Appearance
MySQL SQL优化
本文主要介绍在编写SQL语句时的注意事项。
1. 性能分析
1.1 查看执行频次
我们可以通过以下命令查看当前数据库INSERT、UPDATE、DELETE、SELECT的访问频次:
sql
show global status like 'Com_______' -- 7个_例如:
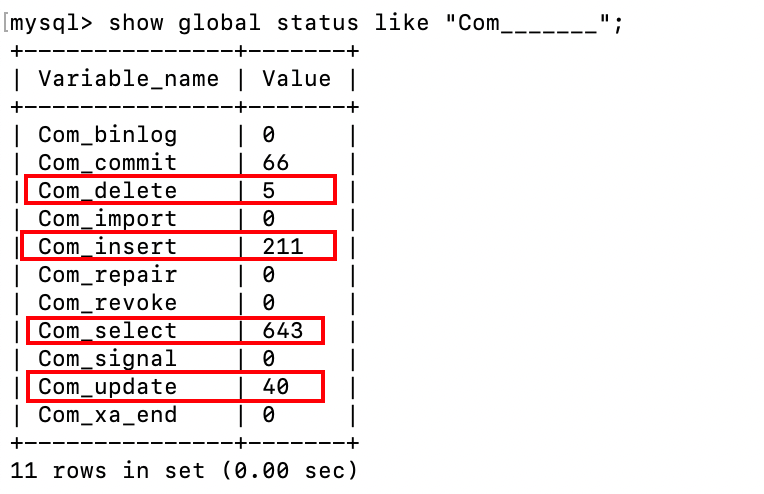
通过以上结果,我们可以判断该数据库是执行DQL语句多还是执行DML语句多,从而有针对性地进行优化。
1.2 慢查询日志
慢查询日志是记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在配置文件中配置开启:
properties
# 开启MySQL慢查询
slow_query_log=1
# 设置慢查询的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录在慢查询日志中
long_query_time=2
# (可选) 指定慢查询日志文件的路径。
# 如果不设置此参数,MySQL 会使用其数据目录 (datadir) 下的默认文件,
# 文件名通常是 'hostname-slow.log' (例如,你的电脑名称-slow.log)。
# 确保 MySQL 进程对该路径有写入权限。
# slow_query_log_file = /var/log/mysql/mysql-slow.log
# slow_query_log_file = /usr/local/mysql/data/mysql-slow.log # 示例路径登录MySQL后,我们可以使用如下命令判断是否开启了慢查询日志:
sql
show variables like 'slow_query_log';
show variables like 'long_query_time';
show variables like 'slow_query_log_file';假设我们执行以下命令:

休眠11秒后返回结果。
之后在慢查询日志中就可以看到该条SQL语句的记录信息:

1.3 show profiles
show profiles命令主要用于分析单个 SQL 语句在服务器端的执行过程中每个阶段的耗时。
首先查看是否开启:
sql
select @@profiling;如果没有开启,可以使用以下命令开启:
sql
set profiling = 1;开启后,可以正常执行我们的SQL语句:
sql
select * from account;然后执行分析命令:
sql
show profiles;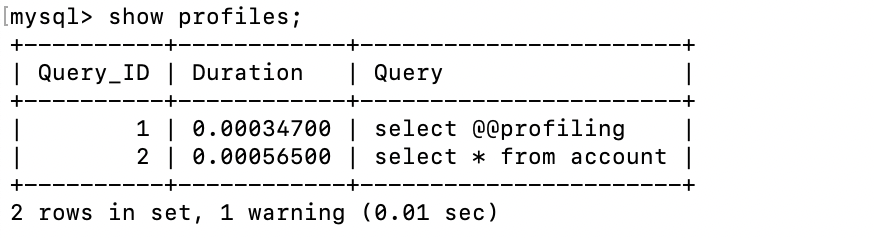
可以看到我们执行的SQL命令以及耗时。
然后我们可以针对某一条SQL命令,查看详细情况:
sql
SHOW PROFILE ALL FOR QUERY 2; -- 这里的 2 是上面 Query_ID 列的值这条命令会显示所有情况,也可以选取查看部分参数,例如:
sql
SHOW PROFILE CPU FOR QUERY 2;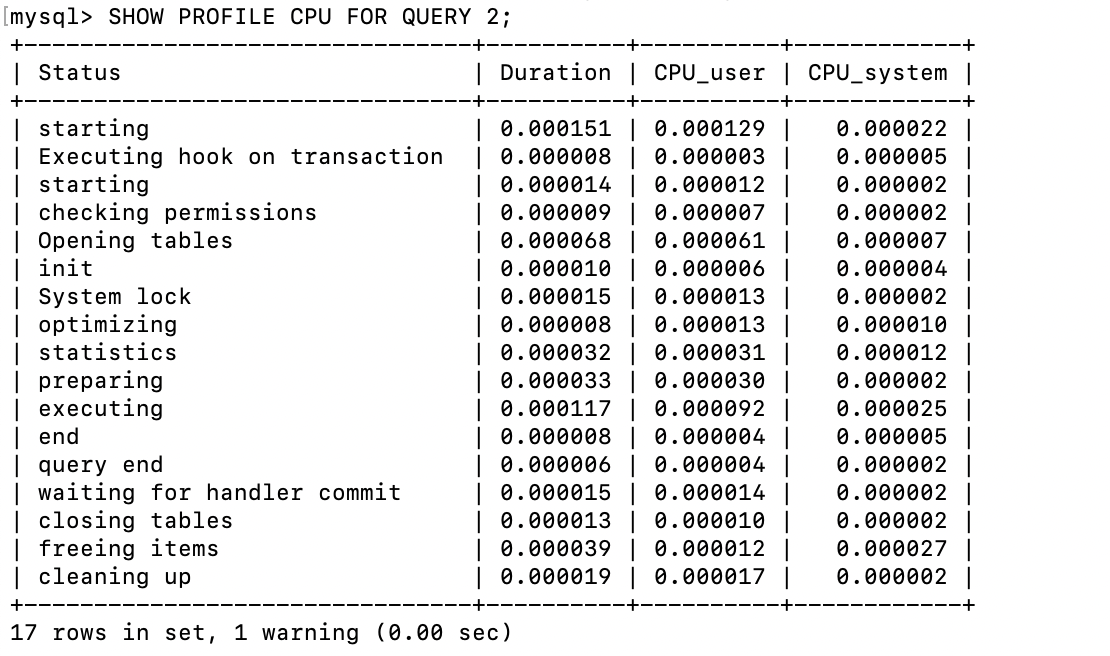
完整的语法如下:
sql
SHOW PROFILE [type [, type] ... ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type: {
ALL
| BLOCK IO
| CONTEXT SWITCHES
| CPU
| IPC
| MEMORY
| PAGE FAULTS
| SOURCE
| SWAPS
}使用完成后,强烈建议关闭:
sql
set profiling = 0;1.4 explain
之前在介绍索引时已说明,此处不再赘述。
2. 插入优化
如果我们要插入多条数据,则使用批量插入语法:
sql
insert into tbl_test values(1,'a'),(2,'b'),(3,'c')...;并且手动提交事务:
sql
begin;
insert into tbl_test values(1,'a'),(2,'b'),(3,'c');
insert into tbl_test values(4,'d'),(5,'e'),(6,'f');
commit;要按照主键顺序插入,否则会引起页分裂。
所谓页分裂,是指表中的行数据都是按照主键的大小顺序存放在聚集索引中的,聚集索引以页为单位存放数据。当我们乱序插入数据时,会寻找合适的插入位置,可能引发页分裂。
例如,如下插入主键值为50的行数据,需要新创建一个页:
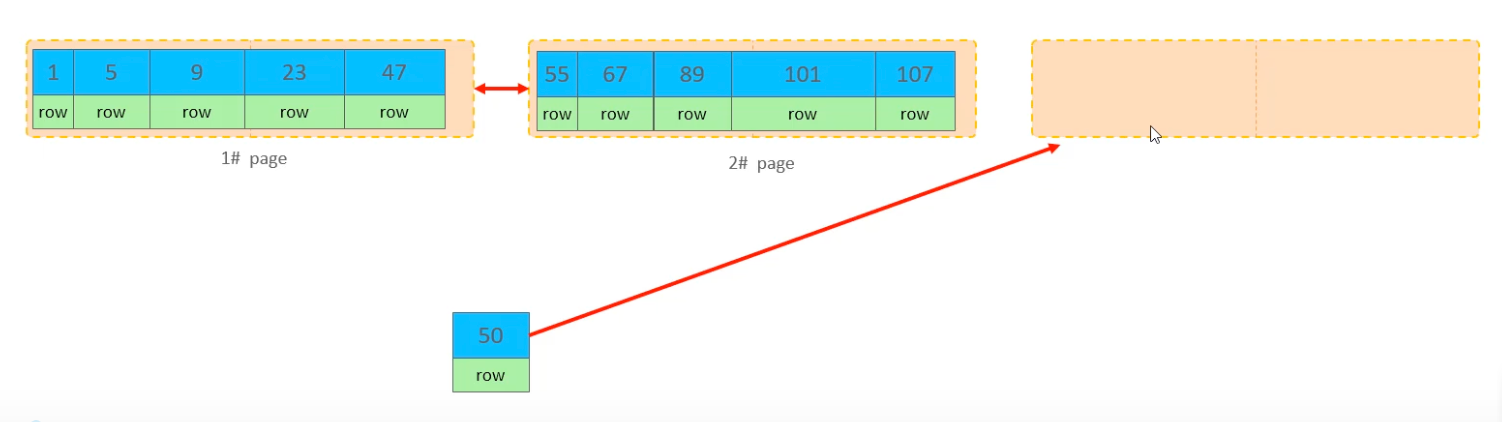
需要找到插入位置,并移动已有数据:

插入数据并改变链表指针关系:

如果是大批量导入数据,推荐使用load指令:https://dev.mysql.com/doc/refman/8.4/en/load-data.html
3. order by优化
优化 ORDER BY 的主要目标是避免文件排序(filesort)。文件排序是 MySQL 在内存或磁盘上对结果集进行排序的操作,当数据量大时,它会消耗大量的 CPU 和 I/O 资源。
- 文件排序(using filesort):通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回结果的排序都叫文件排序;
- 索引排序(using index):通过有序索引顺序扫描直接返回有序数据,这种情况即为索引排序,不需要额外排序,效率高;
有以下方法提高order by 效率:
- 为
ORDER BY的列创建索引: 如果查询经常对某个或某几个列进行排序,那么为这些列创建索引是首要考虑。
sql
CREATE INDEX idx_user_age ON users (age);
SELECT * FROM users ORDER BY age; -- 可以使用索引- 考虑联合索引,并遵循“最左前缀原则”: 当
ORDER BY涉及多个列时,应创建一个联合索引,并且排序的顺序和索引的顺序一致,同时兼顾WHERE条件。
sql
CREATE INDEX idx_user_name_age ON users (name, age);
SELECT * FROM users ORDER BY name, age; -- 可以使用索引
SELECT * FROM users WHERE gender = 'male' ORDER BY name, age; -- 如果 gender 也有索引,可能需要联合索引 (gender, name, age)- 索引方向和
ORDER BY方向一致: 如果ORDER BY使用ASC和DESC混合排序,可能无法使用单一索引。
sql
# 假设索引是 CREATE INDEX idx_a_b ON table (a ASC, b ASC);
SELECT * FROM table ORDER BY a ASC, b ASC; -- 可以使用索引
SELECT * FROM table ORDER BY a DESC, b DESC; -- 如果 MySQL 版本支持降序索引(8.0+),或通过优化器处理,也可以使用索引
SELECT * FROM table ORDER BY a ASC, b DESC; -- 通常无法使用这个单一索引进行优化(需要两个方向都支持)从 MySQL 8.0 开始,支持在 CREATE INDEX 时指定列的排序方向(ASC/DESC),这使得混合排序的 ORDER BY 也能更好地利用索引。
4. limit优化
limit offset, count 深分页的问题:
当 offset 值非常大时,例如 limit 1000000, 10,MySQL 实际上需要做以下事:
- 扫描并丢弃大量数据: 为了找到从
offset开始的count行数据,MySQL 必须从结果集的最开始扫描offset + count行。在扫描了前面offset行之后,它会将其丢弃,只保留并返回从offset + 1到offset + count的那部分数据。- 问题所在: 即使只需要 10 行数据,如果
offset是 100 万,MySQL 也必须读取和处理 100 万 + 10 行数据,然后丢弃掉前面的 100 万行。这意味着随着offset的增大,查询的开销几乎是线性增长的,大量的计算和 I/O 都被浪费在丢弃的数据上。
- 问题所在: 即使只需要 10 行数据,如果
- 文件排序的开销增大: 如果查询中包含
ORDER BY子句,并且该排序无法完全通过索引优化(即发生了filesort),那么LIMIT深分页会加剧filesort的性能问题。MySQL 需要对offset + count行数据进行排序,这会导致更大的内存消耗(sort_buffer_size)和可能的磁盘 I/O(如果数据溢出到磁盘)。
解决方法有两种:
基于游标(Cursor-Based Pagination)/上次查询点优化:不使用
offset,而是记录上次查询到的最后一条数据的某个唯一或排序字段的值,然后利用这个值作为下一次查询的起点。例如:
sql-- 假设上次查询的最后一条记录的 id 是 12345 SELECT * FROM products WHERE id > 12345 ORDER BY id ASC LIMIT 10;该方法的缺点是无法直接跳到任意页(如“第 500 页”),只能“下一页”或“上一页”。
基于子查询的优化:如果的
ORDER BY列已经有索引,并且需要返回很多列,可以考虑使用子查询来优化,即先使用子查询返回结果集的主键列值,然后再通过连接获取结果集。例如:
sqlSELECT t1.* FROM your_table AS t1 INNER JOIN ( SELECT id FROM your_table ORDER BY order_column ASC LIMIT 1000000, 10 ) AS t2 ON t1.id = t2.id;内层子查询
SELECT id ... LIMIT ...只需要扫描索引(因为只返回id列),这比扫描整个数据行要快得多。然后外层INNER JOIN再根据 ID 获取完整的行数据。
5. update优化
update优化主要是避免行级锁升级为表级锁。如果我们在where子句的查询条件列上没有索引,那么MySQL需要逐行扫描数据表,并对扫过的数据行加锁,从而导致隐式地加上了表级锁,从而阻塞其他事务。
解决方法就是创建和使用适当的索引。
6. 小结
用好索引。