Appearance
RabbitMQ 集群
本文介绍RabbitMQ的集群和仲裁队列。
1. 集群概念介绍
1.1 什么是集群
A RabbitMQ cluster is a logical grouping of one or more (three, five, seven, or more) nodes, each sharing users, virtual hosts, queues, streams, exchanges, bindings, runtime parameters and other distributed state.
集群(Cluster),是一个或多个节点(3个、5个、7个或更多)组成的逻辑群,每个节点分享用户、虚拟主机、队列、流、交换机、绑定关系、运行时参数等其他共享数据。
在集群中,所有节点都是平等的,所以没有所谓的主节点和从节点。
All data/state required for the operation of a RabbitMQ broker is replicated across all nodes. An exception to this are message queues, which by default reside on one node, though they are visible and reachable from all nodes. To replicate queues across nodes in a cluster, use a queue type that supports replication. This topic is covered in the Quorum Queues guide.
需要注意的是,经典的消息队列并不会在节点之间复制,但是可以访问其他节点上的消息队列。如果要在节点之间复制消息队列,请使用仲裁队列。
因此,RabbitMQ的集群是普通集群,又称为标准集群,具备下列特征:
- 在集群的各个节点间共享部分数据,包括:交换机、队列元信息。但不包含队列中的消息。
- 当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回。
- 队列所在节点如果宕机,队列中的消息就会丢失,因此普通集群只是提高了并发能力,并未实现高可用。
1.2 节点名称
在集群中,每个节点都有一个唯一的标识符,称为节点名称(Node name)。
节点名称包含两部分:前缀和主机名,例如rabbit@d2fa22a1058a,其中rabbit为前缀(并且通常情况下都是),d2fa22a1058a是主机名。
当RabbitMQ启动时,可以指定该实例的名称(就是节点名称),通过环境变量RABBITMQ_NODENAME,如果没有显式指定,那么节点会通过解析主机名,再加上rabbit前缀生成节点名称。
在集群中,节点使用节点名称来与其他节点通信,这就要求节点能解析主机名,通常有两种方式解析主机名:
- DNS
- 本地host文件(例如,
/etc/hosts)
1.3 节点认证
当节点之间可以通过节点名称的主机名连接后,需要某种方式来认证,不可能所有节点都能无条件连接上某个节点。
在RabbitMQ集群中,使用Erlang cookie来认证,在集群中的每个节点必须具有相同的Erlang cookie。Erlang cookie就是一个字符串,最多有255个字符,通常存储在本地文件中。在Unix系统中,cookie文件通常位于/var/lib/rabbitmq/.erlang.cookie。
如果cookie文件不存在,那么在RabbitMQ实例启动时,Erlang虚拟机会生成一个随机值,填充到该文件中;在Docker容器中,使用RABBITMQ_ERLANG_COOKIE环境变量来填充该文件。
2. 构建集群
本小节内容介绍如何在Docker中构建RabbitMQ集群。
2.1 启动节点
编写docker-compose.yml文件如下:
yml
name: rabbitmq_cluster
services:
# 服务名称
rabbitmq1:
# 镜像名称
image: rabbitmq:4-management
# 容器名称
container_name: mq1
# 主机名称
hostname: mq1
# 容器随着docker启动而自动启动
restart: always
# 宿主机映射到容器内的相应端口
ports:
- 5673:5672
- 15673:15672
# 配置环境变量
environment:
RABBITMQ_DEFAULT_USER: cluster_user
RABBITMQ_DEFAULT_PASS: 123456
RABBITMQ_DEFAULT_VHOST: '/'
# 配置集群的 cookie,所有节点必须一致,这个 cookie 用于节点间的认证
RABBITMQ_ERLANG_COOKIE: abcd1234
# 配置使用的桥接网络
networks:
- rabbitMqNetwork
rabbitmq2:
image: rabbitmq:4-management
container_name: mq2
hostname: mq2
restart: always
ports:
- 5674:5672
- 15674:15672
environment:
RABBITMQ_DEFAULT_USER: cluster_user
RABBITMQ_DEFAULT_PASS: 123456
RABBITMQ_DEFAULT_VHOST: '/'
RABBITMQ_ERLANG_COOKIE: abcd1234
networks:
- rabbitMqNetwork
rabbitmq3:
image: rabbitmq:4-management
container_name: mq3
hostname: mq3
restart: always
ports:
- 5675:5672
- 15675:15672
environment:
RABBITMQ_DEFAULT_USER: cluster_user
RABBITMQ_DEFAULT_PASS: 123456
RABBITMQ_DEFAULT_VHOST: '/'
RABBITMQ_ERLANG_COOKIE: abcd1234
networks:
- rabbitMqNetwork
# 创建一个桥接网络,把各个 rabbitmq 实例连接在一起
networks:
rabbitMqNetwork:
driver: bridge使用docker compose启动上面的文件,在容器日志中可以找到如下内容:
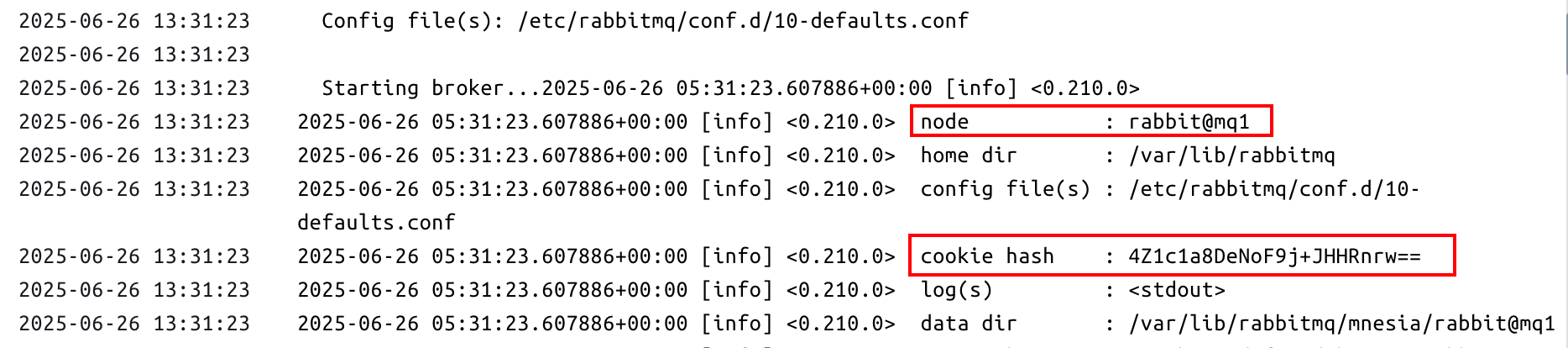
可以看到,node就表示节点名称,使用mq1主机名作为后缀。
2.2 加入集群
在mq2主机中执行以下四行命令,将mq2上的节点加入到mq1集群:
bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@mq1
rabbitmqctl start_app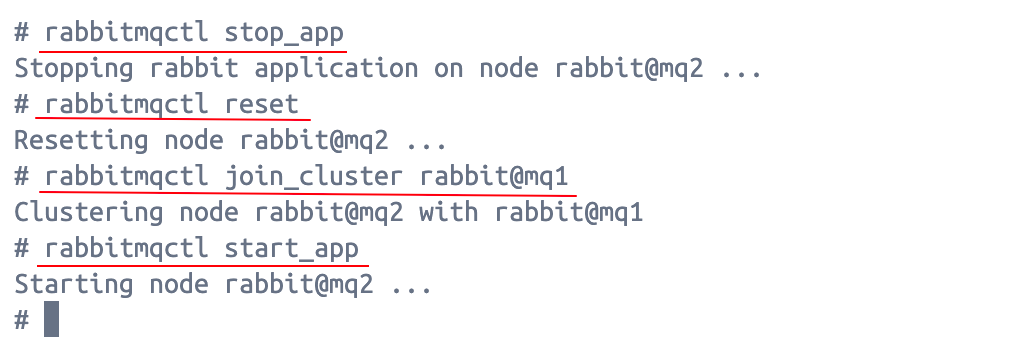
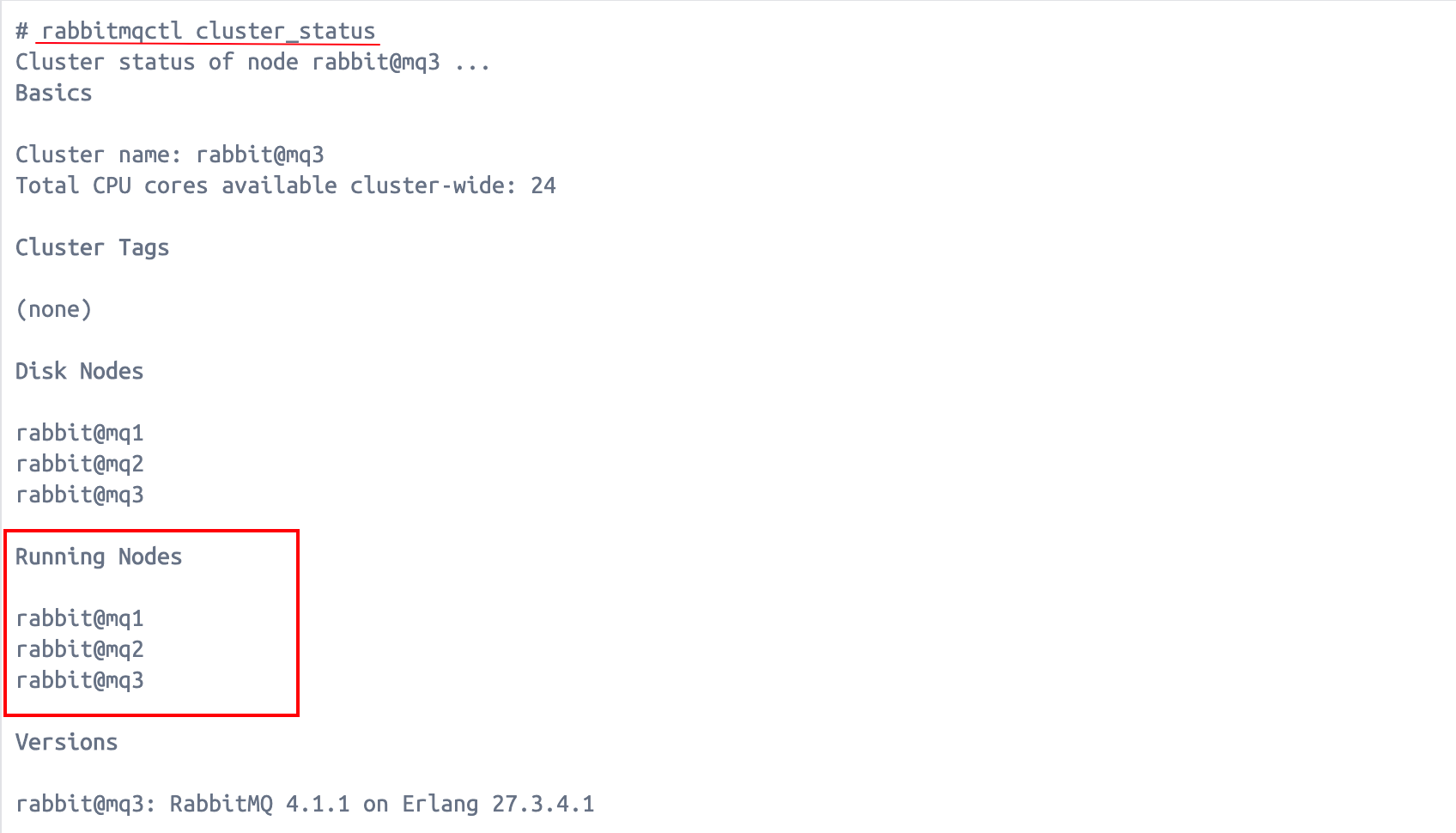
在mq1上查看集群状态:
bash
rabbitmqctl cluster_status
可以看到,目前集群中有两个节点rabbit@mq1和rabbit@mq2。
同理,在mq3中执行同样的命令,将mq3上的RabbitMQ实例加入集群:
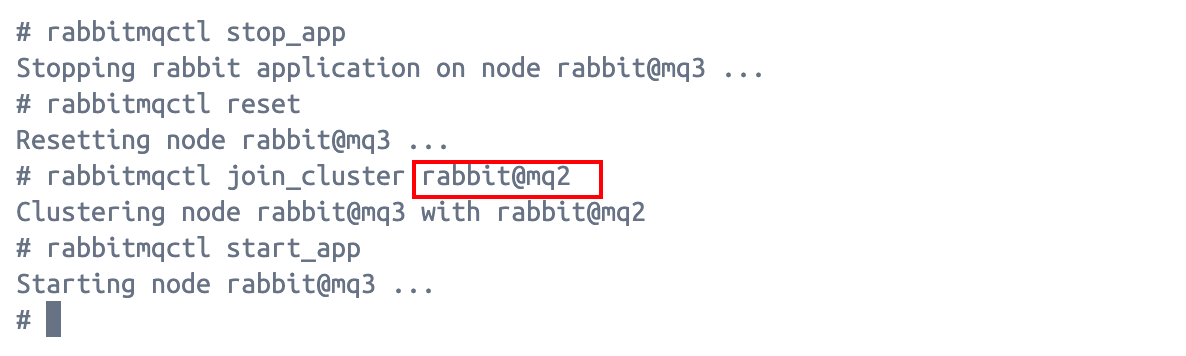
最后,我们再在管理界面上查看集群状态:
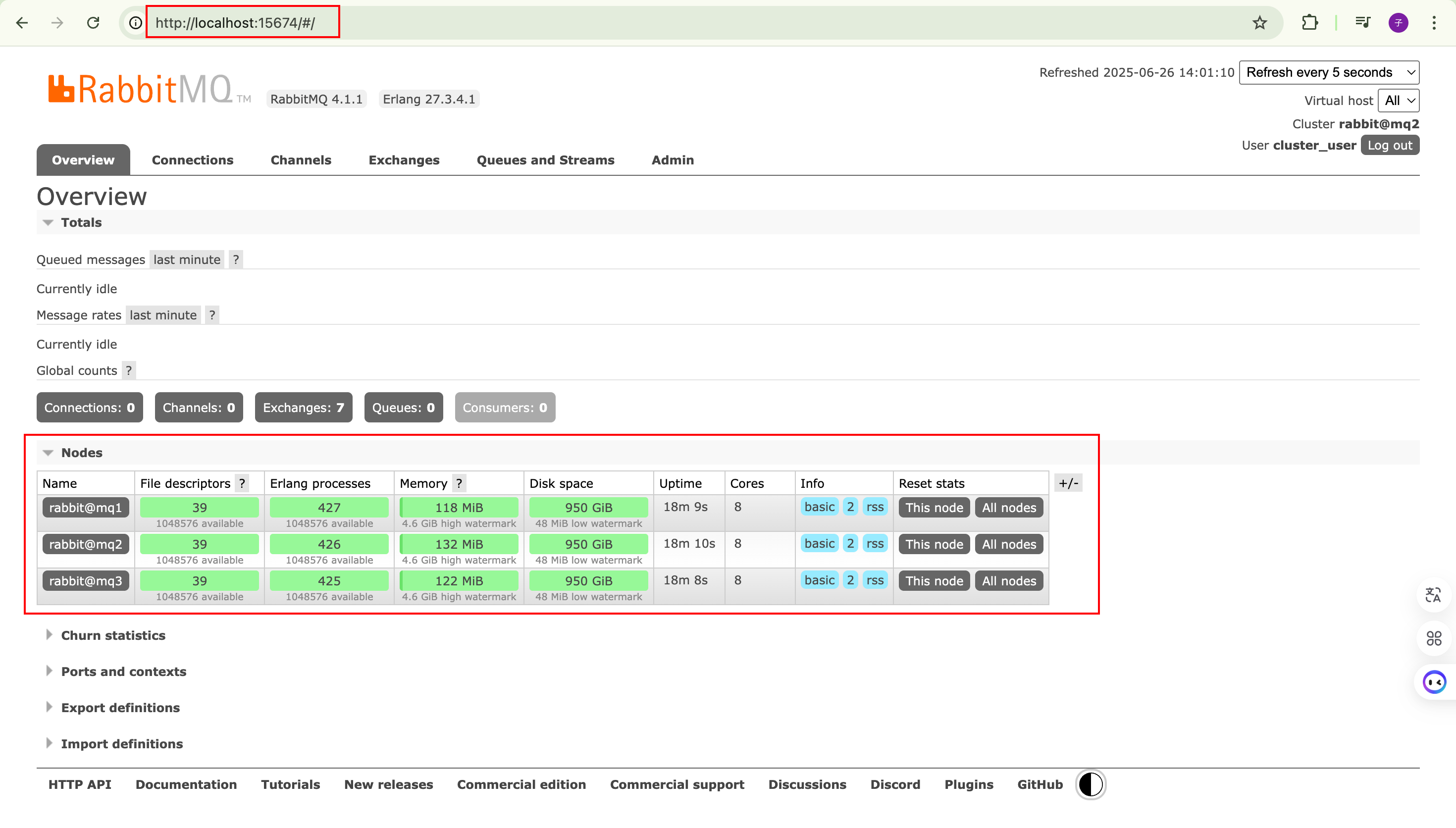
所以,集群构建完毕。
3. 使用集群
3.1 Spring Boot配置
在Spring Boot配置文件中,修改RabbitMQ的地址为集群节点地址:
properties
spring.rabbitmq.addresses=127.0.0.1:5673,127.0.0.1:5674,127.0.0.1:5675
spring.rabbitmq.username=cluster_user
spring.rabbitmq.password=123456之后,就可以正常使用了。
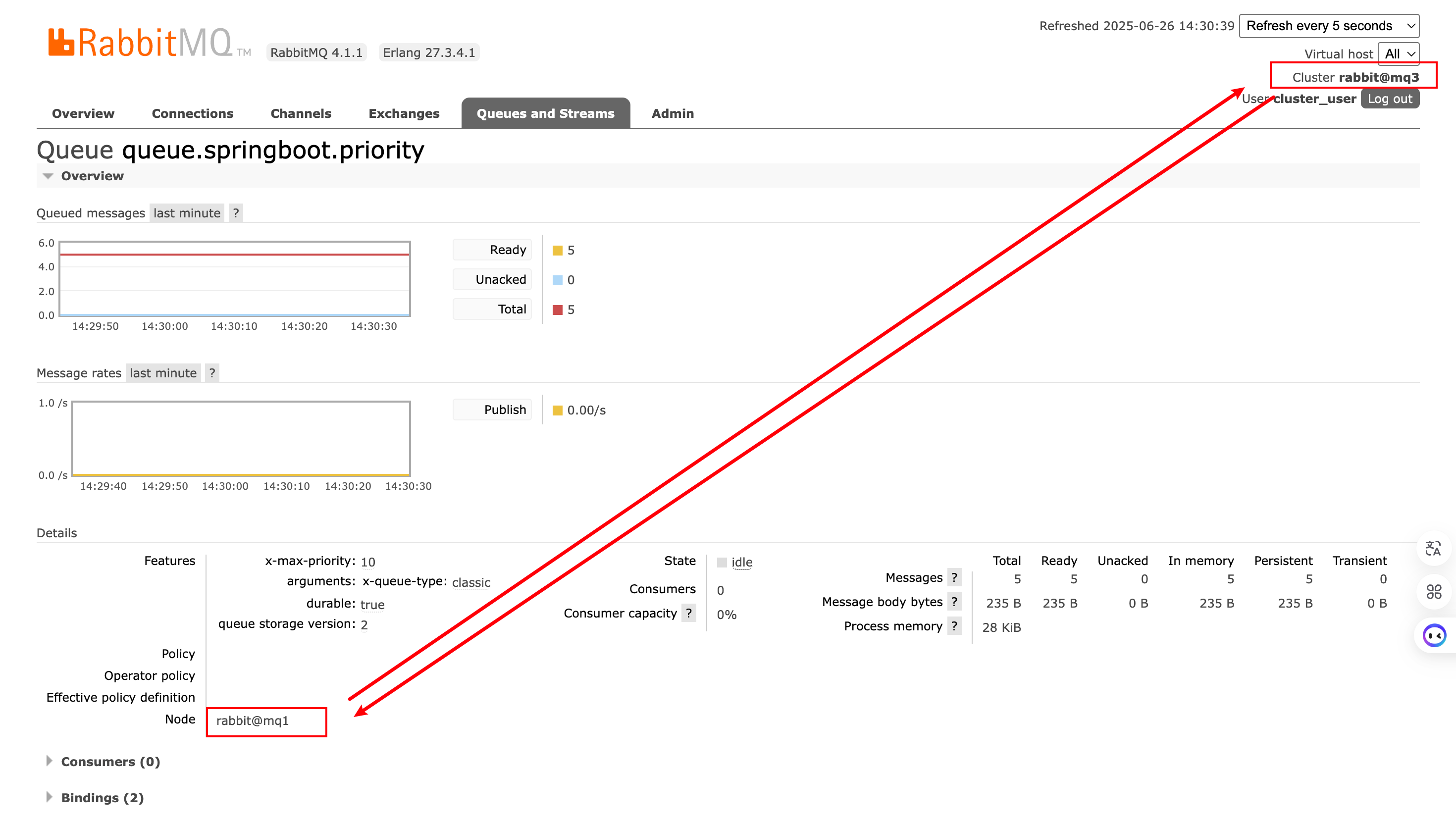
可以发现,队列queue.springboot.priority位于节点rabbit@mq1上,但是在节点rabbit@mq3也可以看到数据。
虽然在配置文件中,声明了多个RabbitMQ地址,但是SpringBoot只会连接上一个实例进行操作,如果该节点意外下线,那么Spring Boot检测到,会切换到到其他节点(有可能第一次操作API会失败,所以可以多试几次)。
3.2 主队列节点的选择
在普通集群模式下,节点的队列消息是不共享的,也就是说,队列中的消息是存放在某一个节点上的,其他节点不存放队列消息,当通过其他节点访问该队列中的消息时,其它节点只是把请求转发到队列所在的节点进行操作。
队列所在节点称为主队列节点,在RabbitMQ管理界面中创建经典队列时,可以发现有个选项,需要选择该队列存放的节点:
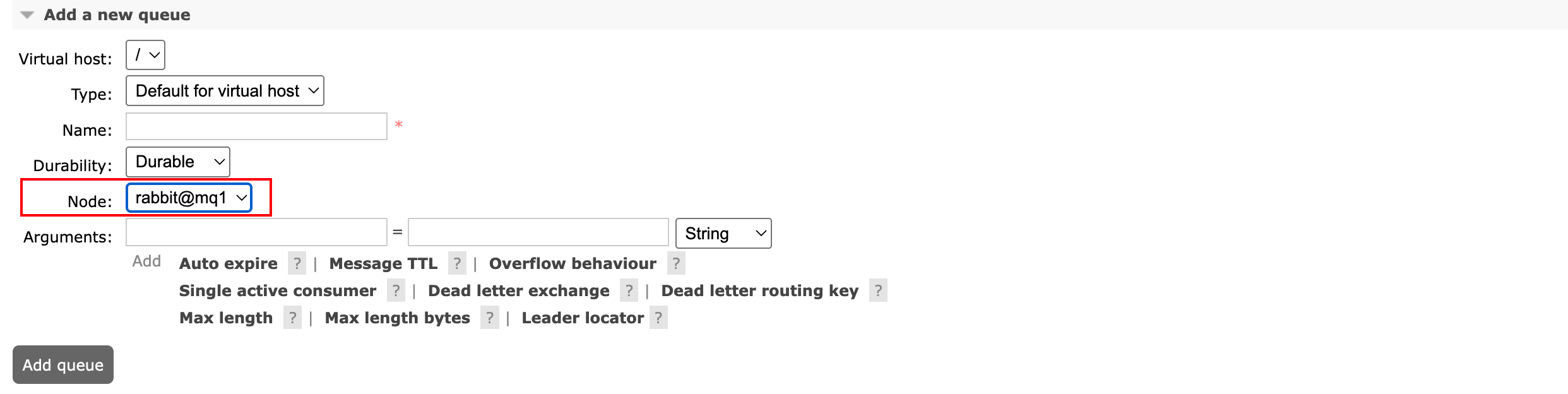
如果在SpringBoot中创建队列,需要如何指定节点呢?我们是并不能显式指定主队列节点,但有配置控制主队列节点的选择。在创建队列时,使用参数x-queue-leader-locator,这个参数有两个可选值:
client-local:默认值,表示将客户端所连接的 RabbitMQ 节点选为主队列节点;balanced:会尝试在集群中的所有可用节点上平衡队列主节点的分布,该选项可以避免单点过载,也就是说在一个节点上拥有多个队列;
例如:
java
@Bean
public Queue myClassicQueueWithLeaderLocator() {
Map<String, Object> args = new HashMap<>();
args.put("x-queue-leader-locator", "balanced");
return QueueBuilder.durable(QUEUE_NAME)
.withArguments(args)
.build();
}For backwards compatibility,
queue-master-locator(policy argument),x-queue-master-locator(queue argument) andqueue_master_locator(configuration option) are still supported by classic queues. However, these are deprecated in favour of the options listed above.These options allow different values:
client-local,randomandmin-masters. The latter two are now mapped tobalancedinternally.x-queue-master-locator 配置不再被推荐使用了。
3.3 普通集群非高可用
由于队列中的消息只保存在某个节点上,如果该节点意外下线,会导致监听该队列的消费者不可用。
例如,队列queue.springboot.priority存在于rabbit@mq1节点上,如果我们启动Spring Boot程序,然后等一会儿将rabbit@mq1所在容器关闭,最终报错如下:
DANGER
o.s.a.r.l.SimpleMessageListenerContainer : Consumer threw missing queues exception, fatal=true
并且会导致消费者停止监听,生产者也无法向队列中加入消息。
4. 移除节点
本小节介绍如何把节点移出集群。
假设现在要移除rabbit@mq3这个节点。
首先,在mq3主机上执行以下命令:
bash
rabbitmqctl stop_app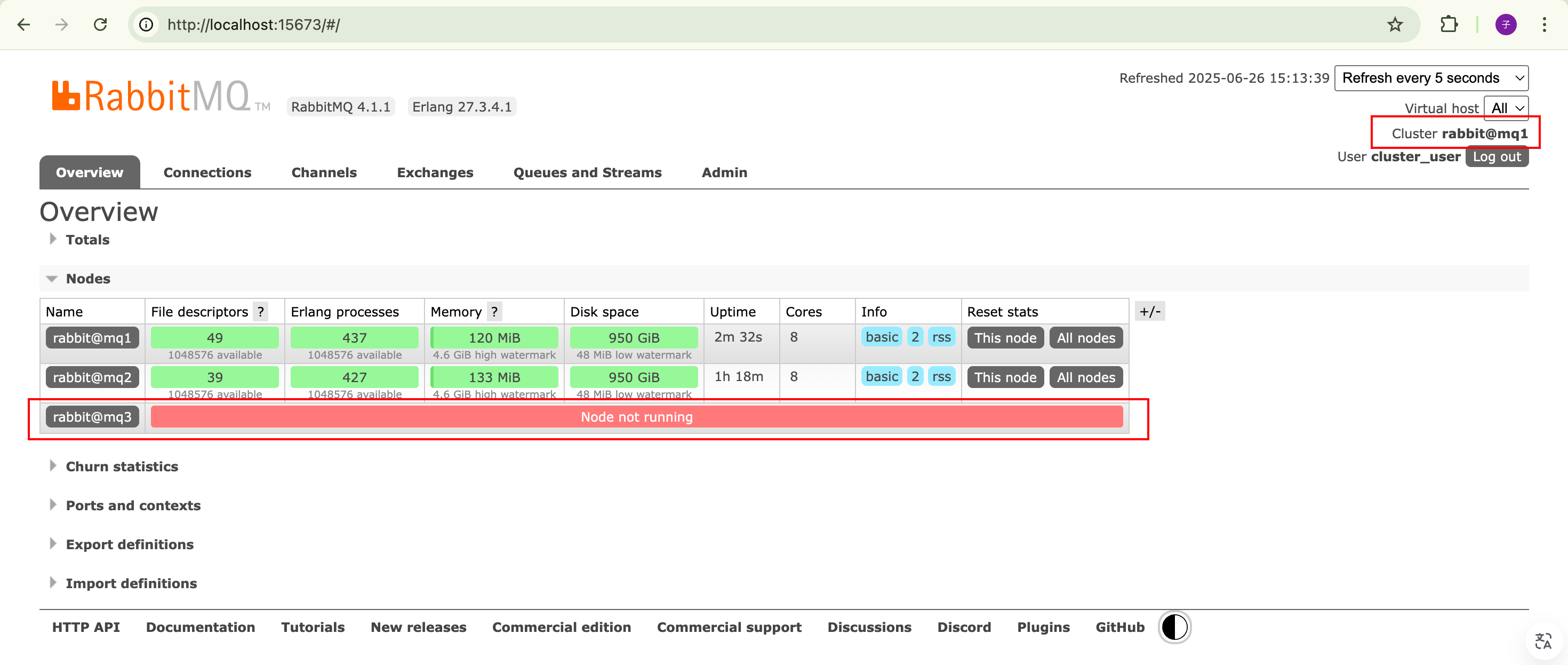
然后,在集群运行中的节点上执行以下命令,将rabbit@mq3移除集群:
bash
rabbitmqctl forget_cluster_node rabbit@mq3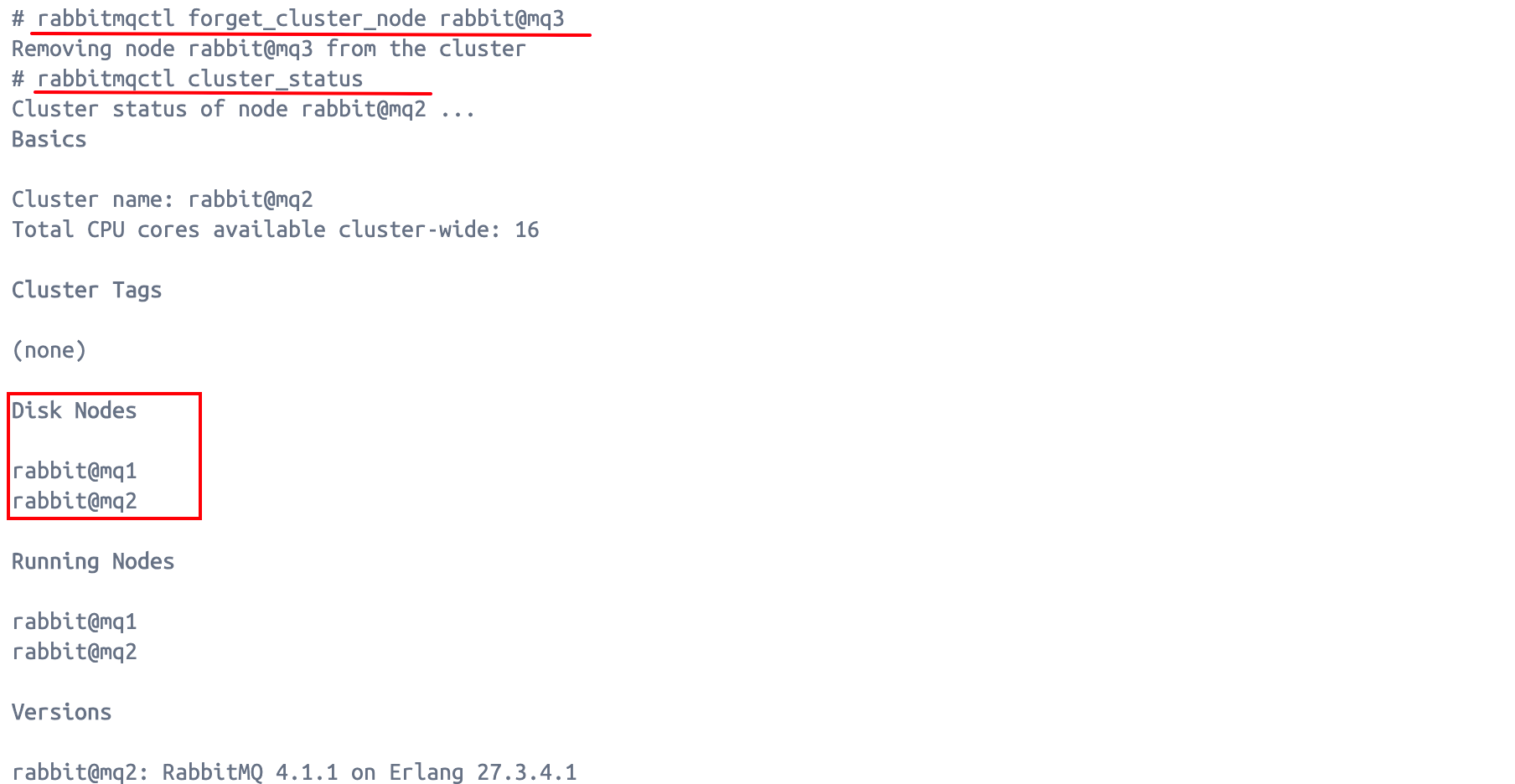
最后,在mq3主机上执行以下命令:
bash
rabbitmqctl reset
rabbitmqctl start_app那么,rabbit@mq3将会作为独立的实例运行。
5. 仲裁队列
注意,在介绍仲裁队列前,先把rabbit@mq3加入到集群中。
5.1 什么是仲裁队列
仲裁队列(Quorum Queues)是 RabbitMQ 从 3.8 版本开始引入的一种高可用、强一致性的队列类型,基于Raft算法实现,有如下特点:
Leader-Follower 架构:每个仲裁队列都有一个 Leader 副本和多个 Follower 副本。
所有的生产消息和消费消息的操作都首先通过 Leader 副本进行。Leader 负责将消息复制到 Follower 副本,并在大多数副本确认后才向客户端发送确认。
当 Leader 发生故障时,Follower 副本会参与选举,选出新的 Leader。
强一致性:仲裁队列保证了消息的顺序性,并且在大多数副本确认写入后才被认为是持久化的。这意味着即使有节点故障,也不会出现数据丢失或不一致的情况(在满足仲裁条件的前提下)。
数据持久化和同步:仲裁队列的消息是持久化的,并且在副本之间进行同步。新的 Follower 加入或 Leader 切换时,数据会进行自动同步。
总之,仲裁队列和经典队列(普通队列)相比,就是仲裁队列的消息会保存到多个集群节点上,当主节点下线后,其他节点也能提供服务,保证了高可用。
5.2 创建仲裁队列
在RabbitMQ管理界面中创建仲裁队列,只需要选择类型为Quorum即可。
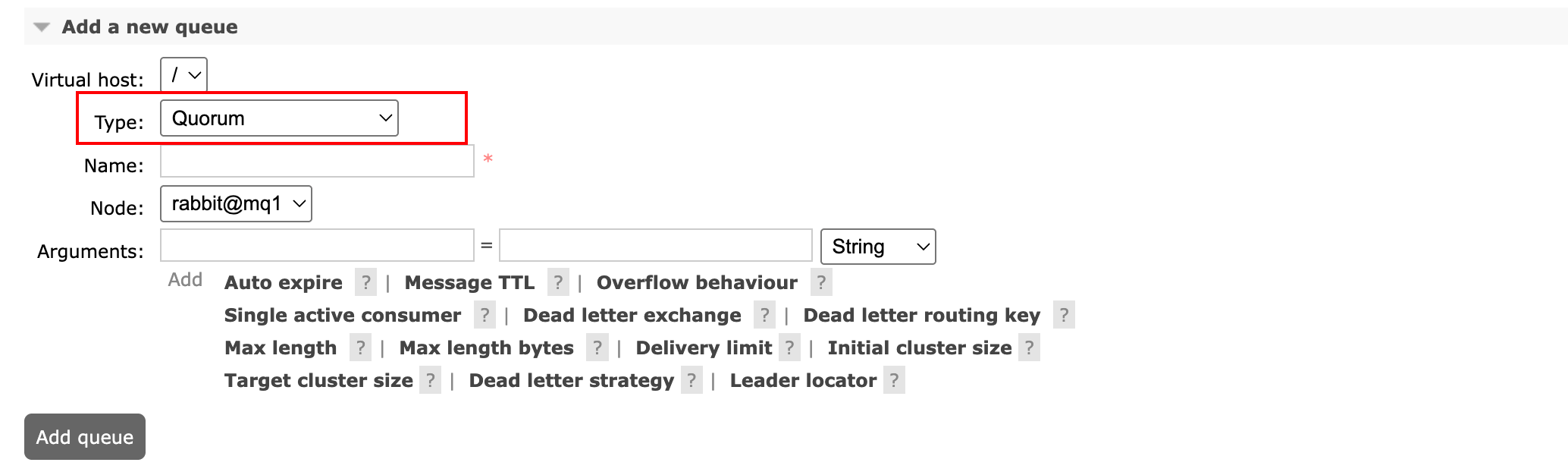
在Spring Boot中创建仲裁队列,如下:
java
public static final String QUEUE_QUORUM_TEST = "queue.quorum.test";
@Bean
public Queue testQuorumQueue(){
Map<String, Object> args = new HashMap<>();
// 队列类型设为仲裁队列
args.put("x-queue-type", "quorum");
// 指定初始仲裁组大小,也就是主队列和从队列的总数。
// 建议设置为奇数,例如 3 或 5,以确保在大多数节点投票时能够形成仲裁。
// 必须小于等于集群节点数
args.put("x-quorum-initial-group-size", 3);
// 创建队列
return new Queue(QUEUE_QUORUM_TEST, true, false, false, args);
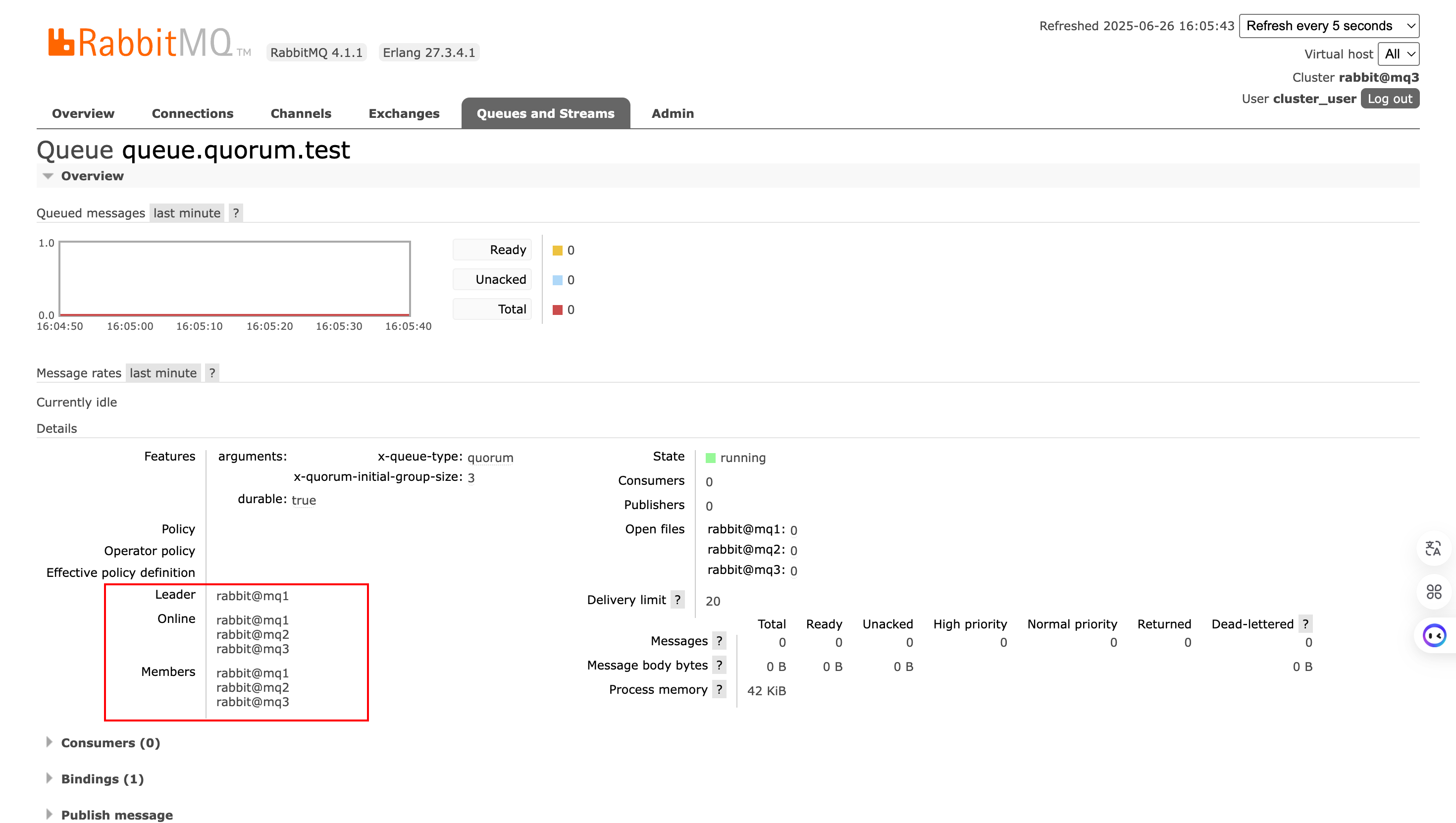
}关于x-quorum-initial-group-size,如果集群节点数为7,设置x-quorum-initial-group-size为3,那么只有3个节点有仲裁队列,其余4个节点没有。

创建完成后,在管理界面,会发现该队列类型为quorum,并且Node后面还有+2,表示有两个副本,详情如下:
5.3 使用仲裁队列
首先编写接口,直接向仲裁队列中发送消息:
java
@PostMapping("/sendQuorumMessage")
public String sendQuorumMessage(@RequestBody MQSendMessage mqSendMessage){
for (int i = 0; i < 10; i++) {
rabbitTemplate.convertAndSend(mqSendMessage.getExchange(),
LocalTime.now() + " [ " + (1+i) + " ] " + mqSendMessage.getMessage()
);
}
return "ok";
}然后消费者接受消息,每条消息处理需要耗时5秒:
java
@RabbitListener(queues = {RabbitMQConfig.QUEUE_QUORUM_TEST})
public void processMessage(Message message, Channel channel) {
// 获取消息唯一标识符
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
// 执行业务逻辑
System.out.println(Thread.currentThread().getName() + ": " + new String(message.getBody()));
Sleeper.sleep(5, TimeUnit.SECONDS);
// 业务逻辑执行完成,消息确认消费
channel.basicAck(deliveryTag, false);
}catch (Exception e){
channel.basicNack(deliveryTag, false, false);
}
}启动Spring Boot程序,发送消息:
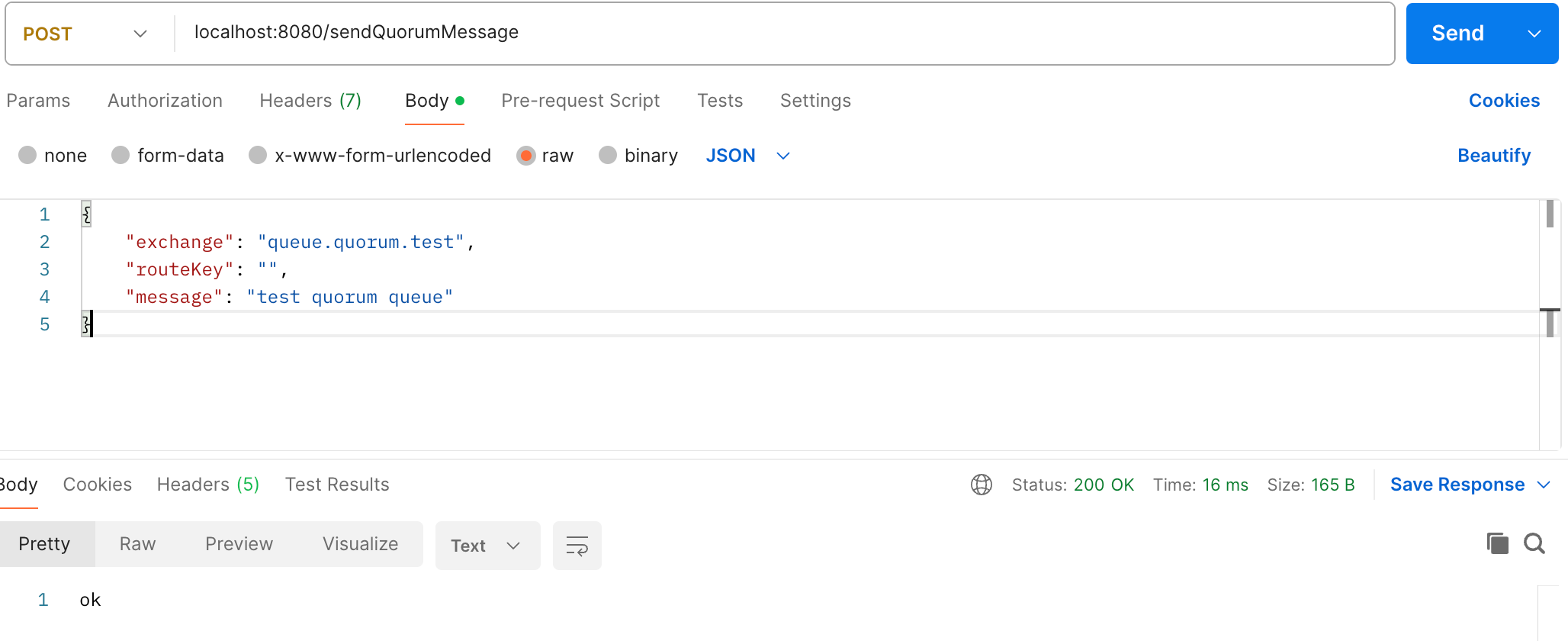
可以发现消费者正常接受消息处理。
手动关闭仲裁主队列所在节点,可以发现重新选举出了主队列节点,并且Spring Boot程序正常运行:
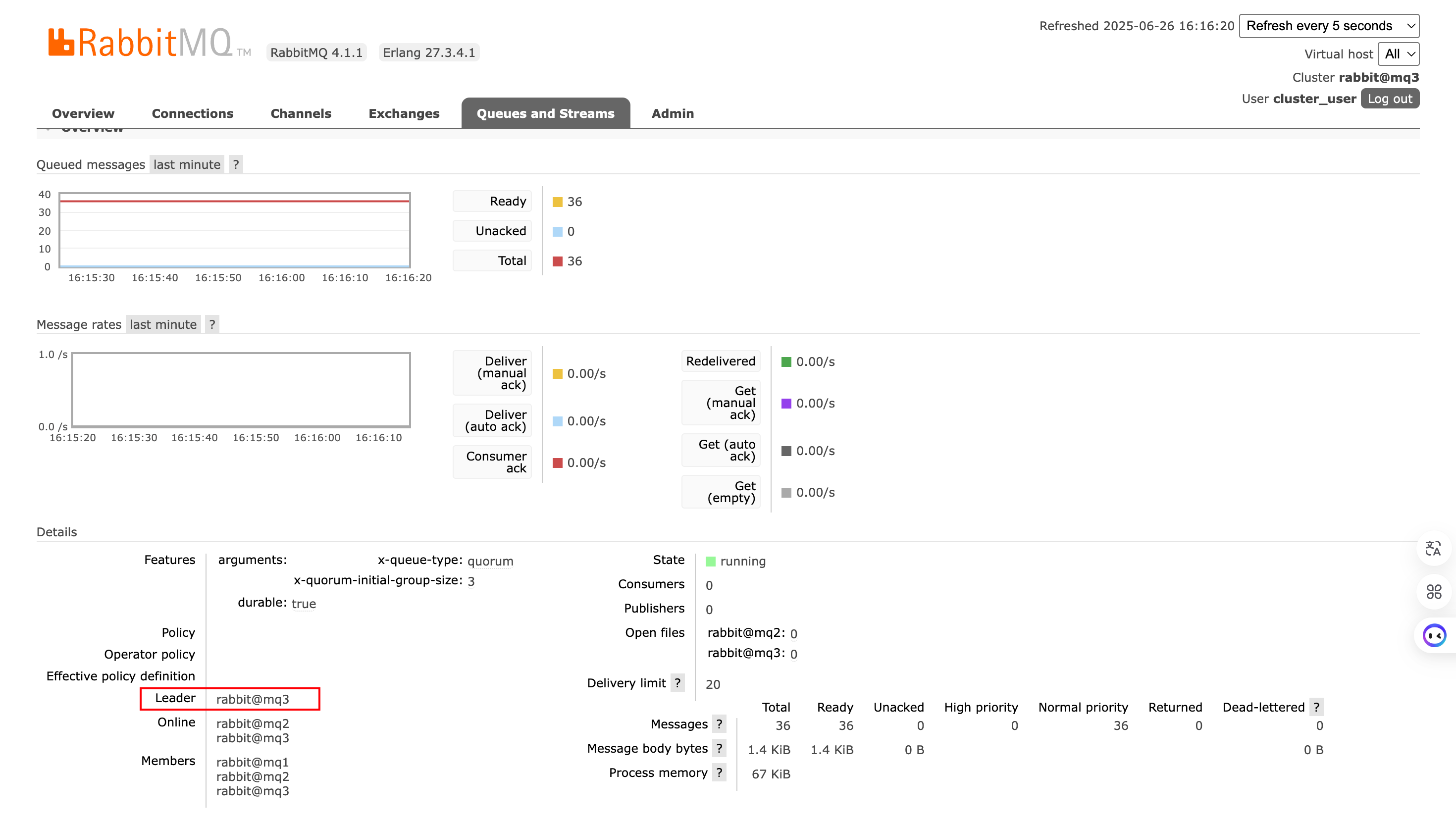
所以仲裁队列保证了高可用。
参考资料
[1] https://www.rabbitmq.com/docs/clustering