Appearance
MySQL 索引
本文介绍MySQL中有关索引的知识,包括索引是什么、如何使用、索引原理等。
1. 索引是什么
在数据之外,数据库还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引(Index)。
概括来说,索引就是帮助MySQL高效获取数据的数据结构,可以加快查询数据的速度。
由于索引的维护需要一些代价,所以创建了索引后,会额外占据空间,而且对于insert、update、delete语句的执行效率有一定影响。但是,目前磁盘空间价格便宜,而且DML语句的执行频次比DQL语句的执行频次低,所以总而言之,索引的使用是利大于弊的,
在MySQL中,索引按照索引列值的特性可分为如下几类:
- 主键索引:索引列就是主键列;如果创建了主键,那么会自动创建主键索引,一张表中只能有一个主键索引,关键字
PRIMARY; - 唯一索引:索引列的值必须唯一,但允许有
NULL值(如果允许的话,NULL值可以有多个);如果创建的是复合唯一索引,则所有列的组合值必须唯一。一张表中可以有多个唯一索引,关键字UNIQUE; - 常规索引:对索引列的值没有要求,允许重复值和
NULL值,用于快速定位数据加快查询速度。一张表中可以有多个常规索引。
索引按照索引列的数量,可以分为如下两类:
- 单列索引:在表中的一个列上创建的索引;
- 联合索引:在表中的多个列上联合创建的索引;
2. 如何使用索引
2.1 查看索引
如果要查看某张表上有哪些索引,我们可以使用如下命令:
sql
show index from table_name;例如:

2.2 创建索引
创建索引有两种方式:显式创建和隐式创建。
显式创建
显式创建是指手动用命令创建索引,语法如下:
sql
create [unique] index index_name on table_name(column1, column2 ...);unique关键字是可选的,如果指定了unique,那么创建的是唯一索引,没有指定创建的则是常规索引;- 表名后面紧跟列名,可以指定一个或多个列,一个列即单列索引,多个列即联合索引;
- 索引名一般按照如下规则书写:
idx_tableName_columnName,例如,要在学生表上为姓名列创建索引,那么索引名为idx_stu_name,如果要在多列上创建索引,则列名均写出,例如,要在学生表上为姓名列、电话列创建索引,那么索引名为idx_stu_name_phone;
隐式创建
隐式创建是指在建表时,会根据关键PRIMARY KEY和UNIQUE创建主键索引和唯一索引。
例如,在下面的表departments中,我们并没有创建索引,但是会发现departments有两个索引:
这是因为在创建表时,指定了主键列和唯一列:
sql
CREATE TABLE IF NOT EXISTS departments (
dept_id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(100) NOT NULL UNIQUE,
location VARCHAR(100)
);所以MySQL自动根据关键字为我们创建了对应的索引。
2.3 使用索引
当在一张表上创建了索引后,使用select对该表进行条件查询时,数据库就会尝试使用索引加快查询速度,对于使用者来说,这是完全无感的,我们只需要按照之前的方式编写select查询语句就好。
2.4 删除索引
删除索引可以使用如下语法:
sql
drop index index_name on table_name;3. explain
explain 是 MySQL 数据库中一个非常强大和重要的 SQL 命令,用于分析和显示 SQL 查询语句的执行计划。
explain可以帮助我们理解查询过程中的以下问题:
表的访问顺序: MySQL 会以何种顺序访问参与查询的表(特别是多表 JOIN 的情况)。
访问类型 (Access Type): MySQL 如何读取表中的数据,是全表扫描、全索引扫描、还是使用索引进行范围查找或精确查找。
索引的使用: MySQL 是否使用了可用的索引,如果使用了,是哪个索引,使用了索引的哪些部分。
扫描行数估计: MySQL 估计需要扫描多少行数据才能完成查询,这个数字越小通常越好。
explain的使用非常简单,只需要在查询语句前加上explain就行了:
sql
explain [SQL 查询语句];例如:

可以看到,explain命令的输出非常丰富,我们一个一个解释每列的作用:
id:在复杂查询(如包含子查询、UNION)中,
id值表示查询中每个 SELECT 子句的执行顺序。id值相同的行,表示它们属于同一组操作,执行顺序通常从上到下。id值不同的行,id值越大,执行优先级越高,通常会先执行id值大的操作(如子查询),然后将结果作为输入传递给id值小的操作。
select_type:SELECT 查询的类型,取值如下:
SIMPLE: 最简单的 SELECT 查询,不包含 UNION 或子查询。PRIMARY: 对于包含子查询或 UNION 的复杂查询,这是最外层的 SELECT。SUBQUERY: 在 SELECT 或 WHERE 子句中出现的子查询的第一个 SELECT。DERIVED: 在 FROM 子句中出现的子查询(派生表)。MySQL 会先执行这个子查询并将结果存入临时表,然后再与外层查询进行关联。UNION: UNION 操作中第二个或以后的 SELECT 语句。UNION RESULT: UNION 操作的结果。
table:正在访问的表名。如果是派生表或子查询结果,会显示
<derivedN>或<subqueryN>,其中N是对应的id值。partitions:对于分区表,显示查询将访问哪些分区。如果查询不是针对分区表的,此列为
NULL。type: 连接类型,这是评估查询性能的最重要指标之一,表示 MySQL 如何查找表中的行。性能从好到差的连接类型如下:
null:表示查询不涉及表。例如:explain select 1;system:表只有一行(系统表),这是一种特殊的const类型,此处不过多介绍;const:表最多只有一个匹配行,通常情况下是 SQL 中使用了主键索引或唯一索引,例如:sqlSELECT * FROM user WHERE id = 1; -- id为主键eq_ref:对每个来自前面表的行,最多返回一行数据(通常用于主键或唯一索引连接),连接查询中使用主键或唯一索引作为连接条件。例如:
对于前面表
employees中的每一行,在表departments中最多找到一行可以满足连接条件;ref:使用非唯一索引或唯一索引的前缀进行等值匹配,可能匹配多行。例如,dept_id列存在索引: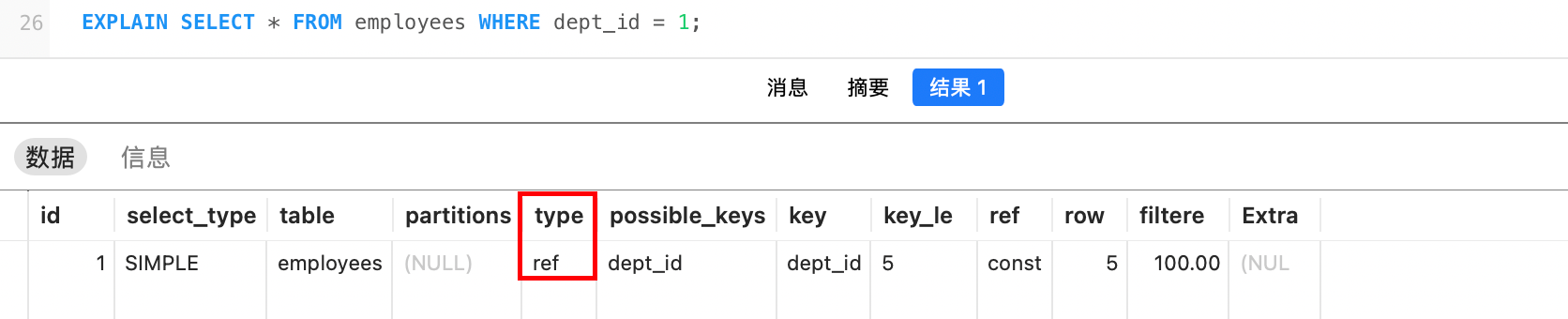
range:索引范围扫描。通过索引查找某个范围内的行。适用于BETWEEN,>,<,>=<=,IN,OR等操作。例如: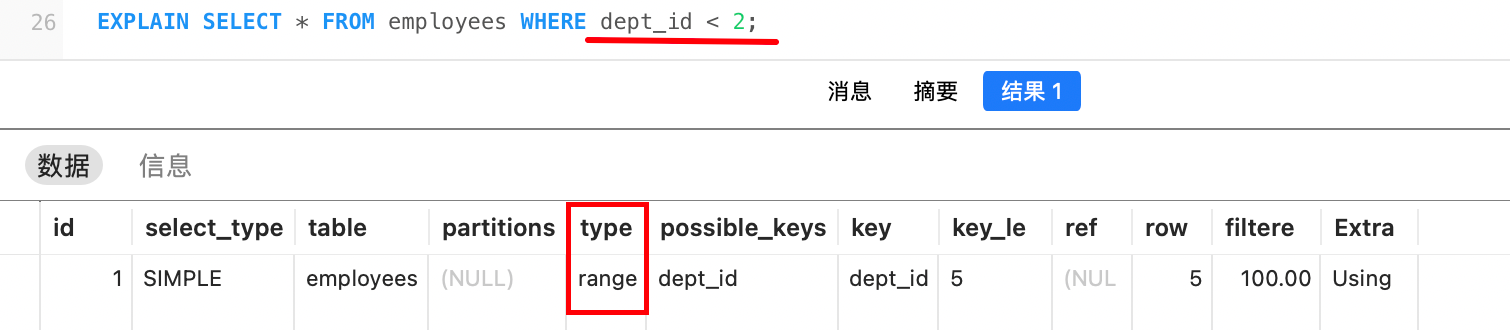
index:全索引扫描。遍历整个索引树,但只访问索引数据,不需要回表。比ALL好,但仍然意味着扫描了大量数据,通常发生在查询的所有列都是索引列(覆盖索引)的情况下。all:全表扫描。MySQL 必须扫描整张表来找到匹配的行。
小结:
优先让查询使用
const,eq_ref,ref类型。避免出现
all和index。添加适当的索引(尤其是覆盖索引)可以提升
type类型。
possible_keys: MySQL 优化器在执行查询时可能考虑使用的索引。这是一个建议列表,不代表实际会使用。
key:MySQL 实际选择用来优化查询的索引。如果为
NULL,表示没有使用索引。key_len:MySQL 使用的索引的长度(字节数)。
对于复合索引,
key_len越大,表示使用的索引列越多,通常意味着索引的选择性越好,过滤能力越强。ref:表示的是 执行查询时使用哪个列或常量与索引进行比较(等值比较),常见的值如下:
const:用常量与索引做比较;func:使用了函数(比如YEAR(date_col));NULL:没用上等值比较来进行查找;表名.列名:使用了某个表的某个字段做关联(多表连接时常见);
例如:

在上面的例子中,
key = dept_id表示用了dept_id索引,type=range表示使用了索引的范围扫描 ,ref=null表示不是等值查找(不是用ref类型),而是用范围查找。row:MySQL 估计为了找到所需的行而必须检查的行数,这是估算出来的结果,与实际扫描的行数有所偏差。估计值越小越好。
filtered:表示通过此表条件过滤的百分比。例如,如果
rows是 1000,filtered是 10.00,表示最终只有 100 行满足条件。这个百分比越高(接近 100%),表示过滤效果越好。Extra:额外信息,包含非常重要的优化器提示和警告。取值如下:
Using index: 覆盖索引。查询的所有列都可以在索引中找到,无需回表(访问实际数据行)。这是最高效的查询之一。Using where: 表示使用了WHERE子句来过滤结果。
4. 索引使用规则
学习了explain的用法,我们就可以使用explain来观察查询语句使用索引的情况,并以此总结索引使用规则。
4.1 比较运算符使用索引的情况
下标列出了一些基本的比较运算符使用索引的情况:
| 比较操作符 | 能否用索引 | 类型(type) |
|---|---|---|
= | ✅ 能 | const / ref |
IN (...) | ✅ 能 | range |
> < >= <= | ✅ 能 | range |
BETWEEN | ✅ 能 | range |
!= | ⚠️ 可能使用(效率差) | range(不一定) |
NOT IN | ⚠️ 可能使用(效率差) | range(不一定) |
4.2 最左前缀原则
当创建了复合索引 (col1, col2, col3) 时,查询必须从索引的最左边列开始匹配才能使用索引。
能使用索引的情况:
WHERE col1 = 'xxx'WHERE col1 = 'xxx' AND col2 = 'yyy'WHERE col1 = 'xxx' AND col2 = 'yyy' AND col3 = 'zzz'
不能使用索引的情况:
WHERE col2 = 'yyy'(没有col1,索引失效)WHERE col3 = 'zzz'(没有col1和col2,索引失效)
部分使用索引的情况:
WHERE col1 = 'xxx' AND col3 = 'zzz'(只有col1能用索引,col3不能)当遇到范围查询时,最左前缀原则会停止匹配。例如,对于复合索引
(a, b, c),WHERE a = 1 AND b > 10 AND c = 3,只有a和b能用到索引,c将无法使用。
4.3 模糊查询
在模糊查询(like)中,前缀匹配可以利用索引,后缀匹配不能使用索引。例如:
where name like '%三':不能使用索引;where name like '_三':不能使用索引;where name like '张%':可以使用索引;where name like '张_':可以使用索引;
4.4 对索引列进行计算
当对索引列进行计算或进行函数运算时,无法使用索引。例如:
where substring(emp_name,1,1) = '张':无法使用索引;where dept_id + 1 = 2:无法使用索引;
4.5 类型不匹配
如果索引列与比较值类型不匹配,则可能发生隐式类型转换,无法使用索引。
例如,假设phone是字符串类型:
sql
SELECT * FROM t WHERE phone = 1234567890;
-- 假设 phone 是 varchar,这里数字比较会导致全表扫描 ❌
-- 应写为:
SELECT * FROM t WHERE phone = '1234567890'; -- ✅ 用到索引4.6 OR查询
在使用 OR 连接的条件中,只要有一个条件列没有索引,那么整个 OR 语句的索引都会失效。例如:
sql
SELECT * FROM students WHERE phone = '13800000005' OR name = 'Eva';
-- ❌ 由于name 没有索引,即使phone有索引,整个语句都不会使用索引
4.7 数据分布影响
要理解本小节内容,需要先理解聚簇索引和二级索引的概念。
索引选择率,也称为索引区分度,是衡量索引列中唯一值数量的指标,它表示一个列中不重复值的比例。
索引选择率的计算公式:
- 选择率越接近 1 (例如,主键、唯一键),表示该列的唯一值越多,数据分布越离散,索引的区分度越高,查询时能过滤掉的数据越多,索引效果越好。
- 选择率越接近 0 (例如,性别、状态等字段,只有少数几个固定值),表示该列的重复值越多,数据分布越集中,索引的区分度越低,查询时能过滤掉的数据越少,索引效果越差,甚至可能导致全表扫描比使用索引更快(因为索引查找和回表的开销可能大于直接扫描)。
MySQL 的查询优化器在决定是否使用索引时,会考虑多种因素,其中索引选择率是核心考量之一。
- 高选择率的索引:
- 能够快速地缩小查询范围,减少需要扫描的数据行数。
- 例如,在一个包含一百万用户表中,按
username(唯一) 查询,索引能立即定位到唯一一条记录。 - 在这种情况下,优化器倾向于使用索引。
- 低选择率的索引:
- 即使使用了索引,可能也需要扫描大量的数据行来找到匹配的记录,并且需要多次回表操作 (如果不是覆盖索引)。
- 例如,在一个包含一百万用户表中,按
gender(只有 "男", "女", "未知" 几个值) 查询。假设 "男" 有 50 万条记录,即使使用gender索引,优化器发现需要回表 50 万次,它可能会认为全表扫描的成本更低,从而放弃使用索引。 - 在这种情况下,优化器可能认为全表扫描的成本低于索引查找 + 回表的成本,从而选择全表扫描。
因此,在进行查找时,如果结果集占绝大部分,那么MySQL可能倾向于使用全表扫描。
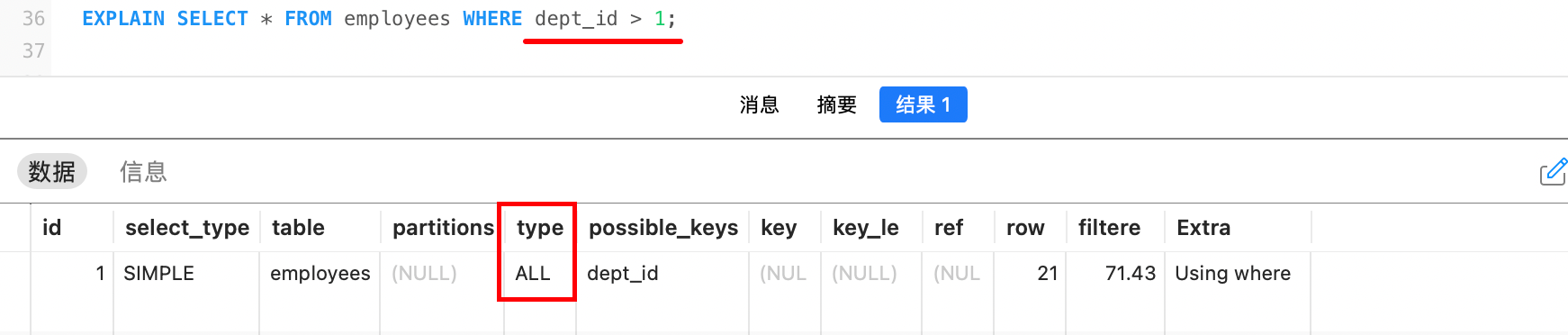
例如,在下面的例子中,部门ID(dept_id)的值大部分都是大于1的,因此查询出来的结果占大部分,区分度不高,索引查找 + 回表的成本高于全表扫描,所以使用了全表扫描:
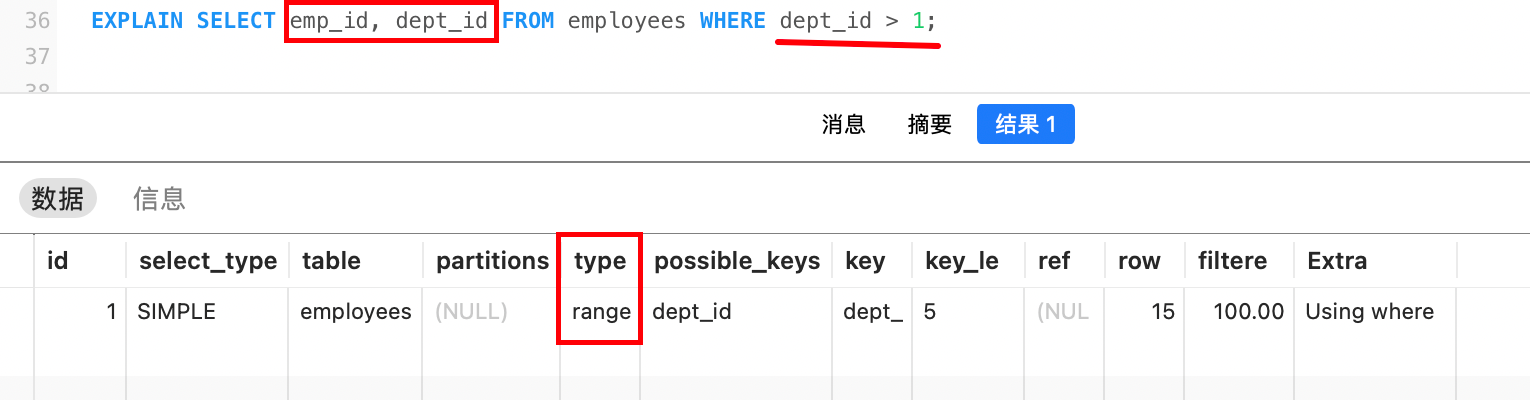
再例如,下面查询语句中,查询条件不变,但是选择的列变了(不用回表查询了),所以仍然会使用索引:
再例如,phone数据列都是有值的,当使用非空查询条件时,实际上会查询出全部数据,此时如果使用索引+回表,效率低于全表扫描,此时MySQL会使用全表扫描:

5. 索引原理
本小节主要介绍B+树索引结构。
5.1 索引介绍与存储引擎支持
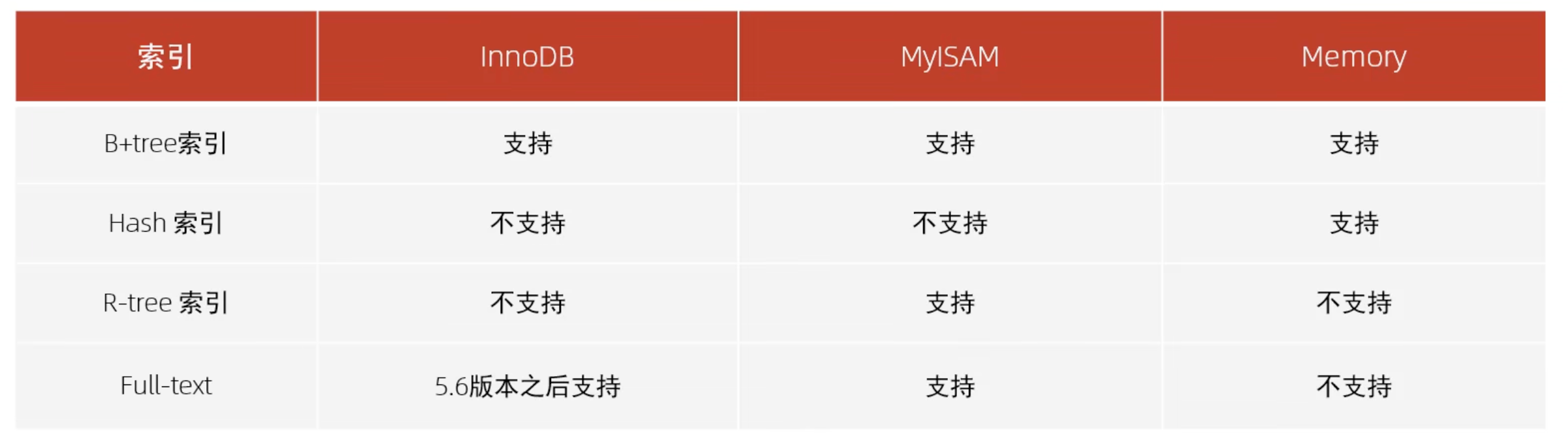
按照索引的实现原理,索引可分为如下几类:

MySQL的索引是在引擎层实现的,所以不同的存储引擎对不同的索引支持不一样:
5.2 二叉树与红黑树
当我们在无序列表中查找某个值时,如果只是用链表结构存储,那么就是全表扫描,如果数据量一大,效率很低。
因此,我们可以构建一棵二叉树,对于某个节点来说,左子树的值均小于该节点的值,右子树的值均大于该节点的值,如下:
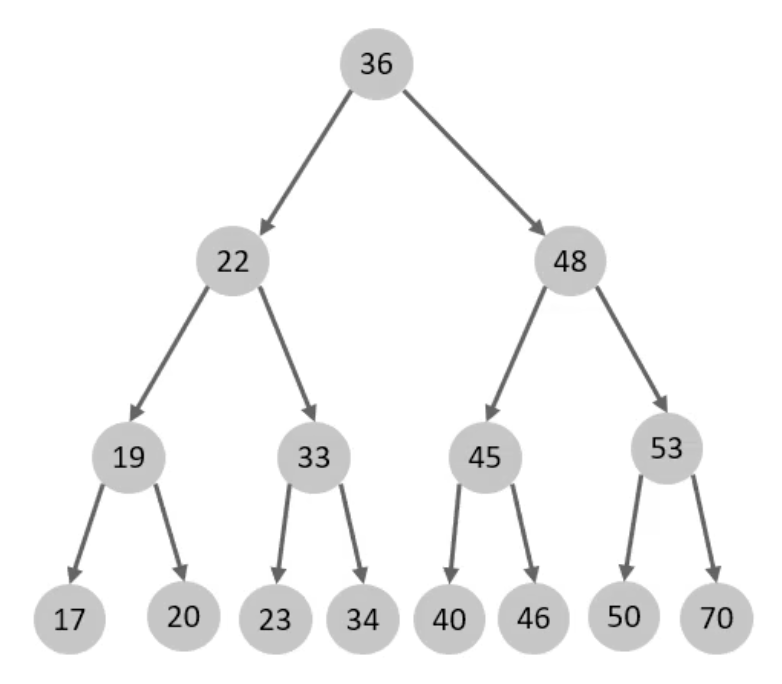
但是,二叉树也有弊端,如果顺序插入的情况下,二叉树会退化成链表:

为了解决二叉树退化为链表的问题,我们可以使用红黑树作为索引结构:
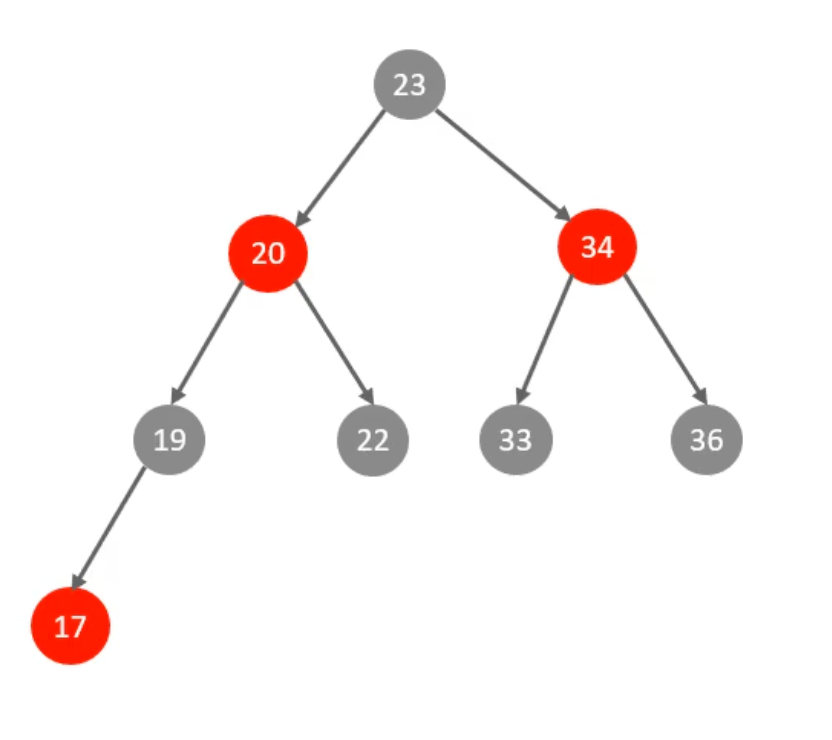
由于红黑树只有两个子节点,当数据量过多(在数据库系统中,这是大概率的)时,会有层级较深,检索速度过慢的问题。
5.2 B树
B树,又称多路平衡查找树,B树的每个节点可以拥有多个子节点。子节点的个数称为阶,例如,一棵B树的节点最多有5个子节点,那么称为5阶B树。
在B树中,对于一个内部节点,如果它有k个子节点和k-1个键值,那么第i个键值将所有小于它的值分隔到第i个子树中,所有大于它的值分隔到第i+1个子树中。
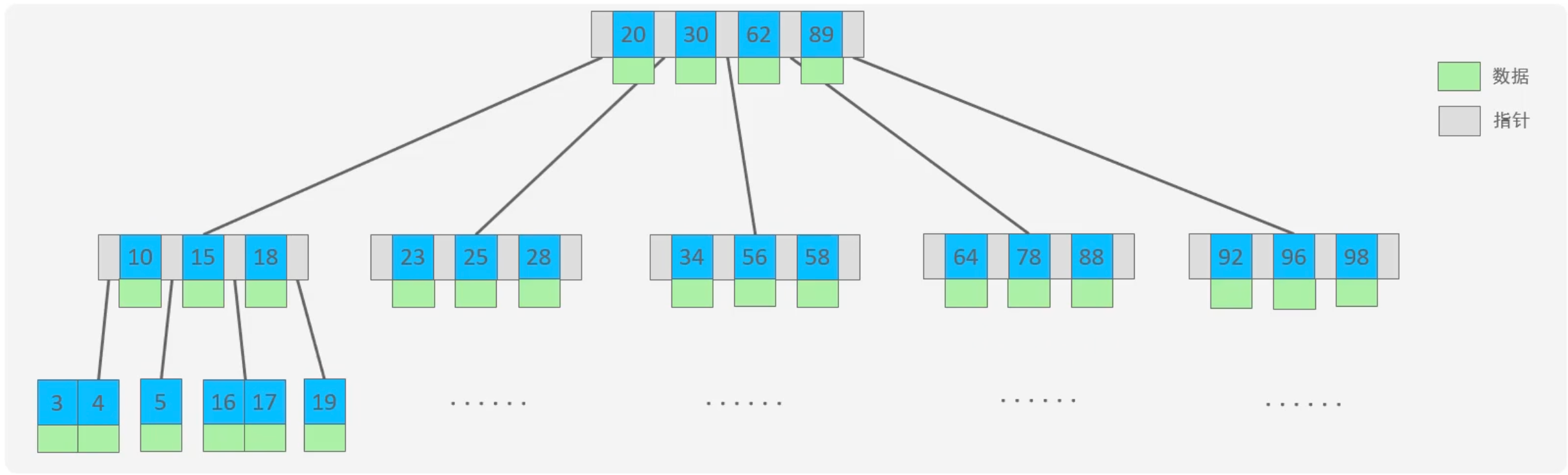
B树的性质(以M阶B树为例):
- 每个节点最多有M个子节点。
- 每个非叶子节点(除根节点外)至少有⌈M/2⌉个子节点。
- 如果根节点不是叶子节点,那么它至少有两个子节点。
- 有k个子节点的非叶子节点拥有k-1个键值。
- 所有叶子节点都在同一层。
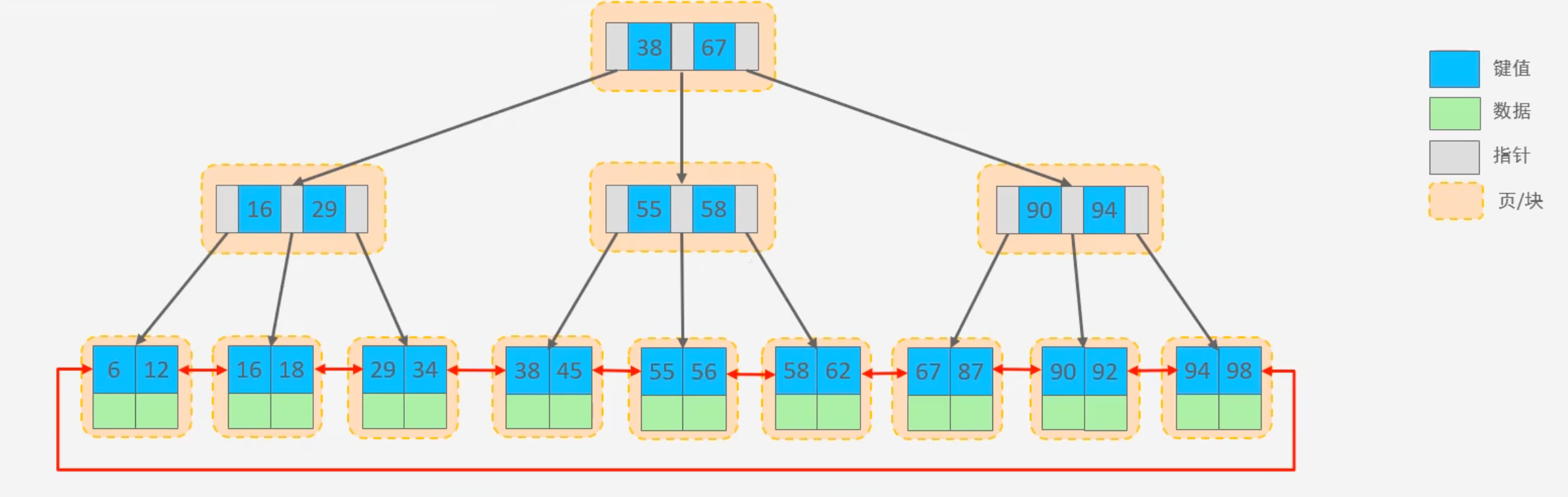
5.3 B+树
B+树(B+ Tree)是B树的一种变体,它与B树的不同之处在于:
数据存储位置:
B树: 内部节点和叶子节点都可以存储键值和对应的数据(或指向数据的指针)。
B+树:所有数据都只存储在叶子节点中。 内部节点(非叶子节点)只存储键值(作为索引),不存储实际的数据。
叶子节点连接:
- B树:叶子节点之间通常没有额外的连接。
- B+树:所有叶子节点都通过指针(通常是链表)顺序连接起来,形成一个有序链表(有利于排序、范围查询)。
查询效率:
- B树:查找数据时,可能在内部节点就找到数据,也可能需要到达叶子节点。因此,查询效率可能不稳定,最好的情况是O(1),最坏的情况是
(M为阶数)。 - B+树:所有的查询都会从根节点开始,一直遍历到叶子节点才能找到最终的数据。因此,查询效率非常稳定,总是
(M为阶数)。
- B树:查找数据时,可能在内部节点就找到数据,也可能需要到达叶子节点。因此,查询效率可能不稳定,最好的情况是O(1),最坏的情况是
6. 聚集索引和二级索引
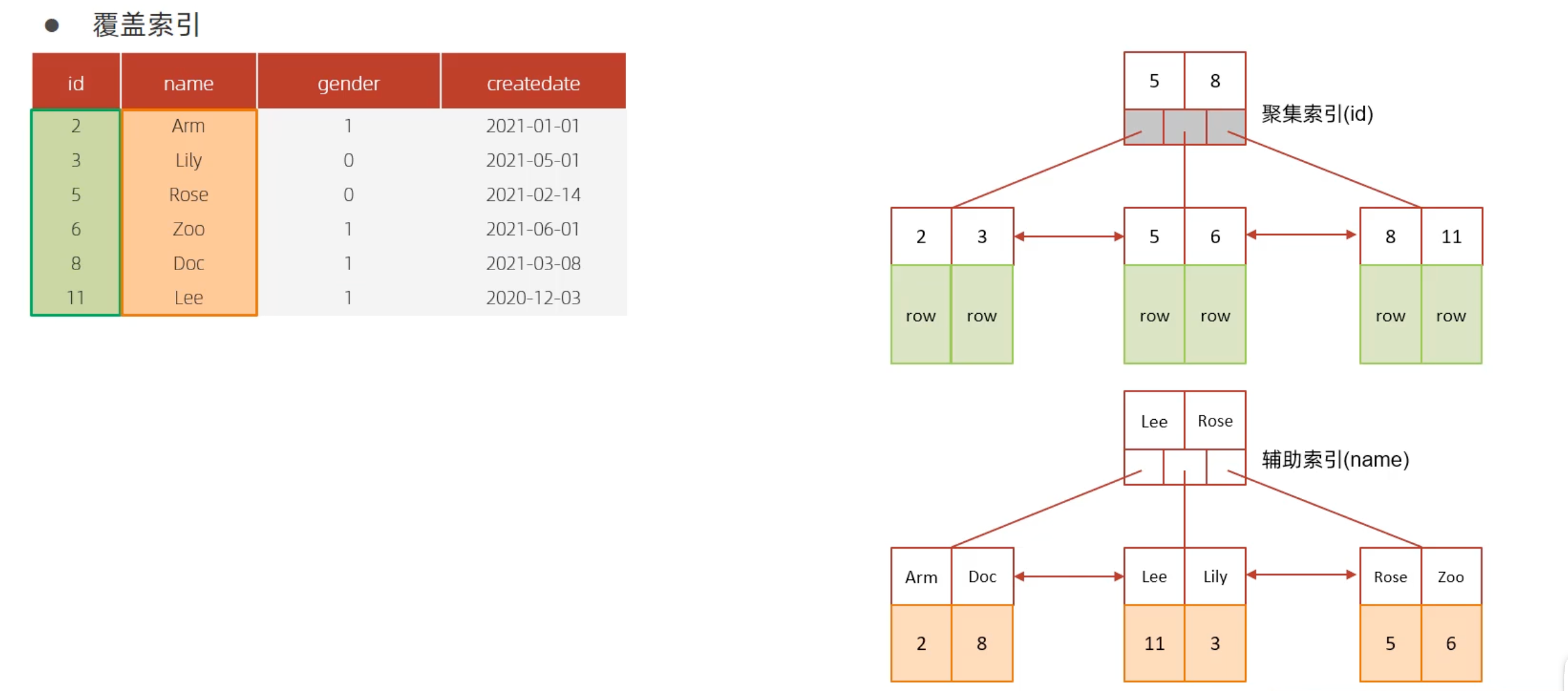
根据数据存储方式和索引叶子节点存储的内容,索引可以分为聚集索引和二级索引。
聚集索引:决定了表数据在磁盘上的物理存储顺序。也就是说,索引的叶子节点就是实际的数据行。一张表有且只有一个聚集索引。
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引;
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引;
- 如果表没有主键,或没有合适的唯一所以,那么InnoDB会自动生成一个
rowid作为隐藏的聚集索引;
二级索引:二级索引(或辅助索引)的叶子节点不存储实际的数据行,而是存储了索引键值和指向对应数据行的引用/指针。这个引用通常是聚集索引的键值(在InnoDB中)或物理行地址(在MyISAM中)。
例如,下图表示了聚集索引和二级索引:
在聚集索引叶子节点中,实际存储的数据
row就表示具体的数据行,所以数据实际是按照索引结构存储的;在二级索引中,叶子节点中的数据(橙色部分)存储的是聚集索引的键值(主键);
接下来看三个查询案例。
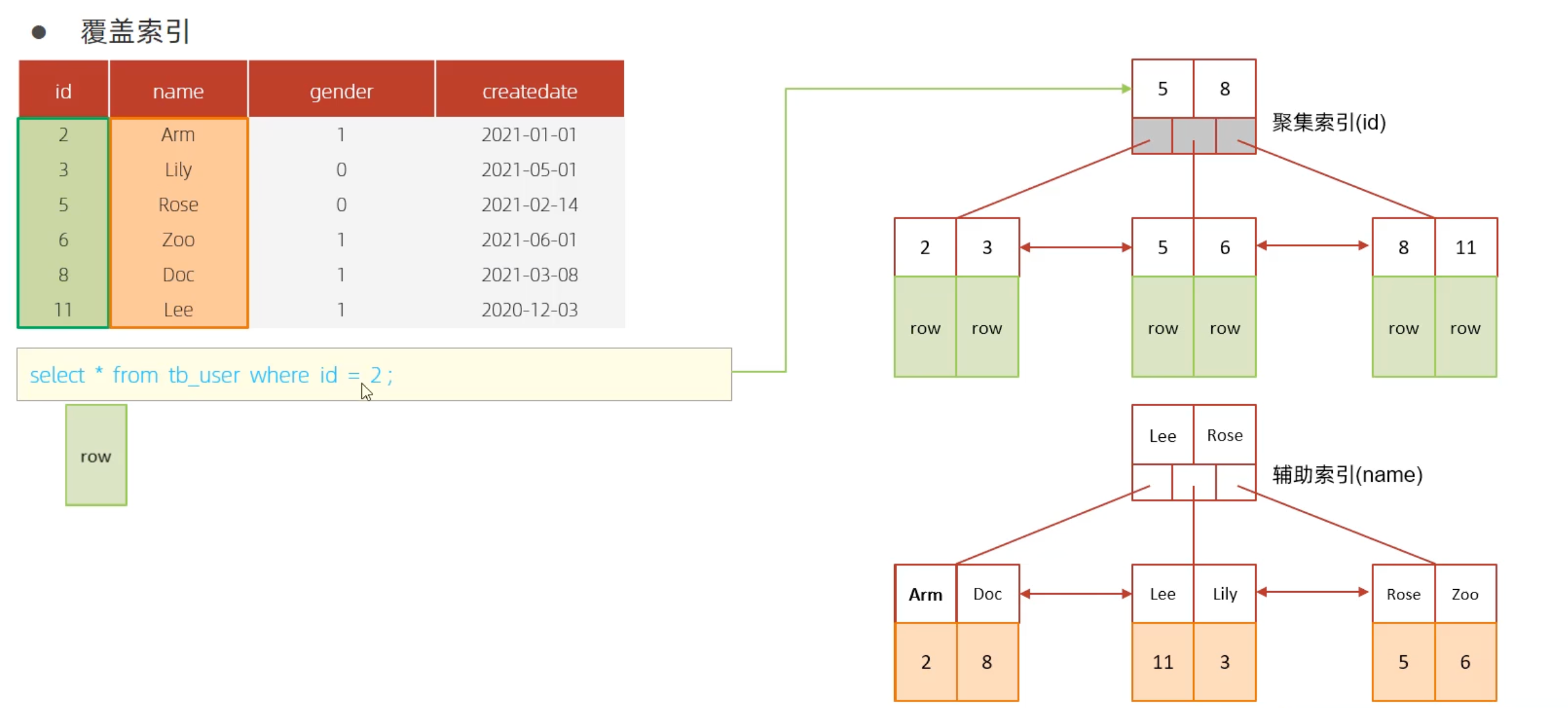
案例一:select * from tb_user where id = 2;
使用聚集索引,并且返回整个数据行内容,由于聚集索引包含所有数据,所以只需要查询一次索引即可。
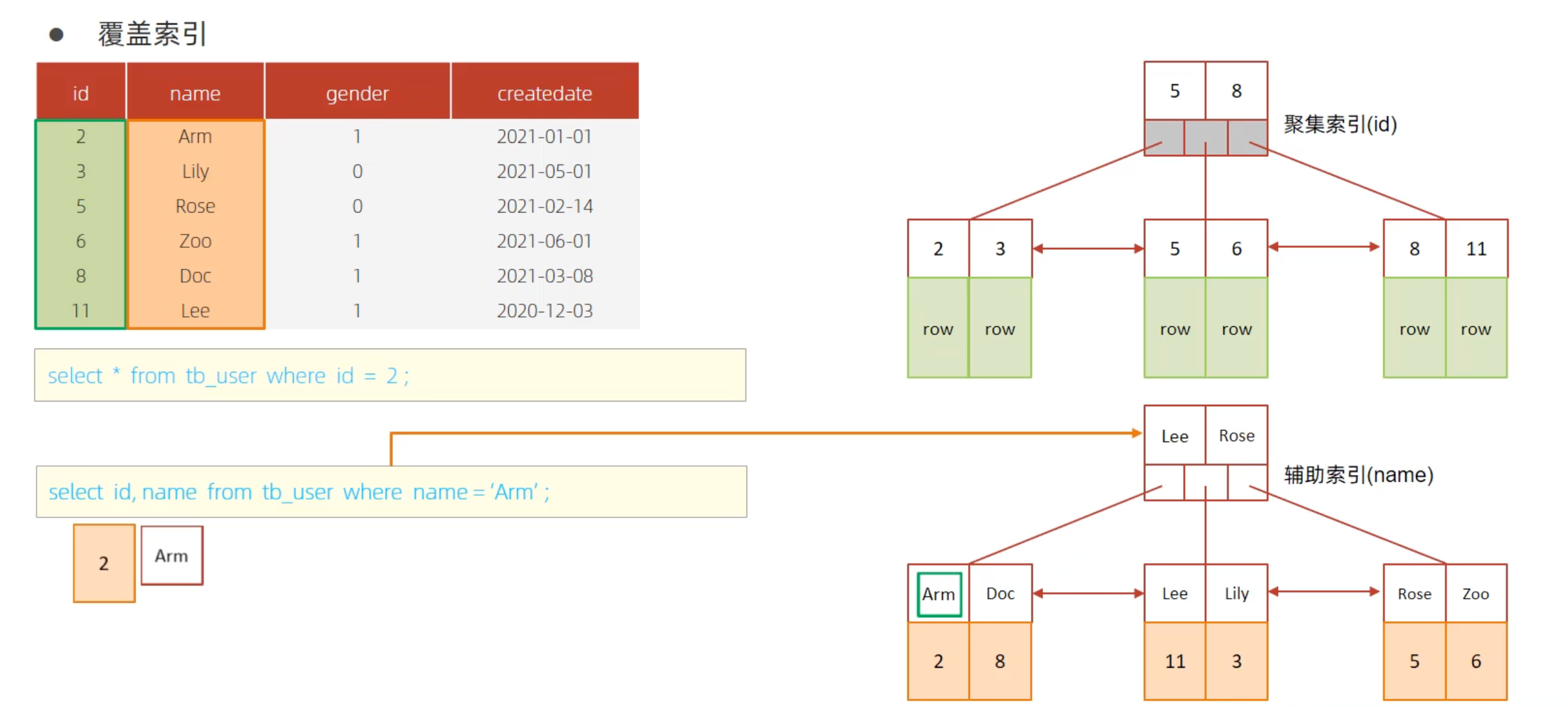
案例二:select id, name from tb_user where name = 'Arm'
使用了二级索引name,并且返回id和name,这两者在二级索引中都存在(name是键,id是主键索引值),所以也只需要查询一次索引即可。
案例三:select id, name, gender from tb_user where name = 'Arm'
使用二级索引name,由于返回的内容中有gender,在二级索引中不包含gender,所以需要拿到主键值id,去聚集索引中查询gender的值,总共需要查询两次索引。这称为回表查询。
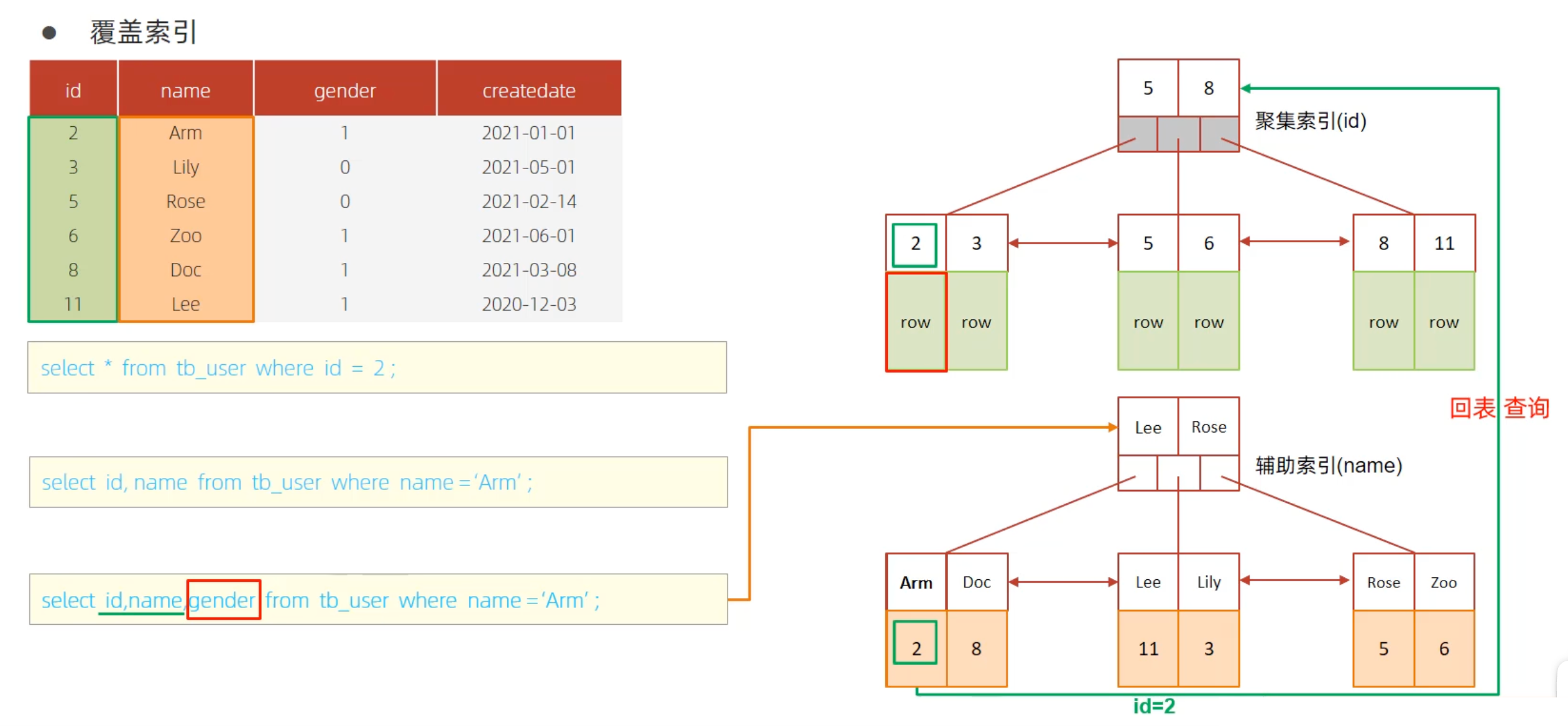
因此,在进行查询时,最好不要使用select *,避免回表查询。
7. SQL提示
当我们创建索引后,执行查询语句时,数据库系统自动帮我们使用索引查询数据,这是无感知的。但是,如果某一个查询条件涉及多个索引,而我们对数据库决策不满意时,可以在SQL中使用特定命令提示数据库,具体如下:
use index(index_name):推荐数据库使用索引index_name,例如:
sql
select * from tb_user use index(idx_user_pro)
where profession = '软件工程';ignore index(index_name):告诉数据库,不要使用索引index_name,例如:
sql
select * from tb_user ignore index(idx_user_pro)
where profession = '软件工程';force index(index_name):强制数据库使用索引index_name,例如:
sql
select * from tb_user force index(idx_user_pro)
where profession = '软件工程';8. 前缀索引
当索引字段类型为字符串(varchar、text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法如下:
sql
create index index_name on table(column(n))- n 为要选取的前缀长度
如何决定前缀长度?可以根据索引的选择性来决定,索引选择性越高则查询效率越高。如果索引选择性为1,表示性能最好。
我们可以使用如下的命令计算前缀长度:
sql
select count(distinct substring(column_name,1,n)) / count(*) from table_name;其中column_name为要创建索引的列名,是字符串类型;n为要选取的前缀长度,可以试验不同值,决定最佳的取值。
参考资料
[1] 黑马程序员MySQL视频教程:https://www.bilibili.com/video/BV1Kr4y1i7ru
[2] 数据结构与算法可视化: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
[3] MySQL 在线文档:https://dev.mysql.com/doc/refman/8.4/en/explain.html