Appearance
Redis 缓存一致性问题
缓存一致性问题,是指在缓存(例如Redis)中的数据与可信数据源(例如数据库MySQL)中的数据不一致。本文主要介绍减少缓存一致性问题的方案。
1. 旁路缓存模式
旁路缓存模式,即Cache Aside,是指在读取数据时,如果缓存未命中,则从数据库读取数据,并将数据写入缓存;在写入数据时,则先更新数据库,然后删除缓存中的相应数据。
1.1 读操作
简单来说,就是读时写,读数据库时写缓存。概括流程如下:
- 先从 Redis 缓存中读取数据,如果命中,直接返回;
- 如果未命中,从数据库读取数据;
- 将读取到的数据写入 Redis 缓存,然后返回;
1.1.1 实现一:非高并发
下面是旁路缓存模式的直接实现:
java
@RestController
@Slf4j
public class StudentController {
private static final String STUDENT_PREFIX = "stu:";
@Resource
private IStudentService studentService;
@Resource
private RedisTemplate redisTemplate;
@Resource
private ObjectMapper objectMapper;
@GetMapping("/student/{id}")
public Student getStudentById(@PathVariable("id") Long id) throws JsonProcessingException {
// 1. 先查缓存
String key = STUDENT_PREFIX + id;
Object cached = redisTemplate.opsForValue().get(key);
if(cached != null){
log.info("get student from Redis, key is {}", key);
return objectMapper.readValue(objectMapper.writeValueAsString(cached), Student.class);
}
以上代码在非高并发场景下可用,在高并发场景下会有问题:如果多个请求同时查询同一个学生信息,由于缓存中没有,所以都会去查数据库,从而导致数据库压力巨大,有可能导致数据库崩溃。
1.1.2 实现二:高并发
为了防止高并发场景下,大量请求同时访问数据库导致崩溃,我们可以在访问数据库时加锁,使得一次只会有一个线程访问数据库:
java
private ReentrantLock reentrantLock = new ReentrantLock();
@GetMapping("/student/{id}")
public Student getStudentById(@PathVariable("id") Long id) {
// 1. 先查缓存
String key = STUDENT_PREFIX + id;
Student studentFromCache = getStudentFromCache(key);
if(studentFromCache != null) {
return studentFromCache;
}
// 2. 缓存中没有,查询数据库
Student student = null;
reentrantLock.lock();
try {
// 拿到锁后再次查询缓存,有可能其他线程已经查完数据库写入缓存了
studentFromCache = getStudentFromCache(key);
if(studentFromCache != null) {
return studentFromCache;
}
log.info("get student from database, id is {}", id);
student = studentService.getById(id);
// 3. 写入缓存
log.info("write Redis, key is {}, value is {}", key, student);
redisTemplate.opsForValue().set(key, student, 10, TimeUnit.MINUTES);
}finally {
reentrantLock.unlock();
}
return student;
}
private Student getStudentFromCache(String key) {
try {
Object cached = redisTemplate.opsForValue().get(key);
if(cached != null){
log.info("get student from Redis, key is {}", key);
return objectMapper.readValue(objectMapper.writeValueAsString(cached), Student.class);
}
}catch (JsonProcessingException e){
log.error(e.getMessage(), e);
}
return null;
}1.2 写操作
假设现在缓存和数据库中的数据一致,ID为1的学生数据如下:
txt
{"id":1,"name":"张三","phone":"18921002100","birth":"2000-01-12","address":"上海"}现在要修改学生的地址,需要同时修改数据库和缓存,存在以下策略:
- 先修改数据库,再修改缓存;
- 先修改缓存,再修改数据库;
- 先删除缓存,再修改数据库;
- 先修改数据库,再删除缓存;
总结而言,就是写时写,写数据库时写缓存。
以上策略均有其不足之处,综合比较而言,第四种方案是比较好的:先修改数据库,再删除缓存。所以旁路缓存模式采用的就是第四种方案。
1.2.1 实现
最简单的实现如下:
java
@PutMapping("/student")
public boolean updateStudent(@RequestBody Student student){
// 1. 更新数据库
boolean updated = studentService.updateById(student);
if(updated){
// 2. 更新数据库成功,删除缓存
String key = STUDENT_PREFIX + student.getId();
redisTemplate.delete(key);
}
return updated;
}1.2.2 延迟双删
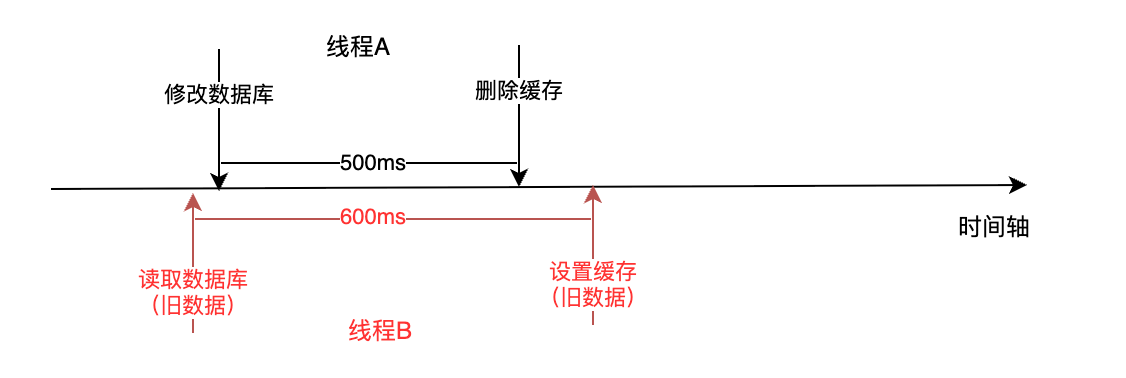
在高并发下,先修改数据库,再删除缓存的策略,极端情况下存在以下问题:
- 由于业务复杂,在更新数据库和删除缓存中间存在着500ms的延迟,用来处理其他业务;在读取数据库和设置缓存间存在600ms的延迟;
- 首先线程B来读取数据,此时发现缓存中没有数据,所以会先查数据库,然后执行其他业务;
- 然后很短的时间间隔(假设只有几毫秒),线程A执行修改数据库的业务,执行其他业务,然后删除缓存;
- 线程B执行完其他业务后,将读取到的数据写入缓存,但是注意,此时写入的是旧数据;
- 此后一段时间内(假如10分钟),由于缓存没有过期,之后的请求读取到的数据都是旧数据;
- 这就造成了缓存不一致问题。流程示意图如下:
要减轻上述问题,可以采用延迟双删策略:
更新数据库。
删除 Redis 缓存。
等待一小段时间(例如几百毫秒),再次删除 Redis 缓存。 这样可以确保在读操作将旧数据写入缓存之后,再次删除缓存,降低脏读概率。
java
@PutMapping("/student")
public boolean updateStudent(@RequestBody Student student){
// 1. 更新数据库
boolean updated = studentService.updateById(student);
if(updated){
// 2. 更新数据库成功,删除缓存
String key = STUDENT_PREFIX + student.getId();
redisTemplate.delete(key);
// 3. 延迟双删
CompletableFuture.runAsync(()->{
Sleeper.sleep(600, TimeUnit.MILLISECONDS);
});
}
return updated;
}示意图如下:
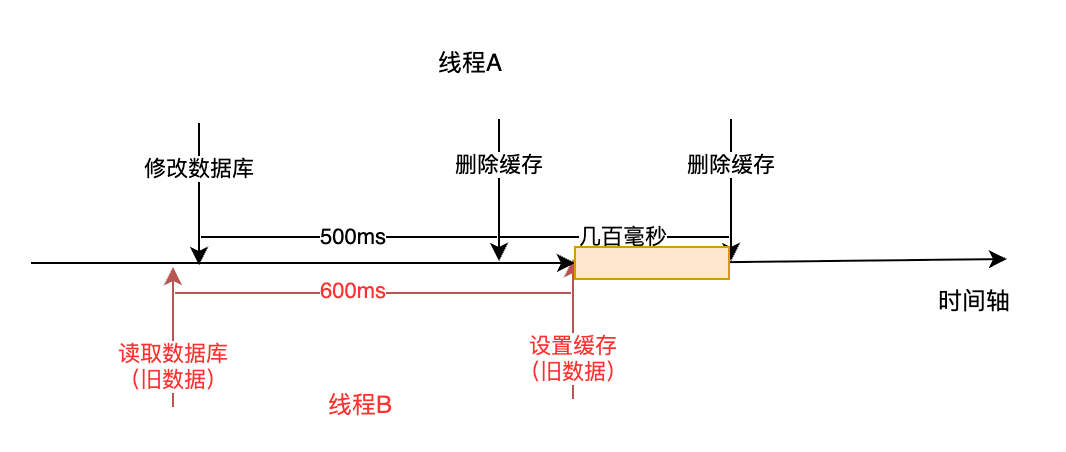
延迟双删减少了旧数据在缓存中存在的时间(图中橙色矩形时间段),最多只有几百毫秒,因此影响不大。
延迟双删存在的问题如下:
- 不太好确定到底要延迟多长时间执行第二次删除操作,最好的时间是读操作间隔时间(600ms)减去写操作间隔时间(500ms),这样会将旧数据停留时间减至最小,但由于网络波动等原因,无法精确得出;
- 会涉及两次删除缓存操作,性能略低;
1.2.3 其他策略讨论
现在我们来讨论其他三种方案存在的问题。
先修改数据库,再修改缓存
假设现在有两个线程A和B,同时执行该操作,顺序如下:
- 线程A修改数据库,由于时间片用完,切换;
- 线程B开始运行,修改数据库;
- 线程B继续运行,修改缓存;
- 最后线程A修改缓存;
以上顺序的问题是,线程A是先运行的,代表旧数据,线程B是后运行的,代表新数据,此时数据库中是新数据,缓存中是旧数据,存在缓存一致性问题。
先修改缓存,再修改数据库
同理,假设现在有两个线程A和B,同时执行该操作,顺序如下:
- 线程A修改缓存,然后切换;
- 线程B开始运行,修改缓存;
- 线程B继续运行,修改数据库;
- 线程A运行,修改数据库;
这种顺序会造成数据库中,旧数据覆盖新数据,问题更大。
先删除缓存,再修改数据库
假设现在有两个线程A和B,执行的操作不同,线程A是执行写操作,线程B是执行读操作,顺序如下:
- 线程A先删除缓存,然后切换;
- 线程B开始执行读操作,此时缓存中没有数据,先查数据库;
- 然后线程B将数据(旧)写入缓存;
- 最后线程A修改数据库;
这种顺序造成的问题仍然是缓存中保留有旧数据,并且相比于先修改数据库再删除缓存的顺序,旧数据被保留在缓存中的可能性更大。
2. 其他策略
除了旁路缓存模式,还有其他方法解决缓存一致性问题。
2.1 读穿透
与 Cache Aside 类似,但缓存逻辑由缓存框架(或 Redis 客户端库)内置或封装。应用程序只管从缓存中读,无需关心缓存的加载逻辑。
读操作:
- 应用程序向缓存发出读请求。
- 如果缓存命中,直接返回。
- 如果未命中,缓存框架会自动从底层数据源(数据库)加载数据,写入缓存,然后返回。
写操作: 通常配合 写穿透(Write Through)或写回(Write Back)。
2.2 写穿透
写入数据时,同时更新缓存和数据库,确保数据一致性。
写操作:
- 应用程序向缓存发出写请求。
- 缓存框架同步地将数据写入缓存和数据库。
优点: 强一致性,写入后缓存和数据库数据一致。
缺点: 写性能较差,因为需要同步写数据库和缓存。
2.3 写回
写入数据时,只更新缓存,不立即更新数据库。数据库的更新是异步进行的。
写操作:
- 应用程序向缓存发出写请求。
- 数据只写入缓存。
- 缓存中的数据被标记为“脏”(Dirty)。
- 后台进程或在特定时机(如缓存淘汰、数据过期或主动刷新)将脏数据批量或异步地写回数据库。
优点: 写性能高,因为是非同步写入数据库。
缺点: 数据一致性风险最高。如果缓存服务(Redis)宕机,未写回数据库的数据可能会丢失。需要有复杂的机制来保证数据不丢失(例如,AOF 持久化,或者在 Redis 前面增加消息队列)。
2.4 Polaris
Facebook (现在是 Meta) 的 Polaris 并不是一个普通的缓存系统,而是一个用于检测和诊断大规模分布式缓存系统中缓存不一致性的可观测性解决方案(Observability Solution)。
Polaris 的核心思想是将缓存一致性问题从一个被动解决的问题转变为一个主动监控和诊断的问题。它通过以下几个关键方面实现这一目标:
- 主动检测不一致性:
- Polaris 不仅等待用户报告问题,而是主动监控缓存和底层数据源之间的数据差异。
- 它会周期性地对缓存中的数据进行采样,并与数据库中的“真实”数据进行比对,以识别不一致的条目。
- 根因分析 (Root Cause Analysis):
- 一旦检测到不一致,Polaris 不仅仅是报告存在问题,更重要的是它会尝试找出问题发生的原因。
- 它利用**分布式追踪(Distributed Tracing)**技术。当数据在系统中流动时(例如,从数据库读取、写入缓存、缓存失效等),Polaris 会记录下关键操作的日志和时间戳。
- 通过分析这些追踪数据,Polaris 可以重建事件序列,找出导致缓存不一致的具体操作(例如,是缓存失效失败、数据库更新未触发缓存更新、还是某个操作的时序问题)。
- 可伸缩性:
- Meta 的系统规模巨大,Polaris 必须能够处理海量的缓存数据和请求。
- 它采用了高效的数据采集、存储和分析技术,以确保在大规模环境下仍然能够有效运行。
- 提供洞察力:
- Polaris 提供了仪表板和工具,让工程师可以清晰地看到缓存一致性的状态,包括不一致的比例、发生不一致的模式、以及潜在的根因。
- 这有助于工程师优化缓存策略、修复代码中的 Bug,从而提高整个系统的可靠性。
传统的缓存一致性解决方案(如 Cache Aside、Write Through)主要关注如何避免不一致的发生。但 Polaris 则是在承认不一致性可能无法完全避免的情况下,提供了一套强大的工具来快速检测、诊断和修复这些不一致。这是一种从“预防为主”到“预防与事后快速处理并重”的思维转变。
参考文章:https://engineering.fb.com/2022/06/08/core-infra/cache-made-consistent/
3. Canal使用
Canal 是阿里开源的一款 MySQL 数据库增量日志解析工具,提供增量数据订阅和消费。
此处使用Canal,可以订阅可信数据源数据变动,从而删除缓存中的数据。
3.1 Canal原理
Canal的原理就是模仿MySQL主从复制,将自己伪装成一个MySQL从节点:
- Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 Canal )
- Canal 解析 binary log 对象(原始为 byte 流)
3.2 安装Canal
3.2.1 MySQL主节点设置
需要先开启MySQL的 binlog 写入功能,配置 binlog-format 为 ROW 模式,具体my.cnf 中配置如下:
txt
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复修改配置文件之后,重启MySQL。
使用命令查看是否打开binlog模式,如输出以下内容则说明binlog已开启。
sql
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+查看binlog_format配置是否正确。
txt
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+添加授权
Canal的原理是模拟自己为MySQL slave,所以一定要为账号授予做为MySQL slave的相关权限。
下面的命令是先创建一个名为canal的账号,再对其进行授权,如果已有账户可直接 grant。
sql
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;3.2.2 Canal-Server启动
这里使用Docker启动Canal。
执行以下命令,拉取canal-server最新镜像(这里是1.1.8版本)。
bash
docker pull canal/canal-server:latest启动容器。
bash
docker run -d --name canal-server -p 11111:11111 canal/canal-server进入容器。
bash
docker exec -it canal-server /bin/bash修改主配置。
bash
vi /home/admin/canal-server/conf/canal.properties主配置项关注如下内容:
properties
#################################################
######### destinations #############
#################################################
canal.destinations = example之后再修改example实例的配置:
bash
vi /home/admin/canal-server/conf/example/instance.properties具体的配置项如下:
properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=host.docker.internal:3316
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
canal.instance.tsdb.dbUsername=canal
canal.instance.tsdb.dbPassword=canal将
canal.instance.master.address修改为MySQL主节点地址。注意:如果是macOS平台容器内使用host.docker.internal表示
localhost。即:
canal.instance.master.address=host.docker.internal:3306将
canal.instance.tsdb.dbUsername修改为MySQL授权的账号,即canal。将
canal.instance.tsdb.dbPassword修改为授权账号的密码。
修改完成后,重启canal-server:
bash
cd /home/admin/canal-server/bin
sh restart.sh3.3 编写Canal客户端代码
参考https://github.com/alibaba/canal/wiki/ClientExample,引入Canal依赖,编写客户端代码。
首先引入依赖:
xml
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>然后编写客户端代码:
java
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
public class CanalSample {
public static void main(String args[]) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}- 注意,Canal客户端监听的是Canal服务端,所以IP和Port是Cana- server的地址,即127.0.0.1:11111;
CanalConnectors.newSingleConnector中第二个参数表示监听的地址,要在canal.properties中有才行,此处为example;connector.subscribe(".*\\..*");表示监听全库全表,此处做演示可不用修改,在实际使用中,需监听指定表的写操作;
3.4 启动Canal客户端
首先启动Canal客户端,然后在MySQL 主节点上执行修改操作,Canal客户端结果如下:
txt
empty count : 21
empty count : 22
empty count : 23
================> binlog[mysql-bin.000001:417] , name[student_management,student] , eventType : UPDATE
-------> before
id : 1 update=false
name : 张三 update=false
phone : 18921002100 update=false
birth : 2000-01-12 update=false
address : 深圳 update=false
-------> after
id : 1 update=false
name : zs1 update=true
phone : 18921002100 update=false
birth : 2000-01-12 update=false
address : 深圳 update=false
empty count : 1
empty count : 2
empty count : 3
empty count : 4可以看到客户端成功监听到修改操作了。
3.5 监听之后删除缓存
当客户端监听到MySQL中数据发生变动后,可以编写代码对缓存中的数据进行删除操作,这样,业务代码在操作数据库时,不用再重复编写代码删除缓存了。
java
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import jakarta.annotation.Resource;
import org.example.studentmanagement.common.RedisKeyPrefix;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
@Component
public class CanalSubscriber {
@Resource
private RedisTemplate redisTemplate;
public void begin() {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
} finally {
connector.disconnect();
}
}
private void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
deleteCache(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
deleteCache(rowData.getBeforeColumnsList());
}
}
}
}
private void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
private void deleteCache(List<Column> columns){
Column column = columns.get(0);
String id = column.getValue();
java
@SpringBootApplication
@MapperScan("org.example.studentmanagement.mapper")
public class StudentManagementApplication {
public static void main(String[] args) {
ConfigurableApplicationContext ioc = SpringApplication.run(StudentManagementApplication.class, args);
CanalSubscriber canalSubscriber = ioc.getBean(CanalSubscriber.class);
java
@RestController
@Slf4j
public class StudentController {
@Resource
private IStudentService studentService;
@PutMapping("/student")
public boolean updateStudent(@RequestBody Student student){
boolean updated = studentService.updateById(student);
// 不用再删除缓存了
return updated;
}
}java
public enum RedisKeyPrefix {
STUDENT_PREFIX("stu:");
private String value;
RedisKeyPrefix(String value){
this.value = value;
}
public String getValue(){
return value;
}
}如果删除缓存失败,还可以将消息推送进消息队列,确保删除成功。Canal 1.1.1版本之后,默认支持将Canal Server接收到的binlog数据直接投递到MQ,目前默认支持的MQ系统有Kafka、RocketMQ、RabbitMQ、PulsarMQ。
参考资料:
[1] https://www.bilibili.com/video/BV13R4y1v7sP