Appearance
MySQL 存储引擎
本文介绍MySQL存储引擎相关知识,并着重介绍InnoDB存储引擎。
1. MySQL体系结构
MySQL是C/S架构,在服务端,主要分为四层:连接层、服务层、引擎层和存储层,如下:
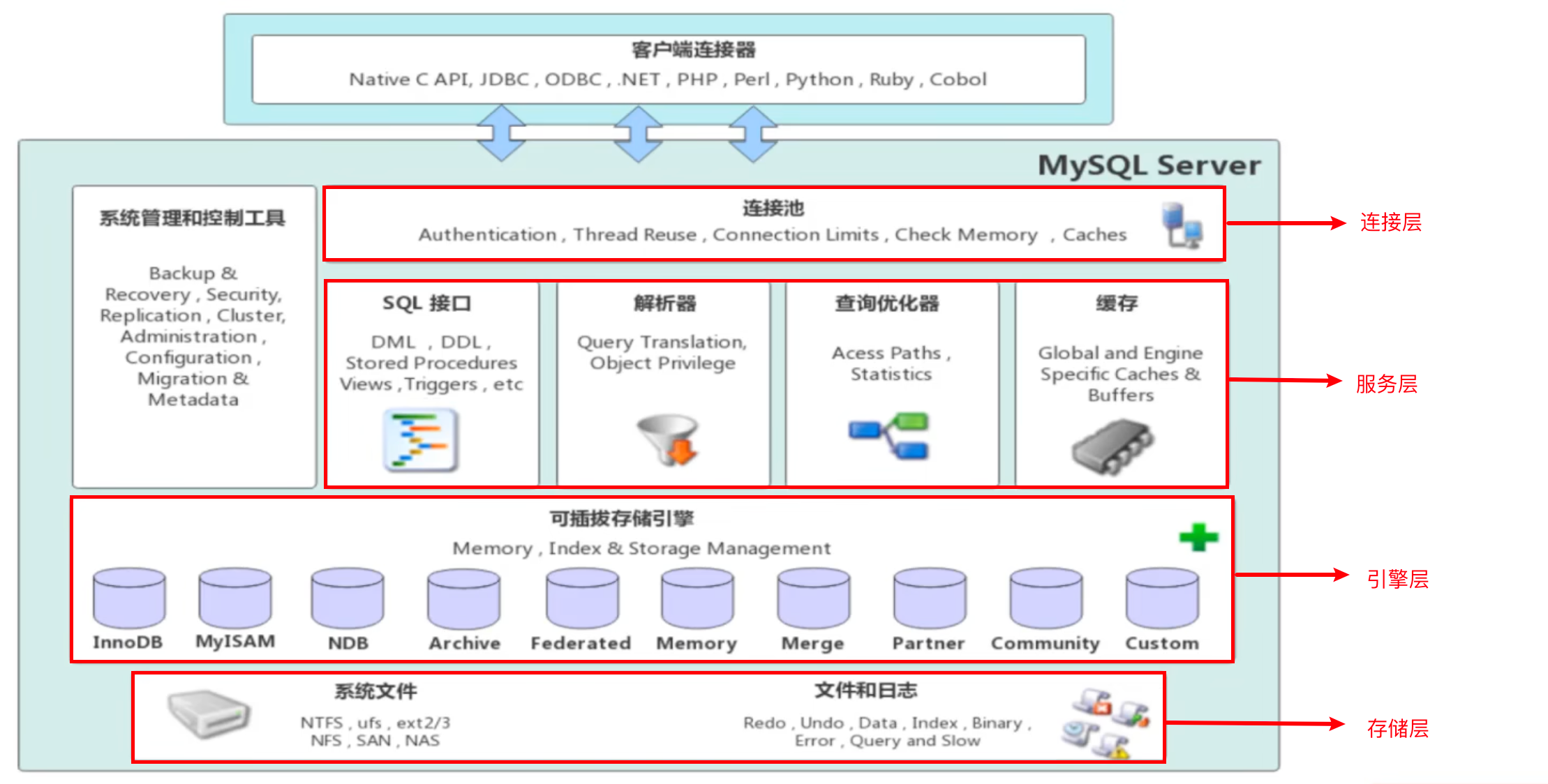
连接层:连接层负责处理客户端与 MySQL 服务器之间的连接和通信。
服务器端会为每个客户端连接创建一个独立的线程来处理其请求。连接管理器负责连接的建立、认证、授权以及断开连接。
服务层:这是 MySQL 体系结构的核心,包含了大部分的 MySQL 核心功能,例如查询解析、优化、缓存以及所有跨存储引擎的功能。
连接池: 用于管理和复用客户端连接,避免频繁创建和销毁连接的开销。
查询缓存 (Query Cache - MySQL 8.0 已移除): 在 MySQL 8.0 之前的版本中,查询缓存会将查询语句及其结果缓存在内存中。当接收到相同的查询请求时,直接从缓存中返回结果,跳过后续的处理步骤。但在高并发和数据经常变化的场景下,查询缓存的维护开销非常大,所以 MySQL 8.0 移除了此功能。
解析器 (Parser): 负责解析客户端发送的 SQL 语句。它会将 SQL 语句进行词法分析(分解成一个个 token)和语法分析(根据 SQL 语法规则生成一个解析树或抽象语法树)。
预处理器 (Preprocessor): 在解析器之后,预处理器对解析树进行进一步处理,例如检查表名、列名、函数名是否存在,权限是否足够,数据类型是否正确等。它还会进行一些查询改写,例如处理
UNION、VIEW等。查询优化器 (Optimizer): 这是 MySQL 服务器层最重要的组件之一。优化器负责生成执行 SQL 语句的最佳执行计划。它会考虑多种因素,例如:
- 如何使用索引
- 表的连接顺序(JOIN ORDER)
- 数据扫描方式(全表扫描、索引扫描等)
- 子查询的优化
- 成本估算,选择成本最低的执行计划
- 可以通过
EXPLAIN命令来查看优化器生成的执行计划
查询执行引擎 (Query Execution Engine): 优化器生成执行计划后,执行引擎负责按照执行计划执行 SQL 语句。服务层会调用存储引擎的接口来完成数据的读取和写入操作。
日志系统 (Log System): MySQL 服务器层维护多种日志文件,用于不同的目的:
- 错误日志 (Error Log): 记录服务器启动、运行、关闭过程中的错误、警告和关键信息。
- 慢查询日志 (Slow Query Log): 记录执行时间超过设定阈值的 SQL 查询,用于性能调优。
- 通用查询日志 (General Query Log): 记录所有发送到 MySQL 服务器的 SQL 语句,用于审计和调试。
- 二进制日志 (Binary Log / Binlog): 记录所有更改数据库数据的事件(例如
INSERT、UPDATE、DELETE等),不记录SELECT。Binlog 是 MySQL 主从复制和数据恢复的基础。
引擎层:负责实际的数据存储和检索、索引的建立与维护。
- 插件式架构: MySQL 允许用户为不同的表选择不同的存储引擎,每个存储引擎有其独特的功能和性能特点。
- 存储引擎 API: 服务器层通过存储引擎 API 与底层的存储引擎进行交互,例如执行
SELECT、INSERT、UPDATE、DELETE等操作。 - 主要的存储引擎如下:
- InnoDB (默认): 支持事务(ACID)、行级锁、外键、崩溃恢复等,适用于大多数高并发、高可靠性的 OLTP(联机事务处理)应用。
- MyISAM: 不支持事务、表级锁、读性能高,适用于读多写少、对数据一致性要求不高的 OLAP(联机分析处理)或归档应用。
- MEMORY: 数据存储在内存中,速度极快但数据易失,适用于临时表或缓存。
存储层:负责存储实际的数据文件和日志文件。不同的存储引擎会以不同的方式在文件系统上组织数据。可以分为如下几类文件:
结构文件:存储表的结构。
数据文件: 存储表中的实际数据。
索引文件: 存储表的索引信息。
日志文件: 包括前面提到的各种日志文件(错误日志、慢查询日志、Binlog 等)。
配置参数文件: 存储 MySQL 服务器的各种配置信息。
2. 存储引擎介绍
2.1 概述
在MySQL中,存储引擎就是存储数据、更新/查询数据、维护索引的实现方式。存储引擎是基于表的,也就是说,每张表都可以有自己的存储引擎,所以存储引擎也被称为表类型。
在建表时,我们可以指定存储引擎:
sql
create table 表名(
列声明...
) engine = 存储引擎名;使用engine关键字设置存储引擎。
我们可以使用以下命令查看数据库支持的存储引擎:
sql
show engines;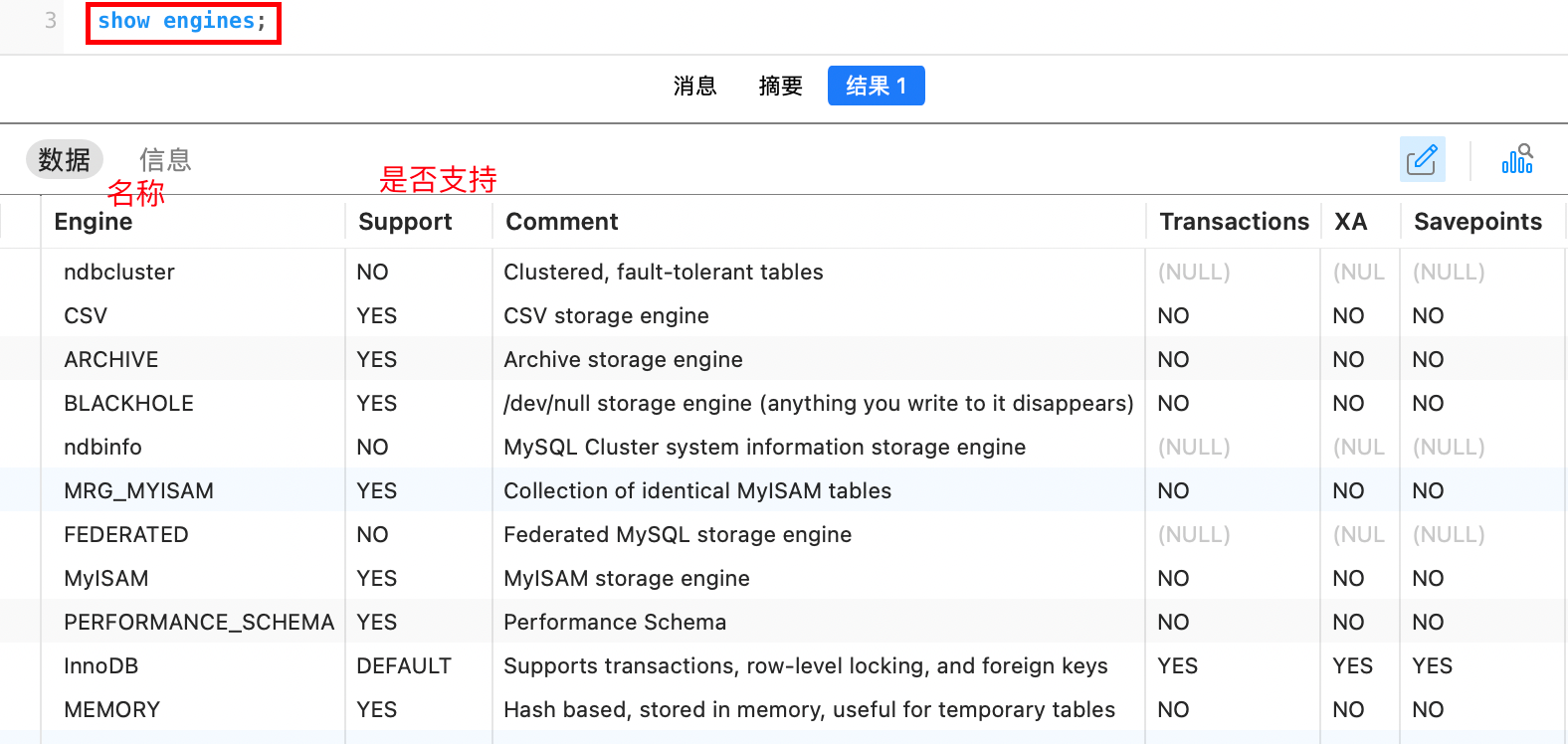
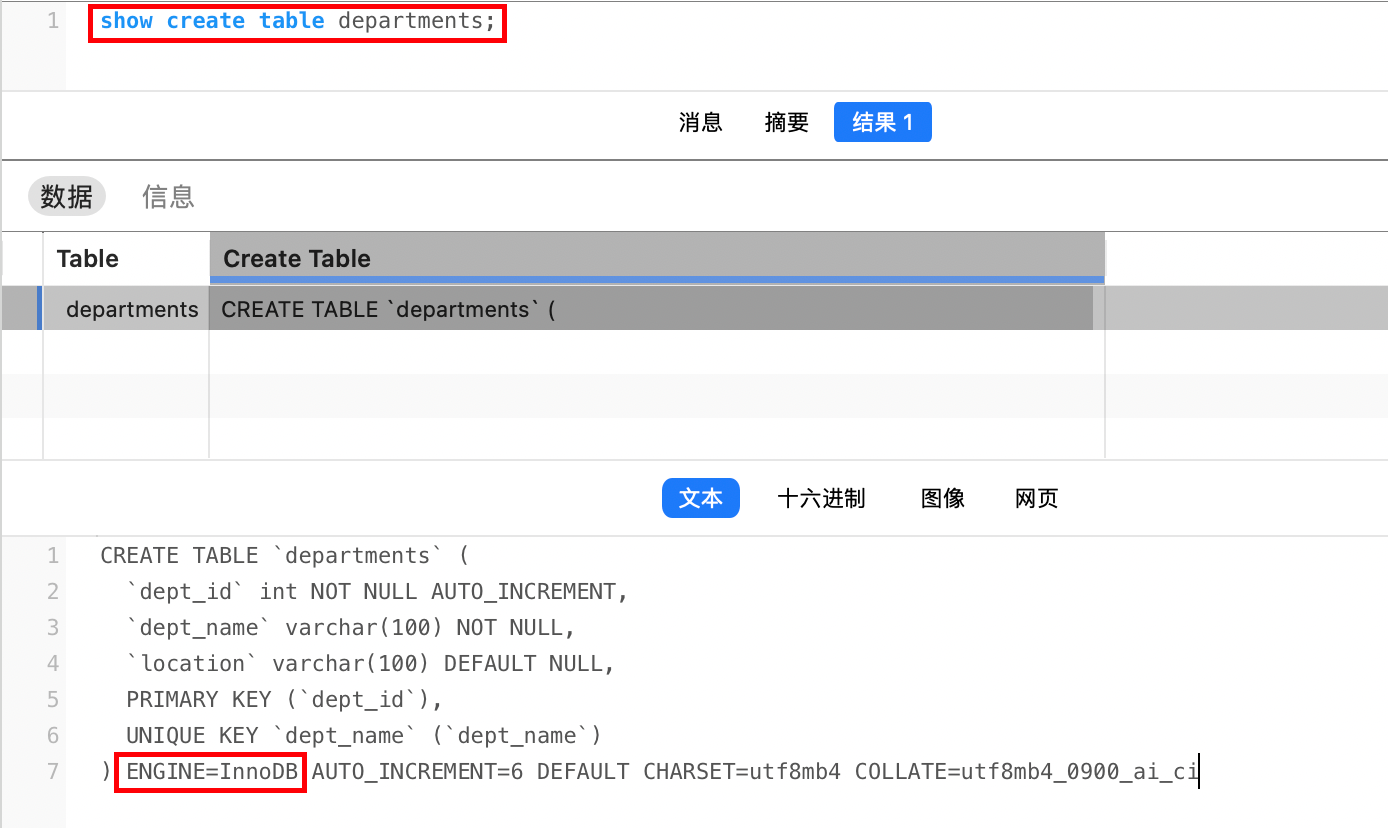
当想查看某个表的存储引擎时,我们可以通过如下命令显示:
sql
show create table 表名;例如:
当然,假设我们使用如Navicat这种图形化数据库管理软件,可以直接查看表的存储引擎:
接下来就介绍三种存储引擎:InnoDB、MyISAM、MEMORY。
2.2 InnoDB
在 MySQL 5.5 版本之后,InnoDB 成为默认的存储引擎,是一种兼顾高可靠性和高性能的通用存储引擎。具有以下特点:
- DML操作遵循ACID模型,支持事务;
- 支持行级锁,意味着在并发写入时,只有被修改的行会被锁定,而不是整张表,大大提高了并发性能;
- 支持外键,允许定义表之间的参照完整性约束,确保数据的一致性;
当创建了一张使用InnoDB作为存储引擎的表后,会在文件系统上生成一个xxx.idb文件,xxx代表的是表名,idb文件是一个二进制文件,其中存储着表的结构、数据和索引。
2.3 MyISAM
MyISAM是MySQL早期的默认存储引擎。具有如下特点:
- 不支持事务;
- 不支持外键;
- 支持表锁,不支持行级锁;
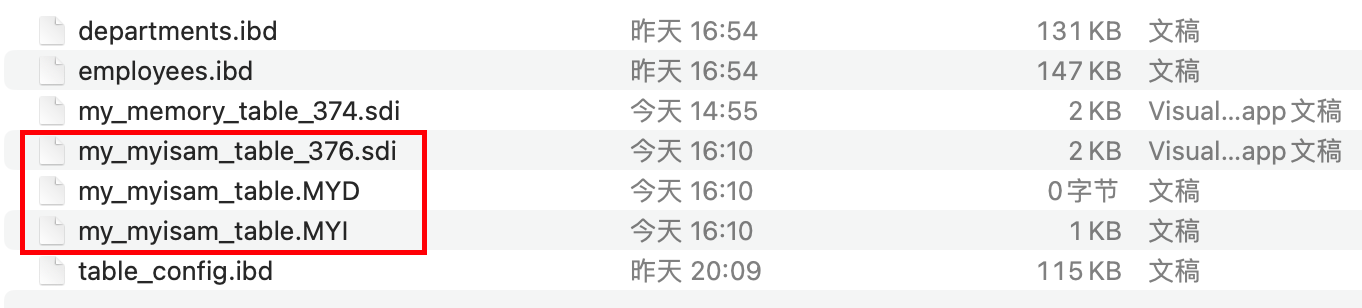
每张 MyISAM 表在磁盘上通常对应三个文件:.sdi (表结构定义)、.MYD (数据文件) 和 .MYI (索引文件):
2.4 MEMORY
MEMORY引擎的表数据存储在内存中,因此,MySQL服务重启或崩溃后,MEMORY表中的数据会丢失。MEMORY引擎默认使用哈希索引。
因为MEMORY引擎表的数据存放在内存中,具有极快的读写性能,适合将这些表作为临时表或缓存使用。
每张 MEMORY 表在磁盘上通常对应一个文件:.sdi (表结构定义),因为数据存放在内存中。
2.5 小结
在当今的数据库应用中,InnoDB 已经成为主流且推荐的存储引擎。 它在大多数情况下,包括复杂的读写混合负载、高并发环境以及对数据完整性有要求的情况下,都提供了稳定高效的性能。
如果想使用MyISAM引擎,推荐使用MongoDB数据库作为替代;如果想使用MEMORY引擎,推荐使用Redis数据库作为替代。
因此,下文会着重介绍InnoDB存储引擎。
3. InnoDB介绍
3.1 逻辑存储结构
在InnoDB中,按照以下的层次结构组织数据:
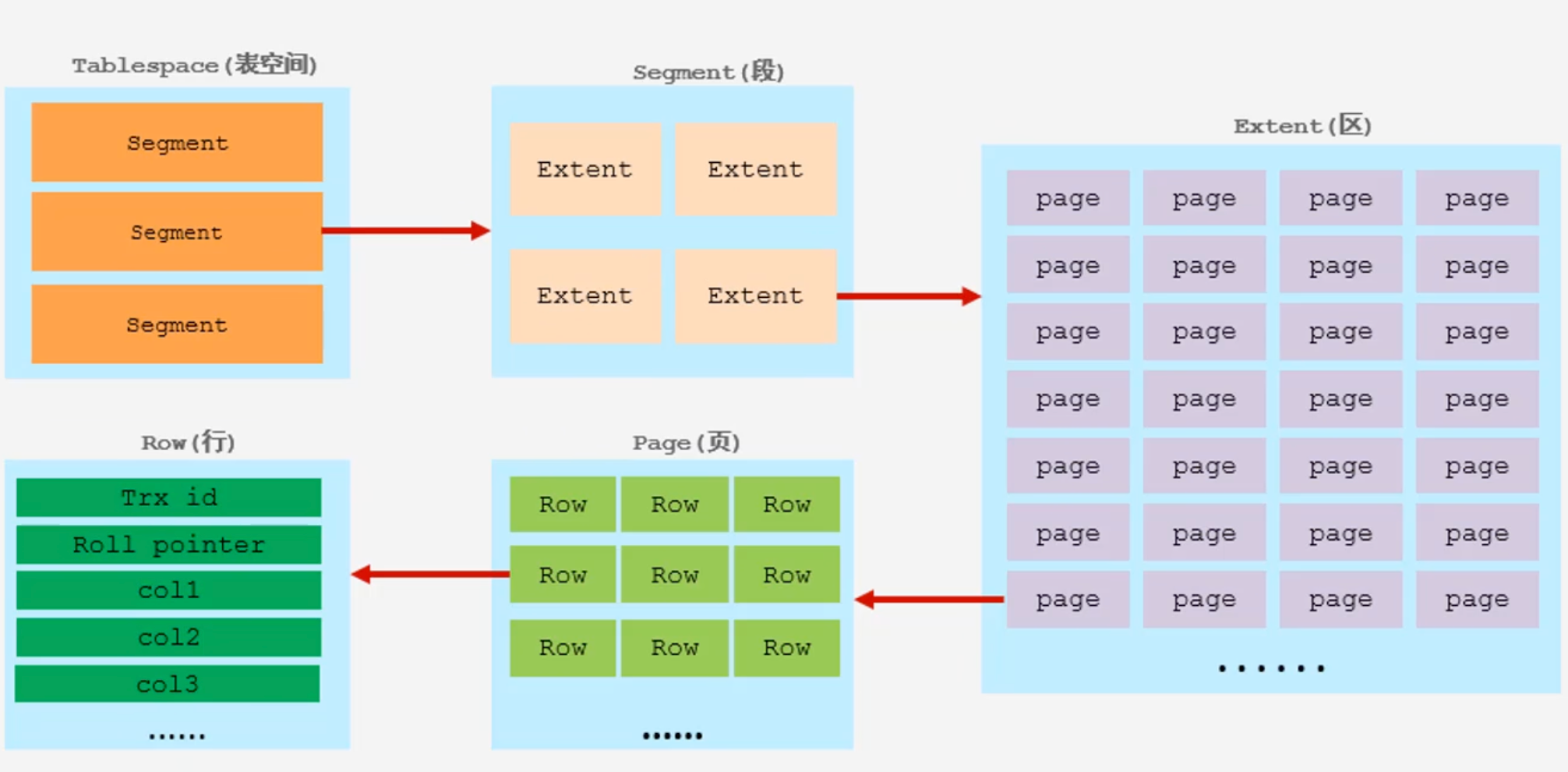
表空间(TableSpace),这是一个逻辑概念,所有 InnoDB 表的数据和索引都存储在表空间中。对应着磁盘中的一个或多个文件。
例如,MySQL数据目录下的
ibdata1就是一个表空间,undo_001和undo_002是两个表空间,以.ibd结尾的文件就是一个表空间。页(Page):在 InnoDB 的表空间中,**数据是以页(page)为单位组织和管理的,**也就是说,一个表空间中实际包含多个页。每个页大小通常是 16KB(默认,可以修改)。所有数据(数据行、索引、表空间元数据、管理信息、UNDO日志等)都是存储在页中的,因此,页有多种类型,不同类型的页有不同的结构,但大致结构如下:

行(Row):行在这里表示实际的数据行,就是我们表中的记录。InnoDB除了保存实际的数据外,还会添加一些隐藏列,比如
Trx_id,Roll Pointer。行的最大长度略微小于页大小的一半,也就是说在数据页中,最少存储两行数据。行存储也分为不同的格式。区(Extent):我们先来看看这样一个场景,假设我们执行下面的语句:
sqlselect * from stu where age <= 20;总共查出20行数据,但这20行数据分属于20个页,那么就要在磁盘中找到这20个页,这个找就大有说法了。
随机找:即页的分布是不连续的,一个位于表空间位置1,一个位于表空间位置18,一个位于表空间位置70,一个位于表空间100......随机找磁盘磁头就需要不断地移动来“跳跃”读取这些不连续的页,这种频繁的磁头寻道操作就是随机 I/O,它的性能非常低。
规律找:即页的分布是连续的,一个位于表空间位置1,一个位于表空间位置2,一个位于表空间位置3......即20个页按顺序摆放。当需要读取这些数据时,磁盘磁头可以进行一次性长距离的顺序读取,而不需要频繁地跳跃。顺序 I/O 比随机 I/O 快得多,因为它减少了磁头寻道和旋转等待的时间。
所以,**区(Extent)**的提出就是为了解决随机IO问题。
默认情况下,64个连续页(页大小为16KB)组成一个区,即一个区的大小是1MB。InnoDB 按区为单位来分配空间。
区的大小也是可变的:
对于页大小小于或等于 16KB 的情况,一个区的大小是 1MB。
16KB 页:1MB = 64 个 16KB 页 (1024KB / 16KB = 64)。
8KB 页:1MB = 128 个 8KB 页 (1024KB / 8KB = 128)。
4KB 页:1MB = 256 个 4KB 页 (1024KB / 4KB = 256)。
对于 32KB 页,一个区的大小是 2MB。
对于 64KB 页,一个区的大小是 4MB。
注意:并不是所有的页都属于某个区(例如,文件空间头部页 (FSP_HDR Page),通常是每个表空间的第 0 号页,包含了表空间的全局元数据,如空闲区列表等),区的提出只是为了顺序分配页而已,对于大部分存储数据的页,都是属于某个区的。
段(Segment):页和区的概念都可以在物理磁盘文件结构上得到反映,段是纯概念,段是对一系列属于同一逻辑对象的页和区的抽象和归类。
数据库中的核心对象是表和索引。一个表可能非常大,一个索引也可能非常复杂(B+ 树结构)。这些逻辑对象的数据可能分散在表空间中不连续的区和页上。段的作用就是将这些物理上可能不连续的页和区,从逻辑上“归属”到同一个表或索引的特定部分。例如,一个索引的叶子节点可能分散在多个区中,但它们都属于“这个索引的叶子节点段”。
在InnoDB中,每个索引都需要两个独立的段来存储其复杂的树形结构:一个用于非叶子节点,一个用于叶子节点。
当一个新的段(例如一个新的表或索引)刚刚创建时,它需要一些初始空间。为了避免浪费一个完整的 1MB 区,InnoDB 会先分配 32 个单独的页给这个段。这些页可能不是连续的,它们是从一个特殊的“自由碎片列表 (free fragment list)”中获取的。之后,InnoDB就会分配一个完整的区给段,InnoDB支持一次性最多分配4个区给段。
3.2 InnoDB架构
下图展示了InnoDB的架构,分为内存结构和磁盘结构。
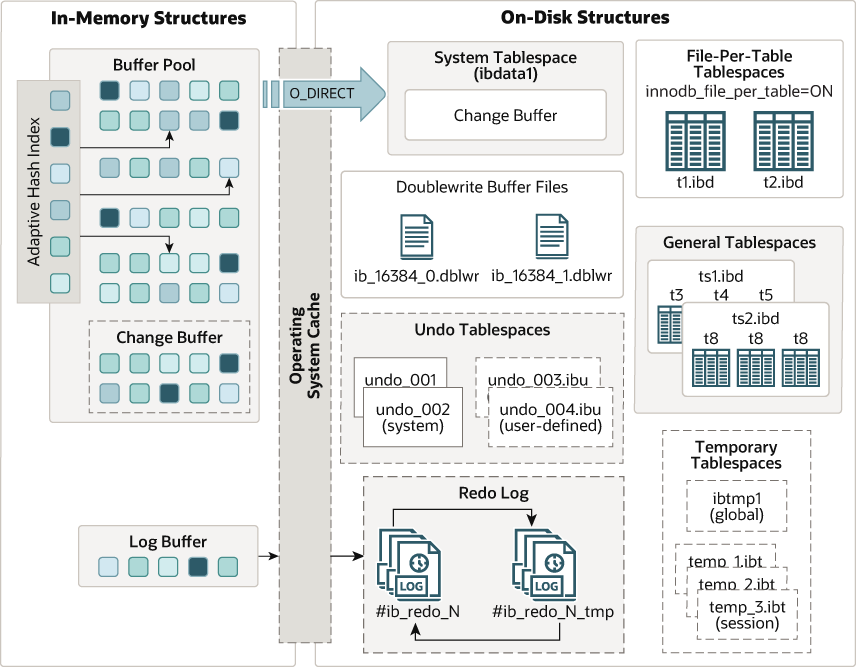
3.3 内存结构
在InnoDB中,内存结构由四部分构成:
- Buffer Pool:缓冲池
- Change Buffer:更改缓冲区
- Adaptive Hash Index:自适应哈希索引
- Log Buffer:日志缓冲
3.3.1 Buffer Pool
缓冲池用来缓存表数据和索引数据,即当执行查询语句时,会对涉及的表和索引数据放入缓冲池,并且,之后的增删改查可以直接使用缓冲池中的数据,之后,再以一定频率刷新到磁盘中,减少IO操作次数,增加效率。缓冲池是内存结构中的主要部分。
缓冲池中的基本单位是页(Page),根据页的使用状态,可以分为空闲页(free page,其中不包含数据)和使用页(其中包含数据);根据缓冲池中页的数据与磁盘中页数据是否一致,可以将使用的页再分为干净页(clean page,数据一致)和脏页(dirty page,数据不一致)。
在缓冲池中以链表结构管理页,因此,存在三条链表:
- 空闲链(Free List):管理未被使用的空间;
- 最近最少使用链(LRU List):管理使用页,负责在缓冲池满时淘汰页;
- 脏链(Flush List):负责管理要被刷新到磁盘的页;
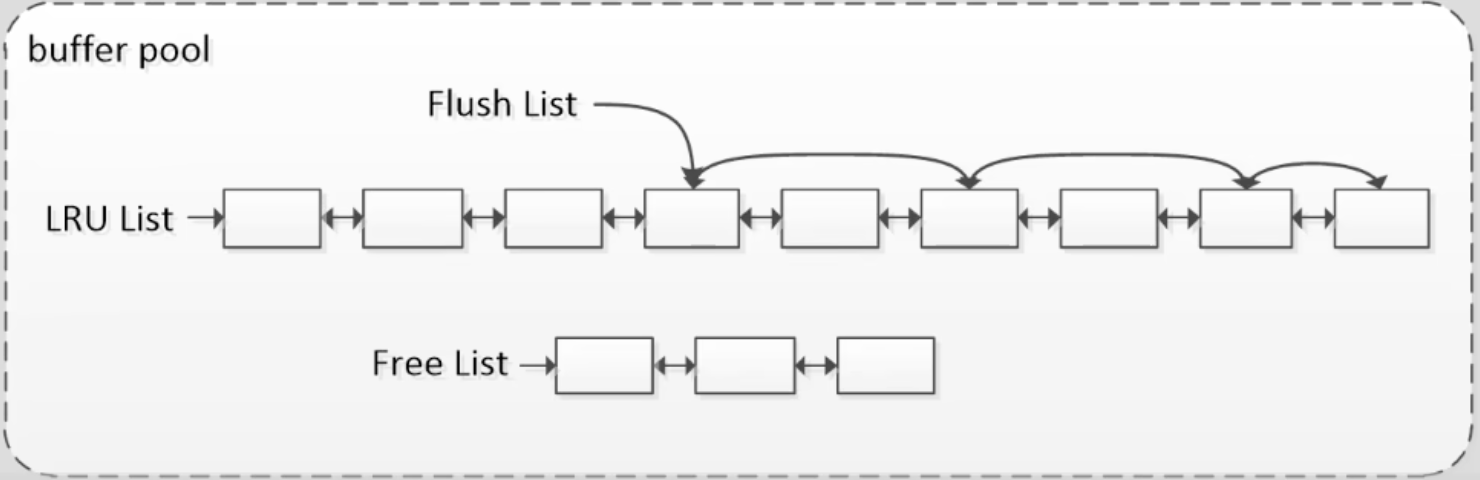
在LRU List中,使用LRU算法的变体形式来进行管理。
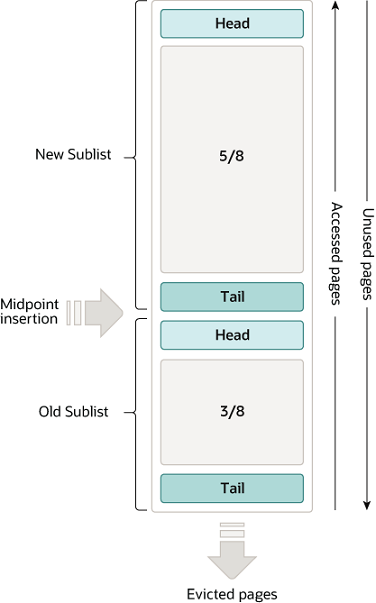
- LRU List将链表分为两部分:New Sublist和Old Sublist,分别占据5/8和3/8,分割点称为中间插入点(Midpoint insertion)。New Sublist存放最近被访问过的页,Old Sublist存放最近没有被访问过的页;
- 当由于查询数据,从磁盘加载新页到缓冲池时,将新页插入到中间插入点(Midpoint insertion),使之成为Old Sublist的第一个页;
- 当访问Old Sublist中的页时,会将访问到的页移到New Sublist的第一个位置;
- 如果从磁盘加载新页到缓冲池时,发现没有空闲页了,那么会把Old Sublist最后一个页移出,腾出空间;
3.3.2 Change Buffer
用于优化对二级索引/辅助索引 (Secondary Index)页本身 的 DML 操作。当对非唯一辅助索引进行 INSERT, UPDATE, DELETE 操作时,如果辅助索引页不在 Buffer Pool 中,InnoDB 不会立即从磁盘加载并修改索引页,而是将这些更改记录到 Change Buffer 中。Change Buffer属于缓冲池的一部分。
假设现有一张表person,其中包含id 和 name字段,id是主键,name字段上有一个常规索引(非唯一)。当执行下面的语句时:
sql
insert into person values(10, '张三');此时不仅会在聚集索引上增加一条记录,还要同时修改name索引,在name索引中也增加一条记录(如果没有的话)。那么针对name索引的修改,如果相关索引页没有在缓冲池中,就会将针对name索引页的修改操作保存到Change Buffer中。当后续相关索引页读取到缓冲池后,就会应用这些修改操作;如果一直没有读取操作,那也有后台线程定期读取索引页并合并修改。
在上面的例子中,只插入一条数据可能看不出Change Buffer的作用,但是如果在百万级别数据的表中插入100条数据呢?name的值是随机的,所以就会触发随机I/O,效率很低。
同理,针对delete操作,也会把对辅助索引页的修改意图保存在Change Buffer。
接下来我们再看看update语句:
sql
update person set name = '李四' where name = '张三';- 首先,这条语句会使用
name索引来定位数据,会将name值为”张三“的辅助索引页加载到缓冲池中; - 然后,根据辅助索引页中的主键值,从聚集索引中查找数据,这就是回表查询,最终会把主键索引页加载到缓冲池中;
- 然后,在缓冲池中修改数据(主键索引页,即数据页),将
name的值改为“李四”; - 然后,由于更新了
name索引,所以此时要做两件事:- 删除
name值为“张三”的索引页,此时这些索引页都在缓冲池中(第1步已经读取进来了),所以直接在缓冲池中进行修改,不用保存操作到Change Buffer中; - 插入
name值为“李四”的索引页,此时有可能(大概率)涉及的索引页不在缓冲池中,所以要将这些操作保存到Change Buffer中;
- 删除
由于Change Buffer是延迟写入的,为了保证这些操作不会丢失,所以在系统表空间(下面会讲)开辟了一段空间,用来持久化Change Buffer中未执行的操作。
3.3.3 Adaptive Hash Index
Adaptive Hash Index (自适应哈希索引,简称 AHI) 是 InnoDB 存储引擎的一个非常独特的特性,它不是一个常规的、由用户创建的索引类型(比如 B-tree 索引)。相反,它是一个内存中的、自动生成的、动态调整的数据结构,旨在加速对 B+树索引的查找(尤其是等值查找)。
AHI是由InnoDB动态构建的,如果 InnoDB 发现某个索引键值被频繁地用于等值查找,它就会在内存中为这个键值创建一个哈希索引,索引的键是 取B+树索引键的某个前缀然后进行哈希计算,索引的值是指向 Buffer Pool 中对应的 B+树索引页的内存地址。
当下一次进行相同的等值查询时,InnoDB 会首先尝试查询 AHI。它会再次对查询条件中的索引键计算哈希值。如果这个哈希值在 AHI 中有匹配的条目,AHI 会直接返回 Buffer Pool 中对应的 B+树索引页内存地址。从而跳过查询B+树索引的过程,查找复杂度从
3.3.4 Log Buffer
Log Buffer,日志缓冲区,主要用于缓存 Redo Log (重做日志) 记录。
Log Buffer 中会包含以下类型的操作:
- DML语句操作;
- 对 Undo Log 的修改记录;
- 对 Change Buffer 的修改记录;
- 对 Doublewrite Buffer 的修改记录;
- 对系统表空间(如 FSP_HDR, XDES 等)和其他元数据页的修改记录;
SELECT 查询不会修改数据,因此 Log Buffer 中不会有关于 SELECT 操作的记录。
Log Buffer中的内容会定期刷新到磁盘中,即Redo Log中。
3.4 磁盘结构
InnoDB的磁盘结构有很多,这里介绍部分。
3.4.1 System Tablespace
System Tablespace,系统表空间,注意,这里的Tablespace没有s,表示只有一个系统表空间,对应着ibdata1文件。
系统表空间是Change Buffer的存储区域。
在早期版本(MySQL 5.7之前),系统表空间存储了一下内容:
InnoDB 数据字典 (Data Dictionary): 这是最重要的部分。它存储了所有数据库、表、索引、列、视图、存储过程、触发器等对象的元数据。这使得
ibdata1文件在这些版本中非常关键,且一旦变大,往往难以收缩。用户创建的表和索引数据 : 在默认情况下或当
innodb_file_per_table参数关闭时,所有 InnoDB 表的数据和索引都会默认存储在系统表空间中。这是导致ibdata1文件无限增长且无法收缩的主要原因,也是为什么强烈建议开启innodb_file_per_table=ON的原因。
但是,在MySQL 8.0之后,MySQL对数据字典进行了重大改进,将其从 InnoDB 系统表空间中分离出来,拥有了独立的 MySQL 数据字典。并且用户创建的表和数据页不会存放在系统表空间了。
3.4.2 File-Per-Table Tablespaces
一个File-Per-Table表空间对应着MySQL数据库中的一张表及其数据、索引,在磁盘中对应着一个.ibd文件。
所以可以理解为,一张表就是一个File-Per-Table表空间,就是一个xxx.ibd文件(xxx为表名)。
3.4.3 Undo Tablespaces
Undo 表空间是一个专门用于存放 Undo Log 的文件,而 Undo Log 记录了事务对数据行(聚簇索引记录)的每一次修改是如何被撤销的,从而支持事务回滚和多版本并发控制(MVCC)。
默认情况下,Undo表空间数据文件是undo_001和undo_002,每个大小默认为16MB。
3.4.4 Doublewrite Buffer
Doublewrite Buffer (双写缓冲区) ,主要用于解决数据页在写入磁盘时可能发生的**部分写失效(partial page write)**问题,从而保证数据文件的完整性和可靠性。在磁盘中,以后缀.dblwr结尾的文件就是双写缓冲文件。
部分写失效问题:InnoDB 存储引擎的数据读写最小单位是页(Page),通常是 16KB。操作系统读写磁盘的最小单位通常是 4KB 或 8KB。当 InnoDB 将一个 16KB 的数据页从内存写入磁盘时,如果操作系统层面的写操作(例如分 4 个 4KB 的块写入)在中间发生中断(比如服务器掉电、操作系统崩溃),就可能导致磁盘上的数据页只写入了一部分,形成一个不完整或损坏的页。一个被部分写入的页是无效的,而且更糟糕的是,仅仅依靠 Redo Log 无法恢复这种损坏的页。Redo Log 记录的是对数据页的逻辑物理修改(例如“将页 X 的偏移 Y 处的值从 Z 改为 W”),它假设被修改的页本身是完整的。如果页本身已经损坏,Redo Log 无法将其恢复到一个一致的、可用的状态。
Doublewrite Buffer 的核心作用就是防止部分写失效,为数据页提供一个额外的安全保障。它通过两次写入的策略来实现这一点:
- 当 InnoDB 的后台线程(如 Page Cleaner)需要将 Buffer Pool 中的脏页 (Dirty Pages) 刷新到磁盘时,它并不会直接将这些页写入到最终的数据文件位置。相反,它会先将这些脏页复制到内存中的 Doublewrite Buffer 区域。
- 然后,内存中的 Doublewrite Buffer 内容会被顺序地写入到磁盘上的 Doublewrite Buffer。这次写入是顺序 I/O,效率非常高。而且,一旦写入完成,操作系统会通过
fsync()强制将数据同步到磁盘,确保其持久性。 - 在确保数据已经安全地写入到磁盘中的 Doublewrite Buffer 区域后,InnoDB 才会将这些脏页写入到它们各自在数据文件(如
.ibd文件)中的最终位置。这次写入通常是随机 I/O,因为不同数据页在磁盘上可能是分散的。
Doublewrite Buffer 如何防止部分写失效?可以分以下情况讨论:
如果第一次写入 (到磁盘中的 Doublewrite Buffer 区域) 失败: 这不影响实际的数据文件,因为脏页还没有开始写入最终位置。崩溃后,可以从 Redo Log 恢复。
如果第二次写入 (到实际数据文件位置) 失败,导致部分写失效:
- 在数据库重启进行崩溃恢复时,InnoDB 会检查数据页的完整性(通过页头中的校验和)。
- 如果发现某个数据页损坏或不完整(部分写失效),InnoDB 知道在磁盘中的 Doublewrite Buffer 区域存在这个页的一个完整副本。
- 于是,InnoDB 会从 Doublewrite Buffer 区域中读取这个完整的页副本,将其拷贝回损坏的数据页位置,从而修复这个损坏的页。
- 完成修复后,InnoDB 就可以继续应用 Redo Log,将所有已提交事务的修改重放到这个完整的页上,确保数据的一致性。
3.4.5 Redo Logs
Redo Log 是一种物理日志,它记录了对数据页所做的所有修改。这些记录是物理的(即描述了数据页内部的字节变化,而不是 SQL 语句),并且是幂等的(即同一条日志记录可以被重复执行多次,结果保持一致)。
在物理上,Redo Log 通常由一组循环写入的文件组成(例如 ib_logfile0, ib_logfile1),位于 MySQL 的数据目录下。
Redo Log 的主要目的是实现事务的 持久性 (Durability) 和 崩溃恢复 (Crash Recovery)。
实现事务持久性 (Durability)
Write-Ahead Logging (WAL) 机制: Redo Log 是 WAL 机制的核心。WAL 的基本原则是:“先写日志,再写数据”。
- 当事务修改数据时,它首先将这些修改记录到 Redo Log 中(并存入 Log Buffer 内存,最终刷新到磁盘)。
- 在事务提交时,必须确保所有相关的 Redo Log 记录已经被安全地写入到磁盘上的 Redo Log 文件中。
- 重要性: 即使此时被修改的数据页(脏页)仍在内存的 Buffer Pool 中,尚未刷新到磁盘,只要 Redo Log 已经持久化,那么这个事务的修改就是持久的。如果此时系统崩溃,可以通过 Redo Log 来恢复这些修改。
保证崩溃恢复 (Crash Recovery) 能力
如果数据库系统在运行过程中突然崩溃(例如断电),内存中的脏页数据会丢失。
当数据库重启时,InnoDB 会执行崩溃恢复。在这个过程中,它会扫描 Redo Log 文件:
- 重放 (Redo): 对于所有在崩溃前已经提交的事务,即使其数据尚未刷新到磁盘,InnoDB 也会根据 Redo Log 中记录的修改信息,将其重放到数据文件上,确保数据达到一致的状态。
- 回滚 (Undo): 对于在崩溃前未提交的事务,InnoDB 会结合 Undo Log 来回滚这些未提交的修改,确保数据库只包含已提交事务的数据。
Redo Log 的写入机制:
- Log Buffer (日志缓冲区): Redo Log 记录首先被写入到内存中的 Log Buffer。
- 刷盘时机 (由
innodb_flush_log_at_trx_commit控制):1(默认,最安全): 每次事务提交,都将 Log Buffer 的内容写入 Redo Log 文件并强制刷新到磁盘。这是最安全的设置,但 I/O 成本最高。0: 每秒将 Log Buffer 的内容写入 Redo Log 文件并刷新到磁盘。即使事务提交,也不立即刷盘。性能最好,但可能丢失 1 秒内的数据。2: 每次事务提交,将 Log Buffer 内容写入 Redo Log 文件(到 OS 缓存),每秒才强制刷新到磁盘。比0安全,比1性能好,但仍有丢失数据的风险。
参考资料
[1] InnoDB表空间和页结构:https://blog.jcole.us/innodb/