的情况。
一致性(Consistency):事务执行前后,数据库从一个一致性状态转换到另一个一致性状态。这意味着事务必须遵守所有的预定义规则(如完整性约束、业务逻辑等),确保数据的有效性和正确性。
例如,如果扣款导致账户余额变为负数,那么即使转账操作在技术上能完成,也因为违反了“余额不能为负”的业务规则,导致数据库处于不一致状态。在这种情况下,事务应该回滚。
原子性(A)和隔离性(I)是实现一致性(C)的前提。
隔离性(Isolation):多个并发事务同时执行时,每个事务好像是独立运行的,互不干扰。一个事务的中间状态对其他事务是不可见的。
例如,当执行转账操作时,其他人去执行查询,不会看到张三账户余额1000元,李四账户余额2000元的中间情况。
持久性(Durability):一旦事务成功提交,其对数据库的修改就是永久性的,即使系统发生故障(如断电、崩溃、重启),这些修改也不会丢失。
事务的四大特性简称ACID。
1.4 并发事务问题
并发事务问题指的是在多用户(代表多个事务)同时访问数据库时,多个事务并行执行可能导致的数据不一致性和完整性破坏。
主要的并发事务问题有以下几种:
脏读:一个事务读取到了另一个未提交事务对数据做的修改。
场景举例:
- 事务 A 修改了数据 X;
- 事务 B 读取到了数据 X(此时事务 A 还没提交);
- 事务 A 发生错误,回滚了对数据 X 的修改;
- 事务 B 发现自己读取的数据 X 是一个不存在的值(因为事务 A 回滚了),这就是“脏数据”;
后果:事务 B 基于脏数据做了进一步操作,导致整个数据库逻辑错误。
不可重复读:在同一个事务中,两次相同的查询(针对同一行数据)结果不一致,因为在两次查询之间,另一个已提交事务修改了该数据。
场景举例:
- 事务 A 查询数据 X,得到值为 V1;
- 事务 B 修改了数据 X 为 V2,并提交了事务;
- 事务 A 再次查询数据 X,得到值为 V2(V2 != V1);
后果:事务 A 无法在一个事务内看到一致的数据视图,可能导致基于数据不一致的决策。
幻读:在同一个事务中,两次相同的查询(针对一个范围内的记录)结果集不一致,因为在两次查询之间,另一个已提交事务插入或删除了该范围内的记录。
场景举例:
- 事务 A 第一次查询某个范围的数据(例如
SELECT COUNT(*) FROM users WHERE age > 20;),得到 N 条记录; - 事务 B 在该范围内插入(或删除)了一条符合条件的新记录,并提交了事务;
- 事务 A 第二次查询相同的范围,得到 N+1(或 N-1)条记录;
后果: 事务 A 无法在一个事务内看到一致的记录集合,可能导致逻辑错误(例如,基于第一次查询结果决定插入一条记录,却发现主键冲突)。
- 事务 A 第一次查询某个范围的数据(例如
1.5 事务隔离级别
在ISO/ANSI SQL 标准中定义了四种事务隔离级别,他们对于并发事务问题解决程度不一,具体如下:
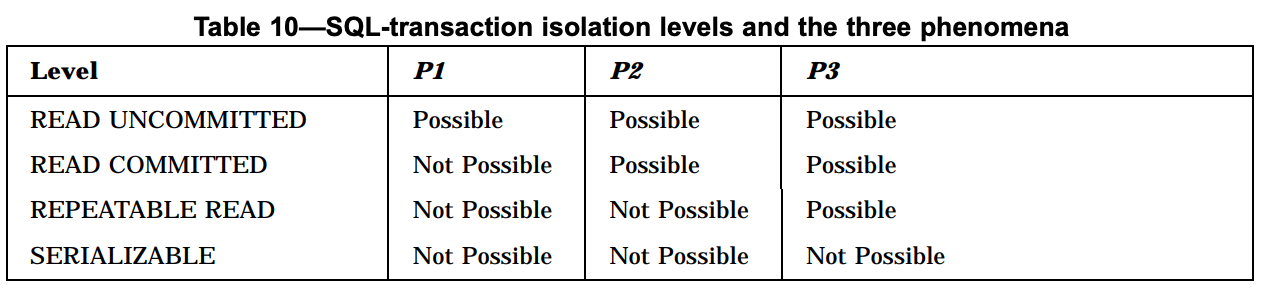 参考资料:https://web.cecs.pdx.edu/~len/sql1999.pdf 第84页 Table-10
参考资料:https://web.cecs.pdx.edu/~len/sql1999.pdf 第84页 Table-10
表格说明:
总共有四种隔离级别,分别为
READ UNCOMMITTED(读未提交),READ COMMITTED(读已提交),REPEATABLE READ(可重复读)和SERIALIZABLE(串行化),从上到下,数据一致性从差到好,事务并发度从高到低。P1表示脏读问题,P2表示不可重复读问题,P3表示幻读问题。
Possible表示本次事务在该隔离级别下,可能出现该问题。例如,
READ UNCOMMITTED行下P1列为Possible,表示在READ UNCOMMITTED隔离级别下,本次事务可能读取到其他事务未提交的数据。同理,
Possible表示在该隔离级别下,本次事务不会出现该问题。
在MySQL中,默认的事务隔离级别是REPEATABLE READ(可重复读)。
并且,MySQL 的 InnoDB 存储引擎通过其独特的 MVCC + 间隙锁 (Gap Lock)和 Next-Key Lock机制,在 REPEATABLE READ 隔离级别下解决了部分幻读问题。
在MySQL中,可以通过以下命令查看当前会话事务隔离级别:
sql
select @@transaction_isolation;可以通过以下命令设置事务隔离级别:
sql
set [session|global] transaction isolation level [read uncommitted | read committed | repeatable read | serializable]下面演示在MySQL中,可重复读隔离级别下,并发事务问题的出现情况:
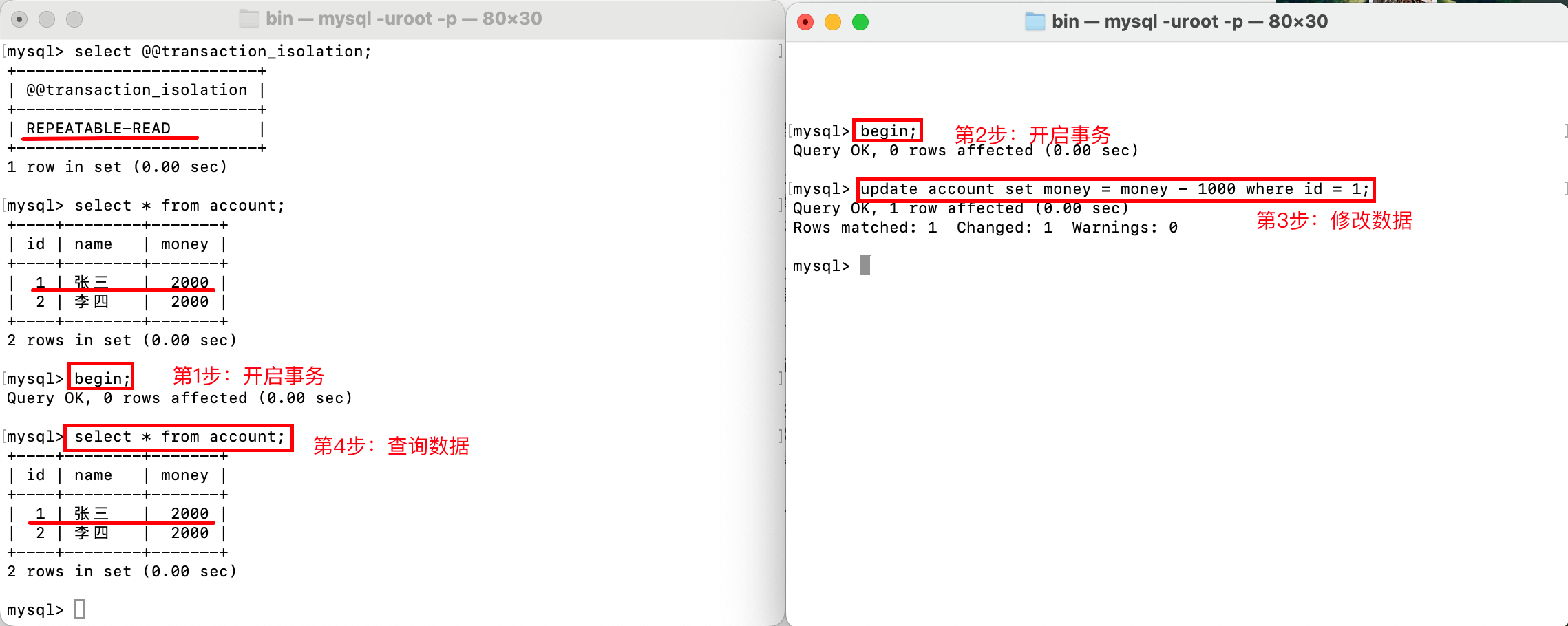
情形一,解决脏读问题:如下,在左边的事务中,并没有读取到右边未提交的事务修改的数据,因此没有出现脏读问题
情形二,解决不可重复读问题,即便右边的事务提交了,在左边的事务中,仍然不会查询到其他事务提交的结果,因此没有出现不可重复读问题。
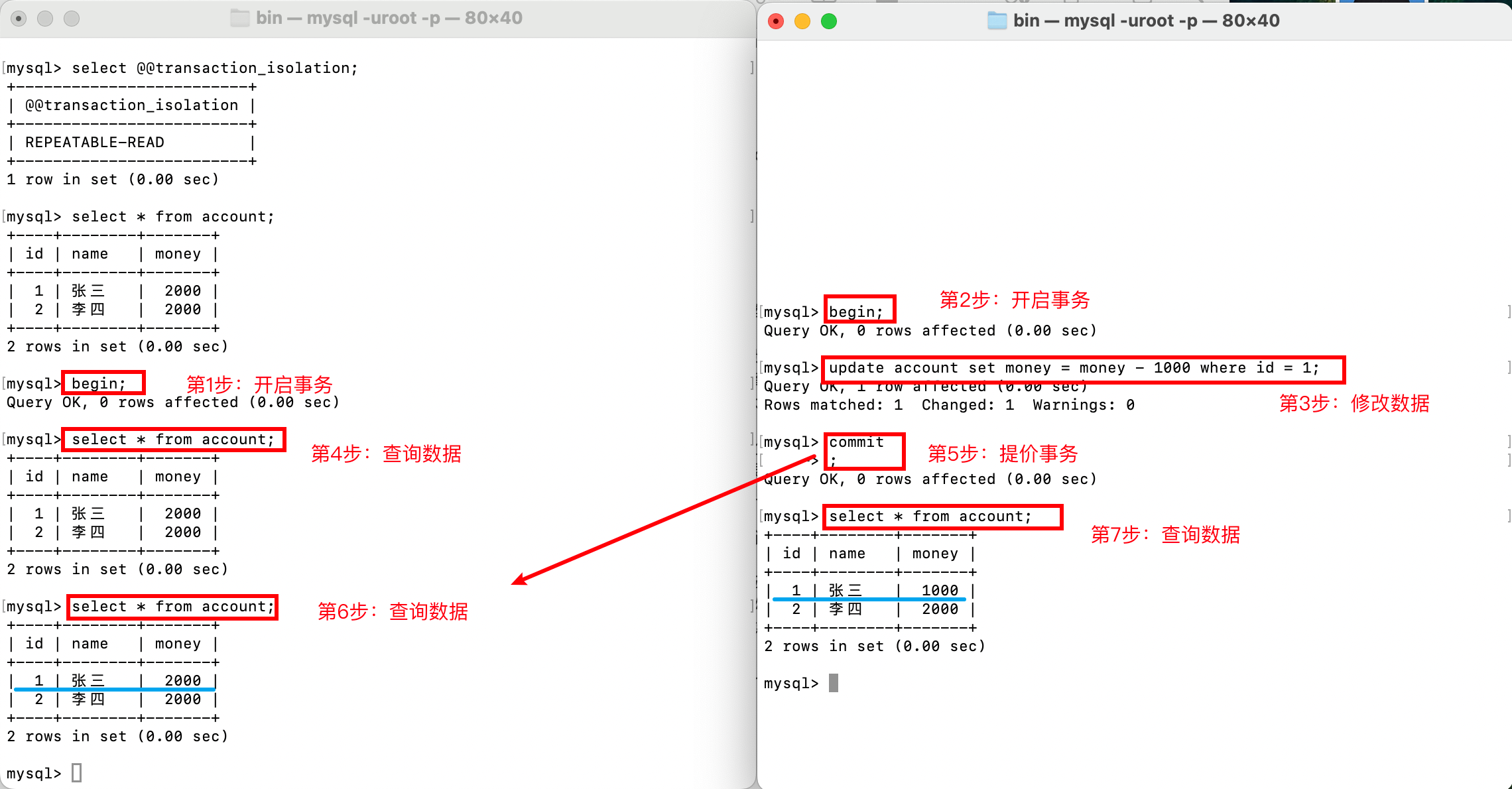
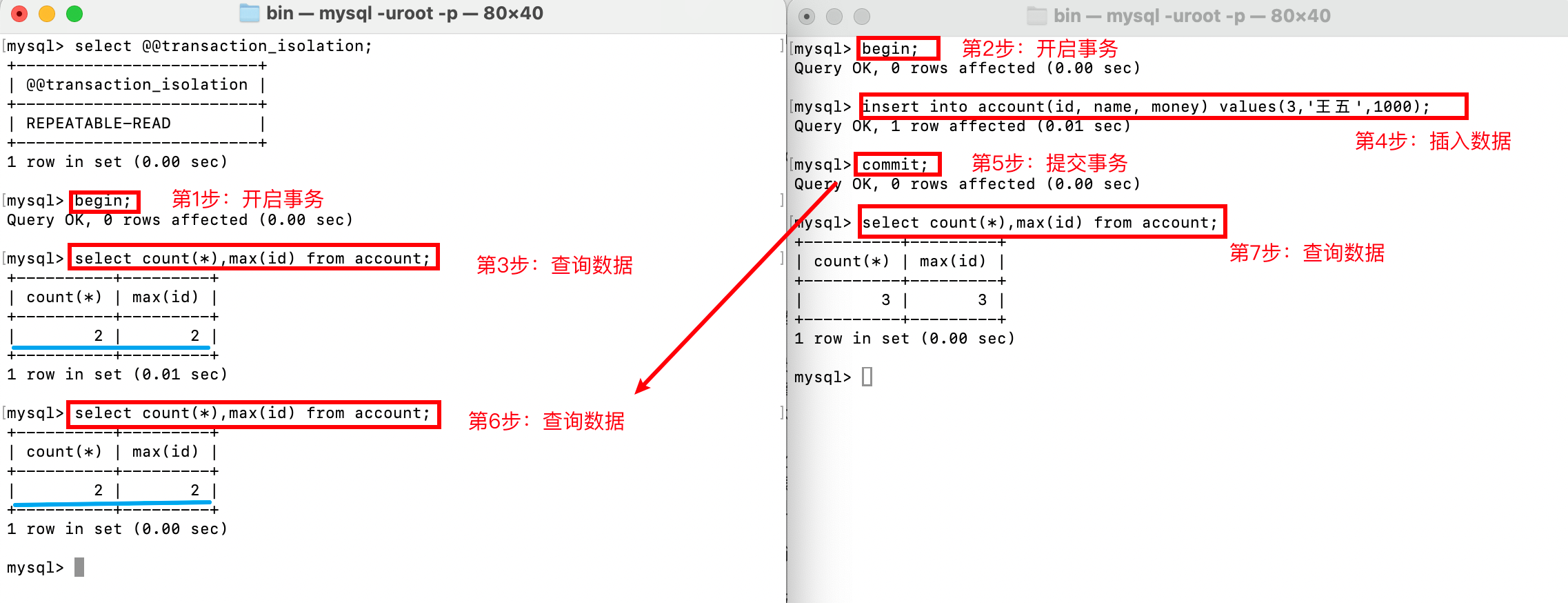
情形三,解决幻读问题,在下面的例子中,左边的事务先查询account表总数,右边的事务插入一条记录,左边的事务再次查询总数时,不变,因此没有出现幻读问题。(这个例子主要使用的技术是MVCC ReadView)。
情形四:未解决幻读问题
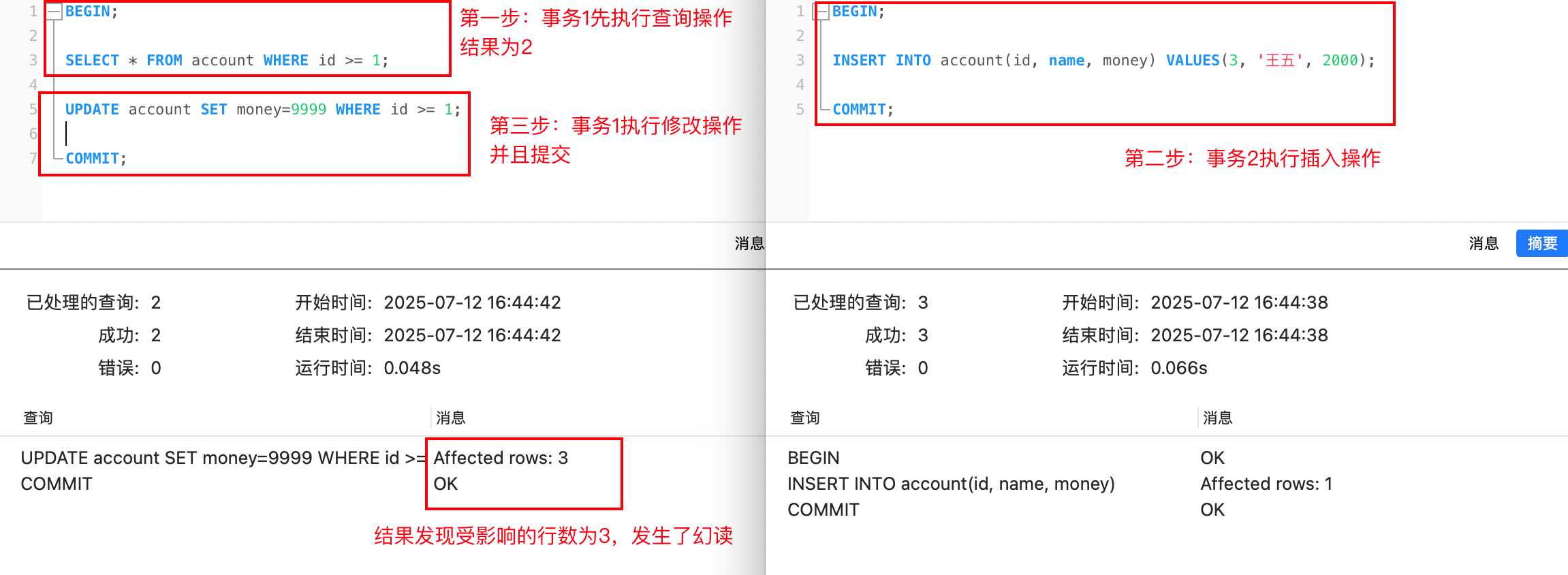
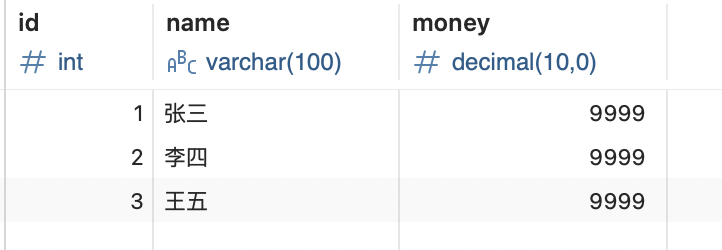
这种情况只是举出例外,mysql并没有完全解决幻读,但这种情况的影响,应视具体的业务而定。
2. 锁
在MySQL中,根据锁的粒度,可以分为行级锁、表级锁和全局锁。下面主要基于InnoDB执行引擎介绍锁的相关知识。
参考MySQL官方文档:https://dev.mysql.com/doc/refman/8.4/en/innodb-locking.html
在继续学习具体的锁之前,下面的命令可以显示当前数据库中的锁:
sql
SELECT object_schema, object_name, index_name, lock_type, lock_mode, lock_status, lock_data FROM `performance_schema`.data_locks;2.1 行级锁
2.1.1 共享锁与排他锁
注意,共享锁和排他锁的概念在表级锁中也适用。
行级锁按照锁是否共享,可以分为共享锁和排他锁:
- 共享锁(Shared Lock,简称S锁):允许获取共享锁的事务读取数据行;
- 排他锁(Exclusive Lock,简称X锁):允许获取排他锁的事务修改、删除数据行;
当某个事务T1获取了某行数据的S锁后,如果其他事务T2要获取同一行数据的S锁,那么可以成功获取;如果其他事务T2要获取同一行数据的X锁,那么需要等待。
当某个事务T1获取了某行数据的X锁后,如果其他事务T2不论想获取同一行数据的S锁还是X锁,都需要等待。
| S锁 | X锁 | |
|---|---|---|
| S锁 | 兼容 | 不兼容 |
| X锁 | 不兼容 | 不兼容 |
锁的升级与降级
当某个事务T1获取了某行数据的S锁后,如果此时没有其他事务持有同一行数据的S锁,那么此时T1对同一行数据加X锁,则可以成功加锁,这称为锁的升级;如果有其他事务持有同一行数据的S锁,那么T1对同一行数据加X锁,则需要等待。
当某个事务T1获取了某行数据的X锁后,如果之后T1再对同一行数据加S锁,则可以成功加锁,这称为锁的降级。
TIP
在MySQL中,我们可以在select ...后面加for update或for share,分别加X锁或S锁。
例如:
在事务1中执行下面的语句(加S锁):
sql
begin;
select * from account where id = 1 for share;然后打开另一个SQL编辑器,查询加锁情况,如下:

其中第二行数据,object_name是表名(account表),lock_type是锁记录(RECORD是行锁),lock_mode中的S锁就表示共享锁,lock_data表示是为id=1的行加的锁,lock_status为GRANTED表示已成功加锁。
如果我们再在事务1中执行下面语句(加X锁):
sql
select * from account where id = 1 for update;查询加锁情况,如下:

表示已成功加上了排他锁,即锁升级了。
2.1.2 锁的位置
根据锁的位置,在MySQL的InnoDB引擎,实现了记录锁、间隙锁、临键锁和插入意向锁。
首先准备测试数据:
sql
CREATE TABLE test_lock(
id INT PRIMARY KEY,
num INT
);
INSERT INTO test_lock(id, num) VALUES
(3,3),(8,3),(15,15),(20,100),(30,15);表数据如下,其中ID为主键,num为普通列,没有索引:
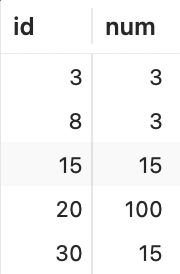
注意
在InnoDB实现中,锁的索引结构中的键值,所以有可能会对多行加锁。
由于InnoDB存在聚集索引,所以每张表肯定有一个索引。
记录锁(Record Lock):锁住记录行本身。在data_locks表中的lock_mode中,值为X,REC_NOT_GAP或S,REC_NOT_GAP即表示记录锁,分别为排他记录锁和共享记录锁;如果是记录锁,在data_locks表中的lock_data中,记录的是锁住的记录行的主键值(如果没有主键,则是唯一索引的键值或者是rowId)。
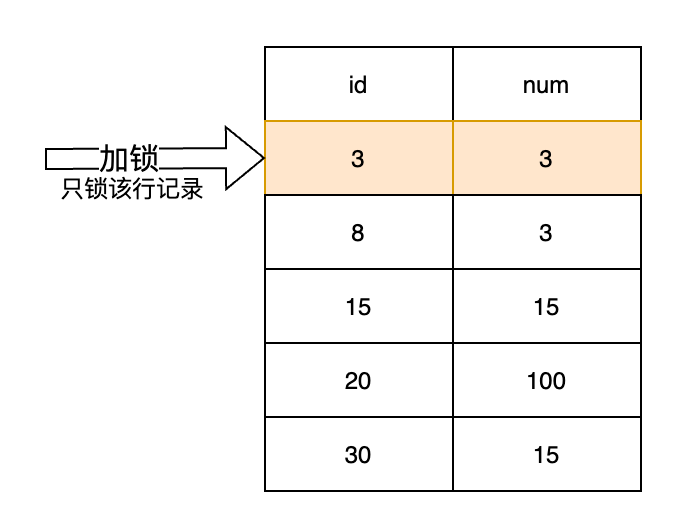
例如,执行下面的语句:
sql
BEGIN;
SELECT * FROM test_lock where id = 3 FOR UPDATE;查询data_locks表,表示在主键值为3的索引上(其实就是记录行)加上了锁,lock_mode为X,REC_NOT_GAP,表示加的是排他记录锁:

此时,其他事务要在这个记录上加锁,都会陷入等待状态,例如,另开一个事务,执行同样的语句,再次查询data_locks表:

可以看到data_locks中多了一条等待的锁记录。
如果我们对事务执行了COMMIT或ROLLBACK操作,会撤销锁记录。
同理,也可以对该行记录加共享锁(S锁,S,REC_NOT_GAP),此时其他事务也可以加S锁,不会阻塞。
sql
BEGIN;
SELECT * FROM test_lock where id = 3 FOR SHARE;
间隙锁(Gap Lock):锁住两个记录行之间的位置(即间隙),不允许其他事务在这个间隙之间插入数据,用来解决幻读问题。
间隙锁不区分共享锁和排他锁,即一个事务在一个间隙中间插入了间隙排他锁,其他事务也能对同一个间隙加锁。
在data_locks中,如果某行表示的是间隙锁,那么lock_mode的值为S,GAP或X,GAP,lock_data中记录的值表示在该记录行前面的间隙加锁。lock_data还有一个特殊值supremum pseudo-record,表示在当前表中最后一行之后的间隙加锁。
间隙锁的示例图如下:
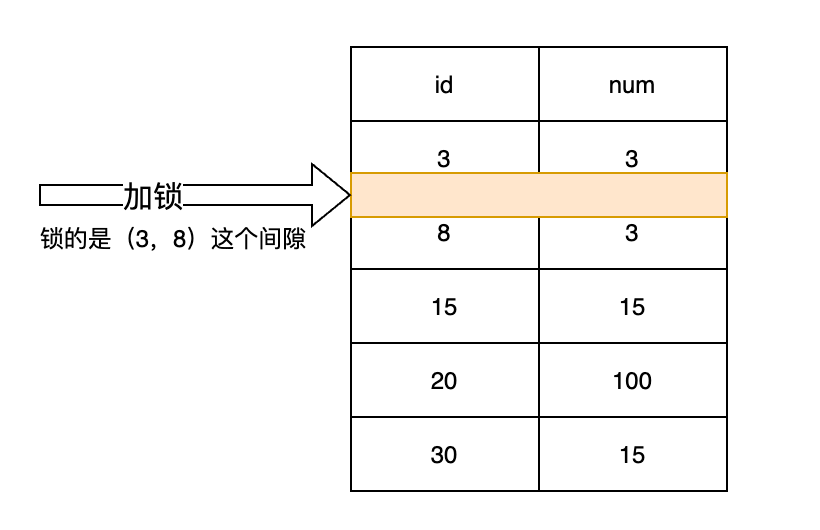
例如,在一个事务中执行如下语句:
sql
BEGIN;
SELECT * FROM test_lock where id = 5 FOR SHARE;
表示对主键值为8的记录行之前的间隙加锁,即不允许其他事务在这个间隙中插入数据。
接下来分别开启两个事务执行以下语句:
sql
BEGIN;
SELECT * FROM test_lock where id = 5 FOR UPDATE;可以看到两个事务都对同一个间隙加上了间隙排他锁,说明间隙锁不区分共享锁和排他锁:

临键锁(next-key Lock):是记录锁+间隙锁的组合,在data_locks表中的lock_mode中,值为X或S即表示记录锁,分别为排他临键锁和共享临键锁;lock_data中的值表示要锁定的记录行,以及该记录行之前的间隙。
示意图如下:
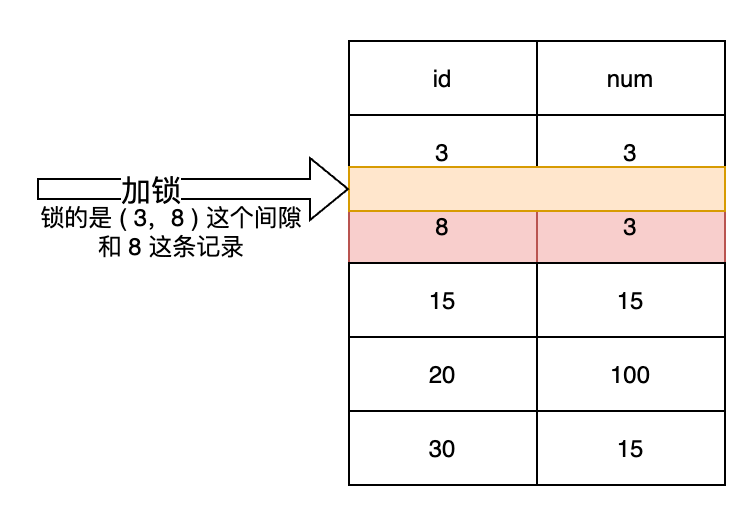
在事务中执行下面的语句:
sql
BEGIN;
SELECT * FROM test_lock where id > 3 AND id <= 8 FOR UPDATE;
再比如,在事务中执行下面的语句:
sql
BEGIN;
SELECT * FROM test_lock where id > 35 FOR UPDATE;
表示在虚拟行(主键值最大)及其前面的间隙加锁。
再比如,在事务中执行以下语句:
sql
BEGIN;
SELECT * FROM test_lock where id <= 8 FOR UPDATE;
在锁记录表中有两条记录,上面的语句表示应该在记录行8(主键值为8)及其前面的间隙(从INT.MIN_VALUE到8的间隙)加锁,但由于表中存在3这条数据,导致间隙被分隔成了两部分,所以实际的间隙为( INT.MIN_VALUE, 3 ]和( 3,8 ],因此表中存在两个记录行。
插入意向锁(Insert Intention Lock):是一种特殊的行级锁,它属于间隙锁 (Gap Lock) 的一种。它是在事务执行 INSERT 操作之前,在被插入行所在的间隙上设置的一种意向锁,表示一个事务打算在该间隙中插入新行。
插入意向锁之间是互相兼容的。这意味着多个事务可以同时在一个间隙中设置插入意向锁,因为它们都打算在该间隙的不同位置插入新行。
插入意向锁会与现有的间隙锁或临键锁冲突。如果一个事务在一个间隙上持有间隙锁或临键锁,那么其他事务(本事务是可以插入新行的)就不能在这个间隙中设置插入意向锁,从而无法插入新行。
如果某个事务A可以获得插入意向锁,说明此时没有其他事务持有该间隙的间隙锁或临键锁,此时事务A成功插入新行,并在该新行上设置一个记录排他锁(X,REC_NOT_GAP),防止新插入的行被其他事务立即修改或删除,然后撤销插入意向锁,因此,在data_locks表中是看不到插入意向锁的。如下,在一个事务中执行下面的语句:
sql
BEGIN;
INSERT INTO test_lock VALUES(5,5);
可以看到,是没有行级锁记录的,即没有插入意向锁。
然后另一个事务继续在该间隙插入数据:
sql
BEGIN;
INSERT INTO test_lock VALUES(6,6);此时插入的新行不冲突,因此该事务不会被阻塞,同样也看不到插入意向锁:

但是,如果另一个事务插入了同样主键值的数据呢?
sql
BEGIN;
INSERT INTO test_lock VALUES(5,6);可以发现该事务被阻塞,而且锁记录如下:

为什么第二个事务是在尝试获取S锁(共享锁)呢?因为第二个事务插入的时候需要检查是否有该主键值的行,做的是读取操作,所以是S锁。当第一个事务提交后,第二个事务获得到锁,从而成功执行读取操作,发现已经有该主键值的行存在了,会抛出重复主键的错误。
下面我们来演示间隙锁/临键锁与插入意向锁之间的冲突:
首先一个事务先获取间隙锁/临键锁:
sql
BEGIN;
SELECT * FROM test_lock where id = 5 FOR UPDATE;然后另一个事务尝试在该间隙之间插入数据:
sql
BEGIN;
INSERT INTO test_lock VALUES(5,6);会发现该事务被阻塞,锁记录表如下:

其中可以看到,在lock_mode中有关键字INSERT_INTENTION,表示插入意向锁,并且lock_status是WAITING,lock_data为8,表示要在8之前的间隙中插入新数据,但是该间隙目前被其他事务锁住了,只能等待。
如果第一个事务提交或回滚后,则第二个事务成功获得意向锁,并且获得后会插入新行:

WARNING
注意,此时第二个事务的锁记录还保存着,并且lock_mode中有X,GAP,感觉第二个事务还持有间隙锁。
但实际上,第二个事务没有持有间隙锁。
我们可以开第三个事务验证,再次在该间隙插入新行:
sql
BEGIN;
INSERT INTO test_lock VALUES(6,6);没有被阻塞!!!
有点奇怪,状态不一致,应该算bug吧。
2.1.3 范围加锁
在上面的例子中,我们都是使用唯一索引(包括主键索引),下面来看看非唯一索引和非索引列的加锁情况。
首先,需要明确的是,在num上没有索引,此时我们执行下面语句:
sql
BEGIN;
SELECT * FROM test_lock where num = 15 FOR UPDATE;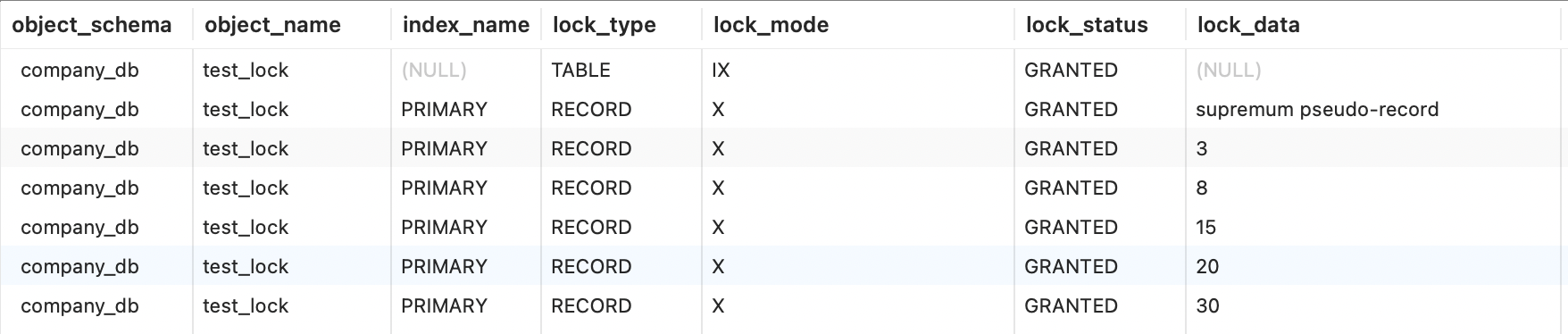
由于num上没有索引,所以MySQL需要进行全表扫描,此时会对所有扫描过的行加锁,并且之后会尽快对不满足查询条件的行解锁。
然而,在某些特定的情况下,即使某行不符合条件,它上面的锁也可能不会立即释放。这是因为在查询执行过程中,结果行与其原始数据源之间的关联可能会丢失。
例如,当使用 UNION 操作时,MySQL 常常会将各个 SELECT 语句的结果集先存储到一个临时表中,然后再对这个临时表进行去重、排序等操作,最终形成结果集。
如果
UNION中的某个SELECT ... FOR UPDATE或FOR SHARE子句扫描并锁定了某些行。这些被锁定的行在被送入临时表之前,可能还没有完全经过所有
WHERE子句条件的评估。一旦这些行的数据进入临时表,它们与原始表的行之间的直接“关系”(即它们是哪个原始行拷贝过来的)就丢失了。
由于这种关系的丢失,
InnoDB无法在临时表处理过程中判断哪些原始行最终没有进入结果集,从而也无法立即释放那些不符合条件的原始行上的锁。因此,这些锁会一直保留,直到整个查询语句(包括
UNION操作)执行结束,即事务结束时才会统一释放。
因此,对非索引列进行加锁查询,有可能导致锁住所有行,即锁表,这对于并发效率有着重大影响。
然后,我们在num列上加常规索引:
sql
CREATE INDEX idx_test_lock_num ON test_lock(num);然后再次执行下面的语句:
sql
BEGIN;
SELECT * FROM test_lock where num = 15 FOR UPDATE;
在上面的锁记录中按照index_name分为两部分:idx_test_lock_num和PRIMARY。
第2条记录,index_name为idx_test_lock_num,lock_type为RECORD,lock_mode为X,GAP,lock_data为100,20(100是num索引中的键值,20是主键索引的键值),表示对num索引中的记录100前的间隙加间隙锁。
同理,后面两天记录表示对(3, 15]加锁,即临键锁。
合并上面三条记录,即表示在idx_test_lock_num中( 3, 15 ] 和[ 15, 100 )这个范围加锁。
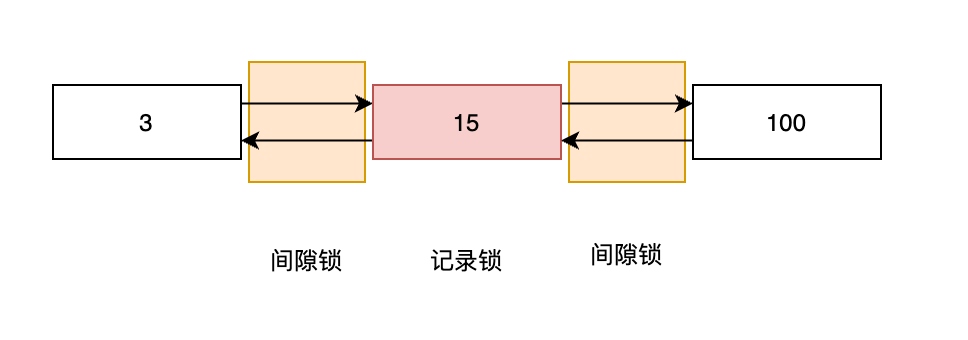
为什么要在15前后的间隙加锁呢?因为num是常规索引,键值有可能重复,如果不对前后间隙加锁,那么其他事务有可能在前后间隙插入相同键值(此处为15)的记录,那么就不能解决幻读问题了。
之后,MySQL再根据idx_test_lock_num中获取到的主键值,去主键索引加锁,此时加的是记录锁,对应着锁记录表中最后两行。
小结:
- 对于聚集索引,如果结果集只返回一行,那么会对该行加上记录锁;
- 对于聚集索引,但是结果集返回零行或多行,则会加上间隙锁或临键锁;
- 对于唯一索引,如果结果集只返回一行,那么会在唯一索引上加记录锁,在聚集索引上加记录锁;
- 对于唯一索引,如果结果集返回零行,则会在唯一索引上加间隙锁或临键锁,不会在聚集索引上加锁。如果结果集返回多行,会在唯一索引上加临键锁,在聚集索引上加记录锁;
- 对于常规索引,会在常规索引加上间隙锁或临键锁,会在聚集索引上加上记录锁或不加锁;
- 对于非索引列,则会锁全表;
2.1.4 不同语句的加锁情况
上面我们只研究了select和insert语句的加锁情况,下面我们再看看其他语句的加锁情况。
常规读:常规读就是select ...语句,不会加锁。
加锁读(locking read):加锁读就是select ... for update或select ... for share,会加临键锁,视情况退化为记录锁或间隙锁。
update语句:对于update ... where语句,会对满足条件的记录加排他临键锁,视情况退化为记录锁或间隙锁。
delete语句:对于delete from ... where语句,会对满足条件的记录加排他临键锁,视情况退化为记录锁或间隙锁。
insert语句:首先会加插入意向锁,然后对新插入的行加排他记录锁。
2.2 表级锁
表级锁可以划分为表锁、元数据锁和意向锁。
2.2.1 表锁
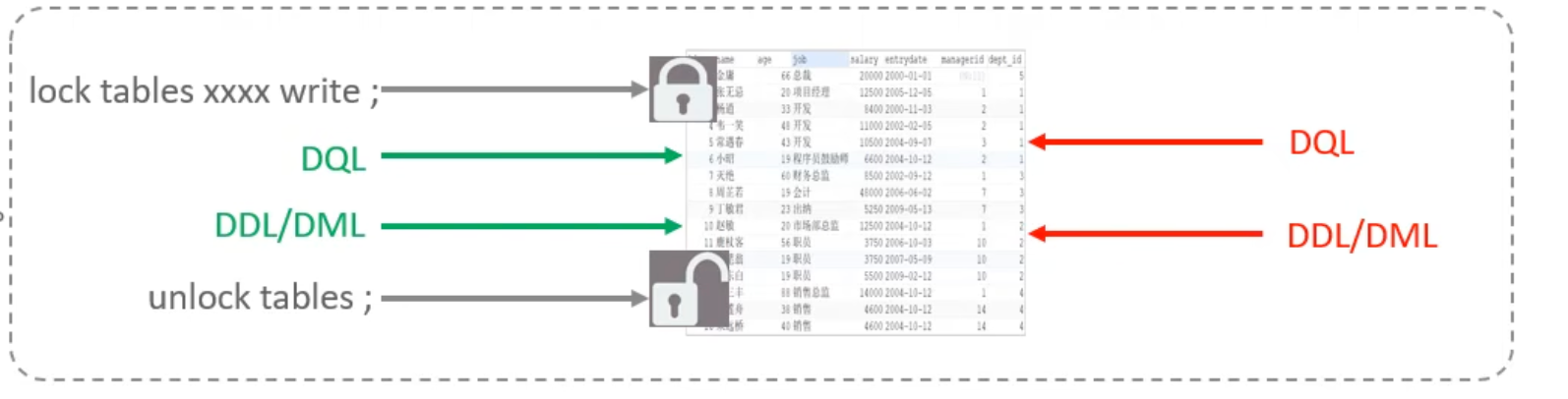
表锁分为两类:共享锁和排他锁,也称为读锁和写锁。
使用如下语法加解表锁:
sql
lock tables 表名1,表名2... read / write; -- 加表锁
unlock tables; -- 解表锁对于读锁,当一个事务加读锁后,该事务和其他事务可以查询表中数据,但是该事务和其他事务不能修改表中数据:
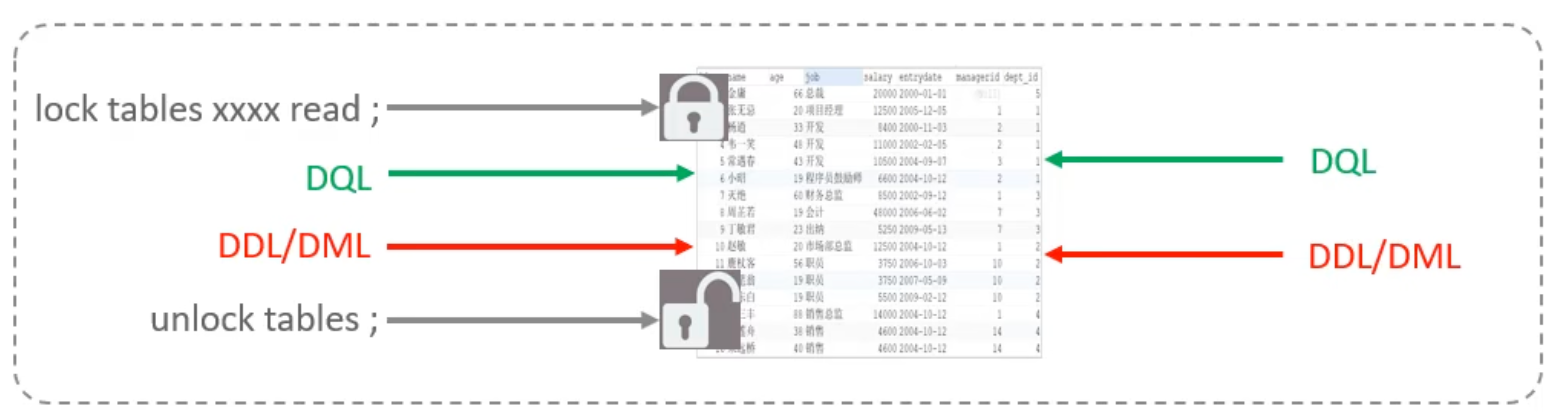
对于写锁,当一个事务加写锁后,该事务可以读取和修改表中数据,但是其他事务不能读取和修改表中数据:
2.2.2 元数据锁
元数据锁(Metadata Locks,简称MDL),主要用于维护数据库对象(表、视图、存储过程等)的元数据(结构)一致性。
MDL加解锁过程是系统自动控制的,无需显式使用,在访问一张表的时候会自动加上。
下表显示了不同语句会加的MDL锁:

当某个事务使用alter table语句修改表元数据时,其他事务不允许在该表上执行任何操作。
可以使用以下语句查看元数据锁:
sql
SELECT object_schema, object_name, object_type, lock_type, lock_status
FROM `performance_schema`.metadata_locks;2.2.3 意向锁
意向锁是 InnoDB 存储引擎特有的,它也是一种表级锁,但其目的并非直接锁定表数据,而是为了协调表级锁和行级锁的兼容性。
假设现在有一个场景,事务A对表中某行数据加了行级锁,如果此时事务B要对整张表上锁,那么需要扫描表中所有行,来判断是否可以加锁,这显然效率低下:
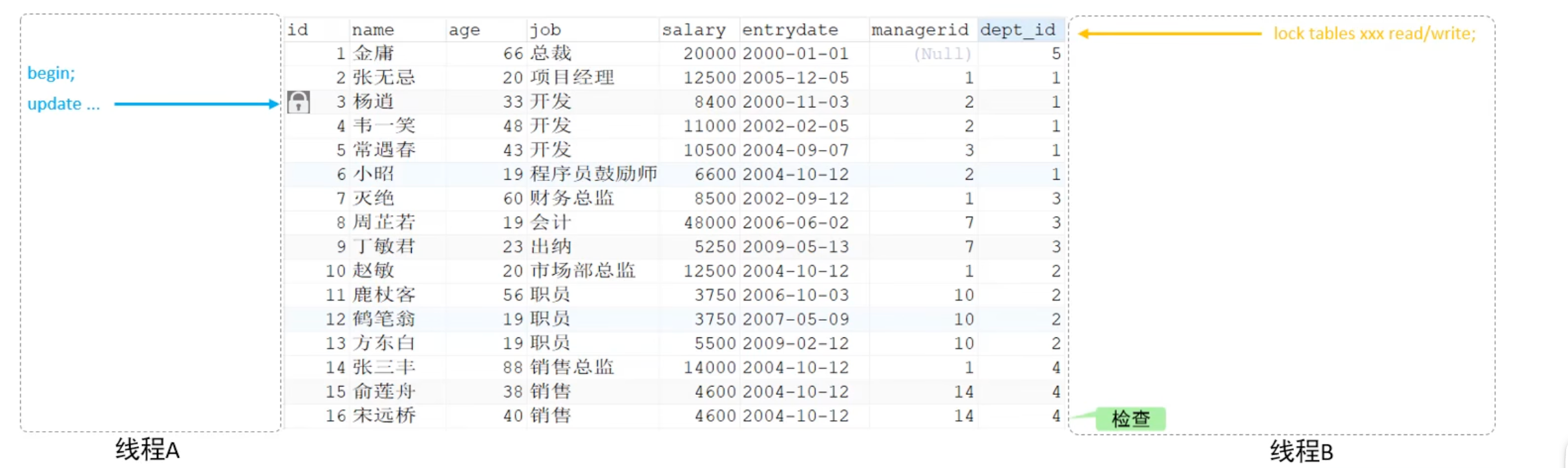
因此意向锁的作用是为了减少加表锁时的检查,使得加表锁时不用检查每行数据是否加锁。在加行锁前,会对整张表加意向锁,即快速告知其他事务,当前表上正在发生行级锁操作。
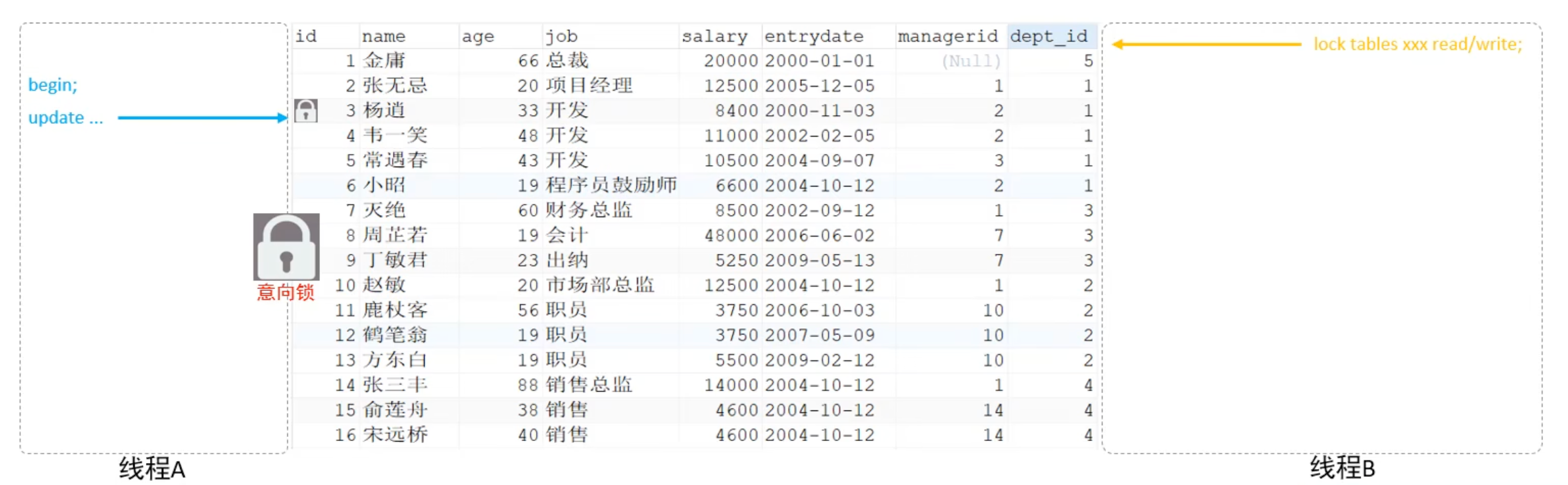
当其他事务要加表级锁时,只需要判断当前表的意向锁和要加的表锁是否冲突。
意向锁也可以分为意向读锁(Intention Shared Lock,简称IS )和意向写锁(Intention Exclusive Lock,简称IX)。其与表的读锁(S)和写锁(X)兼容情况如下:
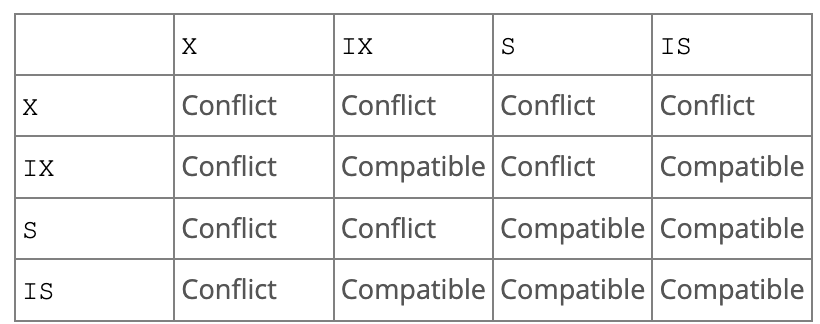
- 意向锁之间是兼容的;
- 意向读锁和读锁是兼容的;
- 读锁和读锁是兼容的;
- 其他都是不兼容的;
2.3 全局锁
在 MySQL 中,全局锁 (Global Lock) 是一种对整个数据库实例加锁的机制。它通常通过执行 FLUSH TABLES WITH READ LOCK 命令来启用,通过UNLOCK TABLES来解锁。
当全局锁生效时,整个 MySQL 数据库将处于只读状态。这意味着:
- 所有数据的增、删、改操作(INSERT, DELETE, UPDATE)都会被阻塞。
- 所有表结构的更改操作(ALTER TABLE, DROP TABLE 等)也会被阻塞。
- 只有查询操作(SELECT)可以正常执行。
全局锁的主要应用场景是进行全库逻辑备份(使用工具mysqldump)。
为什么需要全局锁进行全库逻辑备份?
在进行数据库备份时,如果数据和表结构在备份过程中发生变化,可能导致备份文件的数据不一致或不完整。举个例子:
- 开始备份用户表的数据。
- 此时,有用户发起了一笔购买操作,这涉及到更新用户表的余额和商品表的库存。
- 用户表余额更新完成后,继续备份商品表的数据。
这种情况下,备份的用户表数据是购买前的状态,而备份的商品表数据是购买后的状态,导致备份文件中的数据前后不一致。
通过在备份期间加上全局锁,可以确保整个数据库在备份过程中保持静态,从而获得一致性的备份数据。
全局锁的缺点:
尽管全局锁对于数据一致性备份很有用,但它有一个非常显著的缺点:**会造成业务停滞。**在备份期间,由于整个数据库处于只读状态,所有需要写入操作的业务都会被阻塞,导致业务无法正常进行。对于大型数据库和需要长时间备份的场景,这会严重影响线上业务的可用性。
参考资料
[1] https://www.bilibili.com/video/BV1Kr4y1i7ru
[2] https://dev.mysql.com/doc/refman/8.4/en/innodb-locking.html