Appearance
Redis 集群
本文主要介绍Redis中的集群。
1. 背景介绍与集群概念
在之前的主从模式和哨兵模式中,所有的数据都存储在单个主节点上,但是,在现代互联网应用中,越来越多的数据要存在Redis中,如果仍然使用单主节点,势必会出现问题。
为了解决大规模数据存储和高并发写入的需求,Redis 推出了集群模式。集群将数据分散到多个节点中,实现了数据的分片 (sharding) 和横向扩展,同时内建了高可用性机制。
也就是说,Redis集群包含多个主节点,每个主节点可读可写,只负责存储一部分数据,并且每个主节点都可以有自己的从节点进行数据复制和备份。
2. 哈希槽
Redis集群将数据空间划分为 16384 个哈希槽 (hash slots)。每个 key 通过 CRC16 算法计算出哈希值,然后对 16384 取模,得到对应的哈希槽。每个主节点负责管理一部分哈希槽,从而实现了数据的自动分片。
txt
HASH_SLOT = CRC16(key) mod 16384例如,使用以下命令,可以查看对应的key应处于哪个哈希槽:
txt
CLUSTER KEYSLOT k1结果为:12706,表示k1这个键值对应该存放在序号为12706这个哈希槽中。
注意,要使用
CLUSTER命令,需要在redis.conf先开启以下配置:txtcluster-enabled yes
**为什么使用16384
- 心跳包大小的考量:
- Redis 集群节点之间通过心跳包(ping/pong 消息)来交换集群配置信息,其中包含了每个节点负责的哈希槽位信息。
- 这些槽位信息是以位图(bitmap)的形式存储的。如果使用 65536 个槽,那么表示槽位的位图大小将是 65536 / 8 = 8KB。而使用 16384 个槽,位图大小为 16384 / 8 = 2KB。
- Redis 节点需要每秒发送一定数量的 ping 消息作为心跳包。如果心跳包过大(例如 8KB),会显著增加网络带宽消耗,尤其是在节点数量较多时,容易造成网络拥堵。2KB 的心跳包大小在带宽和信息传输效率之间达到了较好的平衡。
- 集群规模的限制:
- Redis 的作者 Antirez 认为,Redis 集群的主节点数量基本不可能超过 1000 个。
- 如果节点数量过多,心跳包中携带的其他节点信息也会增多,进一步加重心跳包的负担,导致网络拥堵。
- 对于 1000 个主节点以下的集群,16384 个槽位已经足够满足需求,并能保证每个节点分到的槽位数量不会太少,从而保证数据分布的均匀性。没有必要扩展到 65536 个。
- 位图压缩率和传输效率:
- Redis 主节点的配置信息中,它所负责的哈希槽是通过位图形式保存的。在传输过程中,会对位图进行压缩。
- 但是,如果位图的填充率(即
slots/N,N 为节点数)很高,或者节点数很少但哈希槽数量很多时,位图的压缩率反而会很低。 - 16384 这个数量,在大多数实际部署场景下,能保证位图在传输时的压缩率相对较好,减少传输的数据量。
3. 集群实践
3.1 启动6个Redis实例
在Docker中启动6个Redis实例,为搭建3主3从Redis集群做准备。每个Redis实例的配置文件都相同:
txt
port 6379
dir /data/
logfile "redis.log"
requirepass 123456
masterauth 123456
appendonly yes
protected-mode yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000WARNING
注意,在Docker容器中,不能以后台模式启动Redis,即不能配置daemonize yes。
cluster-enabled yes:开启Redis实例的集群模式;cluster-config-file nodes.conf:集群配置文件名,不需要自己创建,Redis会自动创建,只需要指定名称即可。它记录了当前节点在集群中的状态、它负责的哈希槽位、集群中其他节点的信息(ID、IP、端口、角色、状态等)以及集群的纪元(epoch)信息。cluster-node-timeout 5000:定义了 Redis 集群中节点超时的时间(毫秒)。如果一个节点在cluster-node-timeout指定的时间内没有收到来自某个节点的心跳包响应,它就会认为这个节点可能已经失败了(处于PFAIL状态,即 Possible Fail)。如果集群中超过半数的主节点都认为某个节点失败,并且这个节点是主节点,那么集群就会触发故障转移(Failover)过程,尝试将它的某个从节点晋升为新的主节点。
然后使用类似如下的命令启动Redis容器:
txt
docker run --name redis6380 -p 6380:6379 --network redis-net -v /projects/docker/redis6380/conf:/usr/local/etc/redis -v /projects/docker/redis6380/data:/data -d redis:7.4.4 redis-server /usr/local/etc/redis/redis.conf
3.2 创建集群
使用如下命令,进入其中一台Redis容器环境:
bash
docker exec -it redis6380 /bin/sh然后,在容器命令行中运行如下命令:
bash
redis-cli -a 123456 --cluster create redis6380:6379 redis6381:6379 redis6382:6379 redis6383:6379 redis6384:6379 redis6385:6379 --cluster-replicas 1上面的命令就是创建集群的命令:
--cluster-replicas 1:表示为集群中的每个主节点添加一个从节点;redis6380:6379:这些表示要加入集群的Redis实例地址,格式为<host>:<port>;
结果如下:
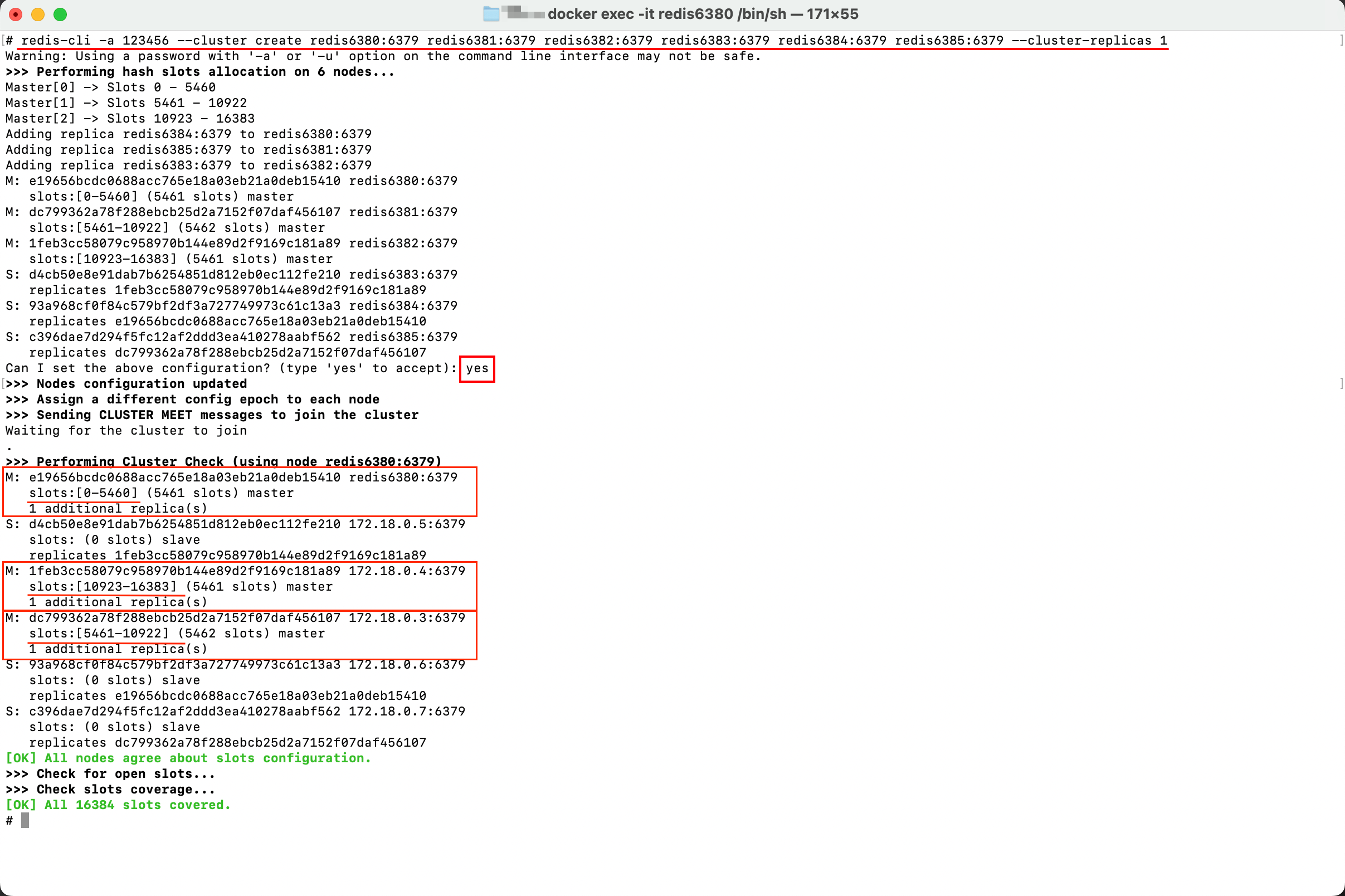
从集群的创建信息中,可以看出:
- redis6380:6379这个节点作为主节点,负责0-5460这5461个哈希槽;
- 172.18.0.3:6379这个节点作为主节点,负责5461-10922这5462个哈希槽;
- 172.18.0.4:6379这个节点作为主节点,负责10923-16383这5461个哈希槽;
- 另外三个Redis节点作为从节点,跟随其中一个主节点,可以通过Node ID找到从属关系;
3.3 查看集群状态
首先使用redis-cli连上集群中的一台主节点(这里以redis6380为例):
bash
redis-cli -a 123456 -c-c:表示以集群模式打开redis-cli;
然后在Redis命令行中输入以下命令,查看集群信息:
txt
cluster info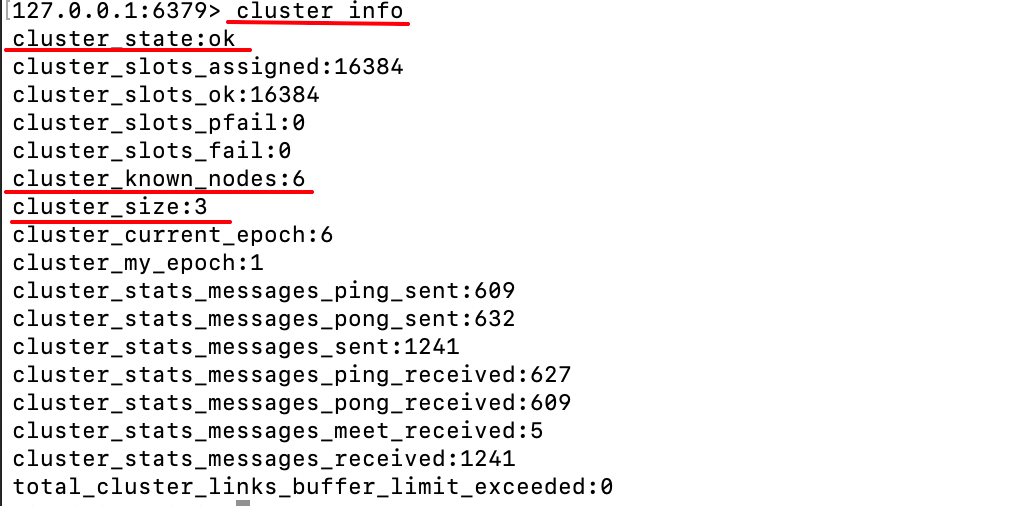
cluster_known_nodes:集群中的所有节点数量,包括主从节点;cluster_size:集群中的主节点数量;
也可以使用如下命令,查看集群节点信息以及主从复制关系:
txt
cluster nodes
结果格式如下:
txt
<id> <ip:port@cport[,hostname]> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>也可以通过如下命令,查看当前登录节点的ID:
txt
cluster myid
3.4 读写数据
在redis-cli中读写数据,会发现先计算key所在的哈希槽,然后重定位到哈希槽所对应的节点:


4. 主节点下线
本小节模拟主节点下线,集群自动故障恢复的场景。
4.1 主节点下线
通过上面的配置信息得知,redis6382是主节点,并且redis6383是其从节点。
我们手动关闭redis6382容器,模拟主节点下线情况。
再次查看集群节点信息,发现redis6383已经上位成为主节点了,并且redis6382的状态为fail:

4.2 原主节点重新上线
重新启动redis6382,查看集群节点信息:

可以看到,原主节点变为了从节点。
5. 集群扩容与缩容
5.1 扩容
首先我们准备一个新的Redis实例redis6386,作为要加入集群的节点:

然后,在redis6386容器的命令行中运行如下命令:
bash
redis-cli -a 123456 --cluster add-node redis6386:6379 redis6380:6379该命令格式为:redis-cli --cluster add-node <new_node_address> <existing_node_address>
--cluster add-node:向集群中加入新节点;<new_node_address>:新节点地址;<existing_node_address>:集群中任意已存在的一个节点地址;
上面的命令表示将redis6386:6379这个实例加到redis6380:6379这个实例所在的集群中。
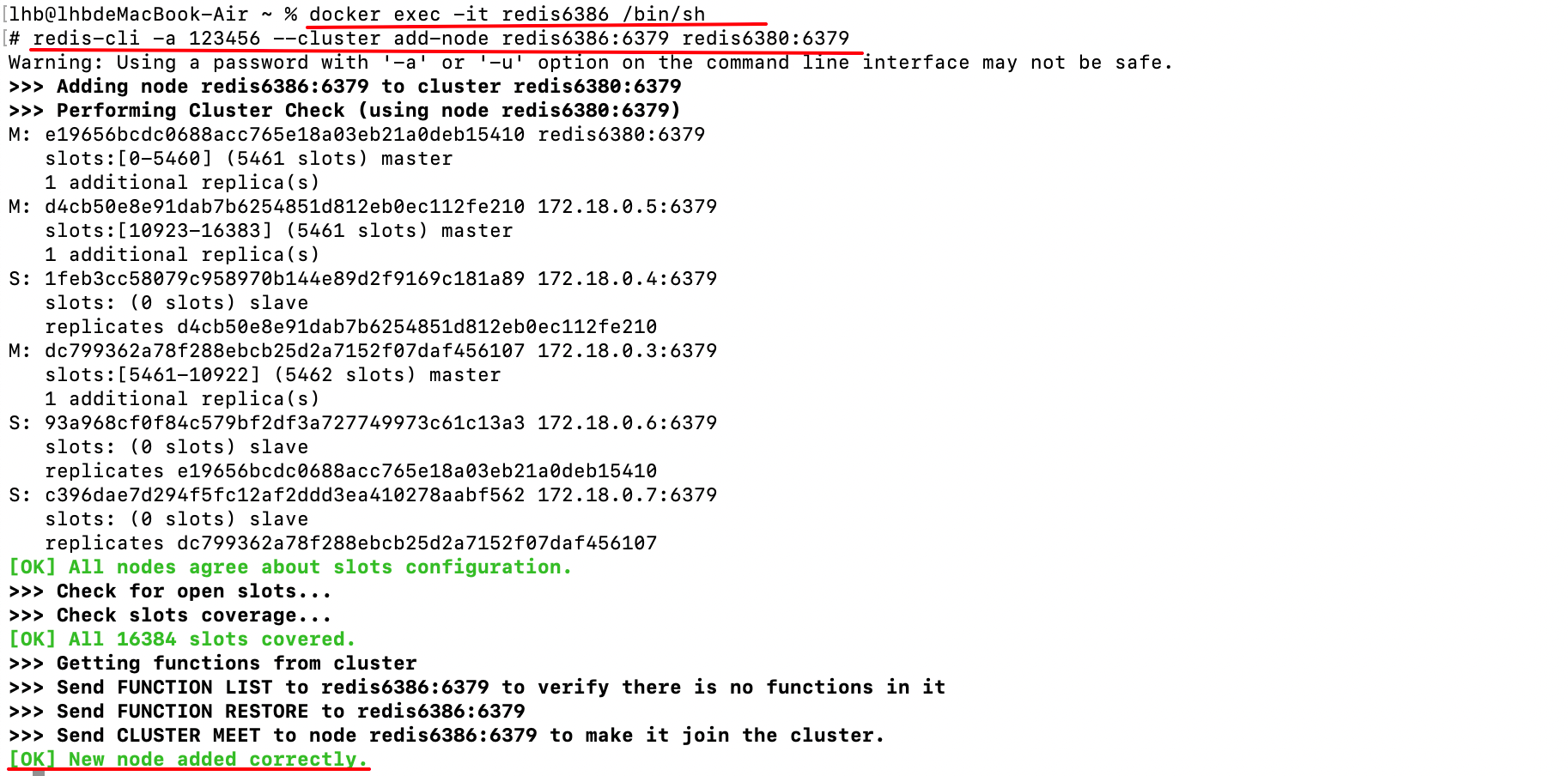
当加入成功后,再次查看集群节点信息:

可以看到新节点已加入到集群中,并且作为主节点,但是,此时新节点还没有分配哈希槽,无法起作用。
下一步就是为新节点分配哈希槽,由于已存在的三个主节点已经平分了16384个哈希槽,要为新节点分配哈希槽,就需要其他节点让出一部分哈希槽。
命令如下:
txt
redis-cli -a 123456 --cluster reshard <existing_node_address><existing_node_address>:表示集群中存在的节点地址;
根据提示:
- 输入要分配的哈希槽数量,现在有4个主节点,平均分配,则每个节点有4096个哈希槽,所以新节点应有4096个哈希槽;
- 输入要接收哈希槽的节点ID,即新节点ID;
- 输入分配的节点ID,即哪些拥有哈希槽的旧的主节点要分一些哈希槽出去,如果是全部,则输入
all;
结果如下:
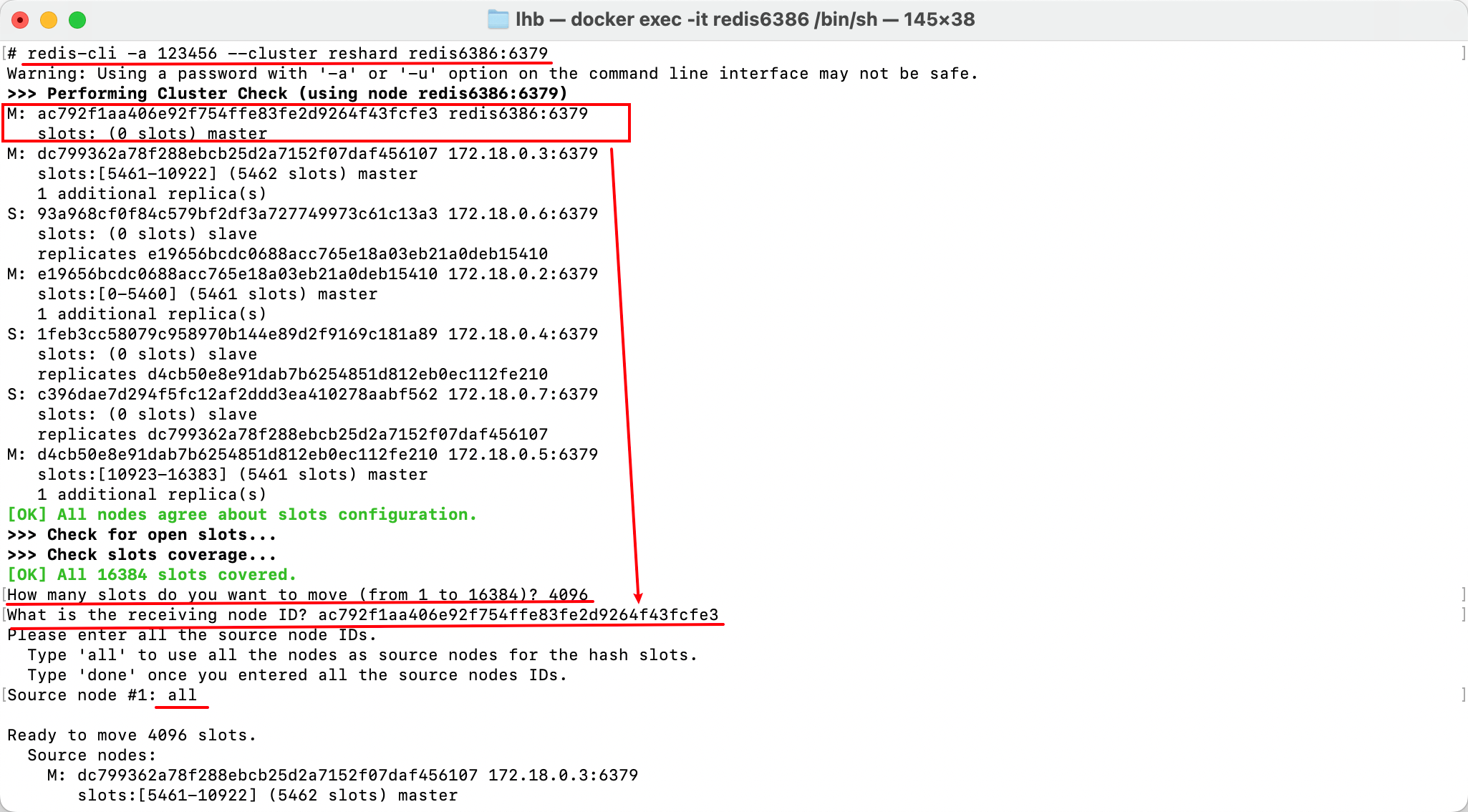
再次查看集群节点信息:

可以看到,新节点已经有哈希槽了,并且哈希槽不连续,表示是由其他旧的主节点各自匀出来一部分哈希槽给新节点的。
最后,为新节点添加从节点(这里先用Docker再开启redis6387容器作为从节点):
txt
redis-cli --cluster add-node <新节点IP:端口> <集群中任意一个已存在节点的IP:端口> --cluster-slave --cluster-master-id <主节点ID>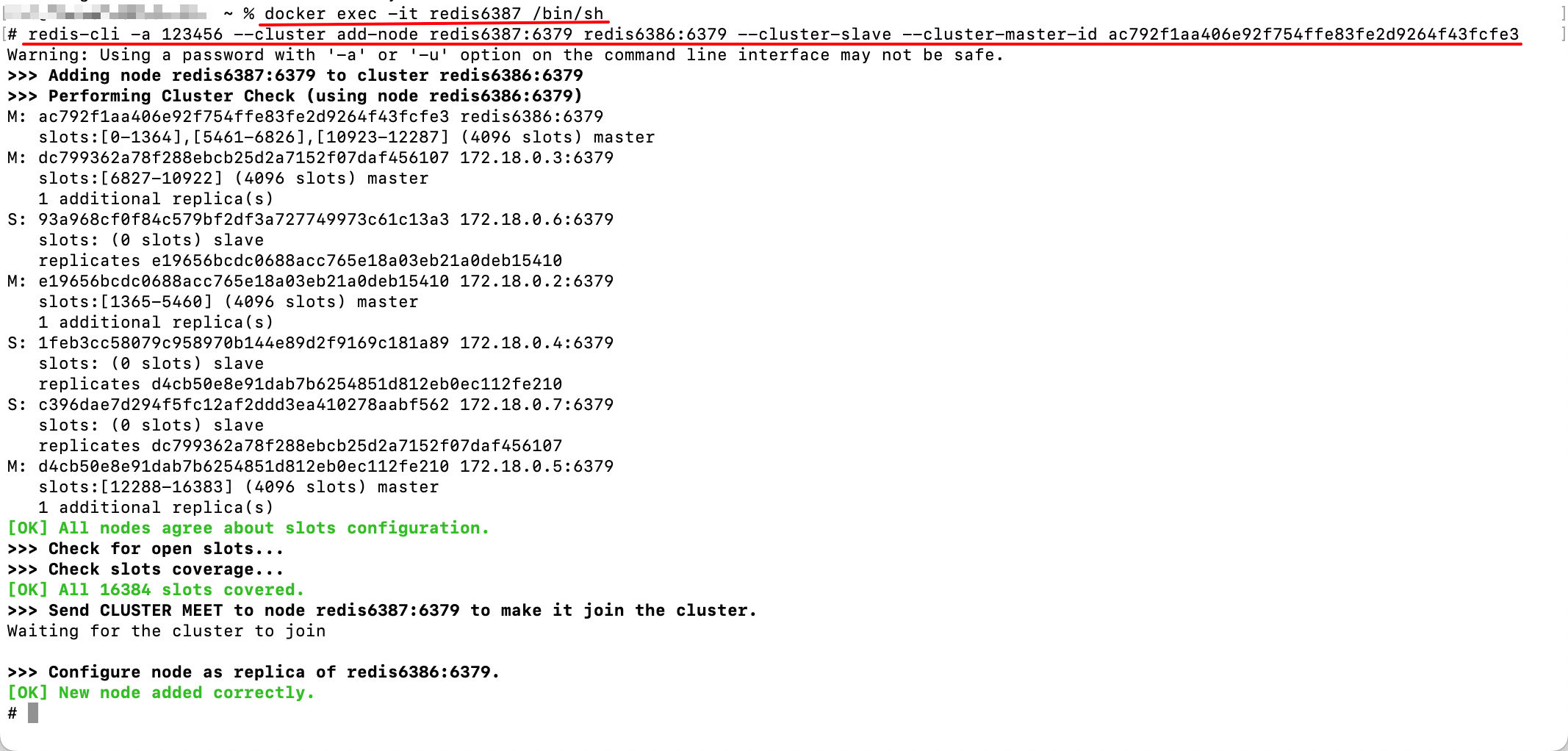

最后,验证一下扩容成功:
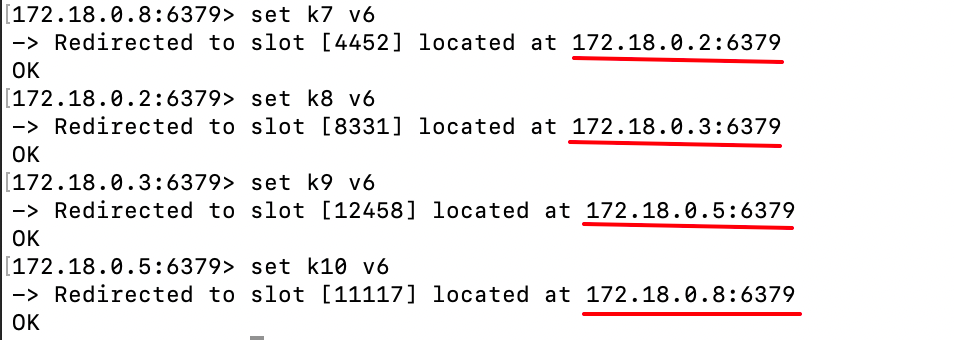
可以看到,数据分别写入了4台节点中。
5.2 扩容小结
扩容步骤小结:
- 首先准备并启动新节点;
- 将新节点加入集群:
redis-cli --cluster add-node <new_node_address> <existing_node_address> - 然后重新分配哈希槽:
redis-cli --cluster reshard <existing_node_address>; - 【可选】最后,为新的主节点分配从节点:
redis-cli --cluster add-node <新节点IP:端口> <集群中任意一个已存在节点的IP:端口> --cluster-slave --cluster-master-id <主节点ID>;
5.3 缩容
缩容是指移除集群中的某台主节点。
首先从集群中移除从节点:
txt
redis-cli --cluster del-node <集群中任意一个已存在节点的IP:端口> <要移除的从节点ID>首先找到要移除的从节点ID:
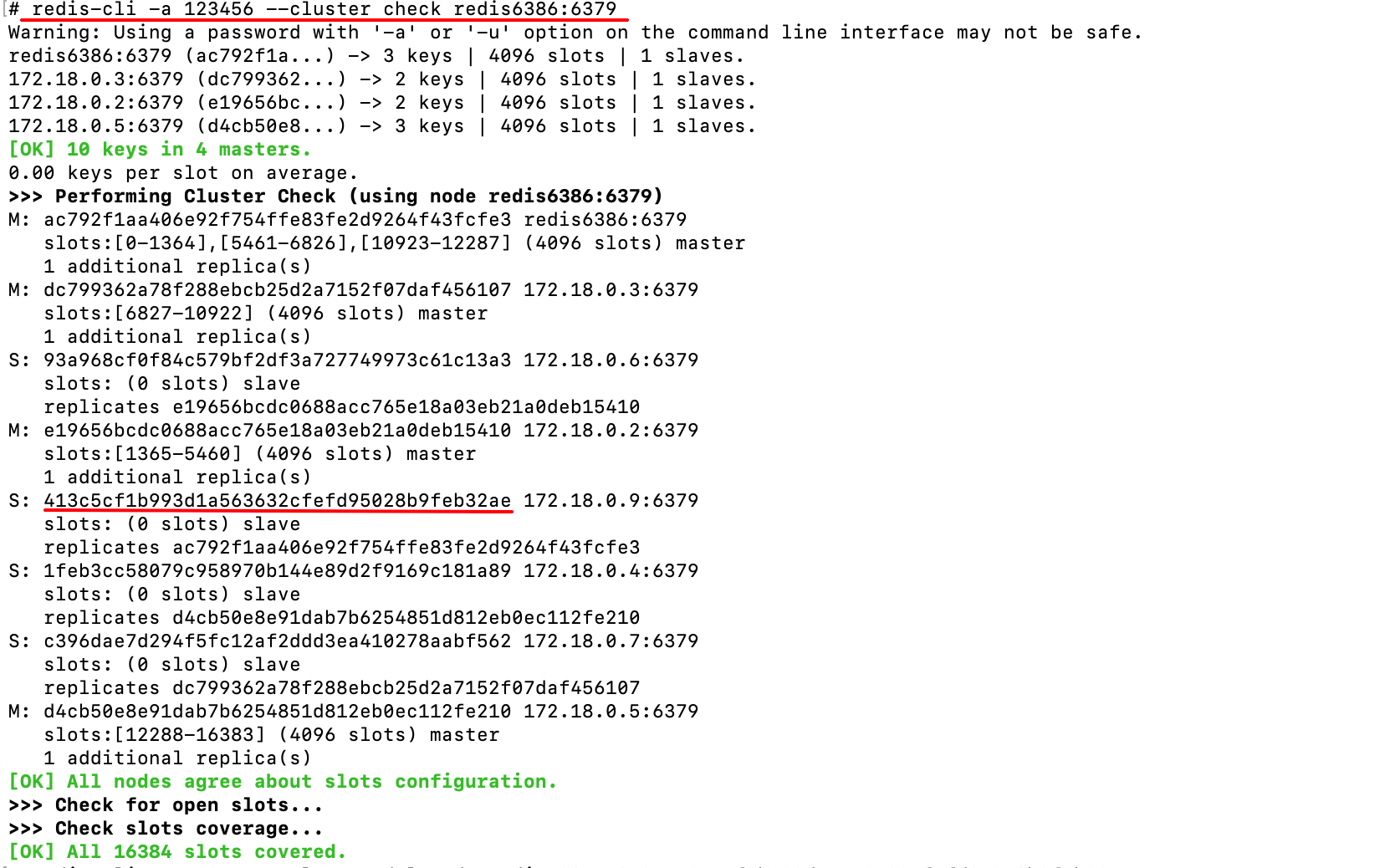
然后移除从节点:
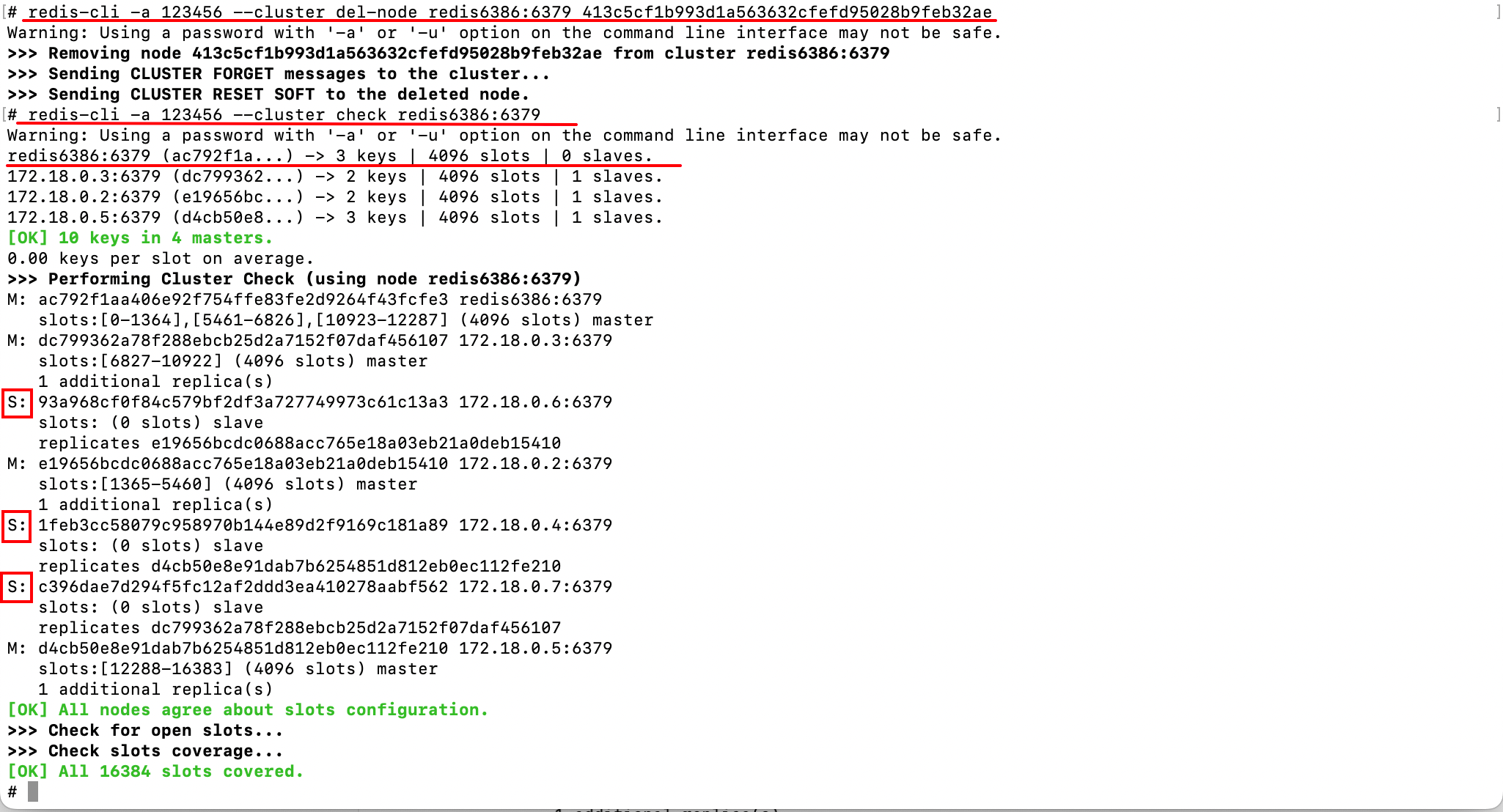
可以看到,此时集群中只有3个从节点了。
此时,就可以顺利关闭从节点Redis实例了。

然后,找到要移除的主节点,将其下的哈希槽迁移给其他主节点:
txt
redis-cli --cluster reshard <集群中任意一个已存在节点的IP:端口>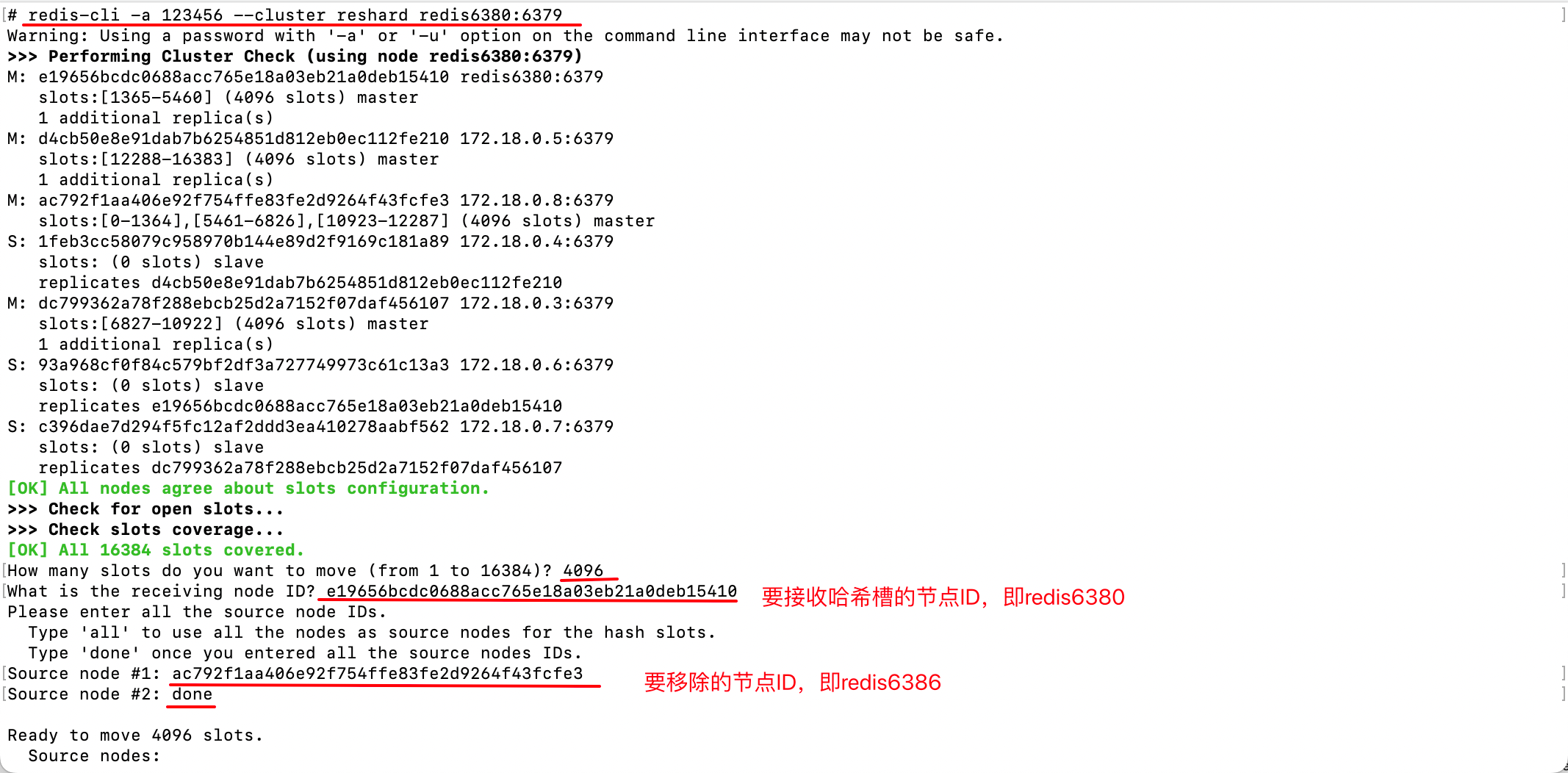
再次检查集群节点信息:
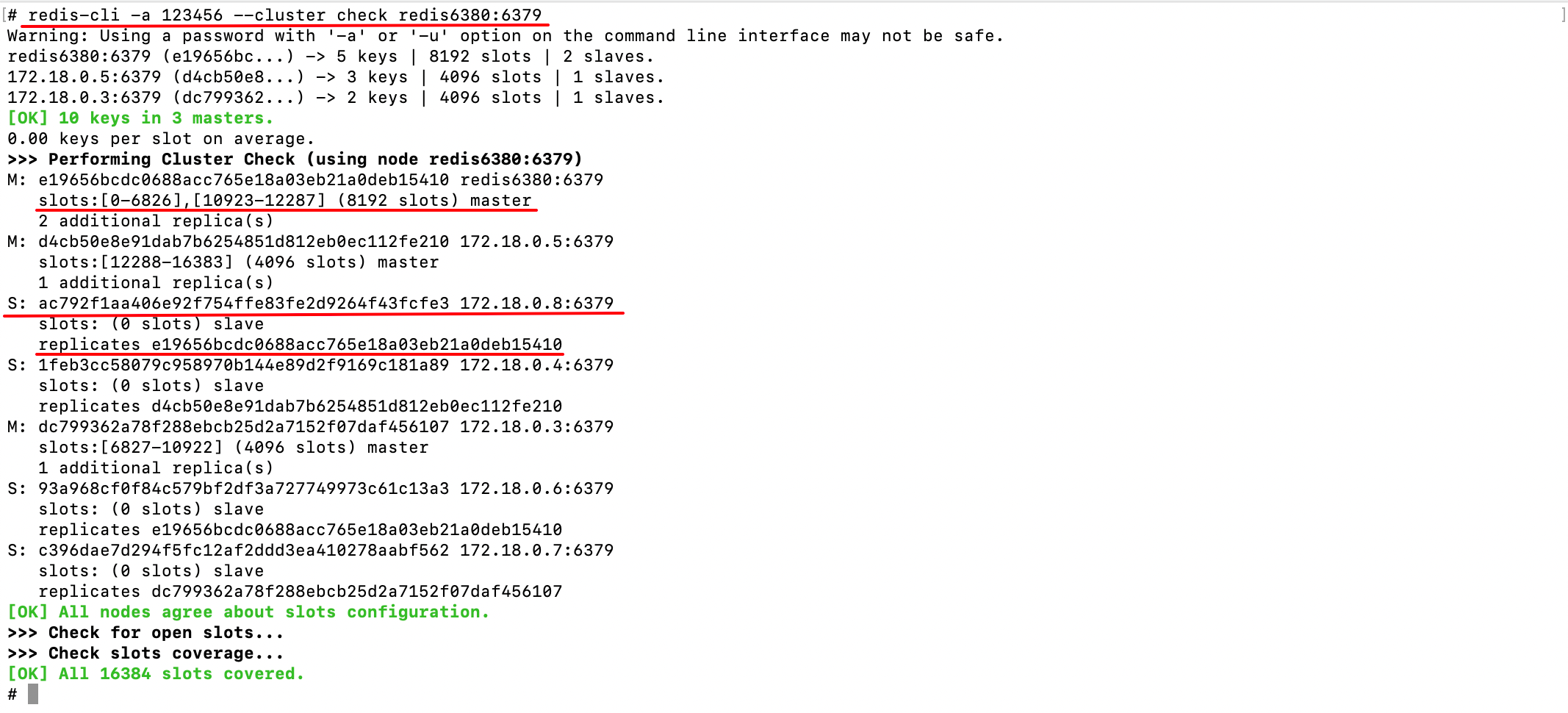
可以发现,要移除的主节点变为了从节点,跟随接收哈希槽的主节点。
最后,再次执行移除从节点的操作即可。
5.4 缩容小结
缩容步骤如下:
- 首先确定要移除的主节点;
- 然后移除该主节点的所有从节点;
- 然后将该主节点的哈希槽分配给其他主节点,这一步后该主节点变为从节点;
- 【可选】最后,再次移除从节点即可;
参考资料
[1] https://redis.io/docs/latest/operate/oss_and_stack/management/scaling/
[2] https://redis.io/docs/latest/operate/oss_and_stack/reference/cluster-spec/