Appearance
MySQL 查询
本文介绍MySQL中有关查询的知识。
1. 概述
在SQL中,查询语句称为DQL,全称为Data Query Language,数据查询语言,用来查询数据库中的记录,关键字为select。DQL语法如下:
sql
select 字段列表
from 表名列表
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数本文将按照上述语法结构逐一介绍,并且会介绍联表查询相关知识。
本文使用到的数据表结构和数据如下:
学生-课程数据库:
Details
sql
-- 创建数据库(如果不存在)
CREATE DATABASE IF NOT EXISTS school_db;
-- 切换到该数据库
USE school_db;
-- 1. 学生表 (students)
CREATE TABLE IF NOT EXISTS students (
student_id INT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(100) NOT NULL,
age INT,
gender ENUM('Male', 'Female', 'Other'),
major VARCHAR(100),
enrollment_date DATE
);
-- 2. 课程表 (courses)
CREATE TABLE IF NOT EXISTS courses (
course_id INT PRIMARY KEY AUTO_INCREMENT,
course_name VARCHAR(100) NOT NULL,
credits INT NOT NULL,
instructor VARCHAR(100)
);
-- 3. 选课表 (enrollments)
CREATE TABLE IF NOT EXISTS enrollments (
enrollment_id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT NOT NULL,
course_id INT NOT NULL,
enrollment_date DATE,
grade DECIMAL(3, 1), -- 成绩,例如 85.5
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (course_id) REFERENCES courses(course_id)
);
-- 插入学生数据
INSERT INTO students (student_name, age, gender, major, enrollment_date) VALUES
('张三', 20, 'Male', '计算机科学', '2023-09-01'),
('李四', 22, 'Female', '软件工程', '2022-09-01'),
('王五', 21, 'Male', '电子信息工程', '2023-09-01'),
('赵六', 23, 'Female', '数据科学', '2022-09-01'),
('钱七', 19, 'Male', '计算机科学', '2024-09-01'),
('孙八', 20, 'Female', '人工智能', '2023-09-01'),
('周九', 21, 'Male', '软件工程', '2023-09-01'),
('吴十', 22, 'Female', '数据科学', '2022-09-01');
-- 插入课程数据
INSERT INTO courses (course_name, credits, instructor) VALUES
('数据库原理', 3, '教授A'),
('数据结构', 4, '教授B'),
('操作系统', 3, '教授C'),
('计算机网络', 3, '教授A'),
('高等数学', 5, '教授D'),
('C++程序设计', 4, '教授B');
-- 插入选课数据
INSERT INTO enrollments (student_id, course_id, enrollment_date, grade) VALUES
(1, 1, '2024-03-01', 92.5),
(1, 2, '2024-03-01', 88.0),
(2, 1, '2024-03-01', 78.0),
(2, 3, '2024-03-01', 85.0),
(3, 2, '2024-03-01', 70.0),
(3, 4, '2024-03-01', 95.0),
(4, 1, '2024-03-01', 80.5),
(4, 5, '2024-03-01', 65.0),
(5, 1, '2024-03-01', NULL), -- 假设还未出成绩
(5, 6, '2024-03-01', 89.0),
(6, 2, '2024-03-01', 75.0),
(6, 3, '2024-03-01', 82.0),
(7, 4, '2024-03-01', 91.0),
(7, 5, '2024-03-01', 77.0),
(8, 6, '2024-03-01', 93.0),
(1, 4, '2024-03-01', 87.0); -- 张三也选了计算机网络部门-员工数据库:
Details
sql
-- 创建数据库(如果不存在)
CREATE DATABASE IF NOT EXISTS company_db;
-- 切换到该数据库
USE company_db;
-- 创建部门表 (如果不存在)
CREATE TABLE IF NOT EXISTS departments (
dept_id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(100) NOT NULL UNIQUE,
location VARCHAR(100)
);
-- 插入部门测试数据 (如果已存在则跳过,或者先清空再插入)
INSERT INTO departments (dept_name, location) VALUES
('销售部', '北京'),
('市场部', '上海'),
('研发部', '深圳'),
('人力资源部', '北京'),
('财务部', '上海')
ON DUPLICATE KEY UPDATE dept_name = dept_name; -- 防止重复插入报错
-- 创建员工表 (如果不存在)
CREATE TABLE IF NOT EXISTS employees (
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(100) NOT NULL,
position VARCHAR(100),
salary DECIMAL(10, 2) NOT NULL,
hire_date DATE,
dept_id INT, -- 外键,关联到 departments 表
manager_id INT, -- 外键,自引用,关联到 employees 表的 emp_id
FOREIGN KEY (dept_id) REFERENCES departments(dept_id),
FOREIGN KEY (manager_id) REFERENCES employees(emp_id)
);
-- 清空现有员工数据 (如果需要重新插入所有数据,请取消注释下一行)
-- TRUNCATE TABLE employees;
-- 插入员工测试数据
-- 注意:插入有经理的员工前,要确保经理的记录已存在
-- 1. 高层管理 (没有直属经理)
INSERT INTO employees (emp_name, position, salary, hire_date, dept_id, manager_id) VALUES
('张伟', '总经理', 150000.00, '2020-01-01', NULL, NULL); -- emp_id = 1
-- 2. 总监/经理层 (直接向总经理汇报)
INSERT INTO employees (emp_name, position, salary, hire_date, dept_id, manager_id) VALUES
('王芳', '销售总监', 80000.00, '2021-03-15', 1, 1), -- emp_id = 2 (销售部)
('李明', '市场总监', 75000.00, '2021-04-20', 2, 1), -- emp_id = 3 (市场部)
('赵刚', '研发总监', 100000.00, '2020-06-01', 3, 1), -- emp_id = 4 (研发部)
('刘丽', 'HR经理', 60000.00, '2022-01-10', 4, 1), -- emp_id = 5 (人力资源部)
('陈涛', '财务经理', 65000.00, '2022-02-01', 5, 1); -- emp_id = 6 (财务部)
-- 3. 基层员工 (故意制造重复数据)
INSERT INTO employees (emp_name, position, salary, hire_date, dept_id, manager_id) VALUES
-- 销售部
('周杰', '销售代表', 40000.00, '2023-05-01', 1, 2), -- emp_id = 7
('吴迪', '销售代表', 38000.00, '2023-06-10', 1, 2), -- emp_id = 8
('郑莉', '销售代表', 40000.00, '2023-05-01', 1, 2), -- emp_id = 9 (与周杰职位、薪资、入职日期相同)
('钱小明', '销售代表', 42000.00, '2023-05-01', 1, 2), -- emp_id = 10 (与周杰、郑莉入职日期相同)
-- 市场部
('孙悦', '市场专员', 35000.00, '2023-07-01', 2, 3), -- emp_id = 11
('李浩', '市场专员', 35000.00, '2023-07-01', 2, 3), -- emp_id = 12 (与孙悦职位、薪资、入职日期相同)
('吴越', '市场专员', 36000.00, '2023-07-01', 2, 3), -- emp_id = 13 (与孙悦、李浩入职日期相同)
-- 研发部
('张华', '后端工程师', 55000.00, '2023-08-15', 3, 4), -- emp_id = 14
('王强', '前端工程师', 52000.00, '2023-09-01', 3, 4), -- emp_id = 15
('刘军', '测试工程师', 48000.00, '2023-08-15', 3, 4), -- emp_id = 16 (与张华入职日期相同)
('陈婷', '后端工程师', 55000.00, '2023-08-15', 3, 4), -- emp_id = 17 (与张华、刘军职位、薪资、入职日期相同)
-- 人力资源部
('何洁', '招聘专员', 38000.00, '2024-01-01', 4, 5), -- emp_id = 18
('郭玲', '薪酬专员', 39000.00, '2024-01-01', 4, 5), -- emp_id = 19 (与何洁入职日期相同)
-- 财务部
('徐斌', '会计', 45000.00, '2023-10-01', 5, 6), -- emp_id = 20
('朱丹', '出纳', 42000.00, '2023-10-01', 5, 6); -- emp_id = 21 (与徐斌入职日期相同)2. 基础查询
查询某个表中多个字段,可以使用如下语法:
sql
select 字段1,字段2,字段3...字段n from 表名;如果想查询全部字段,可以使用*来表示所有字段:
sql
select * from 表名;当然,我们也可以在字段前面加上表名,用.分割:
sql
select 表名.字段1, 表名.字段2, 表名.字段3 ...表 名.字段n from 表名;
select 表名.* from 表名;如果想为查询出来的字段设置别名,可以使用关键字as,as也可以省略,直接在字段名后用空格分隔别名就好:
sql
select 字段1 [as 别名1], 字段2 [别名2] ... from 表名;当然,我们可以为表名设置别名:
sql
select 表别名.字段1 [别名1], 表别名.字段2 [别名2] ... from 表名 表别名;注意,如果为表名设置了别名后,就不允许使用原表名了。
当查询出来的记录重复时,可以使用distinct去除重复记录:
sql
select distinct 字段列表 from 表名;3. 条件查询
3.1 介绍
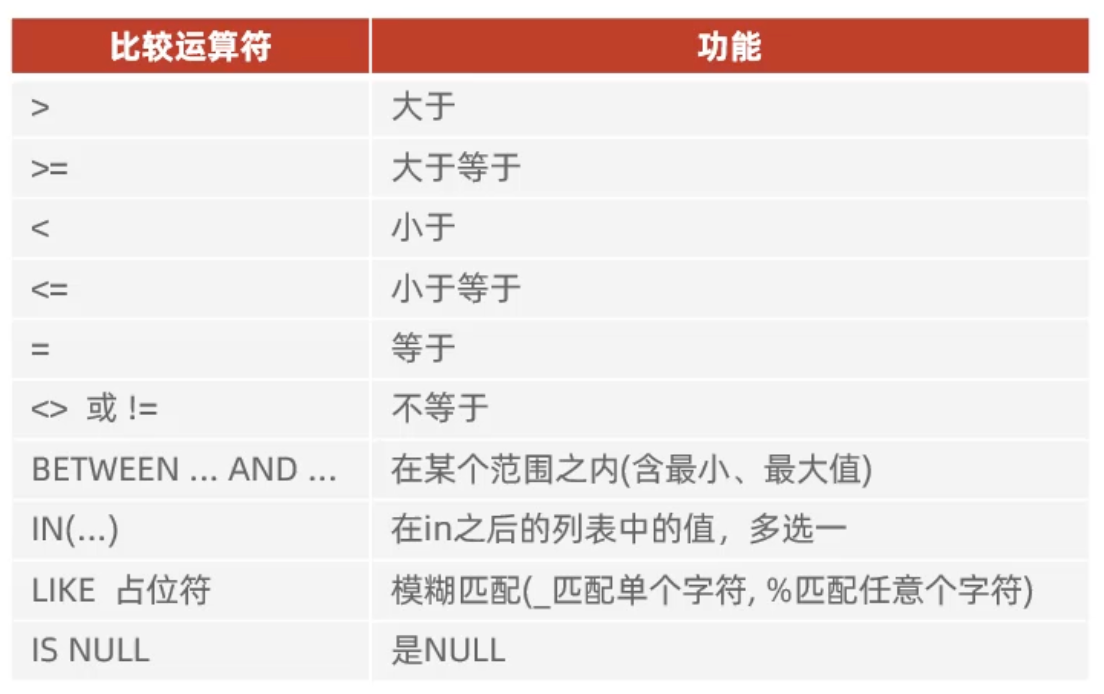
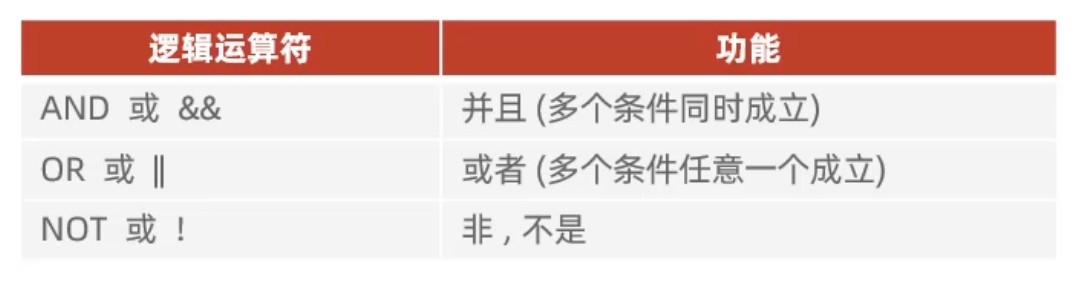
在DQL中,条件查询的关键字是where,语法如下:
sql
select 字段列表 from 表名
where 条件列表;DQL中条件查询支持的运算符如下:
3.2 BETWEEN...AND运算符
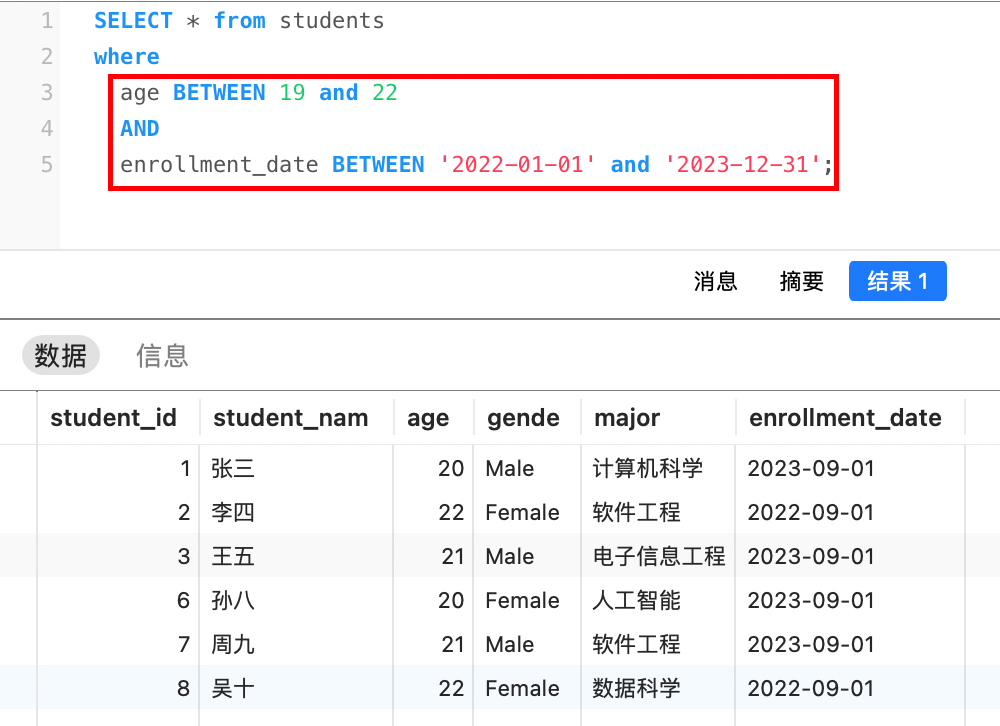
关于BETWEEN ... AND ...运算符,支持数值类型、日期时间类型和字符串类型,但不建议用于字符串类型,示例如下:
3.3 like 模糊匹配
LIKE 运算符主要依赖两个通配符:
%(百分号):- 代表零个、一个或多个任意字符。
- 示例:
'张%'匹配所有以“张”开头的字符串(如“张三”、“张小明”)。 - 示例:
'%三'匹配所有以“三”结尾的字符串(如“张三”、“李老三”)。 - 示例:
'%三%'匹配所有包含“三”的字符串(如“张三丰”、“三毛”、“李三”)。
_(下划线):- 代表单个任意字符。
- 示例:
'张_'匹配“张三”、“张大”等,但不会匹配“张小明”。 - 示例:
'_三'匹配“张三”、“李三”等。 - 示例:
'王_ _'匹配“王小明”、“王大山”等,即以“王”开头,后面紧跟两个任意字符的字符串。
如果想搜索的字符串中本身就包含
%或_,需要使用转义字符来让它们失去通配符的特殊含义。默认的转义字符是反斜杠\。sql-- 查询字符串中包含 '%' 的数据 SELECT column_name FROM table_name WHERE column_name LIKE '%\%%'; -- 查询字符串中包含 '_' 的数据 SELECT column_name FROM table_name WHERE column_name LIKE '%\_%';
例如:
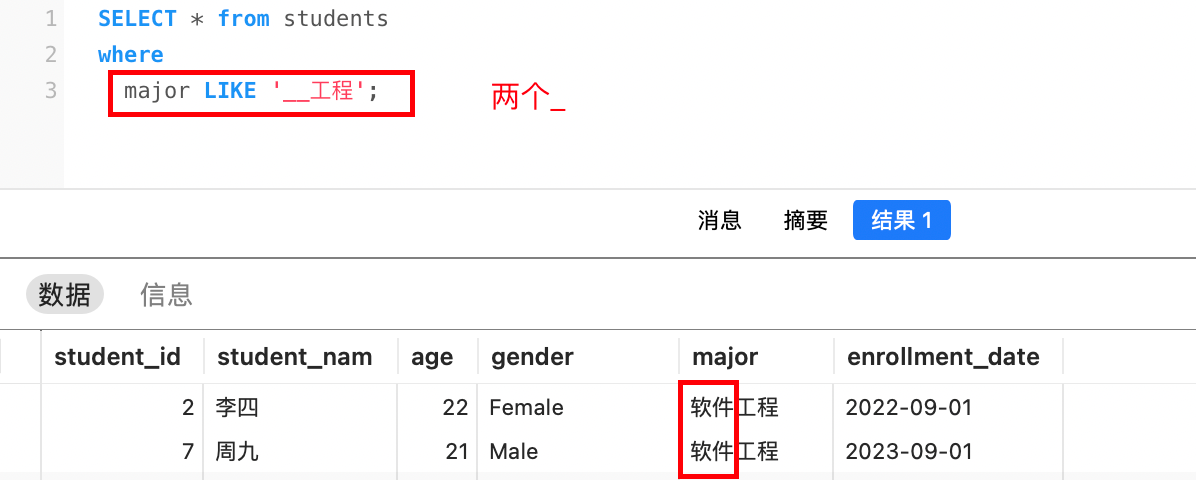
4. 聚合函数
聚合函数(Aggregate Functions) 是一种特殊的函数,它们对一组值(通常是表中的一列)执行计算,然后返回一个单一的汇总值。
换句话说,它们不是对每一行单独进行操作,而是对多行数据进行汇总计算,最终得到一个结果。
聚合函数的特点如下:
处理多行,返回单值: 这是聚合函数最核心的特征。它接收多行作为输入,然后输出一个代表这些行整体特征的单一值。
常与
GROUP BY子句一起使用: 当与GROUP BY(分组查询,下面会介绍)子句一起使用时,聚合函数会对每个分组的数据进行独立的计算,为每个分组返回一个汇总值。如果没有
GROUP BY,聚合函数会作用于整个结果集,将所有行视为一个大组。忽略
NULL值(除了COUNT(*)): 大多数聚合函数在计算时会自动忽略NULL值。例如,
AVG()会计算非NULL值的平均值,SUM()会求和非NULL值。而
COUNT(*)是一个例外,它会计算所有行的数量,包括包含NULL值的行(即使该行所有字段都为NULL,也会统计该行)。通常用于
SELECT列表或HAVING子句: 聚合函数主要出现在SELECT语句的查询列表中,用于显示计算结果;或者出现在HAVING子句中,用于对分组后的结果进行过滤。
常见的聚合函数如下:
| 聚合函数 | 介绍 |
|---|---|
| COUNT() | 统计数量COUNT(*): 返回表中总行数,包括 NULL 值。COUNT(column_name): 返回指定列中非 NULL 值的行数。COUNT(DISTINCT column_name): 返回指定列中不重复的非 NULL 值的行数。 |
| SUM(column_name) | 计算指定数值列的总和,忽略NULL值 |
| AVG(column_name) | 计算指定数值列的平均值,忽略 NULL 值。 |
| MAX(column_name) | 返回指定列中的最大值,适用于数值、日期/时间或字符串类型。 |
| MIN(column_name) | 返回指定列中的最小值,适用于数值、日期/时间或字符串类型。 |
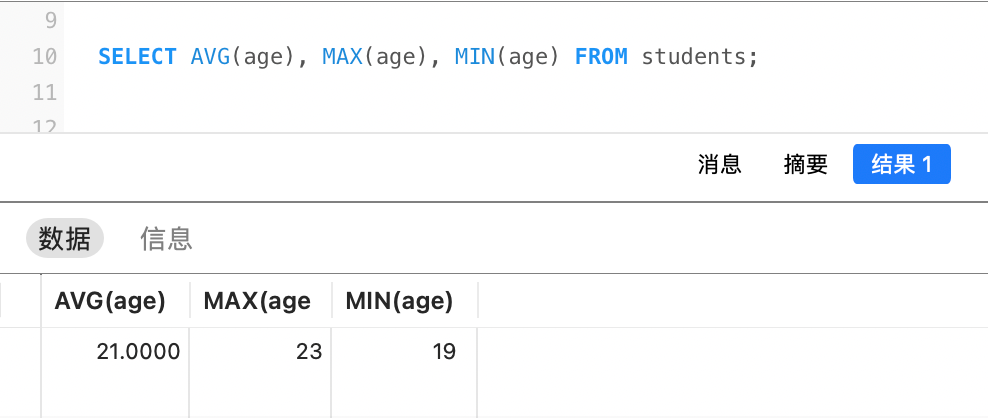
例如,计算总共有多少个学生(根据id计算):

计算学生的平均年龄,最大的年龄和最小的年龄:
5. 分组查询
分组查询允许将表中的数据根据一个或多个列的值进行分类,然后对每个分类(即“组”)的数据执行聚合计算。使用的关键字是group by,语法如下:
sql
select 字段列表 from 表名
where 条件列表
group 分组字段列表
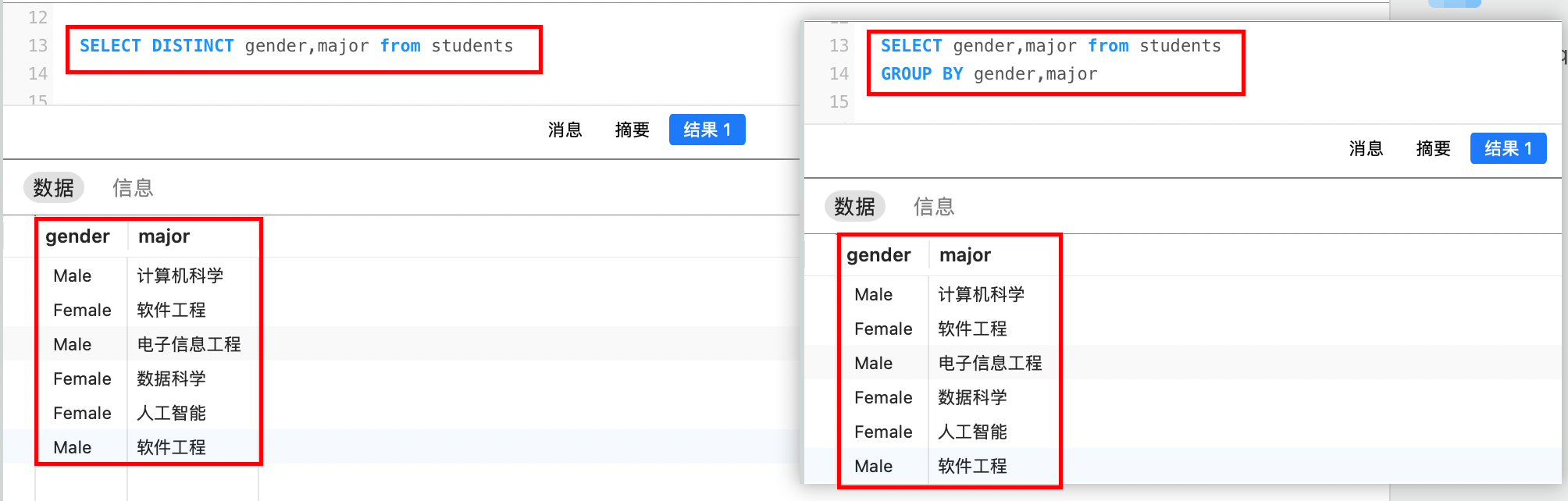
having 分组后条件列表一般情况下,分组查询和聚合函数配合使用,如果只使用 GROUP BY 而不使用聚合函数,SELECT 语句的行为会有些特殊:
SELECT列表中只能出现GROUP BY子句中包含的列。- 它会返回每个分组中唯一的组合。 这实际上起到了类似
DISTINCT的效果。
例如:
where和having的区别:
- 执行时机不同:where是对分组之前进行过滤,不满足where条件的记录不参与分组;而having是对分组之后的结果进行过滤;
- 判断条件不同:where不能对聚合函数进行判断,而having可以;
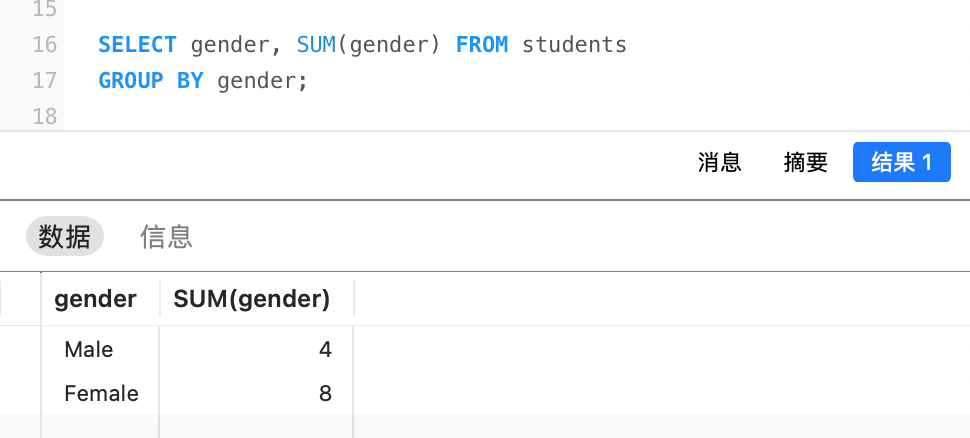
分组查询和聚合函数配合使用,核心思想就是先分类,再统计,group by起分类作用,聚合函数起统计作用。
例如,统计学生中男女生的人数:
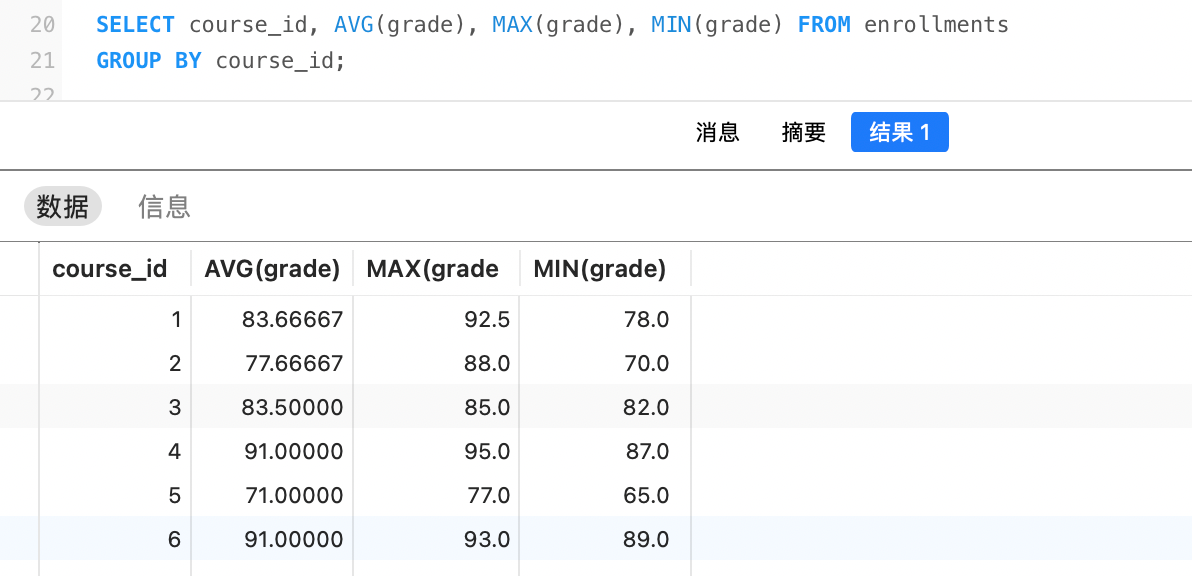
例如,统计每门课程的平均分、最高分和最低分:
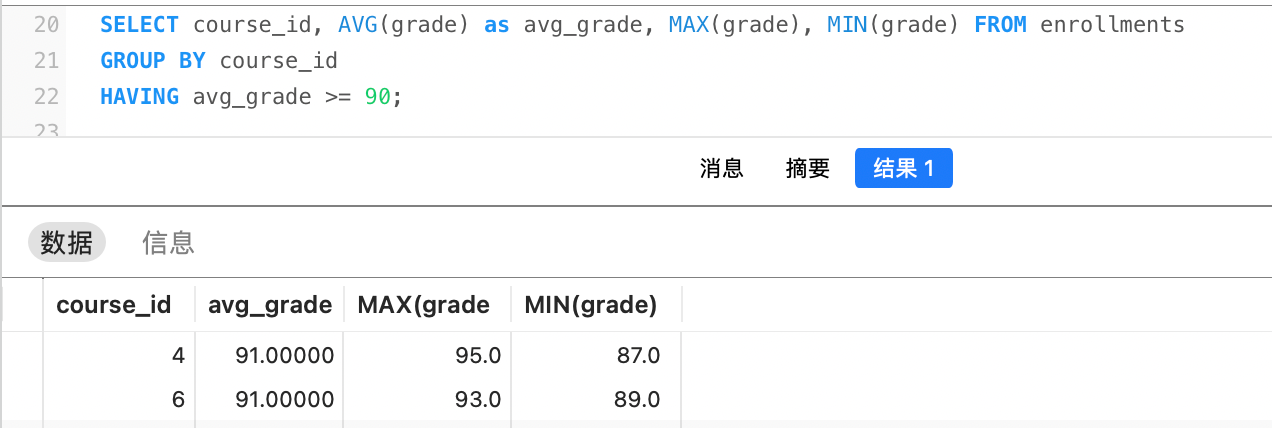
再例如,统计每门课的平均分,再选出平均分高于90分的课程:
6. 排序查询
排序查询就是对查询出来的结果按照某个或多个字段进行排序,可分为升序排序ASC和降序排序DESC,关键字是order by,语法如下:
sql
select 字段列表 from 表名
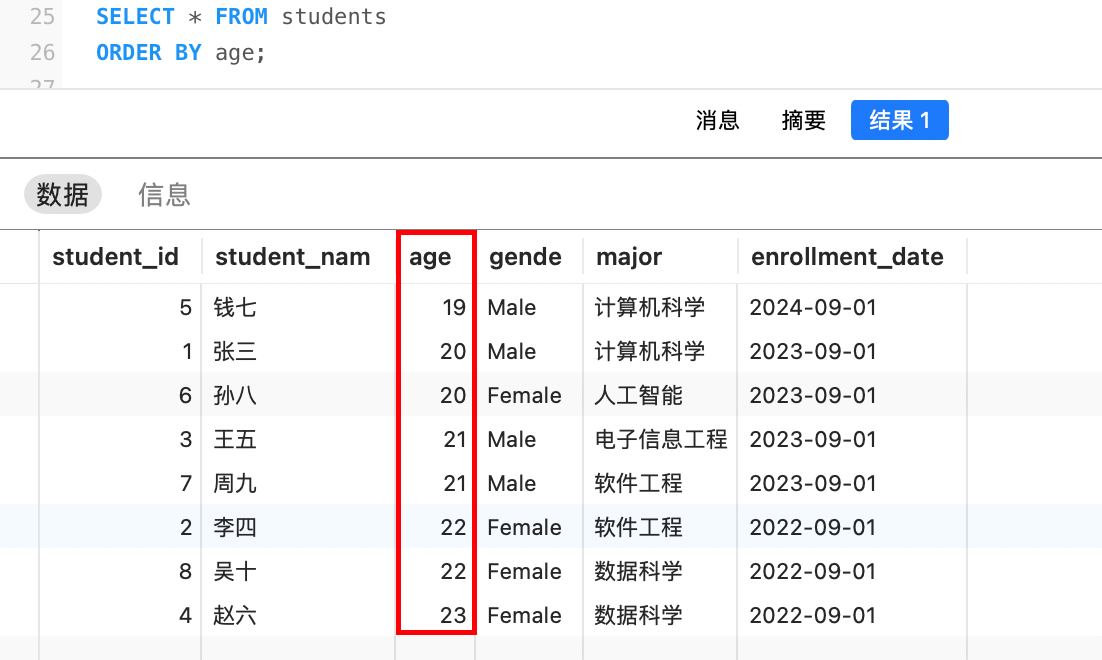
order by 字段列表例如,将学生按照年龄排序:
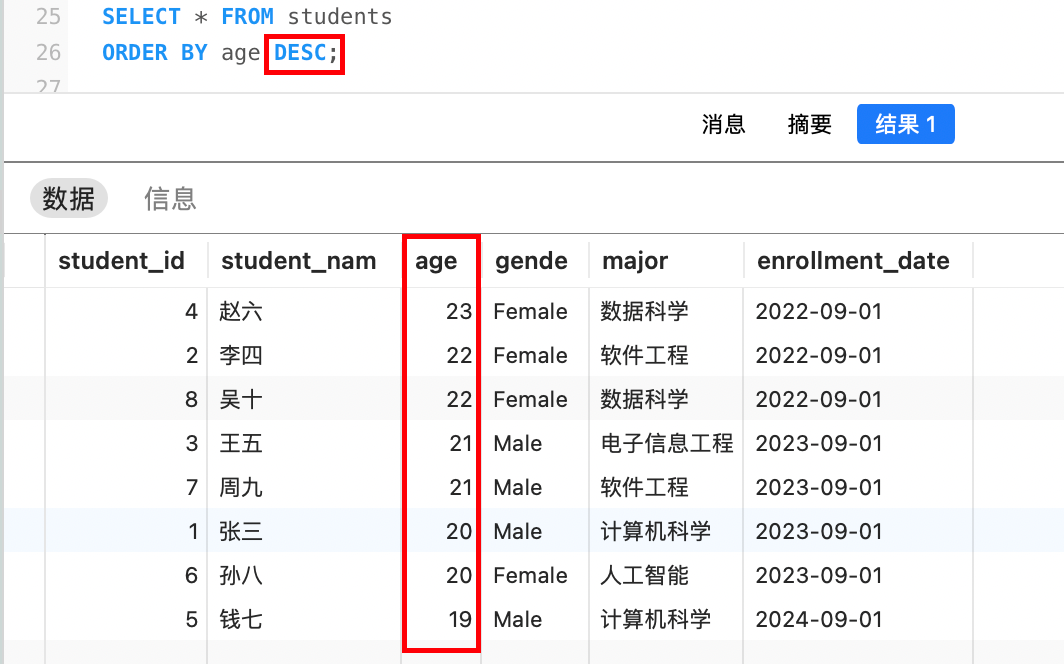
默认是升序排序,也可以在排序字段后改变排序规则:
我们也可以对多个字段进行排序,按照排序字段从左往右,如果前面的字段相同,则往后继续排序。例如,下面先按照年龄降序排序,再按照学生ID降序排序:
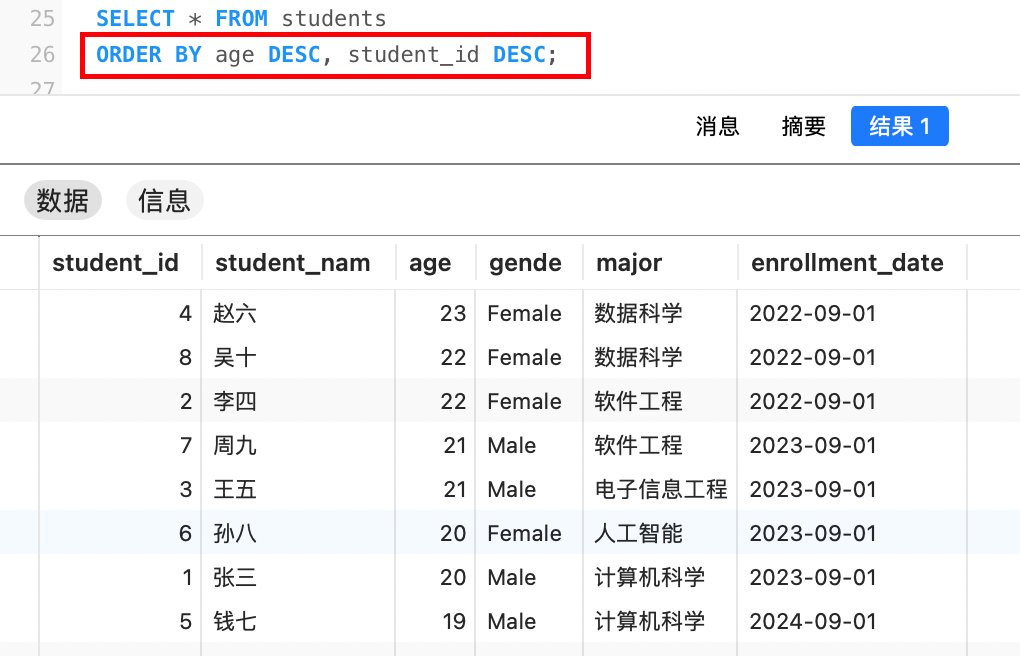
排序字段不一定要出现在结果字段中(即select后)。
7. 分页查询
在MySQL中,分页查询使用关键字limit实现,语法如下:
sql
select 字段列表 from 表名
limit 起始索引,查询记录数;- 起始索引:表示从结果集的第几行开始(起始行为 0),如果为0则可以省略;
- 查询记录数:行数,表示从 起始索引 处开始,要查询的行数。
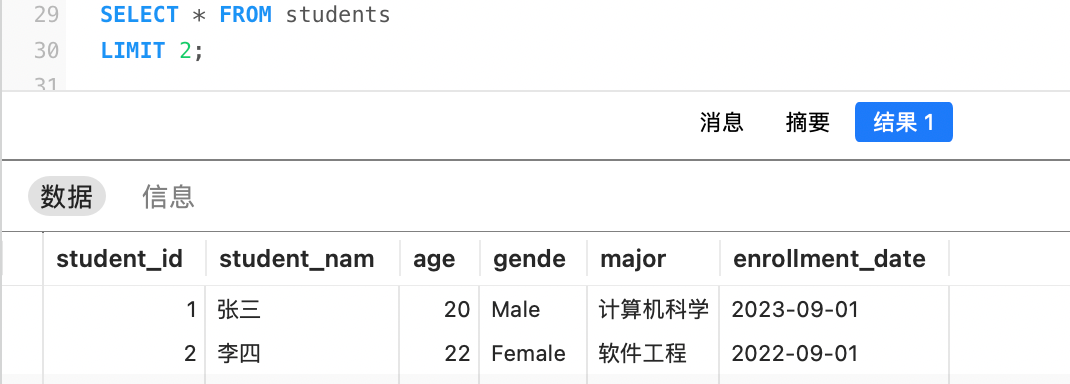
例如,查询前两名学生:
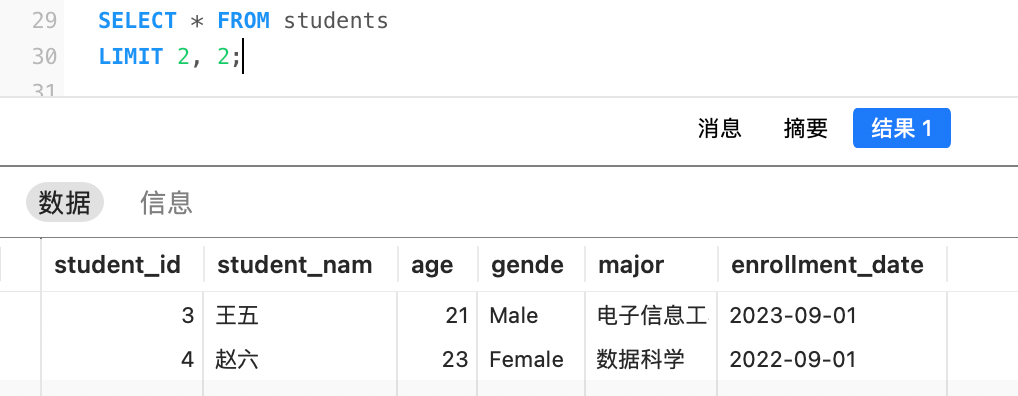
例如,查询第3-4名学生:
注意事项:
在进行分页查询时,务必使用
ORDER BY子句来确保每次查询结果的顺序是确定的。如果没有
ORDER BY,数据库可能会以任意顺序返回行,导致不同页之间的数据出现重复或遗漏,因为数据库内部的存储顺序是不确定的。通常会根据主键、时间戳或业务上有序的字段进行排序。
8. 执行顺序
针对完整的DQL语法,执行顺序分析如下:
sql
select 字段列表
from 表名列表
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数- 首先从表中取出初始结果集,按照字段列表(不看聚合函数);
- 然后执行where条件过滤,进一步缩小结果集范围;
- 然后执行分组,此时需要对组执行聚合函数,得到分组后的结果集;
- 然后执行having条件过滤,进一步过滤分组后的结果集;
- 然后执行排序;
- 最后进行分页;
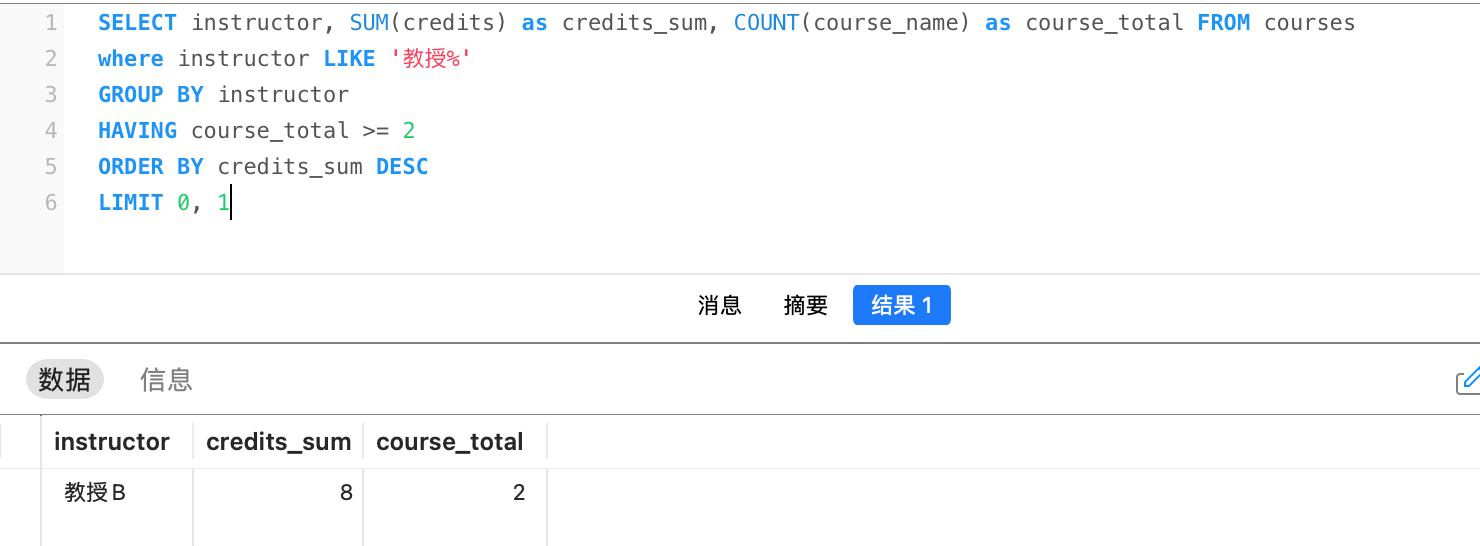
例如,选出授课课程大于等于2门的教授中,课程总学分最高的教授:
9. 多表查询
9.1 多表关系
在数据库设计(或实体设计)中,表与表(实体与实体)之间存在三种关系:一对多(多对一)、多对多和一对一。
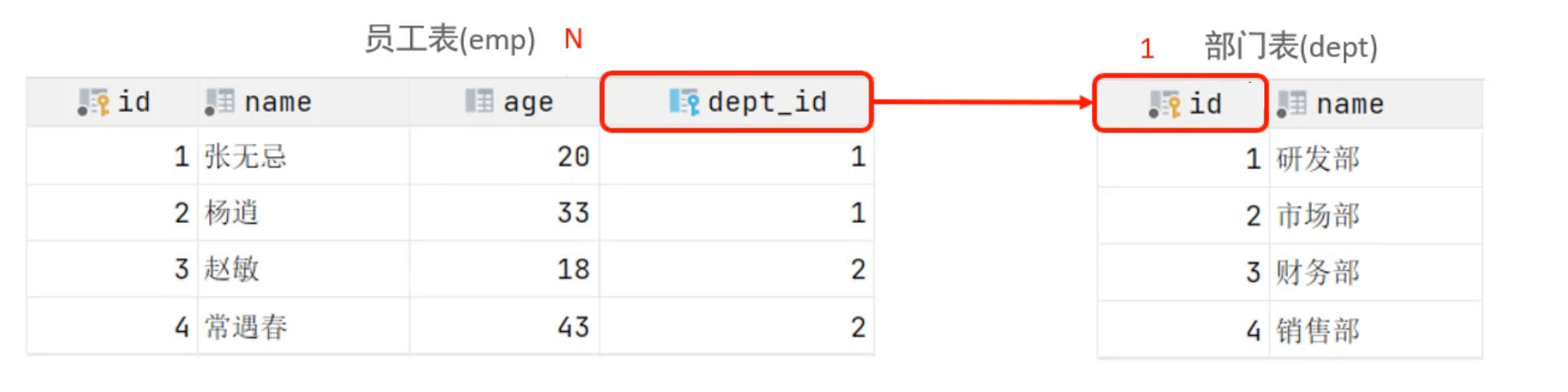
9.1.1 一对多
在两个表中,表 A 中的一行记录可以与表 B 中的多行记录关联,但表 B 中的一行记录只能与表 A 中的一行记录关联。
例如:
- 一个部门(
dept)可以有多个员工(emp),但一个员工只属于一个部门。 - 一个订单(
orders)可以包含多个订单项(order_items),但一个订单项只属于一个订单。
实现方式:通过在“多”的一方(子表)中创建一个外键列,该外键列引用“一”的一方(父表)的主键。
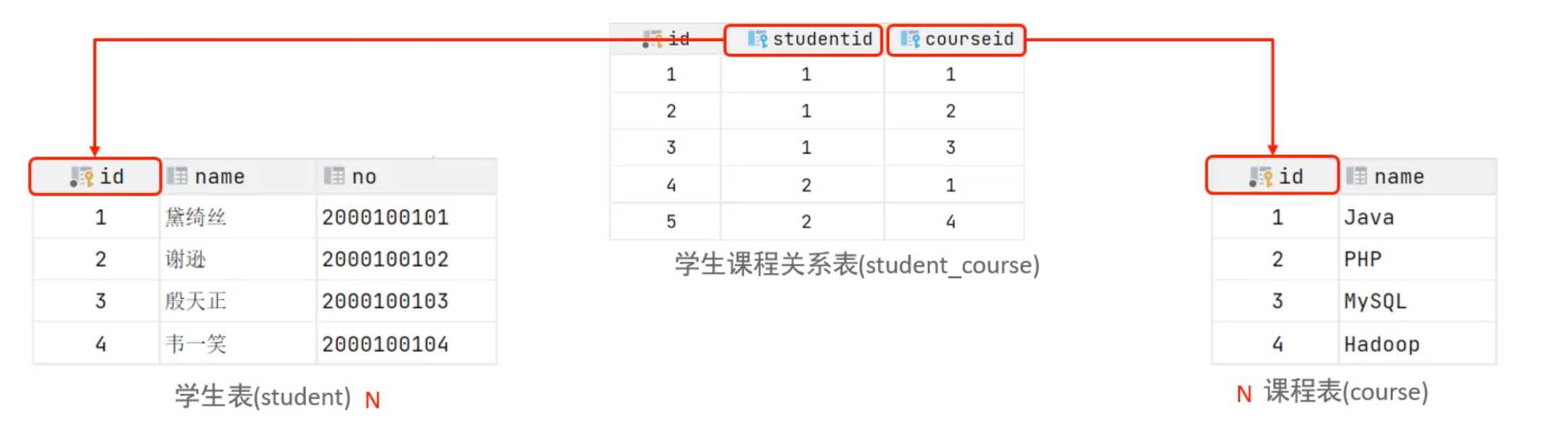
9.1.2 多对多
在两个表中,表 A 中的一行记录可以与表 B 中的多行记录关联,同时表 B 中的一行记录也可以与表 A 中的多行记录关联。
例如:
一个学生(
student)可以选修多门课程(course),一门课程也可以被多个学生选修。一本书(
books)可以有多个作者(authors),一个作者也可以写多本书。
实现方式:创建一个新的中间表,该中间表至少包含两个外键列,分别引用原始两个表的主键。中间表通常还包含其他描述关系本身的属性(例如,选课的时间、成绩)。
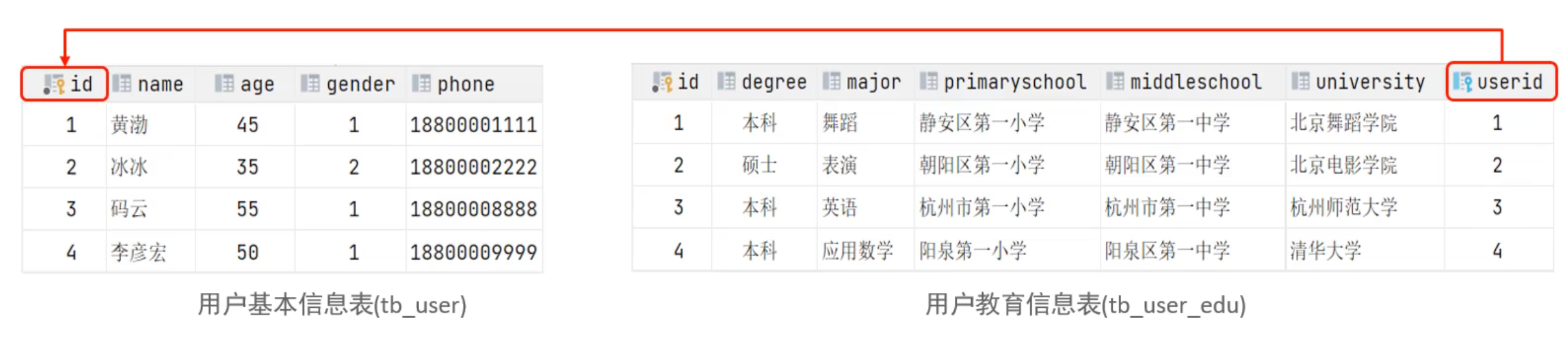
9.1.3 一对一
在两个表中,表 A 中的一行记录最多只能与表 B 中的一行记录关联,反之亦然。
这种关系相对较少,因为它通常意味着这两部分数据可以合并到同一个表中。
主要用于:
- 拆分大表:当一个表的列过多,或者某些列访问频率很低时,可以将其拆分为两个表,但通过一对一关系保持逻辑上的关联。
- 安全性或权限分离:将敏感数据或需要独立权限管理的数据放入单独的表中。
- 处理可空(Nullable)的属性:当一个实体的某些属性只有少部分记录拥有时,可以将其分离。
例如:
tb_users表:存储用户基本信息;tb_user_edu表:存储用户教育信息 ;
实现方式:通过将一个表的主键作为另一个表的外键,并且该外键列必须设置为唯一(UNIQUE)。
9.2 多表查询
多表查询分为三类:
- 连接查询:用于水平组合来自两个或多个表的数据行,基于它们之间共同的列(通常是主键和外键)。它通过将一张表的行与另一张表的行配对来创建一个更宽的结果集。扩展列。
- 联合查询:用于垂直组合来自两个或多个
SELECT语句的结果集。它将多个查询的结果堆叠在一起,形成一个单一的结果集。联合查询要求所有SELECT语句的列数相同,且对应列的数据类型兼容。堆叠行。 - 子查询:是指嵌套在另一个 SQL 查询(称为外部查询或主查询)内部的查询。子查询的结果通常作为外部查询的输入、筛选条件或计算值。它可以出现在
SELECT、FROM、WHERE或HAVING子句中。辅助查询
10. 连接查询
连接查询分为交叉连接(笛卡尔积)、内连接、左外连接、右外连接。
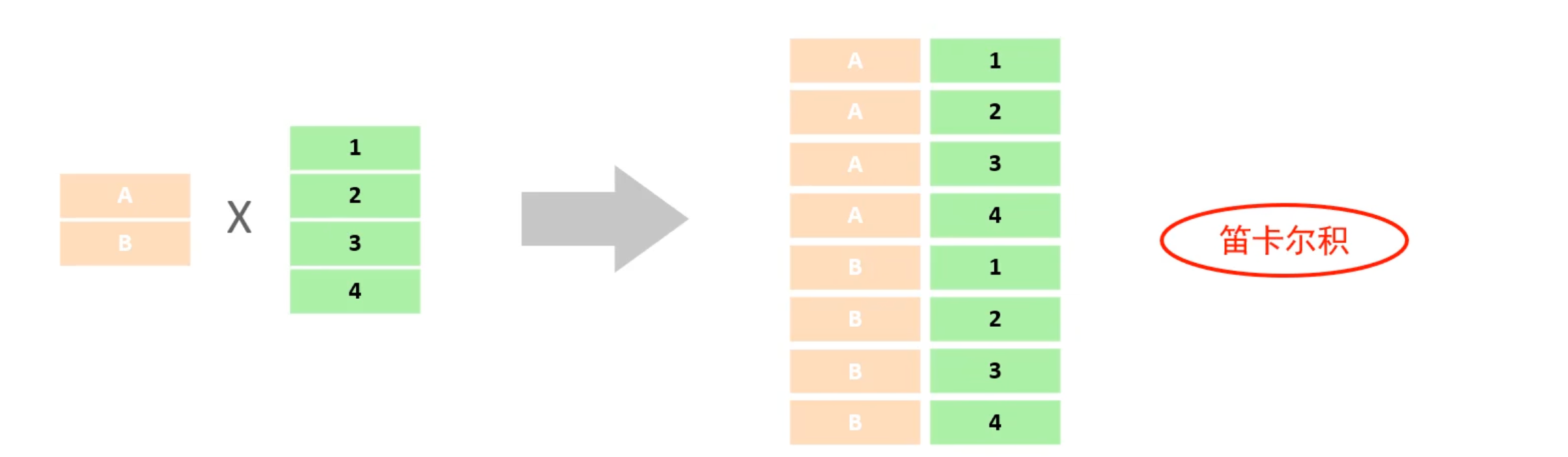
10.1 交叉连接(笛卡尔积)
交叉连接,又称为笛卡尔积。
笛卡尔积是指在数学中,两个集合 A 和 B 的所有组合情况。在数据库中,是指 表A 中的记录与 表B 中的记录一一组合形成的结果集。如果 表A 有 m 行,表B 有 n 行,结果将是 m * n 行。
如下图,表A中有2条记录(A和B),表B中有4条记录(1,2,3,4),那么两表的笛卡尔积有8条记录(2*4=8)。
在MySQL 中,实现交叉连接的方式很简单,即在from后写上要参与连接的表名,用,分隔 ,语法如下:
sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.* from 表名1, 表名2;在MySQL中,我们可以使用[CROSS] JOIN(CROSS 加括号的原因是CROSS可省略)来实现交叉连接,语法如下:
sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.* from 表名1 [CROSS] JOIN 表名2;例如,实现部门和员工的交叉连接:
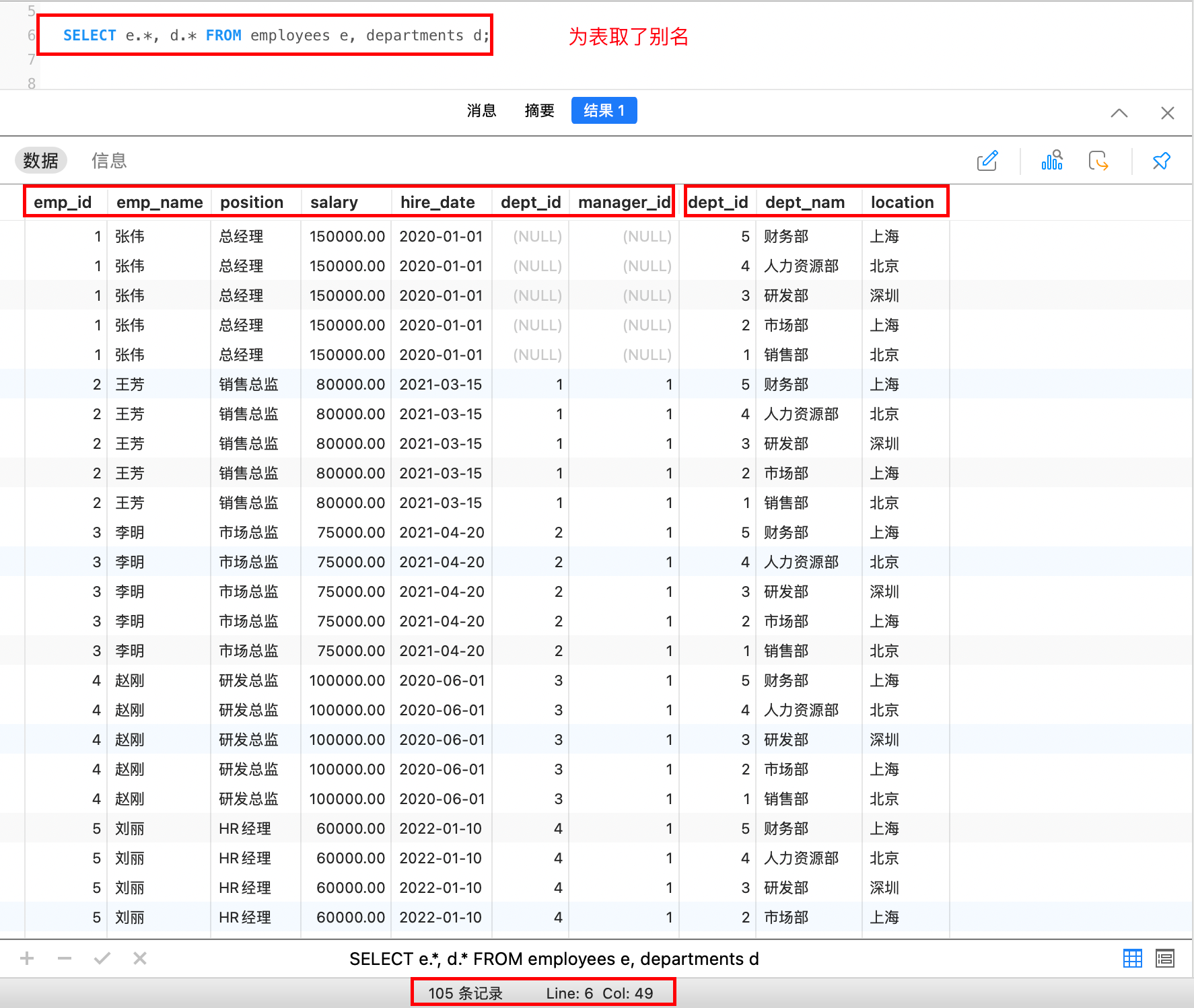
部门表中有5条记录,员工表中有21条记录,总共有105条记录。
我们也可以使用CROSS JOIN,如下:
sql
SELECT * FROM employees [CROSS] JOIN departments;10.2 内连接
内连接是在交叉连接的基础上,对结果集增加条件过滤,只返回满足条件的记录。
根据交叉连接的不同写法,有以下方式实现(多加了一个INNER关键字,但也是可以省略的):
sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.* from 表名1, 表名2
where 查询条件sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.* from 表名1 [CROSS] join 表名2
on 查询条件sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.* from 表名1 [INNER] join 表名2
on 查询条件例如,查询员工及其所在部门信息:
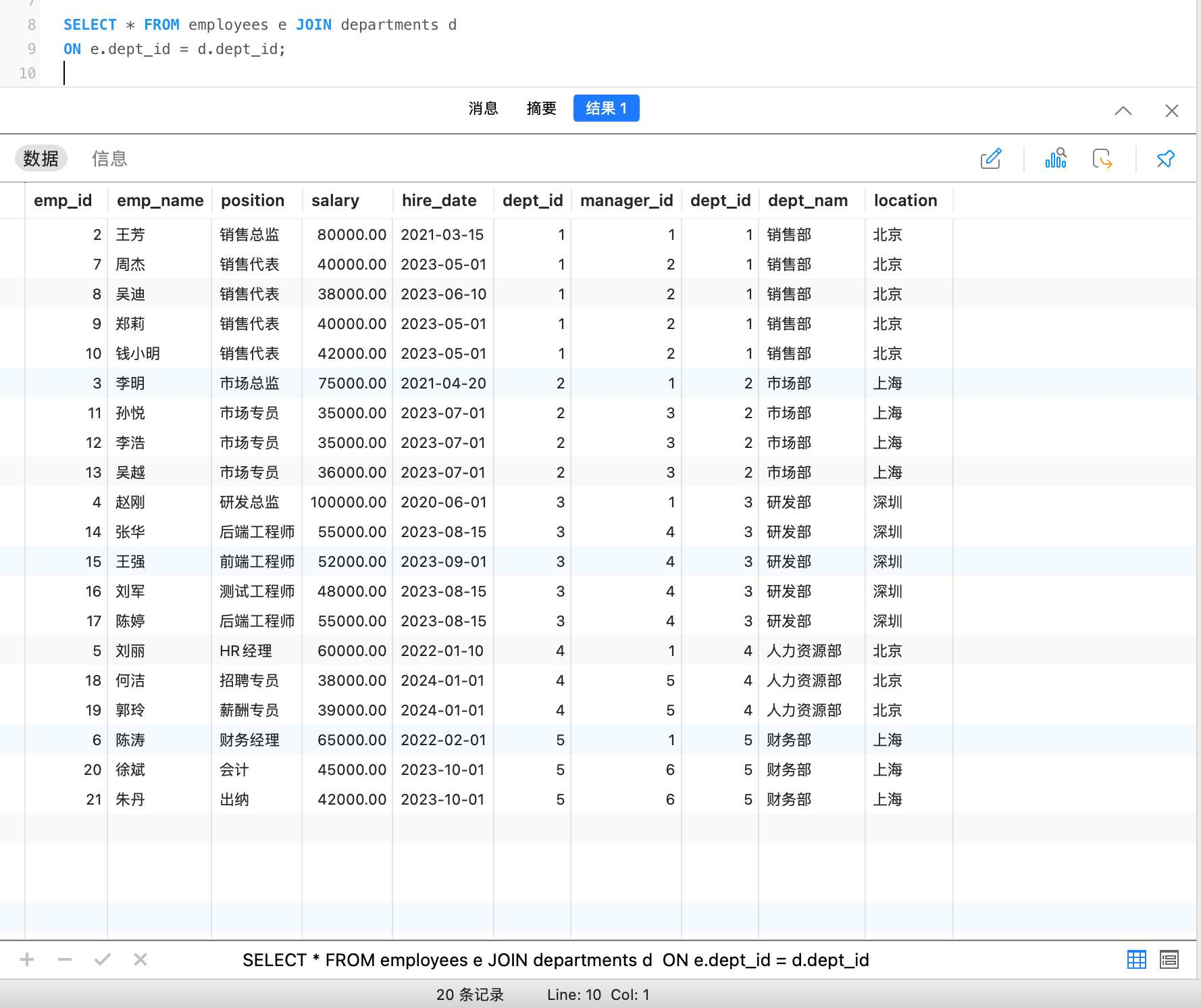
也可以这样写,结果一样:
sql
SELECT * FROM employees e , departments d
WHERE e.dept_id = d.dept_id;10.3 左外连接
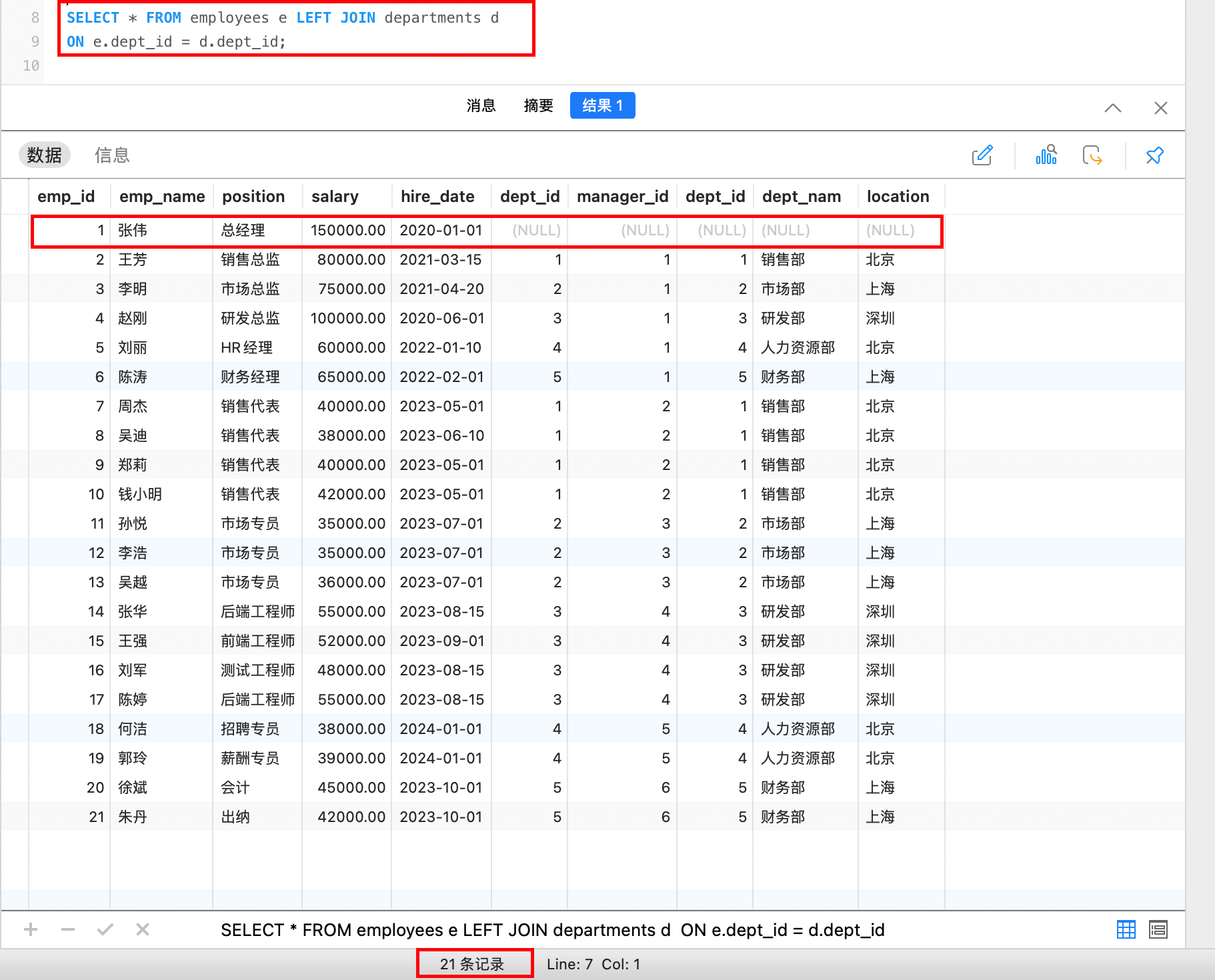
在上面的例子中,我们发现ID 为1 的员工信息没有输出,是因为该员工的部门ID为NULL,所以没有满足条件。如果我们想把所有的员工信息都查询出来,又该如何实现呢?可以使用左外连接。
左外连接返回左表中的所有行,以及右表中匹配的行。如果左表中的行在右表中没有匹配,右表对应的列显示为 NULL。
可以想象流程是取出左表中的一条记录,然后根据查询条件,依次匹配右表中的每条记录,如果满足条件,那么这两条记录组成一条结果记录,放入结果集中。如果在右表中找不到一条记录满足条件,那么同样把该左表记录放入结果集中,只不过右表对应的列显示为NULL。
左外连接语法如下,其中,outer关键字可以省略:
sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.*
from 表名1 left [outer] join 表名2
on 查询条件例如,查询员工及其所属的部门信息,即使该员工没有所属部门:
10.4 右外连接
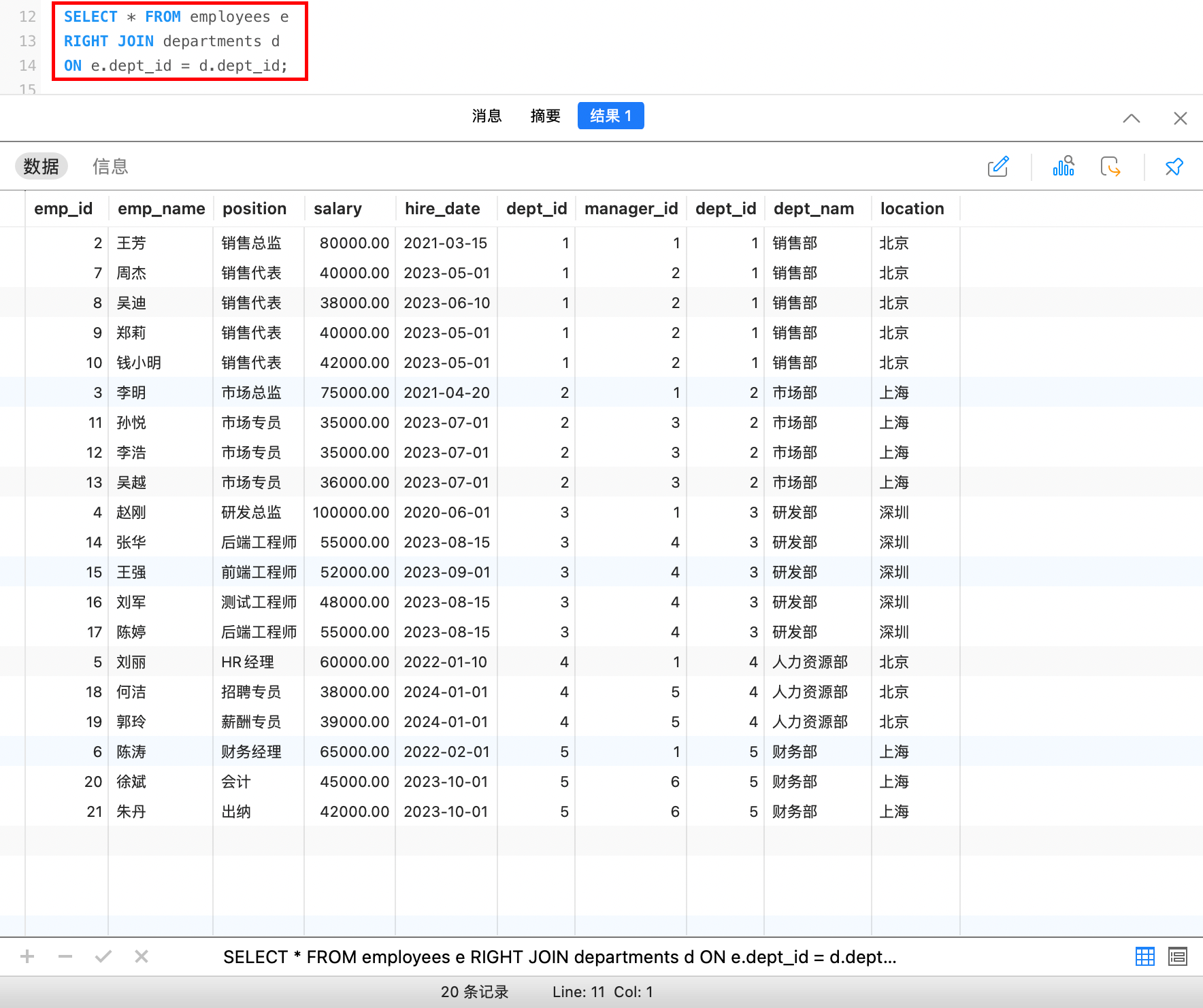
右外连接与左外连接类似,返回右表中的所有行,以及左表中匹配的行。如果右表中的行在左表中没有匹配,左表对应的列显示为 NULL。
右外连接语法如下:
sql
select 表名1.字段1, 表名1.字段2 ... , 表名2.*
from 表名1 right [outer] join 表名2
on 查询条件其实我们可以把右外连接转换为左外连接,只需要将right关键字换成left,然后将两个表的位置交换即可。
例如,查询部门所拥有的员工信息:
10.5 自连接
在 SQL 中,自连接 是一种特殊的连接查询,指的是一个表自己与自己进行连接。
实现自连接的关键是给同一个表起不同的别名 (Alias)。这样,数据库就会把这个表当作两个独立的表来处理,然后就可以像连接不同表一样,使用 ON 子句来定义它们之间的关联条件。
自连接可以是内连接,也可以是外连接。
例如,查询出每个员工以及他们领导的姓名:
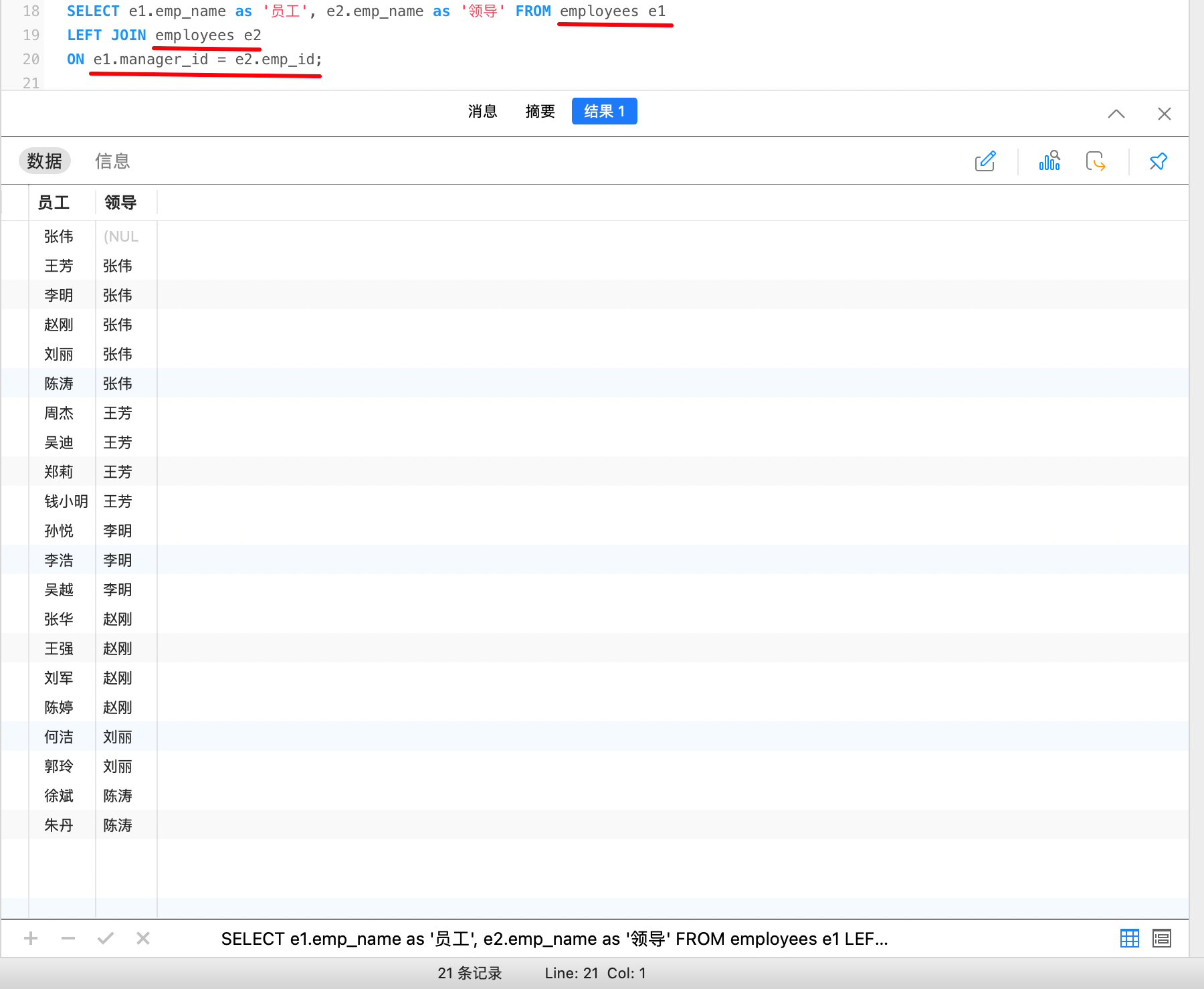
11. 联合查询
用于垂直组合来自两个或多个 SELECT 语句的结果集。它将多个查询的结果堆叠在一起,形成一个单一的结果集。联合查询要求所有 SELECT 语句的列数相同,且对应列的数据类型兼容。
核心思想: 堆叠结果,合并行。
常见类型:
UNION: 合并结果集,并自动去除重复行。UNION ALL: 合并结果集,保留所有重复行。性能通常比UNION更好,因为它不需要额外的去重操作。
例如,查询出2022年之前入职,以及薪资超过60000的员工:
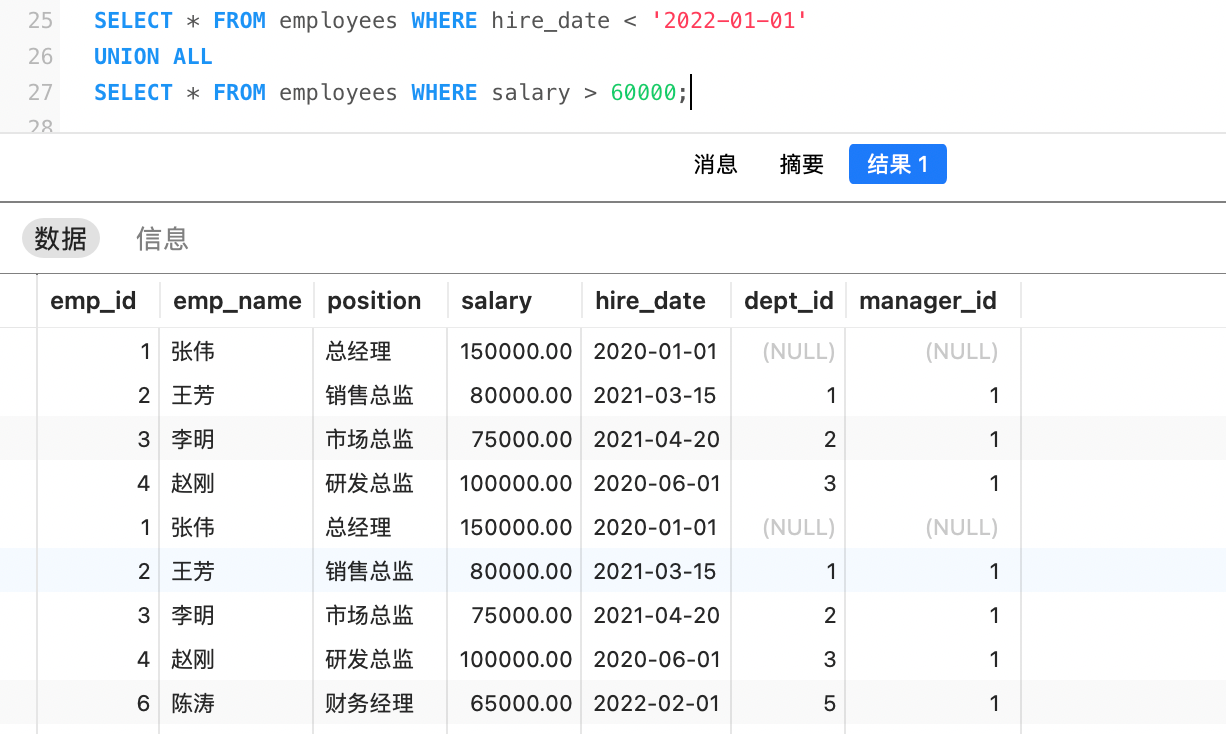
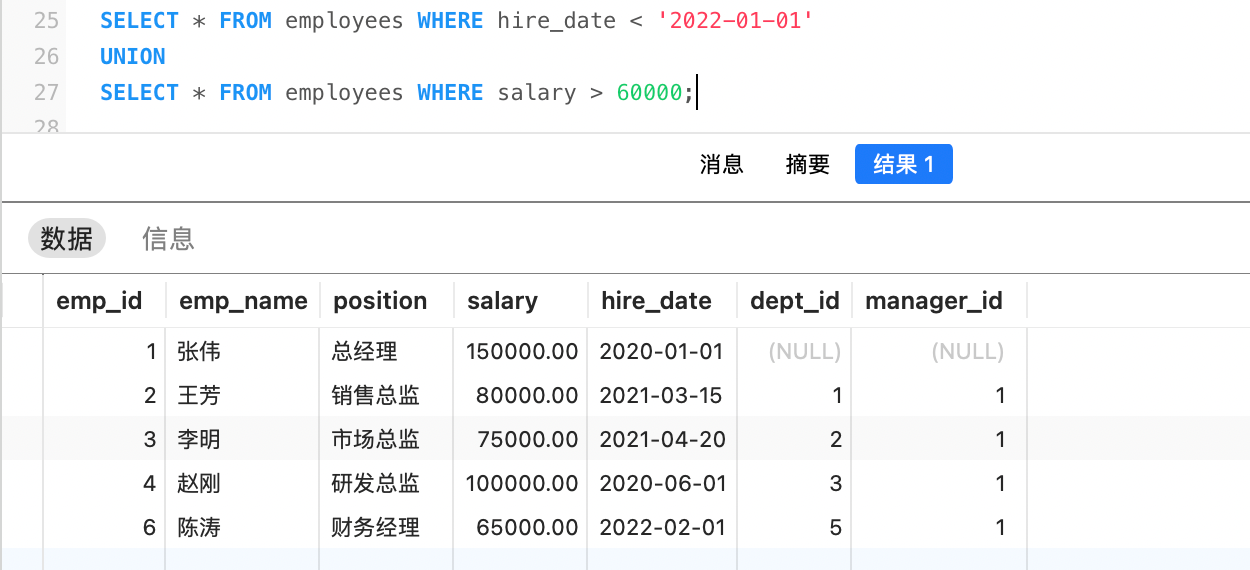
UNION ALL会保留所有重复行,我们也可以使用UNION去除重复行:
12. 子查询
是指嵌套在另一个 SQL 查询(称为外部查询或主查询)内部的查询。
根据子查询的结果不同,可以分为以下几种:
- 标量子查询:结果为单个值,即一行一列;
- 列子查询:结果为一列,可能有多行,即一列多行;
- 行子查询:结果为一行,可能有多列,即一行多列;
- 表子查询:结果为一张表,即多行多列;
根据子查询出现的位置,可以将子查询分为以下两种:
- 作为查询条件:出现在
where或having后; - 作为中间表:出现在
from后; - 作为结果集字段:出现在
select后;
12.1 标量子查询
标量子查询的结果是单个值,即一行一列,常用作查询条件,即where或having后,常用的操作符有:=、!=、>、>=、<、<=。
例如,查询销售部所有员工的信息。
针对上面的问题,我们可以分两步解决:
由于员工表中只有部门ID,没有部门名称,所以我们要先根据名称查询出部门ID;
sqlSELECT dept_id FROM departments WHERE dept_name = '销售部'; -- 结果为 : 1然后再通过部门ID查询出员工信息;
sqlSELECT * FROM employees WHERE dept_id = 1;
将上面两步结合起来,可以写出下面的SQL:
sql
SELECT * FROM employees
WHERE
dept_id = ( SELECT dept_id FROM departments WHERE dept_name = '销售部');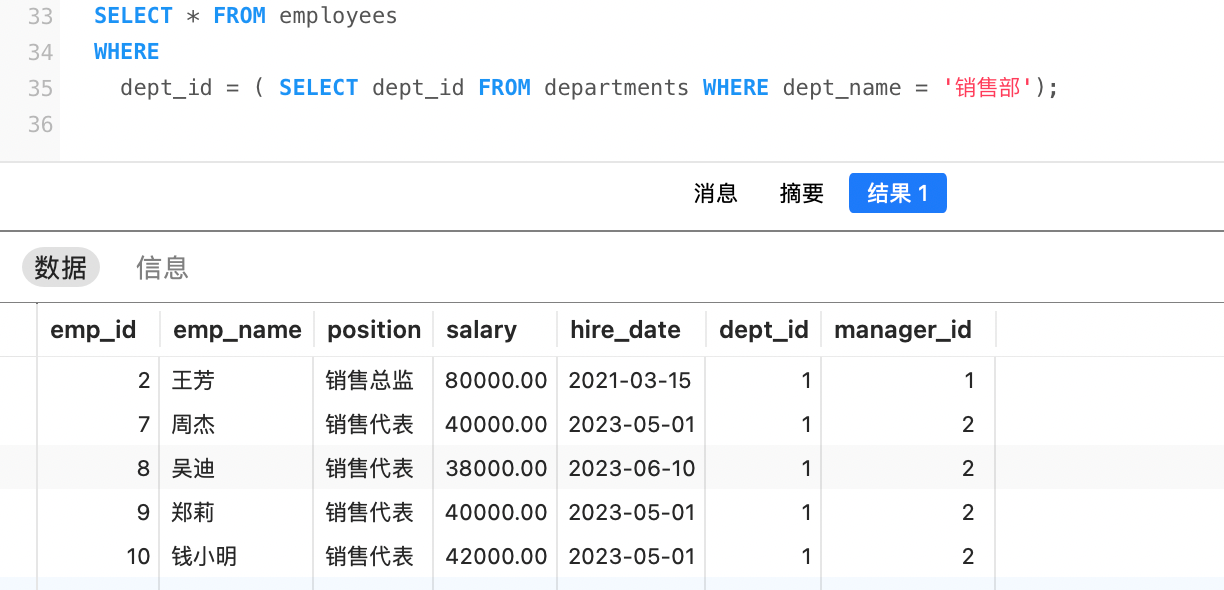
例如,查出销售部门员工的平均工资
我们同样可以分两步进行:
查出销售部门的ID;
sqlSELECT dept_id FROM departments WHERE dept_name = '销售部'; -- 结果为 : 1在员工表中按部门ID进行分组,计算平均工资,然后查出销售部门的平均工资:
sqlSELECT AVG(salary) FROM employees GROUP BY dept_id HAVING dept_id = 1;
最后将上面两步合并起来,得出结果:

12.2 列子查询
列子查询的结果为一列,可能有多行,即一列多行。列子查询常用作查询条件,操作符如下:

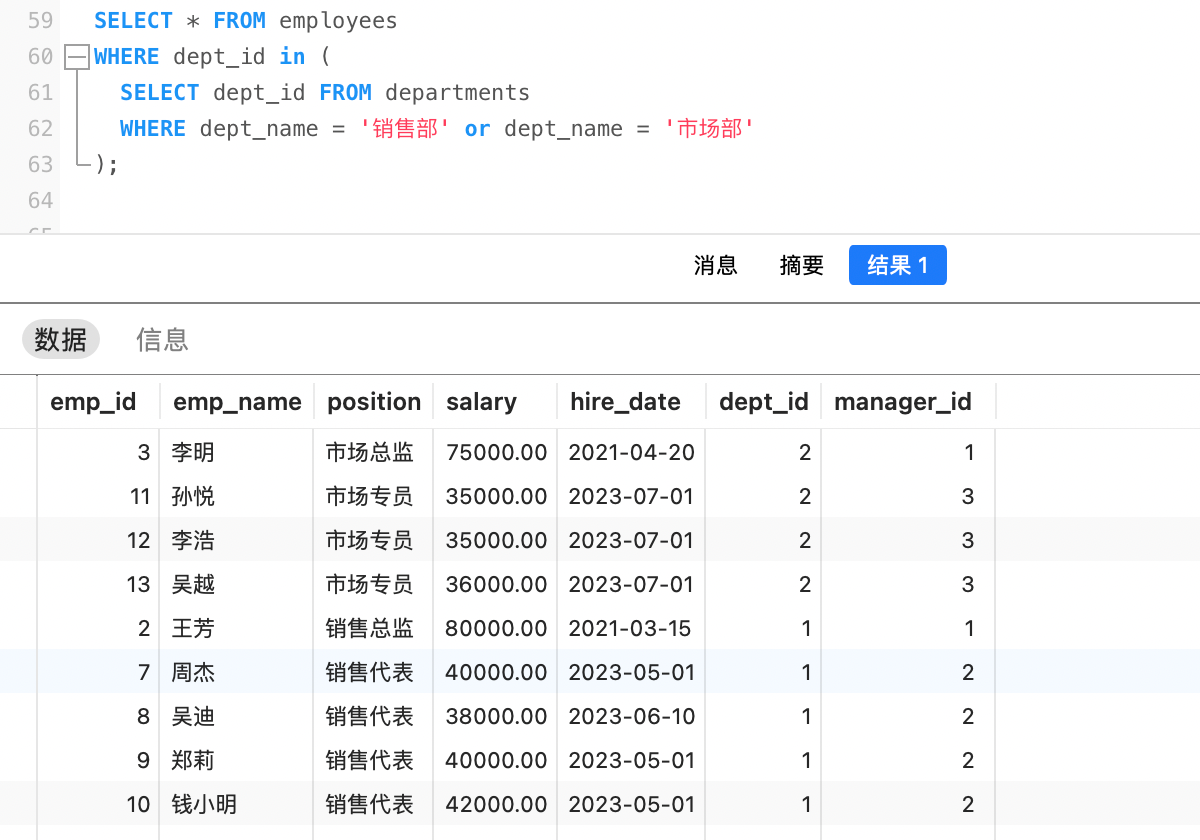
例如,查询销售部和市场部的所有员工信息。
分两步进行:
查询销售部和市场部的ID:
sqlSELECT dept_id FROM departments WHERE dept_name = '销售部' or dept_name = '市场部'; -- 结果如下: 2 1然后查询员工信息:
sqlSELECT * FROM employees WHERE dept_id in (1,2);
综合以上两步,得出结果:
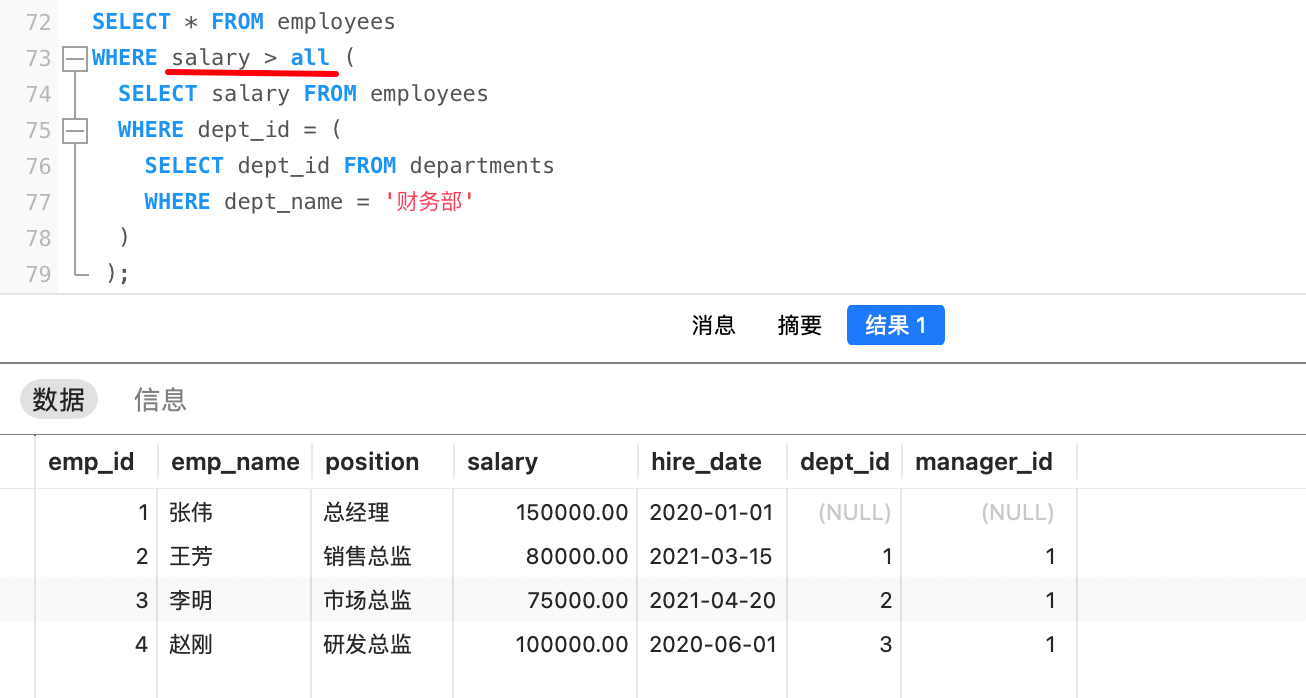
例如,查询比财务部所有人工资都高的员工信息
第一步,查询出财务部的ID:
sqlSELECT dept_id FROM departments WHERE dept_name = '财务部'; -- 结果为:5第二步,查询出财务部所有人员的工资:
sqlSELECT salary FROM employees WHERE dept_id = 5; -- 结果如下: 65000.00 45000.00 42000.00第三步,查询出比财务部所有人工资都高的员工信息:
sqlSELECT * FROM employees WHERE salary > all ( 65000.00, 45000.00, 42000.00 );注意,上面的SQL语句无法运行,是因为 > all 是为子查询设计的,不能和字面量使用。
综合以上三步,我们可以得出结果:
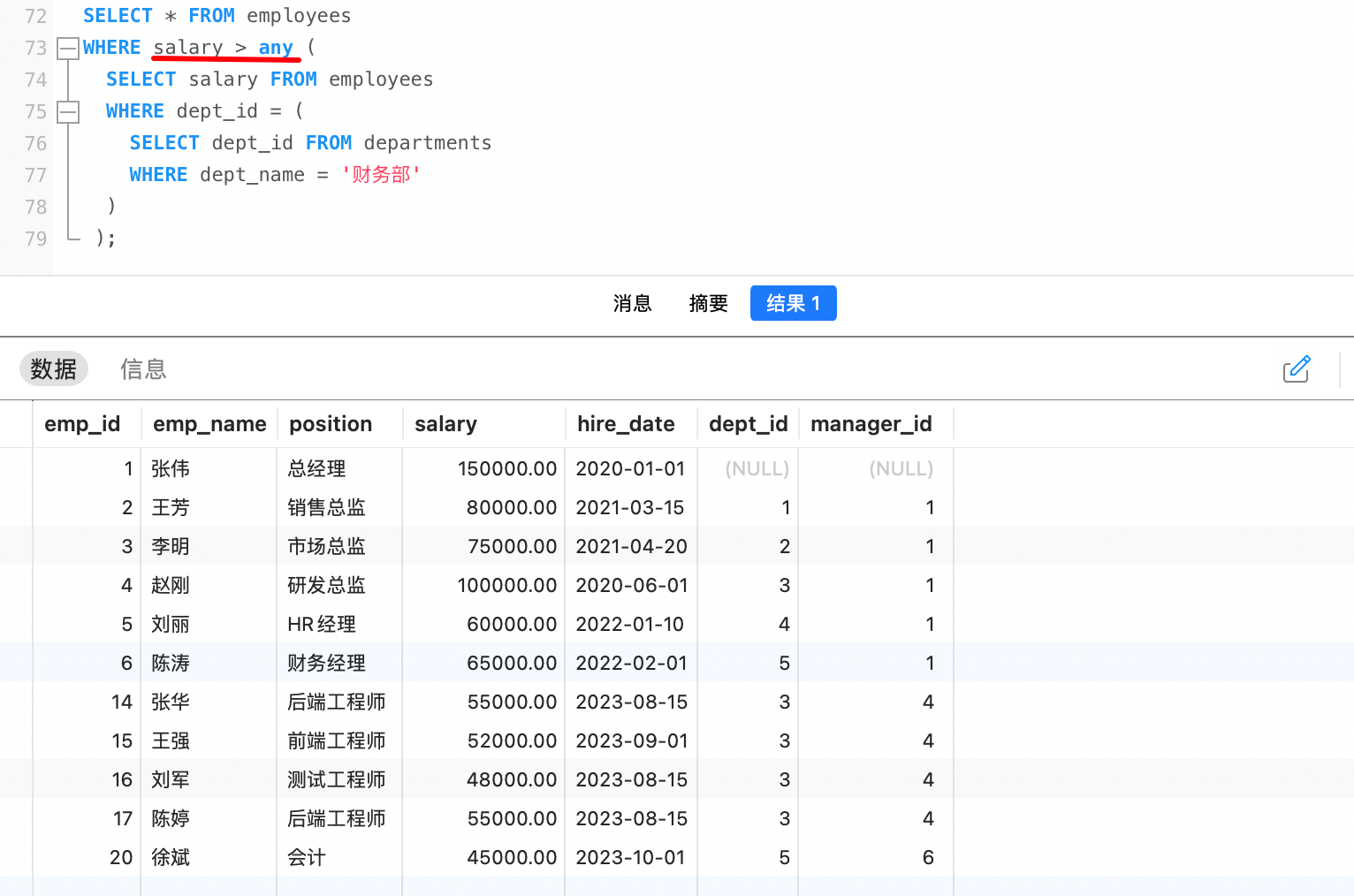
例如,查询出比财务部任意一人工资高的员工信息
分析过程与上例相似,此处略过,结果如下:
12.3 行子查询
行子查询结果为一行,可能有多列,即一行多列。行子查询的主要用途是实现多列比较,即同时比较多个字段的值。常用的操作符有=、!=、in、not in。
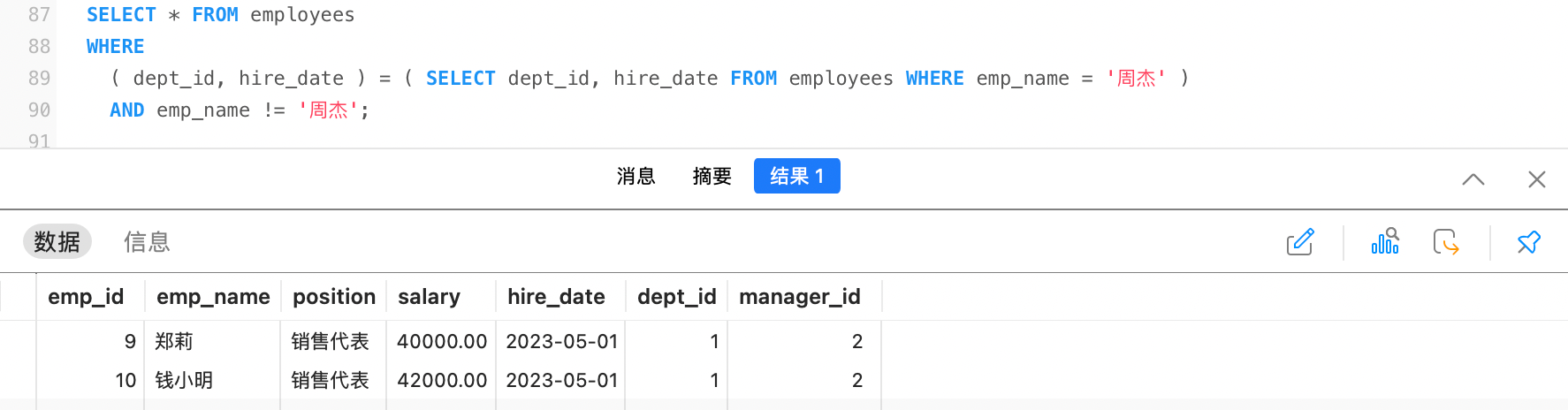
例如,查询出与周杰同部门入职日期相同的员工信息
第一步,查询出周杰的部门与薪资:
sqlSELECT dept_id, hire_date FROM employees WHERE emp_name = '周杰' -- 结果:1 2023-05-01第二步,查询出与周杰同部门入职日期相同的员工信息
sqlSELECT * FROM employees WHERE dept_id = 1 AND hire_date = '2023-05-01'这种多个条件同时满足的条件查询,我们也可以换种写法:
sqlSELECT * FROM employees WHERE (dept_id, hire_date) = (1, '2023-05-01')
综上,我们就可以结合上面的两步给出最终SQL:
12.4 表子查询
表子查询结果为一张表,即多行多列。表子查询可以用作查询条件,常用操作符为IN,也可以用作中间表。
例如,查询与孙悦和周杰职位和薪资相同的员工信息
第一步,查询出孙悦和周杰的职位和薪资:
sqlSELECT position, salary FROM employees WHERE emp_name IN ('孙悦', '周杰') -- 结果如下: 销售代表 40000.00 市场专员 35000.00第二步,查询与孙悦和周杰职位和薪资相同的员工信息
sqlSELECT * FROM employees WHERE (position, salary) in (('销售代表', 40000.00),('市场专员', 35000.00))
结合以上两步,给出最终SQL:
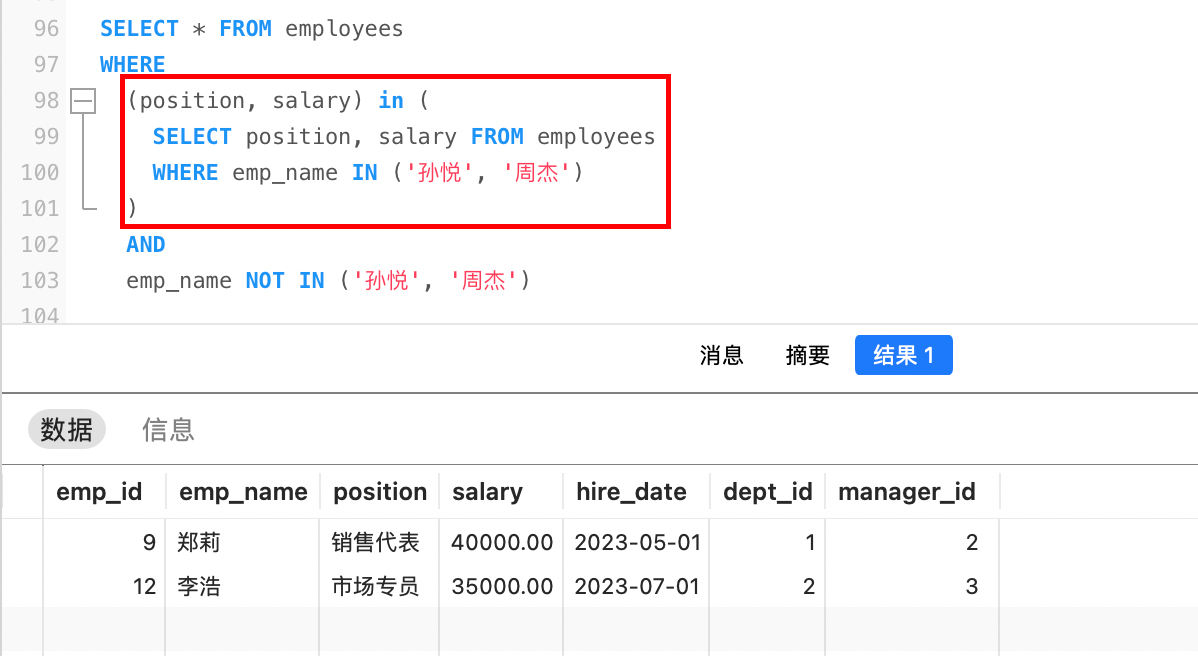
表子查询也可以作为中间表。
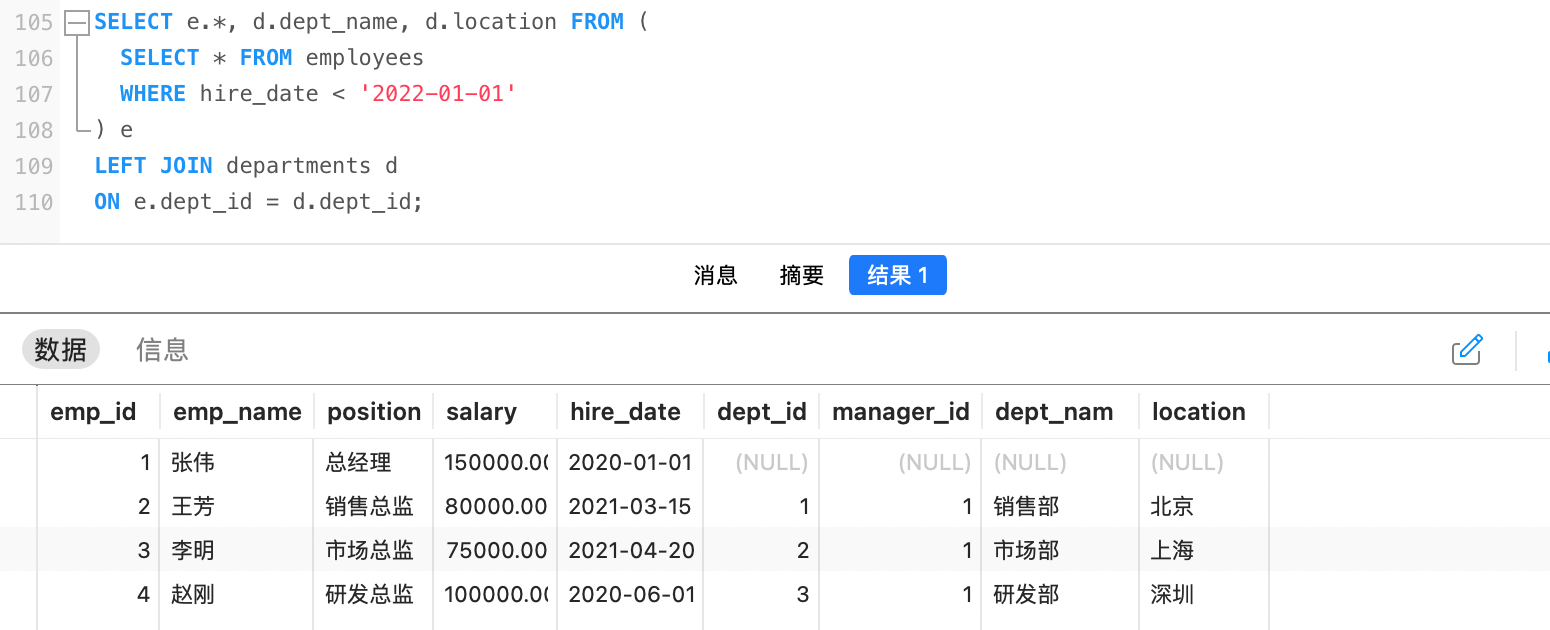
例如,查询入职日期在2022年之前的员工以及其部门信息
首先,查询出入职日期在2022年之前的员工信息:
sql
SELECT * FROM employees
WHERE hire_date < '2022-01-01'结果是一个子表,可以将该结果集作为中间表,与部门表连接查询: